A800和H20之间。 根据报道,平头哥PPU采用HBM2e显存,单卡显存容量96GB,片间带宽为700GB/s,采用PCIe5.0×16通道接口,单卡功耗为400W。英伟达A800显存同样采用
2025-09-22 07:02:00 11608
11608 
8月12日,在2025金融AI推理应用落地与发展论坛上,华为公司副总裁、数据存储产品线总裁周越峰宣布,华为此次和银联联合创新,推出AI推理创新技术UCM(推理记忆数据管理其器)和管理系统的算法,这项突破性成果降低对HBM技术的依赖,提升国内AI大模型的推理能力。
2025-08-13 08:58:4910168 
/HBM4有了新进展,SK海力士的HBM4性能更强。同时,DDR4的陆续减产,更多资源投向了DDR5和HBM。 AI服务器带动业绩增长 戴尔科技发布2026财年第一财季(截至2025年5月2日)业绩报告。数据显示,第一财季戴尔营收达233.8亿美元,同比增长5%,non-GAAP下,营业利润为
2025-06-02 06:54:006567 电子发烧友网报道(文/黄晶晶)近几年,生成式AI引领行业变革,AI训练率先崛起,带动高带宽内存HBM一飞冲天。但我们知道AI推理的广泛应用才能推动AI普惠大众。在AI推理方面,业内巨头、初创公司等都
2025-03-03 08:51:572677 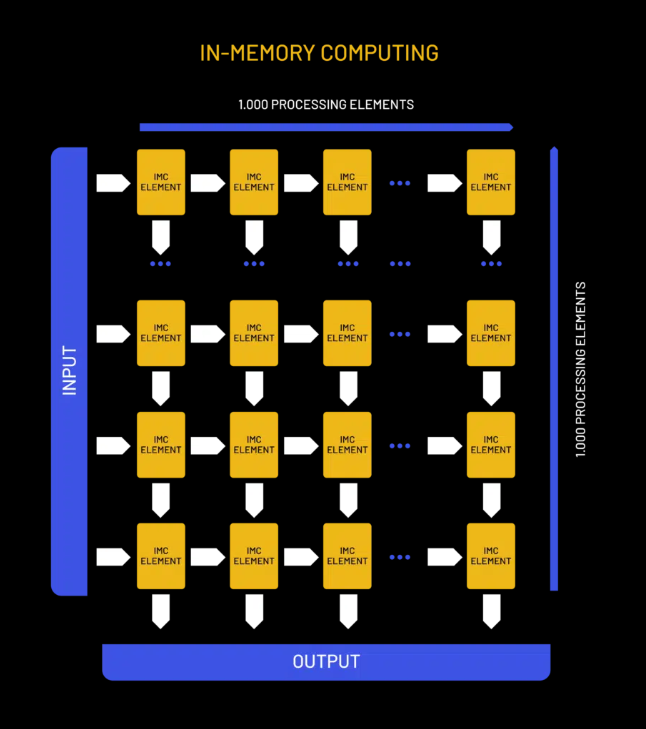
AI(人工智能)极大地增加了物联网边缘的需求。为了满足这种需求,Etron公司推出了世界上第一款扇入式晶圆级封装的DRAM——RPC DRAM®支持高带宽和更小的尺寸。凭借RPC DRAM的性价比和低功耗优势,创新型DRAM是许多可穿戴设备和物联网设备上的微型人工智能相机中使用的理想存储器。
2026-01-05 14:29:3729 ,为开发者提供了一个理想的平台,用于评估RA6E2 MCU组的特性并开发嵌入式系统应用。今天,我们就来深入了解一下这款开发板。 文件下载: Renesas Electronics RA6E2评估套件
2025-12-29 15:15:12119 电子发烧友网报道(文/吴子鹏)在半导体存储行业的常规逻辑中,新一代产品面世前夕,前代产品降价清库存是常规定律,但如今HBM(高带宽内存)将打破这一行业共识。据韩媒最新报道,三星电子和SK海力士已上调
2025-12-28 09:50:111547 使用RA6E2驱动 ESP8266 WiFi模块,调试AT指令。
1. 需求描述
使用RA6E2驱动 esp8266 WiFi模块,用串口调试助手显示 esp8266WiFi模块响应数据。
具体来说
2025-12-25 10:08:37
12月17日,美国存储大厂美光科技公布2026财年第一季度财报(截止11月27日的三个月),受惠于AI数据中心需求爆发,AI服务器对HBM和DDR5强劲需求,美光在2026财年第一季度营收达到136.4亿美元,同比飙升57%,净利润达到52.4亿美元,去年同期34.69亿美元,同比增长49%。
2025-12-18 13:45:0511135 
电子发烧友网综合报道 随着人工智能算力需求的指数级爆发,数据中心对内存的性能、容量与成本平衡提出了前所未有的严苛要求。HBM凭借1024-bit甚至2048-bit的超高位宽,成为AI加速卡的核心
2025-12-17 09:29:551378 基于开放计算标准(OCP OAI/OAM)设计的高密度AI加速器组,通过模块化集成,在单一节点内聚合高达1 PFLOPS(FP16)与2 POPS(INT8)的峰值算力。其配备大容量GDDR6内存
2025-12-14 13:15:111123 
昆仑芯R200加速卡基于7nm XPU-R架构,在150W功耗下提供256 TOPS INT8算力,侧重高性能推理。配备最高32GB GDDR6内存(512GB/s带宽)及108路视频解码能力,支持
2025-12-14 13:12:201255 
昆仑芯K200作为云端AI加速卡,在K100架构基础上全面升级。其INT8算力达256 TOPS,配备16GB HBM内存与512GB/s带宽,专为千亿参数大模型训练与高并发推理优化。采用全高全长双
2025-12-14 11:17:501476 
昆仑芯K100边缘AI加速卡以75W超低功耗实现128 TOPS的INT8算力,重新定义边缘推理能效标准。其半高半长设计搭载8GB HBM内存与256GB/s带宽,支持INT8至FP32多精度计算
2025-12-14 11:12:202500 
超级AI芯片时代,算力突飞猛进,行业日新月异,电子元器件的进化方向是哪里,我们要为此提前做好哪些准备?
2025-12-11 15:13:50553 
和数据传输的要求越来越高。低延迟、高带宽和高吞吐量的数据传输能力成为了关键需求。Amphenol 的 Cool Express Link™ EDSFF E3 2C PCIe® Gen 5/6 电缆连接器
2025-12-11 10:40:02280 在积极配合这一客户需求。从HMB4的加速量产、HBM4E演进到逻辑裸芯片的定制化等HBM技术正在创新中发展。 HBM4 E的 基础裸片 集成内存控制器 外媒报道,台积电在近日的生态论坛上分享了对首代定制 HBM 内存的看法。台积电认为定制HBM将在HBM4E时代正式落地,
2025-11-30 00:31:006422 
我将操作如何在RA6E2微控制器上配置UART通信,通过串口接收字符控制LED灯的开关。
硬件准备
RA6E2开发板
USB连接线
软件配置
1. 创建FSP项目
打开e² studio,创建
2025-11-12 16:23:04
RA6E2是瑞萨电子推出的一款高性能微控制器,适用于工业自动化、物联网设备、消费电子等多种应用场景。该系列芯片基于先进的Arm® Cortex®-M33内核,具备丰富的内存、外设和强大的安全
2025-11-11 19:19:30
自有HBF产品的早期概念设计工作。 图源:闪迪 闪迪HBF SanDisk 闪迪在今年2月份 展示最新研发的高带宽闪存(HBF),这是专为 AI 领域设计的新型存储器架构 。 HBF全称
2025-11-09 06:40:0012401 
和横向扩展问题。Weaver专为克服AI推理工作负载中的内存瓶颈而设计,为下一代数据中心和AI应用提供前所未有的可扩展性、带宽和效率。
2025-11-08 11:01:412158 近期内存市场的涨势令人震惊。行业分析报告显示,2025年第三季度DRAM合约价格同比上涨高达171.8%,这一数字甚至超过了同期黄金的涨幅。有业内观察人士指出,2025年第四季度将标志着 “DRAM牛市” 的真正开始。市场普遍预期,2026年可能会出现更严重的DRAM供应短缺。
2025-11-06 16:46:112708 
嵌入式Linux新手入门:为什么迅为RK3568+迅为资料是黄金组合
2025-11-04 14:05:22341 
本篇使用 RA6E2 的 PWM 输出,来驱动舵机转动,使用 RA6E2 驱动舵机非常方便,只要配置好 GPT PWM 模块,就能轻松实现角度控制。
硬件准备
1、RA6E2 开发板
2、舵机
2025-11-04 00:03:20
相对于HBM、GDDR和DRAM,企业级SSD优势在于弥补了数据供给速度与计算速度之间的巨大鸿沟,特别是全新的CPU、GPU在算力、核心数量、AI吞吐量井喷式的增长,以往的低速存储很容易造成计算单元空转,造成数据饥饿,进而影响到企业的时间与支出成本。
2025-11-03 14:46:151492 
和新应用挑战。无论是CXL与内存扩展技术的落地,还是PCIe 5.0和PCIe 6.0与AI数据密集型应用推动的本地高速存储,都将企业级固态硬盘推向了非常重要角色。存储已经从系统的配套设施,变身成新平台性能释放的关键。 相对于HBM、GDDR和DRAM,企业级SSD优势在于弥补了数据供给速度与计算速
2025-11-03 13:11:17496 三星:明年的 HBM 内存产能已售罄,考虑扩建生产线 据媒体报道,三星考虑扩建高带宽内存(HBM)生产线以提高产能。这家韩国科技巨头周四表示,其明年 HBM 的产能已被预订一空,并正在收到更多订单
2025-11-03 10:48:51924 电子发烧友网为你提供()Skyworks ICE™ 技术 6 GHz Wi-Fi 6E 高效、高功率前端模块相关产品参数、数据手册,更有Skyworks ICE™ 技术 6 GHz Wi-Fi 6E
2025-10-13 18:33:05

了30%,用户平均体验速度提高了25%。更重要的是,AI能够根据用户行为模式进行个性化优化,例如为经常使用视频会议的商务人士提供更高带宽,为游戏玩家提供更低延迟的网络服务。
增强信号处理:让卫星通信
2025-10-11 16:01:17
RA-Eco-RA6E2-64PIN-V1.0是一款基于100MHzArmCortex-M33内核架构的核心板,主控芯片为R7FA6E2BB3CFM。RA6E2组是RA6系列中最新的入门级微控制器
2025-10-01 10:15:03618 
2025年9月24日,美光在2025财年第四季度财报电话会议中确认,第四代高带宽内存(HBM4)将于2026年第二季度量产出货,2026年下半年进入产能爬坡阶段。其送样客户的HBM4产品传输速率突破
2025-09-26 16:42:311181 AI推理芯片和高带宽内存领域的研发,进一步巩固其在AI硬件产业的技术布局,并围绕两大市场空白布局:(1) 端侧大模型原生支持与高效内存调度,(2)端侧HBM模组标准与产业链协同。 微珩科技是一家专注于AI芯片和系统方案设计的高科技企业。 公司致力于研发基于高
2025-09-25 21:35:44535 HBM通过使用3D堆叠技术,将多个DRAM(动态随机存取存储器)芯片堆叠在一起,并通过硅通孔(TSV,Through-Silicon Via)进行连接,从而实现高带宽和低功耗的特点。HBM的应用中,CowoS(Chip on Wafer on Substrate)封装技术是其中一个关键的实现手段。
2025-09-22 10:47:471617 能力
2)内存带宽
3)边缘设备的AI算力
2、架构与形态
1)AGI芯片的基本架构
设计AGI芯片需考虑哪些因素:
①具身智能的大部分功能,是实现从外部环境得到的感知
②把基于大模型的MoE架构引入
2025-09-18 15:31:59
海力士 HBM4 内存的 I/O 接口位宽为 2048-bit,每个针脚带宽达 10Gbps,因此单颗带宽可高达 2.5TB/s。这一里程碑不仅标志着 AI 存储器正式迈入 “2TB/s 带宽时代
2025-09-17 09:29:085964 HBM4 的开发,并在全球首次构建了量产体系,这一消息犹如一颗重磅炸弹,在半导体行业乃至整个科技领域激起千层浪。 高带宽存储器(HBM)作为一种能够实现高速、宽带宽数据传输的下一代 DRAM 技术,自诞生以来便备受瞩目。其核心结构是将多个 DRAM 芯片通过
2025-09-16 17:31:141367 AI的应用多种多样。比如:DALL-E2、Midjourney、Stable Diffusion等,不仅包括对话功能,还包括生成图像、视频、语音和程序代码等功能。
竟然连代码都可以生成,会取代程序员
2025-09-12 16:07:57
常言道,金九银十,金秋是企业冲刺业绩、迎接高峰的黄金期。订单激增、流量暴涨、数据处理需求呈指数级增长。您的企业IT系统,是否做好准备?
2025-09-08 09:05:35812 开发并已经做好大规模量产的准备。 据悉,Exynos 2600芯片采用1+3+6设计,共计有10个核心,其中1颗超大核主频是3.8GHz,3颗性能核心主频是3.26GHz,还有6颗能效核心主频
2025-09-04 17:52:152150 AI 内存是一种专为人工智能 (AI) 应用设计的新型内存技术。与传统的通用内存(如 DDR5 或 LPDDR5)不同,AI 内存的核心目标是解决 AI 计算中遇到的两大挑战:带宽瓶颈和延迟
2025-09-03 15:44:19966 Cat6e并非国际或国家标准中定义的正规超六类网线,其身份存在争议,需结合具体场景分析: 一、标准定义:Cat6e并非官方超六类 国际标准缺失 超六类网线的国际标准为 TIA/EIA-568-C.2
2025-09-02 10:07:282646 本文将探讨内存技术的最新突破、AI 应用日益增长的影响力,以及华邦如何透过策略性布局响应市场不断变化的需求。
2025-08-28 11:17:044320 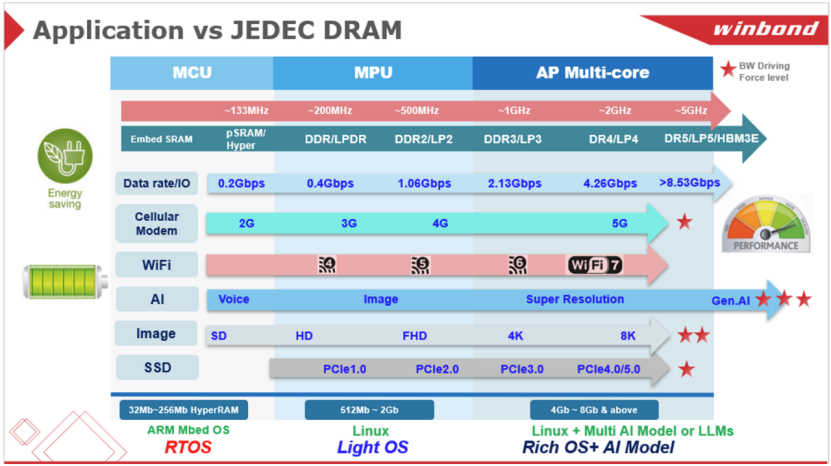
"后的下一代AI GPU "Feynman"。 有分析指出,英伟达此举或是将部分GPU功能集成到基础裸片中,旨在提高HBM和GPU的整体性能。英伟达会将UCIe接口集成到HBM4中,以实现GPU
2025-08-21 08:16:002604 电子发烧友网综合报道,NEO Semiconductor宣布推出全球首款用于AI芯片的超高带宽内存 (X-HBM) 架构。该架构旨在满足生成式AI和高性能计算日益增长的需求,其32Kbit数据总线
2025-08-16 07:51:004694 
要求,并探索构建HBF的技术生态系统。 高带宽闪存(HBF)是一种专为 AI 领域设计的新型存储器架构。在设计上,HBF结合了3D NAND闪存和高带宽存储器(HBM)的特性,能更好地满足AI推理
2025-08-15 09:23:123385 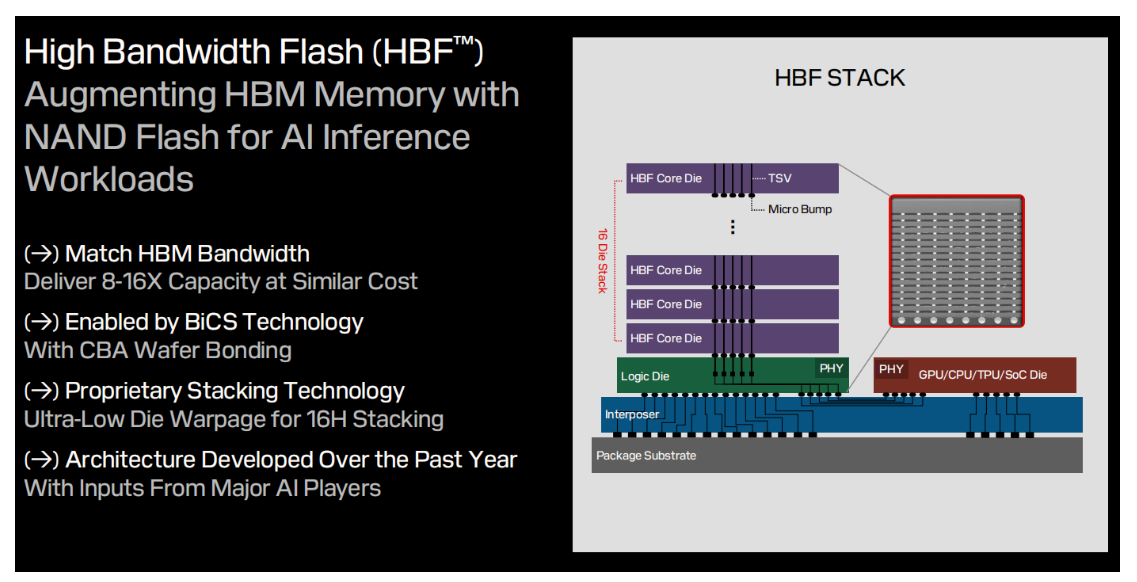
电子发烧友网综合报道,据韩媒报道,下一代低功耗内存模块 “SOCAMM” 市场已全面拉开帷幕。英伟达作为 AI 领域的领军企业,计划在今年为其 AI产品部署60至80万个 SOCAMM 内存模块
2025-07-27 07:50:004448 在当今科技飞速发展的时代,人工智能、大数据分析、云计算以及高端图形处理等领域对高速、高带宽存储的需求呈现出爆炸式增长。这种背景下,高带宽内存(High Bandwidth Memory,HBM)技术
2025-07-24 17:31:16632 
)将多层 DRAM 芯片垂直堆叠,并集成专用控制器逻辑芯片,形成一个紧凑的存储模块。这种架构彻底打破了传统 DDR 内存的平面布局限制,实现了超高带宽、低功耗和小体积高集成度的完美结合,成为支撑 AI、高性能计算(HPC)和高端图形处理的核心存储技术。
2025-07-18 14:30:122952 。近日著名博主《数码闲聊站》又继续爆料,华为会先于苹果落地HBM DRAM。 但HBM在手机应用真的可行吗? 从成本的角度来看,HBM首先在制造工艺上相比传统的LPDDR更复杂。为了实现高带宽
2025-07-13 06:09:006875 明年。目前博通凭借自有半导体设计能力,正为谷歌代工第七代TPU"Ironwood"及Meta自研AI芯片"MTIA v3"。 此外,三星电子也积极推进向亚马逊云服务(AWS)供应HBM3E 12层产品,近期已在平泽园区启动实地审核。AWS计划明年量产搭载该存储器的下一代AI芯
2025-07-12 00:16:003465 DDR内存占据主导地位。全球DDR内存市场正经历一场前所未有的价格风暴。由于原厂加速退出DDR3/DDR4市场,转向DDR5和HBM(高带宽内存)生产,DDR3和DDR4市场呈现供不应求、供需失衡、涨势延续的局面。未来,DDR5渗透率将呈现快速提升,市场份额增长的趋势。
2025-06-25 11:21:152013 
一站式PCBA加工厂家今天为大家讲讲PCBA贴片加工前的准备工作有哪些?PCBA贴片加工前的准备工作。在PCBA代工过程中,贴片加工前的准备工作是确保电路板性能稳定和生产效率高的基础。每个环节都需要
2025-06-25 09:23:55535 
当前,生成式AI(GenAI)的能力正以约每六个月翻倍的速度迭代,但多数企业的应用进展仍停留在缓慢的线性增长中,甚至还在观望。这种差距导致企业逐渐落后,无法释放AI带来的巨大商业价值。哈佛商学院教授
2025-06-18 23:10:46688 
SK海力士在巩固其面向AI的存储器领域领导地位方面,HBM1无疑发挥了决定性作用。无论是率先开发出全球首款最高性能的HBM,还是确立并保持其在面向AI的存储器市场的领先地位,这些成就的背后皆源于SK海力士秉持的“一个团队”协作精神(One Team Spirit)。
2025-06-18 15:31:021666 1. 三星向博通供应HBM3E 芯片,重夺AI 芯片市场地位 据韩媒报道,三星电子将向博通供应第五代高带宽内存(HBM3E),继AMD之后再获大单。据业内消息人士透露,三星电子已完成博
2025-06-18 10:50:381699 随着数据中心对AI训练与推理工作负载需求的持续增长,高性能内存的重要性达到历史新高。Micron Technology Inc.(美光科技股份有限公司,纳斯达克股票代码:MU)宣布已向多家主要客户送样其12层堆叠36GB HBM4内存。
2025-06-18 09:41:531323 STM32N6用cube AI部署模型的时候,用n6-allmems-O3之后analyse得到了RAM和FLASH的内存占用,这里展示的内存占用都是指的是芯片内部的存储器吗
2025-06-09 06:19:56
STM32N6用cube AI部署模型的时候,用n6-allmems-O3之后analyse得到了RAM和FLASH的内存占用,这里展示的内存占用都是指的是芯片内部的存储器吗
2025-06-03 12:13:27
近日,Cadence(NASDAQ:CDNS)近日宣布推出业界速度最快的 HBM4 12.8Gbps 内存 IP 解决方案,以满足新一代 AI 训练和 HPC 硬件系统对 SoC 日益增长的内存带宽
2025-05-26 10:45:261307 参数规模达数百亿甚至万亿级别,带来巨大内存需求,但HBM内存价格高昂,只应用在高端算力卡上。SOCAMM则有望应用于AI服务器、高性能计算、AI PC以及其他如游戏、图形设计、虚拟现实等领域。 SOCAMM利用高I/O密度和先进封装实现极高带宽,有694个I/O端口,远超传统内存模块(如DD
2025-05-17 01:15:003733 AI 模型规模的爆炸式增长促使业内对低延迟内存带宽和容量的需求出现激增。Celestial AI 一直在与多家大型服务商合作,以深入探究运算、内存和网络系统基础架构的瓶颈
2025-05-15 19:15:181045 业内对于更大内存带宽的需求,能适应企业和数据中心应用中前沿的 AI 处理需求,包括云端 AI。Cadence DDR5 MRDIMM IP 基于 Cadence 经过验证且非常成功的 DDR5
2025-05-09 16:37:44905 STM32N6用cube AI部署模型的时候,用n6-allmems-O3之后analyse得到了RAM和FLASH的内存占用,这里展示的内存占用都是指的是芯片内部的存储器吗
2025-04-28 08:25:15
随着人工智能技术的迅猛发展,作为其核心支撑技术的高带宽存储器(以下简称HBM)实现了显著的增长,为SK海力士在去年实创下历史最佳业绩做出了不可或缺的重要贡献。业内普遍认为,SK海力士的成长不仅体现在销售额的大幅提升上,更彰显了其在引领AI时代技术变革方面所发挥的重要作用。
2025-04-18 09:25:59993 客户对HBM的要求为增加带宽、提高功率效率、提高集成度。混合键合就是可以满足此类需求的技术。 混合键合技术预计不仅可应用于HBM,还可应用于3D DRAM和NAND Flash。SK海力士副总裁姜志浩(音译)表示,“目前的做法是分别创建DRAM单元区域和外围区域,
2025-04-17 00:05:001060 与 8-DIMM CXL AIC扩充卡,建构更完整的产品组合,持续展现公司提供高品质、高兼容性内存解决方案的承诺。 全新E3.S 2T CMM 内存模块采用 CXL® 2.0 标准,搭载 PCIe Gen5 x8 接口并支持高
2025-04-16 10:54:04759 。 Cat6e:非国际标准,为部分厂商的命名方式,标识为“Cat6e”,缺乏统一规范。 2. 性能参数 传输速率:两者均支持10Gbps传输速率,但Cat6a理论性能更优。 频率带宽:均为500MHz,远高于
2025-04-15 11:14:459293 年1月,国内头部电商平台AI玩具销量环比激增6倍,预计到2033年,全球市场规模将达到600亿美元,其中亚洲市场将占主导地位。 AI玩具是否真如市场所言机会巨大,遍地黄金?其真实情况到底如何?为此,电子发烧友网采访到了天浪创新科技(深圳)有限公
2025-04-15 09:02:122581 
该系列教程前面几篇文章都是为开发做准备,本文正式进入开发阶段,基于 e2 studio 创建RA8工程,并点亮一个LED。
2025-04-03 17:14:59866 
数据中心依赖数千甚至上万个GPU集群进行高性能计算,对带宽、延迟和数据交换效率提出极高要求。
AI云:以生成式AI为核心的云平台,为多租户环境提供推理服务。这类数据中心要求网络具备高带宽、稳定性
2025-03-25 17:35:05
近年来随着人工智能浪潮的兴起,数据中心和服务器市场对于内存性能的要求达到了前所未有的高度。HBM(高带宽内存)凭借其卓越的性能优势,如高带宽、低功耗、高集成度和灵活的架构,成为了这一领域的“香饽饽”,炙手可热。
2025-03-25 17:26:275227 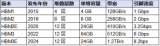
是否有必要将Cat5e网线升级为Cat6,需结合您的实际使用需求、未来规划及预算综合判断。以下是详细分析,帮助您做出决策: 一、性能对比:Cat6显著优于Cat5e 关键差异: Cat6的带宽
2025-03-25 10:01:101604 
在这样的背景下,高带宽存储器(HBM)技术应运而生,以其独特的3D堆叠架构和TSV(硅通孔)技术,为内存芯片行业带来了前所未有的创新。
2025-03-22 10:14:143658 
电子发烧友网为你提供AIPULNION(AIPULNION)PFD6-18D18E2(C)3相关产品参数、数据手册,更有PFD6-18D18E2(C)3的引脚图、接线图、封装手册、中文资料、英文资料,PFD6-18D18E2(C)3真值表,PFD6-18D18E2(C)3管脚等资料,希望可以帮助到广大的电子工程师们。
2025-03-20 18:47:37

电子发烧友网为你提供AIPULNION(AIPULNION)DD6-36E0524G9N2相关产品参数、数据手册,更有DD6-36E0524G9N2的引脚图、接线图、封装手册、中文资料、英文资料,DD6-36E0524G9N2真值表,DD6-36E0524G9N2管脚等资料,希望可以帮助到广大的电子工程师们。
2025-03-20 18:46:45
电子发烧友网为你提供AIPULNION(AIPULNION)DD6-05S24E3C2相关产品参数、数据手册,更有DD6-05S24E3C2的引脚图、接线图、封装手册、中文资料、英文资料,DD6-05S24E3C2真值表,DD6-05S24E3C2管脚等资料,希望可以帮助到广大的电子工程师们。
2025-03-20 18:46:03
电子发烧友网为你提供AIPULNION(AIPULNION)FK6-36S24E2C3相关产品参数、数据手册,更有FK6-36S24E2C3的引脚图、接线图、封装手册、中文资料、英文资料,FK6-36S24E2C3真值表,FK6-36S24E2C3管脚等资料,希望可以帮助到广大的电子工程师们。
2025-03-20 18:41:28
电子发烧友网为你提供AIPULNION(AIPULNION)FK6-18D18E2C3相关产品参数、数据手册,更有FK6-18D18E2C3的引脚图、接线图、封装手册、中文资料、英文资料,FK6-18D18E2C3真值表,FK6-18D18E2C3管脚等资料,希望可以帮助到广大的电子工程师们。
2025-03-20 18:40:27
RZ/V2N——近期在嵌入式世界2025上新发布,为 AI 计算、嵌入式系统及工自动化提供强大支持。这款全新的计算平台旨在满足开发者和企业用户对高性能、低功耗和灵活扩展的需求。
[]()
领先的计算
2025-03-19 17:54:41
物联网技术的快速发展对无线连接提出了更高的要求,而Synaptics推出的SYN43756E芯片正是为满足这些需求而设计的一款高性能Wi-Fi 6E解决方案。它不仅支持多频段通信,还具备低功耗、高
2025-03-18 15:11:21
模组技术,是由英伟达主导研发的面向AI计算、HPC、数据中心等领域的高密度内存解决方案,旨在通过紧凑的设计实现最大化存储容量,保持极佳的性能,并使用可拆卸的设计,便于用户可以对内存模块灵活进行升级和更换。 在CES2025上,英伟达推出的紧凑型超算Project DIGITS,就有望将
2025-02-19 09:06:553216 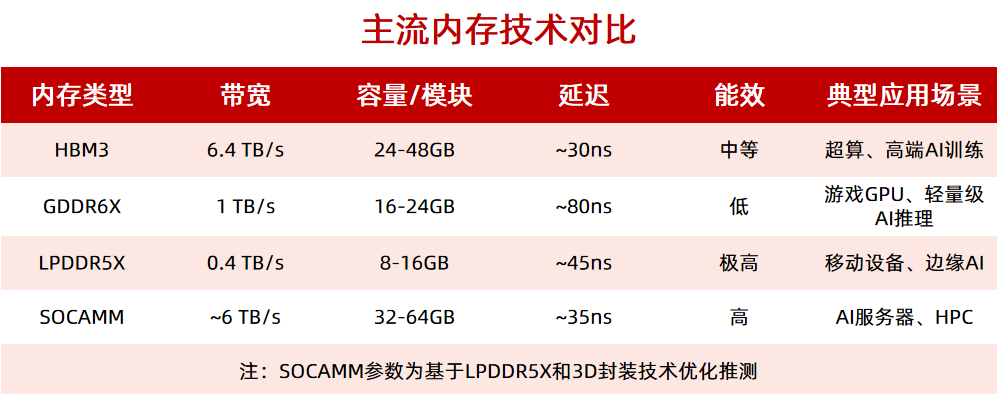
NAND闪存和高带宽存储器(HBM)的特性,能更好地满足AI推理的需求。 HBF的堆叠设计类似于HBM,通过硅通孔(TSVs)将多个高性能闪存核心芯片堆叠,连接到可并行访问闪存子阵列的逻辑芯片上。也就是基于 SanDisk的 BICS 3D NAND 技术,采用CMOS直接键合到阵列(CBA)设计,将3D NA
2025-02-19 00:51:004567 
近日,美光科技宣布即将开始量产其最新的12层堆栈高带宽内存(HBM),并将这一高性能产品供应给领先的AI半导体公司英伟达。这一消息的发布,标志着美光在HBM技术领域的又一次重大突破。
2025-02-18 14:51:191266 据韩媒报道,SK海力士计划于今年3月向其位于韩国的M15X晶圆厂派遣大量工程师,为该厂投产高频宽内存(HBM)做最后准备。这一举措标志着M15X晶圆厂投产的准备工作已进入冲刺阶段,预计将于2025年第四季度正式投产。
2025-02-18 14:46:031276 其高带宽存储器HBM3E产品中的初始缺陷问题,并就三星第五代HBM3E产品向英伟达供应的相关事宜进行了深入讨论。 此次高层会晤引发了外界的广泛关注。据推测,三星8层HBM3E产品的质量认证工作已接近尾声,这标志着三星即将正式迈入英伟达的HBM供应链。对于三星而言
2025-02-18 11:00:38979 MT53E1G32D2FW-046 AAT:B是一款高性能的DDR4 SDRAM内存芯片,由MICRON制造,专为满足现代电子设备对高速内存的需求而设计。该产品具备出色的存储性能和能效,适用于多种
2025-02-14 07:39:58
HMCG78AEBRA是一款高性能的16GB DDR5 4800 RDIMM内存条,专为需要高带宽和高效能的应用而设计。这款内存条采用288-Pin RDIMM封装,支持1.1V低电压运行,能够有效
2025-02-14 07:17:55
据韩国媒体报道,三星电子正面临其第六代1cnm DRAM的良品率挑战,为确保HBM4内存的顺利量产,公司决定对设计进行重大调整。
2025-02-13 16:42:511340 三星电子在近期举行的业绩电话会议中,透露了其高带宽内存(HBM)的最新发展动态。据悉,该公司的第五代HBM3E产品已在2024年第三季度实现大规模生产和销售,并在第四季度成功向多家GPU厂商及数据中心供货。与上一代HBM3相比,HBM3E的销售额实现了显著增长。
2025-02-06 17:59:001106 FCore2S硬件原理图_E6
2025-01-24 09:56:22 2
2 在刚刚过去的一年,以人工智能为代表的全球科技再次呈现出产品技术井喷的状态,以高性能加速器芯片、高带宽HBM内存为代表的计算核心单元受到市场的广泛关注,然而随着GPT-5、视频类AIGC、AGI为代表
2025-01-22 09:26:59780 
2024年作为AIPC元年伴随异构算力(CPU+GPU+NPU)需求高涨及新处理器平台推出DDR5内存以高速率、大容量低延迟与高带宽有效满足高性能算力要求加速本地AI大模型运行效率推动AIPC硬件端
2025-01-21 16:34:412426 
本实验将为您介绍如何在e2 studio中使用Reality AI相关组件来进行AI开发,主要涉及如何使用Reality AI Data shipper/collector,Reality AI
2025-01-21 13:48:011892 
领域迈出了重要一步。16-Hi HBM3E内存以其高带宽、低功耗的特性,在数据中心、人工智能、机器学习等领域具有广泛的应用前景。随着技术的不断进步,市场对高性能内存的需求日益增加,美光的加入无疑将加剧市场竞争,推动整个行业的进步。 据了解,美光此次
2025-01-17 14:14:12913 ;3MHZ了?最后做好的东西使用不同频率、1mV的正弦波激励测试频带宽度,按照-3dB衰减算出来实际频带只有0.05-75HZ,其中0.05的高通滤波使用FIR数字滤波实现。请问为什么测出的上限频率这么窄呢
2025-01-16 06:13:39
光在亚洲地区的进一步布局和扩张。 据美光方面介绍,该工厂将采用最先进的封装技术,致力于提升HBM内存的产能和质量。随着AI芯片行业的迅猛发展,HBM内存的需求也在不断增长。为了满足这一市场需求,美光决定在新加坡建设这座先进的封装工
2025-01-09 16:02:581154 IBM 商业价值研究院(IBV)与牛津经济研究院在 2024年 10月和 11月对 17个行业、6个地区的 400名全球商业领导进行的调研,了解企业必须克服哪些挑战才能在 AI 塑造的竞争格局当中取胜;如何帮助员工做好准备,用以人为本的AI来推动变革,以及期待通过哪些机会来加速 AI 创新等。
2025-01-08 09:44:031286 SK海力士今年计划大幅提升其高带宽内存(HBM)的DRAM产能,目标是将每月产能从去年的10万片增加至17万片,这一增幅达到了70%。此举被视为该公司对除最大客户英伟达外,其他领先人工智能(AI)芯片公司需求激增的积极回应。
2025-01-07 16:39:091306 Android 正在不断发展,以提供更快速、性能更佳的用户体验。其中一项关键改进是使用了 16 KB 的内存页面大小。这一变化使得操作系统能够更高效地管理内存,从而为应用和游戏带来显著的性能提升
2025-01-07 09:26:032206
 电子发烧友App
电子发烧友App








 工商网监
工商网监
评论