从Transformer问世至2023年ChatGPT爆火到2024年Sora吸睛,人们逐渐意识到随着模型参数规模增加,模型的效果越来越好,且两者之间符合Scalinglaw规律,且当模型的参数规模超过数百亿后
2024-03-22 16:40:28 135
135 章节,提供大语言模型微调的详细指导,逐步引领读者掌握关键技能。这不仅有助于初学者迅速上手,也为有经验的开发者提供了深入学习的机会。作为真正的大语言模型实践者,我们拥有十亿、百亿、千亿等不同参数规模大语言
2024-03-18 15:49:46
首先看吞吐量,看起来没有什么违和的,在单卡能放下模型的情况下,确实是 H100 的吞吐量最高,达到 4090 的两倍。
2024-03-13 12:27:28353 学习展开,详细介绍各阶段使用的算法、数据、难点及实践经验。
预训练阶段需要利用包含数千亿甚至数万亿单词的训练数据,并借助由数千块高性能GPU 和高速网络组成的超级计算机,花费数十天完成深度神经网络参数
2024-03-11 15:16:39
谷歌在模型训练方面提供了一些强大的软件工具和平台。以下是几个常用的谷歌模型训练软件及其特点。
2024-03-01 16:24:01183 谷歌模型训练软件主要是指ELECTRA,这是一种新的预训练方法,源自谷歌AI。ELECTRA不仅拥有BERT的优势,而且在效率上更胜一筹。
2024-02-29 17:37:39336 2022 年开始,我们发现 Multilingual BERT 是一个经过大规模跨语言训练验证的模型实例,其展示出了优异的跨语言迁移能力。具
2024-02-20 14:51:35221 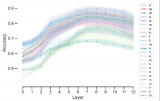
): 与稠密模型相比,预训练速度更快 与具有相同参数数量的模型相比,具有更快的推理速度 需要大量显存,因为所有专家系统都需要加载到内存中 在微调方面
2024-01-13 09:37:33315 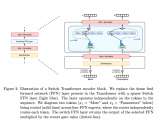
近日,百度地图宣布其城市车道级导航取得里程碑突破,已率先覆盖全国超100城普通道路。
2024-01-09 17:28:51627 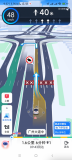
成都辰显光电有限公司(以下简称“辰显光电”)近日完成了数亿元A轮融资,这是其发展历程中的又一重要里程碑。
2024-01-03 14:44:02462 全微调(Full Fine-tuning):全微调是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。
2024-01-03 10:57:212273 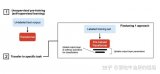
12月28日,国仪量子向上海大学理学院正式交付X波段连续波电子顺磁共振波谱仪EPR200-Plus,标志着国仪量子自主研制的电子顺磁共振波谱仪实现了全球交付100台的重要里程碑。上海大学理学院常务副
2023-12-30 08:25:02172 
大模型时代,根据大模型缩放定律,大家通常都在追求模型的参数规模更大、训练的数据更多,从而使得大模型涌现出更多的智能。但是,模型参数越大部署压力就越大。即使有gptq、fastllm、vllm等推理加速方法,但如果GPU资源不够也很难保证高并发。
2023-12-28 11:47:14432 
2023年12月25日,领先的汽车电子芯片整体解决方案提供商湖北芯擎科技有限公司(以下简称:芯擎科技)正式公布其商业业绩的重要里程碑 – 首款国产7纳米高算力车规级芯片“龍鹰一号”自年内开始量产交付
2023-12-26 10:37:10313 Hello大家好,今天给大家分享一下如何基于YOLOv8姿态评估模型,实现在自定义数据集上,完成自定义姿态评估模型的训练与推理。
2023-12-25 11:29:01968 
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个工件切割分离点预测模型
2023-12-22 11:07:46258 
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个自定义的圆检测与圆心定位预测模型
2023-12-21 10:50:05513 
抓取图像,手动标注并完成自定义目标检测模型训练和测试
在第二章中,我介绍了模型训练的一般过程,其中关键的过程是带有标注信息的数据集获取。训练过程中可以已有的数据集合不能满足自己的要求,这时候就需要
2023-12-16 10:05:19
本章记录了如何从网上抓取素材并进行标注,然后训练,导出测试自己的模型。
2023-12-16 09:55:18266 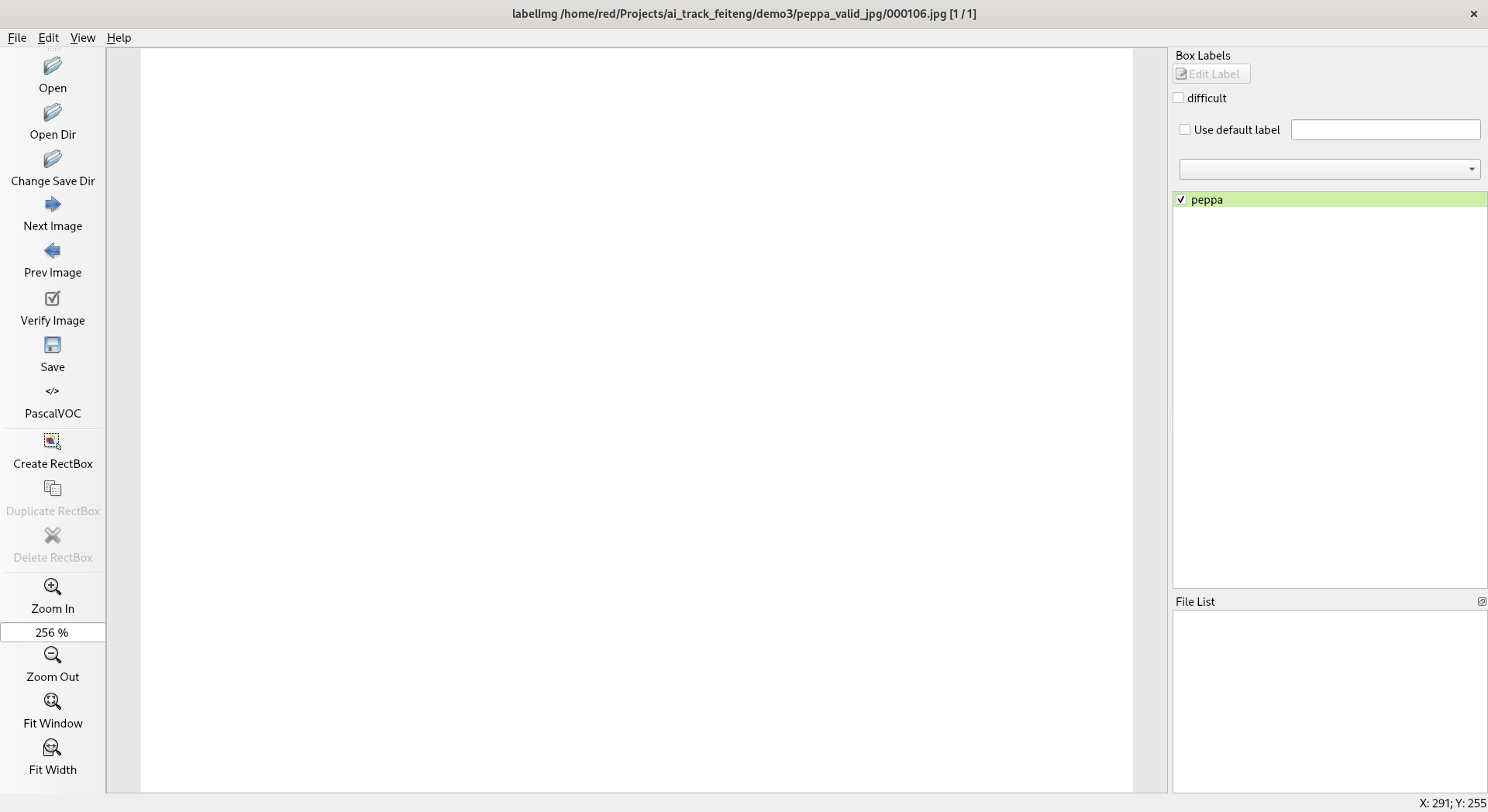
的,只不过主角这次换成了pulsar2:
1、先在服务器上训练好网络模型,并以一个通用的中间形式导出(通常是onnx)
2、根据你要使用的推理引擎进行离线转换,把onnx转换成你的推理引擎能部署的模型
2023-12-10 16:34:43
和足够的计算资源,还需要根据任务和数据的特点进行合理的超参数调整、数据增强和模型微调。在本文中,我们将会详细介绍深度学习模型的训练流程,探讨超参数设置、数据增强技
2023-12-07 12:38:24543 
近日,武汉芯源半导体正式发布首款基于Cortex®-M0+内核的CW32A030C8T7车规级MCU,这是武汉芯源半导体首款通过AEC-Q100 (Grade 2)车规标准的主流通用型车规MCU产品
2023-11-30 15:47:01
基于英伟达混合资源及天数智芯混合资源完成训练的大模型, 也是智源研究院与天数智芯合作取得的最新成果,再次证明了天数智芯通用 GPU 产品支持大模型训练的能力,以及与主流产品的兼容能力。 据林咏华副院长介绍,为了解决异构算力混合训练难题,智源研究院开发了高效并行训练框
2023-11-30 13:10:02727 
和 50% - 75% 的通信成本,而且英伟达最新一代卡皇 H100 自带良好的 FP8 硬件支持。但目前业界大模型训练框架对 FP8 训练的支持还非常有限。最近,微软提出了
2023-11-03 19:15:01848 
的博文,对 Pytorch的AMP ( autocast与Gradscaler 进行对比) 自动混合精度对模型训练加速 。 注意Pytorch1.6+,已经内置torch.cuda.amp,因此便不需要加载
2023-11-03 10:00:191054 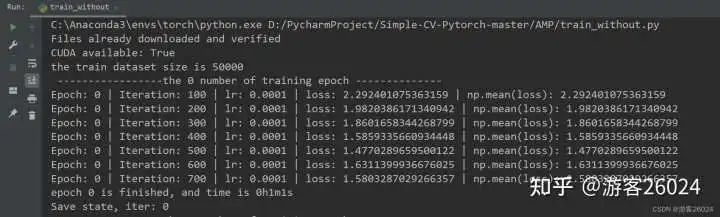
昂贵 H100 的一时洛阳纸贵,供不应求,大模型训练究竟需要多少张卡呢?GPT-4 很有可能是在 10000 到 20000 张 A100 的基础上训练完成的[8]。按照 Elon Musk 的说法
2023-10-29 09:48:134184 
【Vitis AI】 Vitis AI 通过迁移学习训练自定义模型
测评计划:
一、开箱报告,KV260通过网线共享PC网络
二、Zynq超强辅助-PYNQ配置,并使用XVC(Xilinx
2023-10-16 15:03:16
非常高兴地向各位宣布,赛昉VisionFive 2上已成功集成了Android开源项目(AOSP),为用户带来了更多的软件解决方案以及与Android软件生态系统的无缝集成。这一里程碑源于与开源社区
2023-10-16 13:11:45
深度学习、机器学习、生成式AI、深度神经网络、抽象学习、Seq2Seq、VAE、GAN、GPT、BERT、预训练语言模型、Transformer、ChatGPT、GenAI、多模态大模型、视觉大模型
2023-09-22 14:13:09605 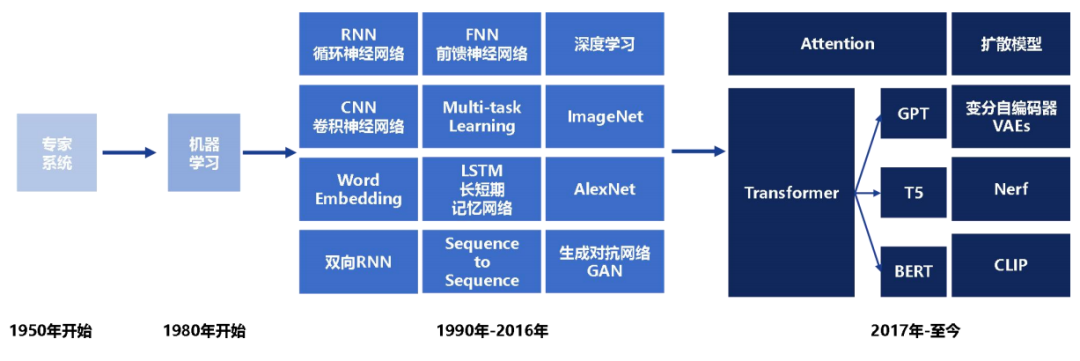
迈步机器人BEAR-H系列是用于辅助脑卒中患者步态康复训练的新型可穿戴式下肢外骨骼机器人。机器人拥有主动被动训练模式,通过对患者髋、膝、踝关节提供助力完成行走训练,可以节省人力,并提高康复效果
2023-09-20 17:25:48
model 训练完成后,使用 instruction 以及其他高质量的私域数据集来提升 LLM 在特定领域的性能;而 rlhf 是 openAI 用来让model 对齐人类价值观的一种强大技术;pre-training dataset 是大模型在训练时真正喂给 model 的数据,从很多 paper 能看到一些观
2023-09-19 10:00:06505 
,608,609]\"
–model参数到模型所在文件夹那一级;paddle模型有2种:组合式(combined model)和非复合式(uncombined model);组合式就是__model__
2023-09-19 07:05:28
为什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 几种并行方式,分别在模型的层内、模型的层间、训练数据三个维度上对 GPU 进行划分。三个并行度乘起来,就是这个训练任务总的 GPU 数量。
2023-09-15 11:16:2112059 
目前官方的线上模型训练只支持K210,请问K510什么时候可以支持
2023-09-13 06:12:13
近期,一支来自中国的研究团队正是针对这些问题提出了解决方案,他们推出了FLM-101B模型及其配套的训练策略。FLM-101B不仅大幅降低了训练成本,而且其性能表现仍然非常出色,它是目前训练成本最低的100B+ LLM。
2023-09-12 16:30:30921 
摘要:本文主要介绍大模型的内部运行原理、我国算力发展现状。大模型指具有巨大参数量的深度学习模型,如GPT-4。其通过在大规模数据集上进行训练,能够产生更加准确和有创造性的结果。大模型的内部运行
2023-09-09 11:15:561261 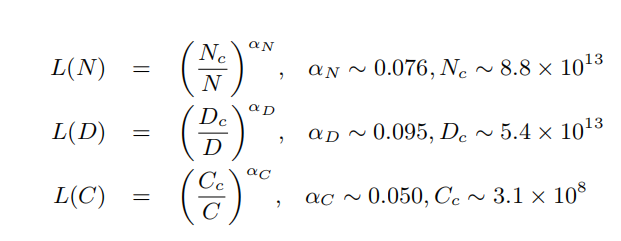
大模型落地实践》的主题演讲,深入介绍了天数智芯通用GPU产品以及自主算力解决方案,为大模型创新发展打造坚实算力底座。 天数智芯副总裁郭为 郭为指出,大模型的飞速发展产生超预期效果,为人工智能发展带来了新的机遇。顺应发展需求
2023-09-07 17:15:05574 
华为盘古大模型以Transformer模型架构为基础,利用深层学习技术进行训练。模型的每个数量达到2.6亿个,是目前世界上最大的汉语预备训练模型之一。这些模型包含许多小模型,其中最大的模型包含1亿4千万个参数。
2023-09-05 09:55:561228 生成式AI和大语言模型(LLM)正在以难以置信的方式吸引全世界的目光,本文简要介绍了大语言模型,训练这些模型带来的硬件挑战,以及GPU和网络行业如何针对训练的工作负载不断优化硬件。
2023-09-01 17:14:561046 
基础设施和通信基础设施等领域开展紧密合作,全面提升自主算力供给能力和服务水平,助力我国数字经济高质量发展。 天数算力是上海天数智芯半导体有限公司(以下简称“天数智芯”)的全资子公司。作为国内率先开展通用GPU设计的初创
2023-08-30 11:47:18848 同类产品有记录以来首次达到的成就,也是整个行业的一个重要里程碑,证明 Transphorm 的氮化镓器件能够满足伺服
2023-08-28 13:44:35154 
在《英特尔锐炫 显卡+ oneAPI 和 OpenVINO 实现英特尔 视频 AI 计算盒训推一体-上篇》一文中,我们详细介绍基于英特尔 独立显卡搭建 YOLOv7 模型的训练环境,并完成了 YOLOv7 模型训练,获得了最佳精度的模型权重。
2023-08-25 11:08:58817 
数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次(Batch)维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。
2023-08-24 15:17:28537 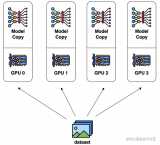
近日,沐曦集成电路(上海)有限公司(下称“沐曦”)曦云C500千亿参数AI大模型训练及通用计算GPU与北京智谱华章科技有限公司(下称“智谱AI”)开源的中英双语对话语言模型ChatGLM2-6B完成
2023-08-23 10:38:473028 模型训练是将模型结构和模型参数相结合,通过样本数据的学习训练模型,使得模型可以对新的样本数据进行准确的预测和分类。本文将详细介绍 CNN 模型训练的步骤。 CNN 模型结构 卷积神经网络的输入
2023-08-21 16:42:00884 生态共创计划,天数智芯作为重要合作伙伴参与此次发布仪式。 飞桨+ 文心大模型硬件生态共创计划发布仪式 天数智芯是国内首家实现通用GPU量产的硬科技企业,公司天垓、智铠两大系列通用GPU产品具有全自主、高性能、广通用等特点,广泛适用互联网、智能安防、生物
2023-08-17 22:15:01836 
模型,以便将来能够进行准确的预测。推理是指在训练完成后,使用已经训练好的模型进行新的预测。然而,深度学习框架是否区分训练和推理呢? 大多数深度学习框架是区分训练和推理的。这是因为,在训练和推理过程中,使用的是
2023-08-17 16:03:11905 盘古大模型参数量有多少 盘古大模型(PanGu-α)是由中国科学院计算技术研究所提供的一种语言生成预训练模型。该模型基于Transformer网络架构,并通过在超过1.1TB的文本数据上进行训练
2023-08-17 11:28:181769 近日,上海天数智芯半导体有限公司(简称 “天数智芯”)与 上海爱可生信息技术股份有限公司(以下简称 “爱可生”) 完成产品兼容性 互 认证。 结论显示: 天数智芯通用 GPU产品智铠MR-V50
2023-08-12 14:30:031109 
新佳绩 继联合电子新一代X-Pin电机正式批产后,公司又迎来了一个重要里程碑。截至2023年6月底,联合电子电机产品累计销售量突破200万!从2013年首个电机项目IMG290批产,到2022年年
2023-08-06 08:35:01880 训练好的ai模型导入cubemx不成功咋办,试了好几个模型压缩了也不行,ram占用过大,有无解决方案?
2023-08-04 09:16:28
有很多方法可以将经过训练的神经网络模型部署到移动或嵌入式设备上。不同的框架在各种平台上支持Arm,包括TensorFlow、PyTorch、Caffe2、MxNet和CNTK,如Android
2023-08-02 06:43:57
训练和微调大型语言模型对于硬件资源的要求非常高。目前,主流的大模型训练硬件通常采用英特尔的CPU和英伟达的GPU。然而,最近苹果的M2 Ultra芯片和AMD的显卡进展给我们带来了一些新的希望。
2023-07-28 16:11:012123 
电子发烧友网报道(文/李弯弯)日前,在2023世界半导体大会暨南京国际半导体博览会上,高通全球副总裁孙刚发表演讲时谈到,目前高通能够支持参数超过10亿的模型在终端上运行,未来几个月内超过100亿参数
2023-07-26 00:15:001058 《 国产 GPU的大模型实践 》 的主题演讲 , 全面介绍了天数智芯 通用 GPU产品特色 以及 在大模型上的 应用 情况 。 天数智芯副总裁郭为 郭为指出,算力关乎大模型产品的成败。作为中国领先的通用GPU 高端芯片及超级算力系统提供商,天数智芯先后发布了训练产品天垓100、推理产品智铠100,
2023-07-17 22:25:02397 
准备时间长,数据来源分散,归集慢,预处理百TB数据需10天左右; ● 其次,多模态大模型以海量文本、图片为训练集,当前海量小文件的加载速度不足100MB/s,训练集加载效率低; ● 第三,大模型参数频繁调优,训练平台不稳定,平均约2天出现一次训
2023-07-14 15:20:02475 
7月6日-8日,为期三天的2023世界人工智能大会(WAIC)圆满落幕!作为国内率先实现通用GPU量产应用的硬科技企业,天数智芯重磅展示了天垓、智铠系列通用GPU产品在大模型方面的最新应用成果以及
2023-07-11 23:05:01835 
而言,核心三要素是算法、数据和算力,其中算力是底座。 对于算力而言,目前行业基本的共识是基于通用GPU来构建AI大模型的算力集群,上海天数智芯半导体有限公司(以下简称:天数智芯)是目前国内第一家实现通用GPU量产并落地的公司。在WAIC上,天数
2023-07-11 01:07:002454 
参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。 现在业界的大语言模型都是
2023-07-10 09:13:575726 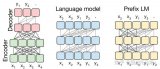
Corporation颁发的2022年度里程碑奖。贸泽长期备货Amphenol旗下40多个产品部门的全线产品,客户可前往贸泽官网mouser.cn进行购买。 该奖项颁发给贸泽团队,包括供应商经理
2023-07-07 16:58:28293 又一里程碑。 在活动现场,墨芯展台成为全场热点:1760亿参数的大语言模型Bloom在墨芯AI计算平台的推理引擎支持下,能够快速、流畅地回答各类问题,并完成诗歌创作、文案撰写等多项语言生成任务,赢得现场观众的关注与赞叹。 墨芯在千亿参
2023-07-07 14:41:17531 7月6日,2023世界人工智能大会在上海世博中心正式开幕。上海天数智芯半导体有限公司(以下简称“天数智芯”)携大模型训练、推理以及20+行业应用案例亮相WAIC,以视频、互动等多方式呈现,吸引众多
2023-07-07 08:20:02424 
近日,上海天数智芯半导体有限公司(简称“天数智芯”)与上海云脉芯联科技有限公司(简称“云脉芯联”)完成产品兼容性认证。在AI大模型智算中心场景下,双方共同对天数智芯通用GPU产品天垓100系列产品
2023-06-30 17:50:03865 
天数智芯在 湘江新区的布局合作 事宜 。 天数智芯首席运营官刘峥等人陪同参加。 蔡全根副董事长首先对谭勇书记的热情接待表示衷心的感谢。蔡全根表示,天数智芯率先实现国内通用GPU从0到1的重点突破,发布的两款通用GPU产品天垓100、智铠
2023-06-29 22:30:01776 
英伟达前段时间发布GH 200包含 36 个 NVLink 开关,将 256 个 GH200 Grace Hopper 芯片和 144TB 的共享内存连接成一个单元。除此之外,英伟达A100、A800、H100、V100也在大模型训练中广受欢迎。
2023-06-29 11:23:5825390 
在这篇文章中,我们将尽可能详细地梳理一个完整的 LLM 训练流程。包括模型预训练(Pretrain)、Tokenizer 训练、指令微调(Instruction Tuning)等环节。 文末
2023-06-29 10:08:591200 
SAM被认为是里程碑式的视觉基础模型,它可以通过各种用户交互提示来引导图像中的任何对象的分割。SAM利用在广泛的SA-1B数据集上训练的Transformer模型,使其能够熟练处理各种场景和对象。
2023-06-28 15:08:332574 
1. 大模型训练的套路 昨天写了一篇关于生成式模型的训练之道,觉得很多话还没有说完,一些关键点还没有点透,决定在上文的基础上,再深入探讨一下大模型训练这个话题。 任何一个大模型的训练,万变不离其宗
2023-06-21 19:55:02312 
本文基于DeepSpeedExamples仓库中给出的Megatron相关例子探索一下训练GPT2模型的流程。主要包含3个部分,第一个部分是基于原始的Megatron如何训练GPT2模型,第二个部分
2023-06-19 14:45:131717 
在一些非自然图像中要比传统模型表现更好 CoOp 增加一些 prompt 会让模型能力进一步提升 怎么让能力更好?可以引入其他知识,即其他的预训练模型,包括大语言模型、多模态模型 也包括
2023-06-15 16:36:11276 
迁移学习彻底改变了自然语言处理(NLP)领域,允许从业者利用预先训练的模型来完成自己的任务,从而大大减少了训练时间和计算资源。在本文中,我们将讨论迁移学习的概念,探索一些流行的预训练模型,并通过实际示例演示如何使用这些模型进行文本分类。我们将使用拥抱面转换器库来实现。
2023-06-14 09:30:14293 上海天数智芯半导体有限公司 天垓100训练卡(BI-V100) 天垓100聚焦高性能、通用性和灵活性,支持200余种人工智能模型,支持通用计算、科学计算、大模型、支持业界前沿新算法模型。模型适配速度快,从容面对未来的算法变迁,为人工智能及通用计
2023-06-12 16:15:02515 
的Aquila语言基础模型,使用代码数据进行继续训练,稳定运行19天,模型收敛效果符合预期,证明天数智芯有支持百亿级参数大模型训练的能力。 在北京市海淀区的大力支持下,智源研究院、天数智芯与爱特云翔共同合作,联手开展基于自主通用GPU的
2023-06-12 15:23:17550 
6月,智源研究院在北京智源大会上重磅发布了全面开源的“悟道3.0”系列大模型,包括“悟道·天鹰”(Aquila)语言大模型等领先成果。目前,摩尔线程已率先完成对“悟道·天鹰”(Aquila
2023-06-12 14:30:221182 ,全面介绍了天数智芯基于自研通用GPU的全栈式集群解决方案及其在支持大模型上的具体实践。 天数智芯产品线总裁邹翾 邹翾指出,顺应大模型的发展潮流,天数智芯依托通用GPU架构,从训练和推理两个角度为客户提供支撑,全力打造高性
2023-06-08 22:55:02951 
前文说过,用Megatron做分布式训练的开源大模型有很多,我们选用的是THUDM开源的CodeGeeX(代码生成式大模型,类比于openAI Codex)。选用它的原因是“完全开源”与“清晰的模型架构和预训练配置图”,能帮助我们高效阅读源码。我们再来回顾下这两张图。
2023-06-07 15:08:242186 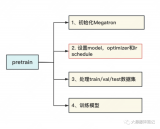
本文章将依次介绍如何将Pytorch自训练模型经过一系列变换变成OpenVINO IR模型形式,而后使用OpenVINO Python API 对IR模型进行推理,并将推理结果通过OpenCV API显示在实时画面上。
2023-06-07 09:31:421057 
因为该模型的训练时间明显更长,训练了1.4 万亿标记而不是 3000 亿标记。所以你不应该仅仅通过模型包含的参数数量来判断模型的能力。
2023-05-30 14:34:56642 
5月,上海市委网信办杨海军总工程师一行就大模型发展及应用情况赴上海天数智芯半导体有限公司(以下简称“天数智芯”)调研考察,天数智芯副董事长蔡全根等陪同调研。
2023-05-26 11:33:19861 本文章将依次介绍如何将 Pytorch 自训练模型经过一系列变换变成 OpenVINO IR 模型形式,而后使用 OpenVINO Python API 对 IR 模型进行推理,并将推理结果通过 OpenCV API 显示在实时画面上。
2023-05-26 10:23:09548 
vivo AI 团队与 NVIDIA 团队合作,通过算子优化,提升 vivo 文本预训练大模型的训练速度。在实际应用中, 训练提速 60% ,满足了下游业务应用对模型训练速度的要求。通过
2023-05-26 07:15:03422 
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。
2023-05-25 17:10:09593 OPPO 今日正式发布 Reno 十代里程碑之作 Reno10 系列新品。得益于 Reno 系列在轻薄美学和人像科技赛道的长期深耕,Reno10 系列创新地为用户带来一款兼具轻薄手感和大底潜望的人像轻旗舰。
2023-05-24 16:03:25931 
作为深度学习领域的 “github”,HuggingFace 已经共享了超过 100,000 个预训练模型
2023-05-19 15:57:43494 
近日,上海天数智芯半导体有限公司(以下简称“天数智芯”)与中电云数智科技有限公司(以下简称“中国电子云”)完成产品兼容性认证。结论显示:天数智芯的通用GPU天垓、智铠系列加速卡在中国电子云专属云平台以及超融合产品上运行稳定,性能可靠,表现出良好的兼容性。
2023-05-17 14:50:491013 在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
2023-05-17 14:24:201623 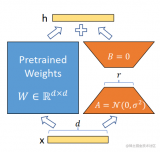
全球 50 多家车企共计部署了 800 多辆基于NVIDIA DRIVE Hyperion 自动驾驶汽车开发平台和参考架构打造的自动驾驶测试车辆。近日,该架构于自动驾驶安全领域树立了新的里程碑。
2023-05-10 14:55:01879 在合作伙伴的大力支持和共同努力下,天数智芯自主算力集群方案不仅能够有效支持OPT、LLaMa、GPT-2、CPM、GLM等主流AIGC大模型的Pretrain和Finetune,还适配支持了清华、智源、复旦等在内的国内多个研究机构的开源大模型,取得了大模型适配支持阶段性成果。
2023-04-23 14:19:39938 
我正在尝试使用自己的数据集训练人脸检测模型。此错误发生在训练开始期间。如何解决这一问题?
2023-04-17 08:04:49
,五年不到的时间,完成智舱、智驾、智控三大方向、四个系列产品的顺利流片、安全及可靠性验证和量产上车,目前已拥有260多家国内外优质客户,完成超百万片上车的里程碑,成为国内车规级核心芯片设计的引领者。芯
2023-04-14 14:01:22
DriveGPT 雪湖·海若的底层模型采用 GPT(Generative Pre-trained Transformer)生成式预训练大模型,与 ChatGPT 使用自然语言进行输入与输出
2023-04-14 10:27:15871 全球累计出货量已达1亿颗,广泛运用在如智能座舱、智能驾驶、智能网联、新能源电动车大小三电系统等,这一重要里程碑凸显了兆易创新与国内外主流车厂及Tier1供应商的密切合作关系。兆易创新致力于为汽车领域客户
2023-04-13 15:18:46
我正在尝试使用 eIQ 门户训练人脸检测模型。我正在尝试从 tensorflow 数据集 (tfds) 导入数据集,特别是 coco/2017 数据集。但是,我只想导入 wider_face。但是,当我尝试这样做时,会出现导入程序错误,如下图所示。任何帮助都可以。
2023-04-06 08:45:14
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。 如果要教一个刚学会走路的孩子什么是独角兽,那么我们首先应
2023-04-04 01:45:021024
 电子发烧友App
电子发烧友App













 工商网监
工商网监
评论