 电子发烧友App
电子发烧友App


块I/O流程与 I/O调度器
- 一个块IO的一生:从page cache到bio 到 request
- 块设备层的数据结构
- page和bio的关系,request 和bio的关系
- O_DIRECT 和O_SYNC
- blktrace , ftrace
- IO调度和CFQ调度算法
- CFQ和ionice
- cgroup与IO
- io性能测试: iotop, iostat
主要内容:从应用程序发起一次IO行为,最终怎么到磁盘,以及在这个路径上有什么trace的方法和 配置。每次应用程序写磁盘,都是到pagecache 。三进三出 讲解 bio的一生,都是在pagecache以下。
首先,在一次普通的sys_write过程中,会触发以下的函数调用。
sys_write -> vfs_write -> generic_file_write_iter
PageCache: Linux通过局部性原理,使用页面缓存提高性能。
1) generic_perform_write -> write_begin -> copy_data ->write_end
generic_perform_write: 开始pagecache的写入过程
write_begin: 在内存空间中准备对应index需要的page。
例如: ext4_write_begin 中包含
grab_cache_page_write_begin : 查获取一个缓存页或者创建一个缓存页。
-> page_cache_get_page: 从mapping的radix tree中查找缓存页,假如不存在,则从伙伴系统中申请一个新页插入,并添加到LRU链表中。
ext4_write_end 首先调用__block_commit_write提交写入的数据,
通过set_buffer_uptodate :
-> mark_buffer_dirty -> set_buffer_dirty/ set_page_dirty/ set_inode_dirty 将该页设脏,
通过wb_wakeup_delayed把writeback任务提交到bdi_writeback队列中。
DirectIO:
2) generic_file_direct_write -> filemap_write_and_write_range -> mapping-> a_ops-> direct_IO
如果是buffer IO , 脏页回写是异步的,并且由块设备层负责。
对于新版本的内核,ext4注册的方法是new_sync_write
sys_write -> vfs_write -> __vfs_write -> new_sync_write
-> filp->f_op->write_iter -> ext4_file_write_iter
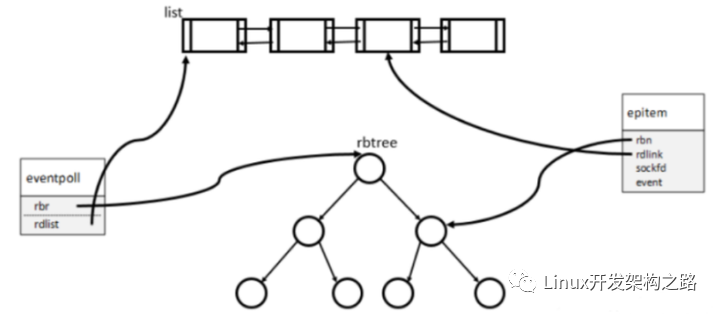
块设备层的数据结构
struct page -> struct inode -> struct bio -> struct request
真正开始做IO之前,即操作block子系统之前,包括以下步骤:
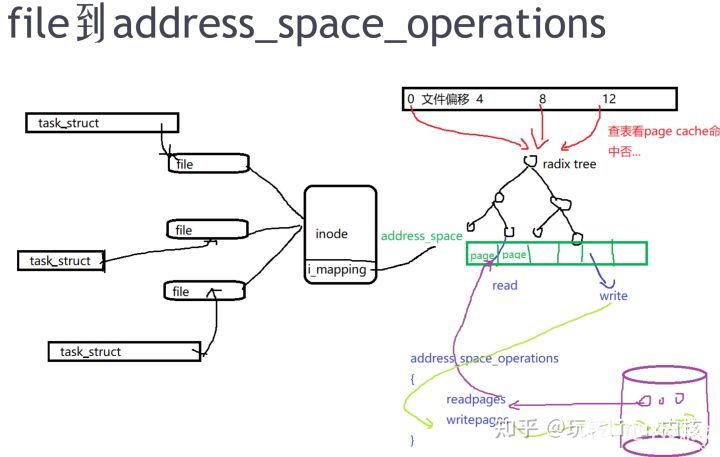
应用程序读一个文件,首先会去查page cache是否命中,下一次再读page cache是命中的。
应用程序去写硬盘时,首先会去写page cache,至于什么时候开始写硬盘,由linux flush线程通过(pdflush->每一个设备的flush ->工作队列)实现。当然也可以是线程本身,通过direct IO去写硬盘。
如上图三个task_struct进程,同时打开一个文件,在内存中生成file数据结构,记录文件打开的实例。
inode是真实存在硬盘里,当inode结构体中的i_mapping,对应的地址空间address_space。一个4M的文件,被分成很多4K单元存在于内存,通过地址 去radix tree来查page cache是否命中。如果查到了,就从radix tree对应的page返回。 如果没有page cache对应,就会通过 address_space_operations(文件系统实现的数据结构) 去 readpage,从硬盘里的块读到pagecache。
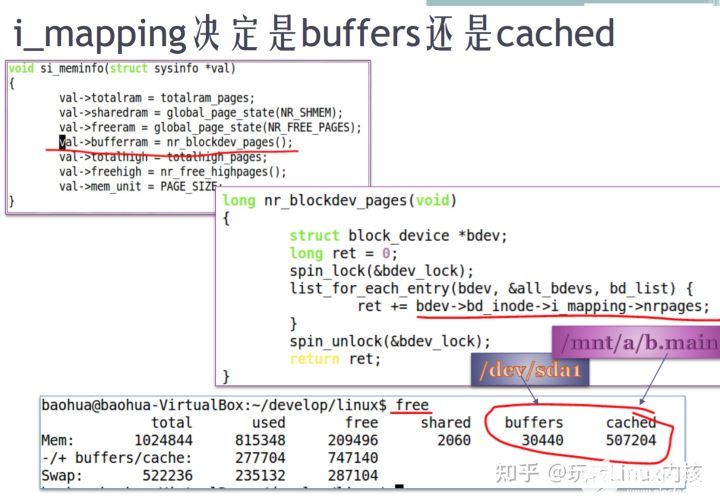
free命令看到的buffers和cache有什么区别?
答:在内核层面,全部都是pagecache。前者对应的是裸分区产生的page cache,后者对应的是挂载文件系统之后,文件系统目录产生的page cache。如下图内核代码的截图:
文件系统的管理单元是block,内存管理是以page为单位,扇区(section)是硬件读写的最小单元。假设你把ext4文件系统格式化成1k/block,那么一个page对应4个block,此时读一个内存的page,文件系统要操作4个block。假设你把ext4文件系统格式化成4k/block,那么page和block可以一一对应。
/proc/meminfo中的 buffer ram如何计算出?
调用 nr_blockdev_pages(),这个函数会遍历所有原始块设备(list_for_each_entry),把所有原始块设备的inode中的i_mapping , 指向 address_space_operation。包括radix tree管理的pagecache,和 pagecache读写硬盘的硬件操作的接口。nr_pages: page cache中已经命中的page。
page和 bio的关系
所谓的bio,抽象的读写block device的请求,指文件系统的block与内存page的对应。bio要变成实际的block device access还要通过block device driver再排队,并受到ioscheduler的控制。
有时候文件系统格式化block为1k,一次读写page的请求,最终转换成操作多个block。bio为I/O请求提供了一个轻量级的表示方法,内核用一个bio的结构体来描述一次块IO操作。
bio结构体如下:
struct bio {
sector_t bi_sector; /*我们想在块设备的第几个扇区上进行io操作(起始扇区),此处扇区大小是按512计算的*/
struct bio *bi_next;
struct block_device *bi_bdev; /*指向块设备描述符的指针,该io操作是针对哪个块设备的*/
unsigned long bi_rw; /*该io操作是读还是写*/
unsigned short bi_vcnt; /* bio的bio_vec数组中段的数目 */
unsigned short bi_idx; /* bio的bio_vec数组中段的当前索引值 */
unsigned short bi_phys_segments; //合并之后bio中(内存)物理段的数目
unsigned int bi_size; /* 需要传送的字节数 */
bio_end_io_t *bi_end_io; /* bio的I/O操作结束时调用的方法 */
void *bi_private; //通用块层和块设备驱动程序的I/O完成方法使用的指针
unsigned int bi_max_vecs; /* bio的bio vec数组中允许的最大段数 */
atomic_t bi_cnt; /* bio的引用计数器 */
struct bio_vec *bi_io_vec; /*指向bio的bio_vec数组中的段的指针 */
struct bio_set *bi_pool;
struct bio_vec bi_inline_vecs[0];/*一般一个bio就一个段,bi_inline_vecs就可满足,省去了再为bi_io_vec分配空间*/
}
struct bio_vec {
struct page *bv_page; //指向段的页框对应页描述符的指针
unsigned int bv_len; //段的字节长度,长度可以超过一个页
unsigned int bv_offset; //页框中段数据的偏移量
};
一个bio可能有很多个bio段,这些bio段在内存是可能不连续,位于不同的页,但在磁盘上对应的位置是连续的。一般上层构建bio的时候都是只有一个bio段。(新的DMA支持多个不连续内存的数据传输)可以看到bio的段可能指向多个page,而bio也可以在没有buffer_head的情况下构造。
request 和bio的关系
在IO调度器中,上层提交的bio被构造成request结构,每个物理设备会对应一个request_queue,里面顺序存放着相关的request。每个请求包含一个或多个bio结构,bio之间用有序链表连接起来,按bio起始扇区的位置从小到大,而且这些bio之间在磁盘扇区是相邻的,也就是说一个bio的结尾刚好是下一个bio的开头。
通常,通用块层创建一个仅包含一个bio结构的请求,可能存在新bio与请求中已存在的数据物理相邻的情况,就把bio加入该请求,否则用该bio初始化一个新的请求。
buffer 和cache,在linux内核实现上没有区别,在计数上有区别。最后都是 address_space ->radix tree -> read/write pages。
buffer_head: 是内核封装的数据结构。它是内核page与磁盘上物理数据块之间的桥梁。一方面,每个page包含多个buffer_head(一般4个),另外一方面,buffer_head中又记录了底层设备块号信息。这样,通过page->buffer_head->block就能完成数据的读写。
【文章福利】小编推荐自己的Linux内核技术交流群:【865977150】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!
提升技术跳槽涨薪;
Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂ke.qq.com/course/4032547?flowToken=1040236
O_DIRECT 和 O_SYNC
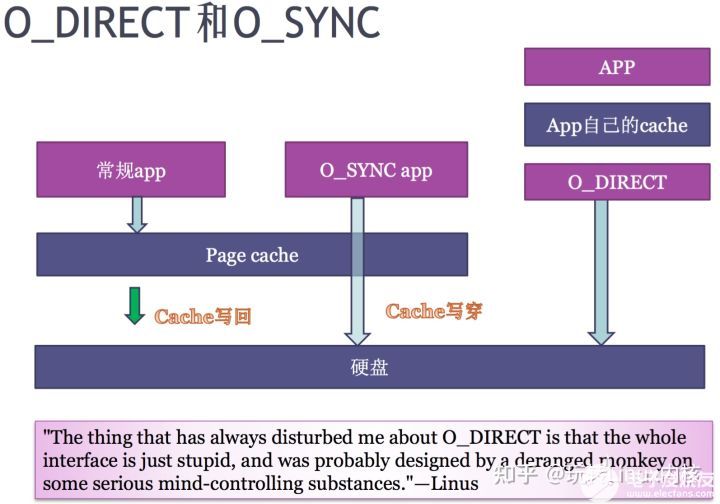
两者区别,O_DIRECT 把一片地址配置成不带cache的空间 , 直接导硬盘 , 而 O_SYNC 类似CPU cache的write through. 当应用程序使用O_SYNC写page cache时,直接写穿到硬盘。当应用程序同时使用O_SYNC和 O_DIRECT,可能会出现page cache的不一致问题。
writeback机制与bdi
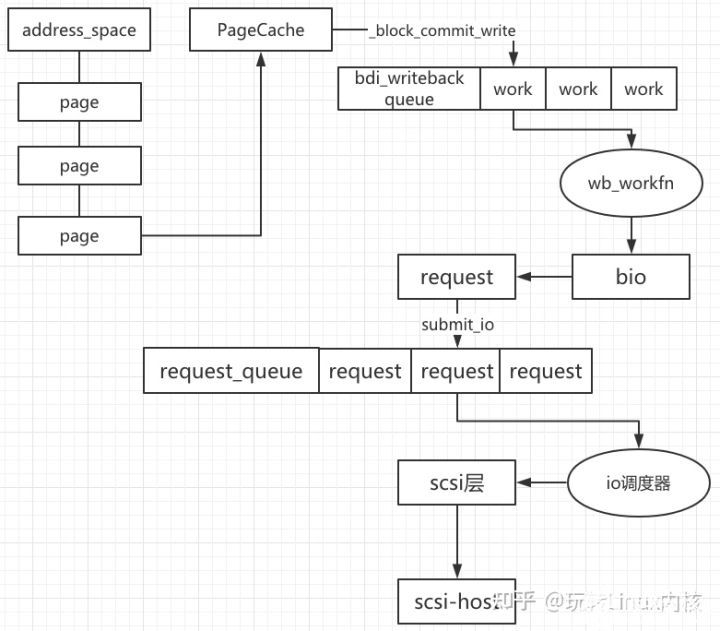
write的过程,把要写的page提交到bdi_writeback 队列中,然后由writeback线程将其真正写到block device上。writeback机制:一方面加快了write()的速度,另一方面便于合并和排序多个write请求。
三进三出讲解bio
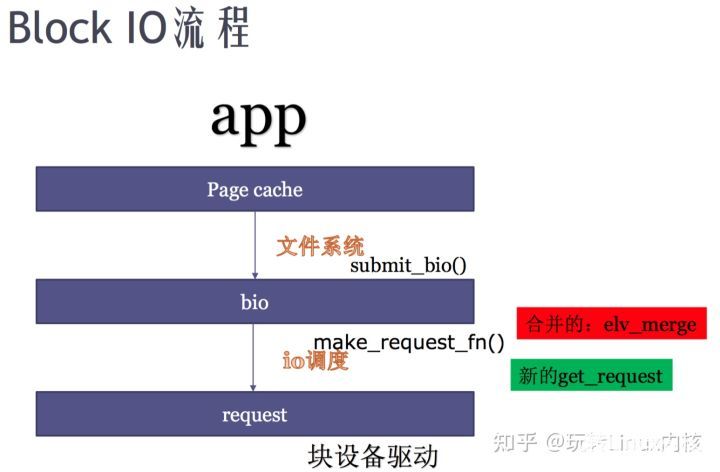
page cache只有通过 address_space_operations里的 write_pages和 read_pages,才能产生对文件系统的block产生IO行为。而不管是directIO还是writeback机制最终都会通过submit_bio方法提交bio到block层。
block io( bio ) : 讲文件系统上哪些block 读到内存哪些 page, 文件系统的 block bitmap 和 inode table,bio是从文件系统解析出来,从block到page之间的关系。
generic_make_request实现中请求构建的关键为 make_request_fn, 该函数的调用链路为:
blk_init_queue() -> blk_init_queue_node() -> blk_init_allocated_queue -> blk_queue_make_request(q, lk_queue_io), 最后被调用执行的回调函数blk_queue_bio实现如下:
page cache和 硬盘数据 通过linux readpages函数关联时,会把文件系统的四个block,转化成4个bio。bio里的指针指向数据在硬盘的位置,也会有把这些数据读出来之后放置到page cache的哪些page。
当一个page对应多个block的情况,一个page 对应几个bio:size(page) > size(block),
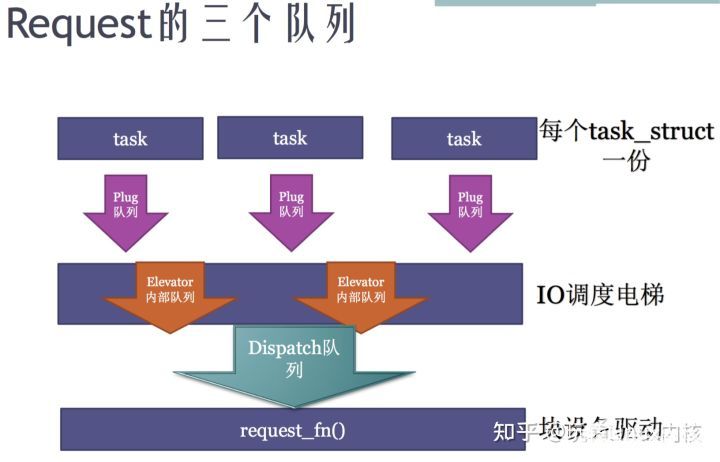
bio --> request每个进程有自己的plug队列,先把bio先发送到plug队列。在plug队列里,把bio转化成request。第一个bio一定是一个request,之后的bio就会查看多个bio是否可以merge到一个request,如果不能合并就产生一个新的request。
bio边发plug队列,边转成request。而这些request 先放到 elevator电梯队列,IO调度电梯做的类似路由器中QoS的功能->限制端口的流量。
deadline调度算法:优先考虑读,认为写不重要。应用程序写到pagecache以后,就已经写完了。
I/O写入流程图
ftrace
vfs_read/vfs_write 慢,到底层操作磁盘差十万八千里。要用ftrace分析,才能知道具体原因。

对于文件读写这种非常复杂的流程,在工程里面可以使用的调试方式是 ftrace。
除了用ftrace工具进行函数级的分析之外,使用blktrace去跟踪整个block io 生命周期,比如什么时候进入plug队列,unplug,什么时候进入电梯调度,什么时候进到驱动队列。
blktrace
apt-get install sleuthkit blktrace
#1:
blktrace -d /dev/sda -o - | blkparse -i - > 1.trace
#2:
root@whale-indextest01-1001:/home/gzzhangyi2015/learningLinuxKernel/io-courses/bio-flow# dd if=read.c of=barry oflag=sync
0+1 records in
0+1 records out
219 bytes (219 B) copied, 0.000854041 s, 256 kB/s
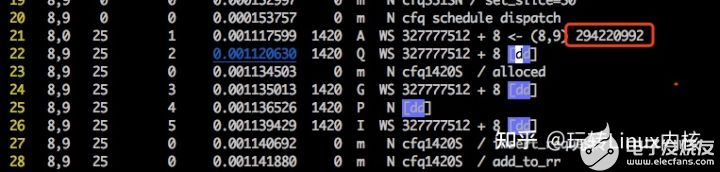
扇区号(294220992)/8 = block号(36777624)
再用debugfs -R 'icheck 块号' /dev/sda9

再用debugfs -R 'ncheck inode' /dev/sda9

再用 blkcat /dev/sda9 块号
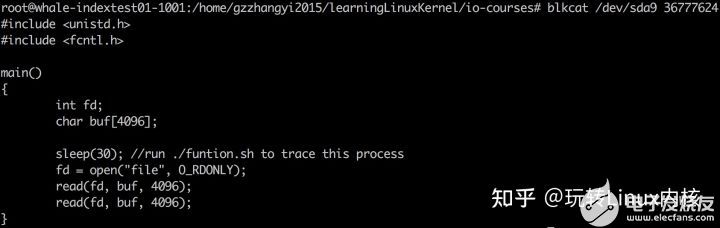
总结:
blktrace 是在内核里关键函数点上加了一些记录,再把记录抓下来。主要是看操作的流程。
ftrace 看 函数的流程。
IO调度 和 CFQ调度算法

主要从 进程优先级 , 流量控制 方面考虑,在通用块层和 I/O调度层 进行限速,限制带宽和 IOPS。
Noop:空操作调度算法,也就是没有任何调度操作,并不对io请求进行排序,仅仅做适当的io合并的一个fifo队列。合并的技术,不太适用于排序。适用于固态硬盘,因为固态硬盘基本上可以随机访问。
CFQ:完全公平队列调度类似进程调度里的CFS,指定进程的nice值。它试图给所有进程提供一个完全公平的IO操作环境。它为每个进程创建一个同步IO调度队列,并默认以时间片和请求数限定的方式分配IO资源,以此保证每个进程的IO资源占用是公平的,cfq还实现了针对进程级别的优先级调度。
CFQ对于IO密集型场景不适用,尤其是IO压力集中在某些进程上的场景。该场景下需要更多满足某个或某几个进程的IO响应速度,而不是让所有的进程公平的使用IO。
此时,deadline调度(最终期限调度)就更适应这样的场景。deadline实现了四个队列,其中两个分别处理正常read和write,按扇区号排序,进行正常io的合并处理以提高吞吐量.因为IO请求可能会集中在某些磁盘位置,这样会导致新来的请求一直被合并,于是可能会有其他磁盘位置的io请求被饿死。
于是,实现了另外两个处理超时read和write的队列,按请求创建时间排序,如果有超时的请求出现,就放进这两个队列,调度算法保证超时(达到最终期限时间)的队列中的请求会优先被处理,防止请求被饿死。由于deadline的特点,无疑在这里无法区分进程,也就不能实现针对进程的io资源控制。
从原理上看,cfq是一种比较通用的调度算法,是一种以进程为出发点考虑的调度算法,保证大家尽量公平。
deadline是一种以提高机械硬盘吞吐量为思考出发点的调度算法,只有当有io请求达到最终期限的时候才进行调度,非常适合业务比较单一并且IO压力比较重的业务,比如数据库。
而noop呢?其实如果我们把我们的思考对象拓展到固态硬盘,那么你就会发现,无论cfq还是deadline,都是针对机械硬盘的结构进行的队列算法调整,而这种调整对于固态硬盘来说,完全没有意义。对于固态硬盘来说,IO调度算法越复杂,效率就越低,因为额外要处理的逻辑越多。
所以,固态硬盘这种场景下,使用noop是最好的,deadline次之,而cfq由于复杂度的原因,无疑效率最低。
CFQ 和 ionice

demo
把linux的IO调度算法改成CFQ,并且运行两个不同IO nice值的进程:
目前的调度算法是 deadline
root@whale-indextest01-1001:/sys/block/sda/queue# cat scheduler
noop [deadline] cfq
root@whale-indextest01-1001:/sys/block/sda/queue# echo cfq > scheduler
root@whale-indextest01-1001:/sys/block/sda/queue# cat scheduler
noop deadline [cfq]
root@whale-indextest01-1001:/sys/block/sda/queue# ionice -c 2 -n 0 cat /dev/sda9 > /dev/null&
[1] 6755
root@whale-indextest01-1001:/sys/block/sda/queue# ionice -c 2 -n 7 cat /dev/sda9 > /dev/null&
[2] 6757
root@whale-indextest01-1001:/sys/block/sda/queue# iotop
cgroup与IO

root@whale-indextest01-1001:/sys/fs/cgroup/blkio# cgexec -g blkio:A dd if=/dev/sda9 of=/dev/null iflag=direct &
[3] 7550
root@whale-indextest01-1001:/sys/fs/cgroup/blkio# cgexec -g blkio:B dd if=/dev/sda9 of=/dev/null iflag=direct &
[4] 7552
IO性能测试
1、rrqm/s & wrqm/s 看io合并: 和/sys/block/sdb/queue/scheduler 设置的io调度算法有关。
2、%util与硬盘设备饱和度: iostat 无法看硬盘设备的饱和度。
3、即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态。
await 是单个I/O所消耗的时间,包括硬盘设备处理I/O的时间和I/O请求在kernel队列中等待的时间.
实际场景根据I/O模式 随机/顺序与否进行判断。如果磁盘阵列的写操作不在一两个毫秒以内就算慢的了;读操作则未必,不在缓存中的数据仍然需要读取物理硬盘,单个小数据块的读取速度跟单盘差不多。
iowait
- %iowait 表示在一个采样周期内有百分之几的时间属于以下情况:CPU空闲、并且有仍未完成的I/O请求。
- %iowait 升高并不能证明等待I/O的进程数量增多了,也不能证明等待I/O的总时间增加了。
- %iowait升高有可能仅仅是cpu空闲时间增加了。
- %iowait 的高低与I/O的多少没有必然关系,而是与I/O的并发度相关。所以,仅凭 %iowait 的上升不能得出I/O负载增加 的结论。
它是一个非常模糊的指标,如果看到 %iowait 升高,还需检查I/O量有没有明显增加,avserv/avwait/avque等指标有没有明显增大,应用有没有感觉变慢。
FAQ:
什么是Bufferd IO/ Direct IO? 如何解释cgroup的blkio对buffered IO是没有限速支持的?
答:这里面的buffer的含义跟内存中buffer cache有概念上的不同。实际上这里Buffered IO的含义,相当于内存中的buffer cache+page cache,就是IO经过缓存的意思。
cgroup针对IO的资源限制实现在了通用块设备层,对哪些IO操作有影响呢? 原则上说都有影响,因为绝大多数数据都是要经过通用块设备层写入存储的,但是对于应用程序来说感受可能不一样。在一般IO的情况下,应用程序很可能很快的就写完了数据(在数据量小于缓存空间的情况下),然后去做其他事情了。这时应用程序感受不到自己被限速了,而内核在处理write-back的阶段,由于没有相关page cache中的inode是属于那个cgroup的信息记录,所以所有的page cache的回写只能放到cgroup的root组中进行限制,而不能在其他cgroup中进行限制,因为root组的cgroup一般是不做限制的。
而在Sync IO和Direct IO的情况下,由于应用程序写的数据是不经过缓存层的,所以能直接感受到速度被限制,一定要等到整个数据按限制好的速度写完或者读完,才能返回。这就是当前cgroup的blkio限制所能起作用的环境限制。












 工商网监
工商网监
评论