 电子发烧友App
电子发烧友App


编者注:欢迎来到 AspenCore 的嵌入式人工智能 (AI) 特别项目。本文连同最后一页列出的文章,从多个角度深入探讨了在嵌入式系统中注入本地化 AI 的业务和技术。
作者:Gina Roos,电子产品总编
开发人员和系统设计人员可以通过多种方式为他们的嵌入式设计添加某种形式的神经网络或深度学习功能。早期——甚至在今天——设计师已经成功地使用了图形处理单元 (GPU) 和现场可编程门阵列 (FGPA),这两者都很好地满足了深度学习的内存密集型需求。甚至传统的 x86 CPU 也已进入 AI 应用程序。
许多开发人员发现这些现有技术并不总是最合适的。因此,在过去几年中, 许多初创公司(以及成熟的芯片制造商)都专注于构建专门用于 AI 应用的芯片。这些芯片从头开始构建,以满足人工智能算法和运行应用程序的计算能力需求。
需要注意的是,用于 SoC 的 IP 模块是提供神经网络功能的另一种选择,但那是另一回事了。该领域的供应商包括Cadence、Ceva、NXP、Synopsys和VeriSilicon。
但与所有技术一样,每种解决方案都有优势和权衡。总体而言,设计人员需要根据其特定的最终应用选择最佳技术。人工智能芯片通常分为三个关键应用领域——云端训练、云端推理和边缘推理。
训练中的大炮是Nvidia 的 GPU,它已成为训练机器学习算法的热门选择。这个过程分析数以万亿计的数据样本。这里的一大优势是 GPU 的并行计算架构。
云上的推理解决了许多人工智能应用程序的机器学习模型,这些应用程序的计算过于密集,无法部署在边缘设备上。可以提供低延迟和处理计算密集型任务的 FPGA 等处理器在这些应用中具有优势。由于并非所有 AI 功能的计算任务都可以在云上完成,因此现有和初创公司的芯片制造商正在开发自己的 AI 芯片并将 AI 功能添加到他们的处理器中。

那么,设计师在涉足人工智能领域之前首先需要回答的问题是什么?我与BabbleLabs Inc的首席执行官、硅谷企业家和技术专家 Chris Rowen 进行了交谈。 和Cognite Ventures,以获得一些答案。
问题 1:了解您的最终应用要求
在开始任何设计时,第一个问题始终是您的最终应用程序要求是什么。紧随其后的是“我有一个特定的任务吗?” 有时这很清楚,Rowen 说。“如果我是一名构建安全摄像头的系统设计师,我会非常关心芯片在视频流的横截面运行方面的表现——对象检测、对象识别、对象跟踪等——少数几个与该最终应用程序特别相关的任务。”
下一个问题是应用程序是在云中运行还是在边缘设备中运行。这将推动设计人员在他们应该考虑的芯片方面走向不同的方向。
“最终应用显然很重要,”Rowen 说。“如果它在云中,问题将是,'它是用于训练神经网络还是仅用于推理?' ——运行一个先前训练过的网络。如果它在边缘,您想要运行的特定应用程序集是什么?”
Rowen 表示,大多数新芯片都是为边缘视觉应用而制造的,这些芯片主要用于推理应用,用于一种或另一种成像或视频分析。一个越来越重要的子类别是音频,尤其是语音处理。
所以它首先归结为云与边缘。那么在云中,是训练还是推理?在边缘,它是通用的(应用程序未知)还是视觉或其他一些特殊的应用程序,如语音处理?
问题二:软件支持
软件工具也有助于区分不同的芯片。“如果它是一个训练芯片,它是否支持各种训练环境——TensorFlow、PyTorch等——因为应用程序和软件开发团队使用了许多重要的训练环境,”Rowen 说。他说,Nvidia 是当今训练芯片的黄金标准和主要供应商。
“在推理方面,这是一个问题,即你能在多大程度上采用预先训练的模型并将其映射到芯片的特定特性。当有像神经网络交换格式这样的标准时,这是一个更容易的问题。” NNEF 是由Khronos Group推动的标准,旨在使映射工具的标准化变得更加容易。
“通常,与将应用程序映射到某些新处理引擎所涉及的所有其他软件相比,这些神经网络的复杂性并不高,”Rowen 解释说。“即使工具并不完美,人们通常也可以找到一种方法,使用不太复杂的工具将现有神经网络映射到视觉芯片或音频芯片或任何边缘处理芯片上。”
在软件扮演的核心角色不那么重要的情况下——即使它确实扮演了关键角色——设计人员应该在硬件层面考虑价格、性能和能效,这会带来下一组问题。
问题 3:内存要求
任何芯片选择的长期问题都围绕着成本和性能。而对于神经网络,什么是片上内存,芯片提供多少内存带宽?
“其中一些神经网络问题非常耗费内存,”Rowen 说。“当然,通常在云中进行的训练过程非常占用内存,需要大量的片上内存和非常高的内存带宽。”
他补充说,推理过程通常占用更少的内存,并且可能不需要大量的片外带宽,具体取决于目标应用程序。
所以这是挑战。区分为通用用途和特定应用而构建的芯片的一件事是,芯片设计人员是否已将大量资源分配给片上存储器和片外存储器带宽。但是,如果设计人员不知道他们需要运行哪些应用程序,他们可能需要在内存带宽方面过度配置,这会使其成本更高。
“过度配置会增加成本,这就是为什么通用芯片几乎总是比专用芯片贵——因为他们必须购买更大的保险单,”罗文说。权衡可以包括成本、功率和物理足迹。
Rowen 表示,如果设计人员能够稍微缩小要求,以使成本更低、功耗更低的芯片适合应用,那么系统级性能就会有很大提升。“通用和专用[芯片]之间的差异可能是一个数量级。”
问题 4:性能——延迟与吞吐量
性能的最终定义是芯片在神经网络应用程序中的运行速度。这里的两个相关指标是吞吐量和延迟——系统是针对增加吞吐量进行优化还是针对减少延迟进行优化。
Rowen 说,在云中,重点通常是吞吐量,而延迟在实时边缘系统中往往非常重要。例如,如果您正在为自动驾驶应用程序构建芯片,则延迟更为重要,并且是一个关键的安全问题,他补充道。
“幸运的是,对于这些神经网络应用中的许多应用来说,所提供的性能和芯片的倍增率之间存在很强的相关性,”Rowen 解释说。“计算资源的充分利用程度存在一些差异,但在最简单的层面上,只需询问‘在给定分辨率下每秒有多少乘法累加’或‘每瓦特有多少乘法累加’芯片确实是一个很好的关于芯片能力的粗略指南。”
今天,总的来说,GPU 是云中神经网络训练的主导力量,而普通 x86 处理器是云中最常见的推理平台,因为它们可以灵活地运行包含深度学习元素和Rowen 说,单个处理器上的传统软件元素。
在大多数情况下,边缘没有太多的训练。他补充说,它通常专注于推理,通常用于视频或音频等特定用例。
Rowen 向 Electronic Products 提供了一些芯片(来自初创公司和现有平台)的应用定位的粗略评估。“有一种趋势是,面向云的芯片更加通用,而面向边缘的芯片更加专业化。”
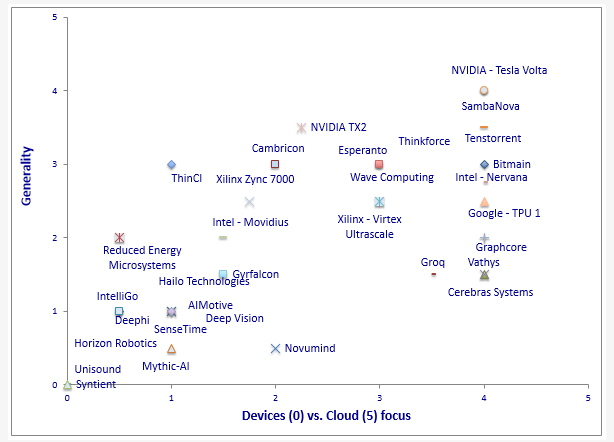
在 x 轴上:0 表示最适合边缘设备(汽车、电话、物联网);5 表示最适合云。在 y 轴上:0 表示专门针对神经网络,尤其是神经网络推理;5 表示通用、跨越神经网络推理、训练和其他非神经网络(但计算密集型)应用程序。图片来源:Cognite Ventures LLC。
以下是一些人工智能增强芯片和平台的快照,它们暗示了当今市场上跨移动和企业应用程序的各种神经网络解决方案:
Gyrfalcon 的 Lightspeeur AI 芯片:初创公司 Gyrfalcon Technology Inc. 吹捧一种超低功耗和高性能的 AI 芯片。Lightspeeur 2801S智能矩阵处理器基于以内存为AI处理单元的APiM架构。“这消除了导致高功耗的巨大数据移动,实现了 9.3 TOPS [每秒万亿次操作]/瓦特的卓越能效,”该公司表示。“该架构具有真正的片上并行性、原位计算,并消除了内存瓶颈。它有大约 28,000 个并行计算核心,并且不需要外部存储器来进行 AI 推理。”
该公司声称算术逻辑单元 (ALU) 的使用效率为 77%,运行卷积神经网络 (CNN) 的效率更高。
提供交钥匙参考设计,包括用于 USB 加密狗、多芯片板和系统开发套件的参考设计。目标应用包括移动边缘计算、基于人工智能的物联网、消费便携式设备、智能监控视频、AR/VR产品、人脸检测/识别、自然语言处理、支持深度学习的设备、人工智能数据中心服务器和自动驾驶。
华为麒麟970:华为消费者业务集团首个移动AI计算平台,具有专用神经处理单元(NPU),将云AI与原生AI处理相结合。麒麟970由八核 CPU 和新一代 12 核 GPU 组成。
华为表示:“与四核 Cortex-A73 CPU 集群相比,麒麟 970 的全新异构计算架构可提供高达 25 倍的性能和 50 倍的效率提升。” 翻译:芯片组以更低的功耗更快地交付相同的人工智能计算任务。基准图像识别测试表明,麒麟 970 每分钟处理 2,000 张图像。
除了在自己的手机中使用新的人工智能芯片组外,华为还将移动人工智能定位为一个开放平台,为开发者和合作伙伴提供技术。
英特尔的 Nervana 神经网络处理器 (NPP):去年年底推出的 Nervana NNP 号称是业界首款用于神经网络处理的芯片,历时三年。专为深度学习而构建的英特尔 Nervana NNP 没有标准的缓存层次结构,片上内存由软件管理。英特尔表示:“更好的内存管理使芯片能够对每个芯片上的大量计算实现高水平的利用。” “这意味着为深度学习模型实现更快的训练时间。”
除了新的内存架构之外,英特尔还开发了一种新的数字格式 Flexpoint,它显着提高了芯片的并行度,同时降低了每次计算的功率。英特尔表示,由于单芯片上的神经网络计算在很大程度上受到功率和内存带宽的限制,因此 Flexpoint 为神经网络工作负载提供了更高程度的吞吐量。英特尔新设计的目标是“实现高计算利用率并通过多芯片互连支持真正的模型并行性”。
英特尔的 Movidius VPU:英特尔正与微软合作,将Microsoft Windows ML 与英特尔的 Movidius 视觉处理单元 (VPU)相结合,在边缘实现人工智能推理。作为用于加速边缘人工智能工作负载的专用芯片,英特尔Movidius Myriad X VPU 声称是业界首款配备专用神经计算引擎的片上系统,用于边缘深度学习推理的硬件加速。英特尔表示:“这款第三代 VPU 专门设计用于以高速和低功耗运行深度神经网络,以减轻特定 AI 任务的负担。”
英特尔还继续针对通用机器学习和推理工作负载优化其至强可扩展处理器和数据中心加速器。
MediaTek Inc. 的 NeuroPilot AI 平台:NeuroPilot 平台专为 AI 边缘计算而设计,提供硬件和软件的组合、一个 AI 处理单元和 NeuroPilot 软件开发套件 (SDK)。它支持包括Google TensorFlow、Caffe、Amazon MXNet和Sony NNabla在内的主流AI框架,并且在操作系统层面支持Android和Linux。
联发科表示,该平台“使 AI 更接近芯片组级别——适用于计算边缘的设备——深度学习和智能决策需要更快地发生”,从而创建了一个边缘到云的 AI 计算解决方案的混合体。
Nvidia 的 Tesla V100 GPU:与上一代相比,Nvidia 提升了其深度学习计算平台的 10 倍性能。新的NVIDIA Tesla V100 还包括 2 倍内存提升(32 GB 内存)以处理内存密集型深度学习和高性能计算工作负载,以及称为 NVIDIA NVSwitch 的新 GPU 互连结构。该公司表示,这使得多达 16 个 Tesla V100 GPU 能够以每秒 2.4 TB 的速度同时通信。Nvidia 还更新了软件堆栈。Tesla V100 32GB GPU 可用于完整的NVIDIA DGX 系统产品组合。
恩智浦用于边缘处理的机器学习 (ML) 环境:证明机器学习模型可以使用现有 CPU 在边缘运行,恩智浦半导体 NV 推出了嵌入式 AI 环境,允许设计人员在恩智浦的产品组合中实施机器学习,从低至成本微控制器到 i.MX RT 处理器和高性能应用处理器。NXP 表示,ML 环境为选择正确的执行引擎(Arm Cortex 内核、高性能 GPU/DSP)和在这些引擎上部署机器学习模型(包括神经网络)的工具提供了统包支持。
此外,恩智浦表示,该环境包括免费软件,允许客户导入他们自己训练的 TensorFlow 或 Caffe 模型,将它们转换为优化的推理引擎,并将它们部署在恩智浦从低成本 MCU 到 i.MX 和 Layerscape 的处理解决方案上处理器。
NXP 人工智能技术负责人 Markus Levy 在一份声明中表示:“在嵌入式应用程序中的机器学习方面,一切都是为了平衡成本和最终用户体验。” “例如,许多人仍然对即使在我们具有成本效益的 MCU 中也能部署具有足够性能的推理引擎感到惊讶。另一方面,我们的高性能交叉和应用处理器具有处理资源,可在我们客户的许多应用中进行快速推理和训练。随着人工智能用例的扩展,我们将继续使用具有机器学习专用加速功能的下一代处理器来推动这种增长。”
NXP 还提供EdgeScale 平台,用于从云端部署到嵌入式设备(物联网和边缘)。该公司解释说,EdgeScale 容器化了“云中的 AI/ML 学习和推理引擎,并自动将容器安全地部署到边缘设备。” NXP 还为 ML 工具、推理引擎、解决方案和设计服务创建了一个合作伙伴生态系统。
高通骁龙 845:据说高通技术公司的第三代人工智能移动平台与上一代 SoC 相比,人工智能性能提升了 3 倍。
除了现有对 Google 的TensorFlow和 Facebook 的Caffe/Caffe2框架的支持外,Snapdragon 神经处理引擎 (NPE) SDK 现在还支持 Tensorflow Lite 和新的开放式神经网络交换(ONNX),让开发人员可以轻松使用他们的框架高通表示,选择包括 Caffe2、CNTK 和 MxNet。它还支持 Google 的 Android NN API。目标应用包括智能手机、XR 耳机和始终连接的 PC。
在安全方面,骁龙 845现在提供了一个硬件隔离子系统,即安全处理单元 (SPU),它为高通的移动安全解决方案增加了“现有层的类似保险库的特性”。
高通的 AI 引擎由多个硬件和软件组件组成,在 Snapdragon 845 上具有设备端 AI 处理功能,将在 Snapdragon 845、835、820 和 660 移动平台上得到支持。AI 引擎支持 Snapdragon 核心硬件架构——Qualcomm Hexagon 矢量处理器、Qualcomm Adreno GPU 和 Qualcomm Kryo CPU。软件组件包括 Snapdragon 神经处理引擎、Android 神经网络 API 和 Haxagon 神经网络。
得益于异构计算,骁龙 845 的新架构带来了显着的改进。例如,高通表示,与上一代相比,新的摄像头和视觉处理架构可将视频捕捉、游戏和 XR 应用的功耗降低高达 30%,图形性能和能效提升高达 30%。与上一代相比,新 Adreno 630 的结果。
三星的 Exynos 9 系列:今年早些时候,三星电子有限公司推出了其最新的高级应用处理器 (AP),即Exynos 9 系列 9810,用于 AI 应用和更丰富的多媒体内容。该移动处理器是三星的第三代定制 CPU (2.9 GHz),具有超高速千兆位 LTE 调制解调器和深度学习增强的图像处理功能。
该处理器拥有一个全新的八核 CPU,其中四个是第三代定制核心,可以达到 2.9 GHz,另外四个针对效率进行了优化。三星表示:“通过拓宽管道和改进高速缓存的架构,单核性能提高了两倍,多核性能比其前身提高了约 40%。”
该芯片还增加了新功能,通过基于神经网络的深度学习增强用户体验,并通过单独的安全处理单元增强安全性,以保护面部、虹膜和指纹信息等个人数据。Exynos 9 系列 9810 目前处于量产阶段。
这些只是目前或即将上市的 AI 处理器选项中的一小部分。然而,通过询问 Rowen 概述的四个问题,开发人员将能够针对他们特定的嵌入式 AI 项目确定最佳候选人。
审核编辑 黄昊宇



















 工商网监
工商网监
评论