 电子发烧友App
电子发烧友App


摘要: 近日,阿里云宣布自研云原生数据库POLARDB正式全面售卖。这个从诞生就备受瞩目,基于计算和存储分离的第三代云计算架构下的商用关系型云数据库产品,实现了100%向下兼容MySQL 5.6的同时,支持单库容量扩展至上百TB以及计算引擎能力及存储能力的秒级扩展能力。
近日,阿里云宣布自研云原生数据库POLARDB正式全面售卖。这个从诞生就备受瞩目,基于计算和存储分离的第三代云计算架构下的商用关系型云数据库产品,实现了100%向下兼容MySQL 5.6的同时,支持单库容量扩展至上百TB以及计算引擎能力及存储能力的秒级扩展能力。
随着数据量的膨胀,越来越多企业将其IT资产迁移到公有云上,这引发了人们对云数据库现状与未来趋势的反思。
身居互联网时代,企业将不得不面对海量数据存储、高并发等场景,传统数据库虽然稳定但成本高,而开源数据库又一直无法解决性能瓶颈问题。那么,用户该如何做出抉择和取舍?相信对于大多数用户来说,他们并不知道如何来选择数据库,也不知道如何来优化数据库来应对新的业务挑战,他们只希望“用更短的时间、更快地到达目的地。”
而这也正是阿里云投入大量心血自研云数据库POLARDB的缘由。
聚焦用户核心痛点,新时代下的云数据库要敢于打破常规
在兼容性、性能、存储容量上,POLARDB不断突破,这三点看似对数据库最为朴素的考量标准也恰恰成就了POLARDB,最简单也最难,解决了这三点就解决了99%的数据库问题。
数据库用户最常遇到的问题就是在遇到高吞吐并发处理的场景下,性能达不到业务峰值窗口处理能力要求,尤其是读性能。数据容量小,一旦磁盘满了,业务就要被迫迁移。尽管有些数据库可以提供扩容支持,但是在用户数据量比较大的情况,存在着升级规格需要迁移数据的情况,超过1个TB之后的数据库迁移变得非常慢,多达几个小时,甚至超过1天。
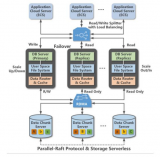
而POLARDB的存储容量可以实现无缝扩展,不管数据量有多大,几分钟内即可实现只读副本扩容,1分钟内即可实现全量备份,为企业的快速业务发展提供了弹性扩展能力。
与传统云数据库一个实例一份数据拷贝不同,POLARDB同一个实例的所有节点(包括读写节点和只读节点)都实现访问存储节点上的同一份数据,使得POLARDB的数据备份耗时实现秒级响应。并且借助RDMA网络以及最新的块存储技术,实现服务器宕机后无需搬运数据重启进程即可服务,满足了互联网环境下企业对数据库服务器高可用的需求。
通过放弃传统分布式数据库OLTP多路并发写的支持,采用一写多读的架构设计,简化分布式系统难以兼顾的理论模型,大幅度提升OLTP性能。
载誉而归,POLARDB有魄力更有实力
去年,在POLARDB的现场发布会上,现场实测跑分上,POLARDB读写性能均超越了AWS Aurora,读性能实现100万QPS,写性能实现13万QPS。过去需要要70个小时的10TB的业务数据创建只读副本,在POLARDB上只需几分钟,全球范围创建容灾实例时间也是一样。
时隔半年,阿里云POLARDB走出国门,亮相ICDE2018,并同步举办阿里云自有的POLARDB技术专场。
回到初心,在经过一年的不断优化迭代,POLARDB终于全面开放售卖。对于高吞吐并发处理、高可用业务弹性业务场景的用户来说,可以享受仅为商业数据库成本的1/10便可以轻松应对不断变化的业务需求。
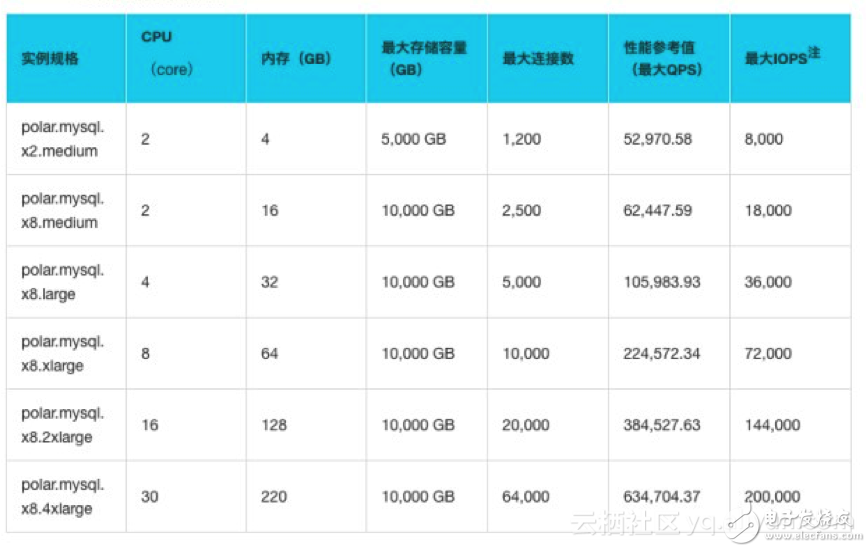
POLARDB支持的实例规格如下。
了解更多关于POLARDB超能力请戳:
https://www.aliyun.com/product/polardb
本文为云栖社区原创内容,未经允许不得转载

































































 工商网监
工商网监
评论