 电子发烧友App
电子发烧友App


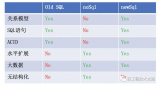
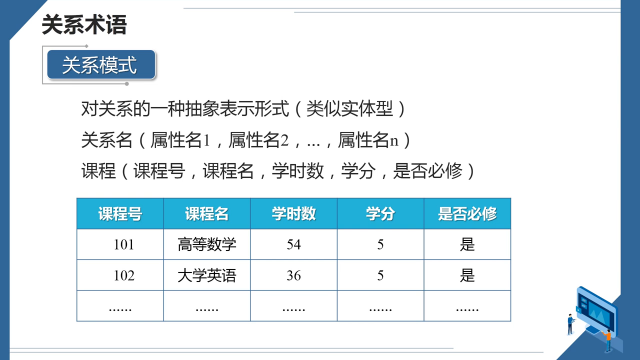
OLAP与OLTP数据库由于关注的业务不同,所以软件在工作方式和优化方法会有一些不同。
OLTP业务主要业务场景是交易记录的准确性,因此需要写入具有唯一性,所以传统针对OLTP数据库的优化方法将负责写入的“一夫”节点性能大幅提升,如使用更快的CPU,增加更多的内存,使用将内存当做磁盘用的傲腾存储,使用IB网络(InfiniBand network)等。
但个体设备的配置提升,会遇到天花板。于是近年来有人提出将数据库进行分库分表,增加写入节点的数量而提升写入能力。通过将数据复制到多个只读节点,提升数据读的能力。
比如对于一个记录用户名数据库,按姓名拼音的第一个字母拆成26个数据库,这样就可以将原来只能由一个库来写,变成分别由26个库来写入,从而提升写入能力。但每个分开的库还是只能有一个写入,还是有种“一夫当关,万夫莫开”的意思。
举个例子说明,柏睿自研的分布式全内存数据库RapidsDB是基于MPP并行计算架构,集群的性能随着节点规模的增加而增加。RapidsDB的技术架构类似于“团体作战”风格,所有的数据库节点都能同时协同战斗,因此提升的性能不是由个体决定的。例如在一个具有5个数据库节点的RapidsDB集群里,用户要导入1000T的数据文件任务,是由5个数据库节点将1000T任务分散同时完成。如果性能不够,再加数据库节点就可以实现性能提升了。
以上分析,仅从技术架构而言,并不能完全说明哪种技术是最好。只有适合业务,才是最好的技术。
审核编辑:符乾江
































































 工商网监
工商网监
评论