 电子发烧友App
电子发烧友App


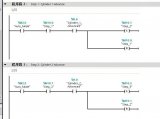
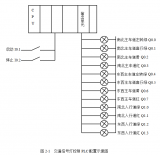
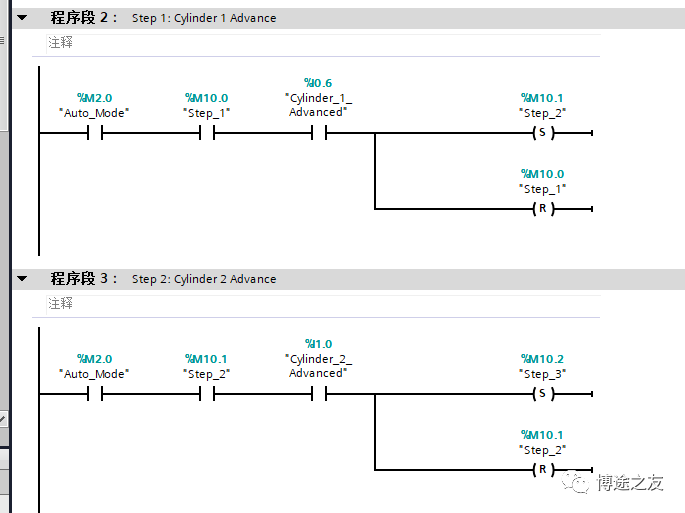
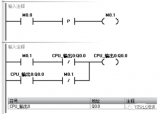
今天来分享给大家PLC程序解密 每个plc的生产厂家都说自己的plc无法解密 ,但是最终都还难逃破解的厄运。经过几天的努力功夫不负有心人,终于可以直读密码了react-redux 这个库想必熟悉 react 的人都不陌生,用一句话描述它就是:它作为『redux 这个框架无关的数据流管理库』和『react 这个视图库』的桥梁,使得 react 中能更新 redux 的 store,并能监听 store 的变化并通知 react 的相关组件更新,从而能让 react 将状态放在外部管理(有利于 model 集中管理,能利用 redux 单项数据流架构,数据流易预测易维护,也极大的方便了任意层级组件间通信等等好处)。
react-redux 版本来自截止 2022.02.28 时的最新版本 v8.0.0-beta.2(有点悲催的是,读源码的时候还是 7 版本,没想到刚读完git pull一下就升到 8 了,所以把 8 又看了一遍)
react-redux 8相比于 7 版本包括但不限于这些改变:
- 全部用 typescript 重构
- 原来的 Subscription class 被 createSubscription 重构,用闭包函数代替 class 的好处,讲到那部分代码的时候会提到。
-
使用 React18 的useSyncExternalStore代替原来自己实现的订阅更新(内部是
useReducer),useSyncExternalStore以及它的前身useMutableSource解决了 concurrent 模式下的tearing问题,也让库本身的代码更简洁,useSyncExternalStore相比于前辈useMutableSource不用关心selector(这里说的是useSyncExternalStore的 selector,不是 react-redux)的 immutable 心智负担。
下面的部分和源码解析没有直接关系,但读了也能有所收获,也能明白为什么要写这篇文章。想直接看源码解析部分的可以跳转到React-Redux 源码解析部分
正文前的吹水阶段 1:既然是『再读』,那『首读』呢?
不知道大家平时在逛技术论坛的时候,有没有看见过类似这样的评论:redux 性能不好,mobx 更香……
喜欢刨根问底的人(比如我)看到了不禁想问更多问题:
- 究竟是 redux 性能不好还是 react-redux 性能不好?
- 具体不好在哪里?
- 能不能避免?
这些问题你问了,可能得到的也是三言两语,不够深入。与此同时还有一个问题, react-redux 是如何关联起 redux 和 react 的?这个问题倒是有不少源码解析的文章,我曾经看过一篇很详细的,不过很可惜是老版本的,还在用 class component,所以当时的我决定自己去看源码。当时属于是粗读,读完之后的简单总结就是 Provider 中有 Subscription 实例,connect 这个高阶组件中也有 Subscription 实例,并且有负责自身更新的 hooks: useReducer,useReducer 的 dispatch 会被注册进 Subscription 的 listeners,listeners 中有一个方法 notify 会遍历调用每个 listener,notify 会被注册给 redux 的 subscribe,从而 redux 的 state 更新后会通知给所有 connect 组件,当然每个 connect 都有检查自己是否需要更新的方法 checkForUpdates 来避免不必要的更新,具体细节就不说了。
总之,当时我只粗读了整体逻辑,但是可以解答我上面的问题了:
-
react-redux 确实有可能性能不好。而至于 redux,每次 dispatch 都会让 state 去每个 reducer 走一遍,并且为了保证数据 immutable 也会有额外的创建复制开销。不过
mutable阵营的库如果频繁修改对象也会导致 V8 的对象内存结构由顺序结构变成字典结构,查询速度降低,以及内联缓存变得高度超态,这点上 immutable 算拉回一点差距。不过为了一个清晰可靠的数据流架构,这种级别的开销在大部分场景算是值得,甚至忽略不计。 - react-redux 性能具体不好在哪里?因为每个 connect 不管需不需要更新都会被通知一次,开发者定义的 selector 都会被调用一遍甚至多遍,如果 selector 逻辑昂贵,还是会比较消耗性能的。
- 那么 react-redux 一定会性能不好吗?不一定,根据上面的分析,如果你的 selector 逻辑简单(或者将复杂派生计算都放在 redux 的 reducer 里,但是这样可能不利于构建一个合理的 model),connect 用的不多,那么性能并不会被 mobx 这样的细粒度更新拉开太多。也就是说 selector 里业务计算不复杂、使用全局状态管理的组件不多的情况下,完全不会有可感知的性能问题。那如果 selector 里面的业务计算复杂怎么办呢?能不能完全避免呢?当然可以,你可以用 reselect 这个库,它会缓存 selector 的结果,只有原始数据变化时才会重新计算派生数据。
这就是我的『首读』,我带着目的和问题去读源码,现在问题已经解决了,按理说一切都结束了,那么『再读』是因何而起的呢?
正文前的吹水阶段 2:为什么要『再读』?
前段时间我关注了一个 github 上的 React 状态管理库zustand。
zustand 是一个非常时髦的基于 hooks 的状态管理库,基于简化的 flux 架构,也是 2021 年 Star 增长最快的 React 状态管理库。可以说是 redux + react-redux 的有力竞争者。
它的 github 开头是这样介绍的

大意是:它是一个小巧、快速、可扩展的、使用简化的 flux 架构的状态管理解决方案。有基于 hooks 的 api,使用起来十分舒适、人性化。
不要因为它很可爱而忽视它(貌似作者把它比喻成小熊了,封面图也是一个可爱的小熊)。它有很多的爪子,花了大量的时间去处理常见的陷阱,比如可怕的子代僵尸问题(zombie child problem),react 并发模式(react concurrency),以及使用 portals 时多个 render 之间的 context 丢失问题(context loss)。它可能是 React 领域中唯一一个能够正确处理所有这些问题的状态管理器。
里面讲到一个东西:zombie child problem。当我点进 zombie child problem 时,是 react-redux 的官方文档,让我们一起来看看这个问题是什么以及 react-redux 是如何解决的。想看原文可以直接点链接。
"Stale Props" and "Zombie Children"(过期 Props 和僵尸子节点问题)
自 v7.1.0 版本发布以后,react-redux 就可以使用 hooks api 了,官方也推荐使用 hooks 作为组件中的默认使用方法。但是有一些边缘情况可能会发生,这篇文档就是让我们意识到这些事的。
react-redux 实现中最难的地方之一就是:如果你的 mapStateToProps 是(state, ownProps)这样使用的,它将会每次被传入『最新的』props。一直到版本 4 都一直有边缘场景下的重复的 bug 被报告,比如:有一个列表 item 的数据被删除了,mapStateToProps 里面就报错了。
从版本 5 开始,react-redux 试图保证
ownProps的一致性。在版本 7 里面,每个connect()内部都有一个自定义的 Subscription 类,从而当 connect 里面又有 connect,它能形成一个嵌套的结构。这确保了树中更低层的 connect 组件只会在离它最近的祖先 connect 组件更新后才会接受到来自 store 的更新。然而,这个实现依赖于每个connect()实例里面覆写了内部 React Context 的一部分(subscription 那部分),用它自身的 Subscription 实例用于嵌套。然后用这个新的 React Context ( \ ) 渲染子节点。\>如果用 hooks,没有办法渲染一个 context.Provider,这就代表它不能让 subscriptions 有嵌套的结构。因为这一点,"stale props" 和 "zombie child" 问题可能在『用 hooks 代替 connect』 的应用里重新发生。
具体来说,"stale props" 会出现在这种场景:
- selector 函数会根据这个组件的 props 计算出数据
- 父组件会重新 render,并传给这个组件新的 props
- 但是这个组件会在 props 更新之前就执行 selector(译者注:因为子组件的来自 store 的更新是在 useLayoutEffect/useEffect 中注册的,所以子组件先于父组件注册,redux 触发订阅会先触发子组件的更新方法)
这种旧的 props 和最新 store state 算出来的结果,很有可能是错误的,甚至会引起报错。
"Zombie child"具体是指在以下场景:
- 多个嵌套的 connect 组件 mounted,子组件比父组件更早的注册到 store 上
- 一个 action dispatch 了在 store 里删除数据的行为,比如一个 todo list 中的 item
- 父组件在渲染的时候就会少一个 item 子组件
- 但是,因为子组件是先被订阅的,它的 subscription 先于父组件。当它计算一个基于 store 和 props 计算的值时,部分数据可能已经不存在了,如果计算逻辑不注意的话就会报错。
useSelector()试图这样解决这个问题:它会捕获所有来自 store 更新导致的 selector 计算中的报错,当错误发生时,组件会强制更新,这时 selector 会再次执行。这个需要 selector 是个纯函数并且你没有逻辑依赖 selector 抛出错误。如果你更喜欢自己处理,这里有一个可能有用的事项能帮助你在使用
useSelector()时避免这些问题
- 不要在 selector 的计算中依赖 props
- 如果在:你必须要依赖 props 计算并且 props 将来可能发生变化、依赖的 store 数据可能会被删除,这两种情况下时,你要防备性的写 selector。不要直接像
state.todos[props.id].name这样读取值,而是先读取state.todos[props.id],验证它是否存在再读取todo.name
因为connect向 context provider 增加了必要的Subscription,它会延迟执行子 subscriptions 直到这个 connected 组件 re-rendered。组件树中如果有 connected 组件在使用useSelector的组件的上层,也可以避免这个问题,因为父 connect 有和 hooks 组件同样的 store 更新(译者注:父 connect 组件更新后才会更新子 hooks 组件,同时 connect 组件的更新会带动子节点更新,被删除的节点在此次父组件的更新中已经卸载了:因为上文中说state.todos[props.id].name,说明 hooks 组件是上层通过 ids 遍历出来的。于是后续来自 store 的子 hooks 组件更新不会有被删除的)
以上的解释可能让大家明白了 "Stale Props" 和 "Zombie Children" 问题是如何产生的以及 react-redux 大概是怎么解决的,就是通过子代 connect 的更新被嵌套收集到父级 connect,每次 redux 更新并不是遍历更新所有 connect,而是父级先更新,然后子代由父级更新后才触发更新。但是似乎 hooks 的出现让它并不能完美解决问题了,而且具体这些设计的细节也没有说到。这部分的疑惑和缺失就是我准备再读 react-redux 源码的原因。
React-Redux 源码解析
react-redux 版本来自截止 2022.02.28 时的最新版本 v8.0.0-beta.2
阅读源码期间在 fork 的 react-redux 项目中写下了一些中文注释,作为一个新项目放在了react-redux-with-comment仓库,阅读文章需要对照源码的可以看一下,版本是 8.0.0-beta.2
在讲具体细节之前我想先说一下总体的抽象设计,让大家心中带着设计蓝图去读其中的细节,否则只看细节很难让它们之间串联起来明白它们是如何共同协作完成整个功能的。
React-Redux 的 Provider 和 connect 都提供了自己的贯穿子树的 context,它们的所有的子节点都可以拿到它们,并会将自己的更新方法交给它们。最终形成了根 <-- 父 <-- 子这样的收集顺序。根收集的更新方法会由 redux 触发,父收集的更新方法在父更新后再更新,于是保证了父节点被 redux 更新后子节点才更新的顺序。
审核编辑:符乾江





























 工商网监
工商网监
评论