 电子发烧友App
电子发烧友App


摘要: TensorFlow作为现在最为流行的深度学习代码库,在数据科学家中间非常流行,特别是可以明显加速训练效率的分布式训练更是杀手级的特性。但是如何真正部署和运行大规模的分布式模型训练,却成了新的挑战。
介绍
本系列将介绍如何在阿里云容器服务上运行Kubeflow, 本文介绍如何使用TfJob运行分布式模型训练。
TensorFlow分布式训练和Kubernetes
TensorFlow作为现在最为流行的深度学习代码库,在数据科学家中间非常流行,特别是可以明显加速训练效率的分布式训练更是杀手级的特性。但是如何真正部署和运行大规模的分布式模型训练,却成了新的挑战。 实际分布式TensorFLow的使用者需要关心3件事情。
寻找足够运行训练的资源,通常一个分布式训练需要若干数量的worker(运算服务器)和ps(参数服务器),而这些运算成员都需要使用计算资源。
安装和配置支撑程序运算的软件和应用
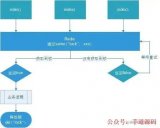
根据分布式TensorFlow的设计,需要配置ClusterSpec。这个json格式的ClusterSpec是用来描述整个分布式训练集群的架构,比如需要使用两个worker和ps,ClusterSpec应该长成下面的样子,并且分布式训练中每个成员都需要利用这个ClusterSpec初始化tf.train.ClusterSpec对象,建立集群内部通信
cluster = tf.train.ClusterSpec({"worker": [":2222", ":2222"], "ps": [":2223", ":2223"]}) 其中第一件事情是Kubernetes资源调度非常擅长的事情,无论CPU和GPU调度,都是直接可以使用;而第二件事情是Docker擅长的,固化和可重复的操作保存到容器镜像。而自动化的构建ClusterSpec是TFJob解决的问题,让用户通过简单的集中式配置,完成TensorFlow分布式集群拓扑的构建。
应该说烦恼了数据科学家很久的分布式训练问题,通过Kubernetes+TFJob的方案可以得到比较好的解决。
利用Kubernetes和TFJob部署分布式训练
修改TensorFlow分布式训练代码
之前在阿里云上小试TFJob一文中已经介绍了TFJob的定义,这里就不再赘述了。可以知道TFJob里有的角色类型为MASTER, WORKER 和 PS。
举个现实的例子,假设从事分布式训练的TFJob叫做distributed-mnist, 其中节点有1个MASTER, 2个WORKERS和2个PS,ClusterSpec对应的格式如下所示:
{
"master":[
"distributed-mnist-master-0:2222"
], "ps":[
"distributed-mnist-ps-0:2222", "distributed-mnist-ps-1:2222"
], "worker":[
"distributed-mnist-worker-0:2222", "distributed-mnist-worker-1:2222"
]
}而tf_operator的工作就是创建对应的5个Pod, 并且将环境变量TF_CONFIG传入到每个Pod中,TF_CONFIG包含三部分的内容,当前集群ClusterSpec, 该节点的角色类型,以及id。比如该Pod为worker0,它所收到的环境变量TF_CONFIG为:
{
"cluster":{
"master":[
"distributed-mnist-master-0:2222"
], "ps":[
"distributed-mnist-ps-0:2222"
], "worker":[
"distributed-mnist-worker-0:2222", "distributed-mnist-worker-1:2222"
]
}, "task":{
"type":"worker", "index":0
}, "environment":"cloud"}在这里,tf_operator负责将集群拓扑的发现和配置工作完成,免除了使用者的麻烦。对于使用者来说,他只需要在这里代码中使用通过获取环境变量TF_CONFIG中的上下文。
这意味着,用户需要根据和TFJob的规约修改分布式训练代码:
# 从环境变量TF_CONFIG中读取json格式的数据tf_config_json = os.environ.get("TF_CONFIG", "{}")# 反序列化成python对象tf_config = json.loads(tf_config_json)# 获取Cluster Speccluster_spec = tf_config.get("cluster", {})
cluster_spec_object = tf.train.ClusterSpec(cluster_spec)# 获取角色类型和id, 比如这里的job_name 是 "worker" and task_id 是 0task = tf_config.get("task", {})
job_name = task["type"]
task_id = task["index"]# 创建TensorFlow Training Server对象server_def = tf.train.ServerDef(
cluster=cluster_spec_object.as_cluster_def(),
protocol="grpc",
job_name=job_name,
task_index=task_id)
server = tf.train.Server(server_def)# 如果job_name为ps,则调用server.join()if job_name == 'ps':
server.join()# 检查当前进程是否是master, 如果是master,就需要负责创建session和保存summary。is_chief = (job_name == 'master')# 通常分布式训练的例子只有ps和worker两个角色,而在TFJob里增加了master这个角色,实际在分布式TensorFlow的编程模型并没有这个设计。而这需要使用TFJob的分布式代码里进行处理,不过这个处理并不复杂,只需要将master也看做worker_device的类型with tf.device(tf.train.replica_device_setter(
worker_device="/job:{0}/task:{1}".format(job_name,task_id),
cluster=cluster_spec)):具体代码可以参考示例代码
2. 在本例子中,将演示如何使用TFJob运行分布式训练,并且将训练结果和日志保存到NAS存储上,最后通过Tensorboard读取训练日志。
2.1 创建NAS数据卷,并且设置与当前Kubernetes集群的同一个具体vpc的挂载点。操作详见文档
2.2 在NAS上创建 /training的数据文件夹, 下载mnist训练所需要的数据
mkdir -p /nfs mount -t nfs -o vers=4.0 xxxxxxx.cn-hangzhou.nas.aliyuncs.com:/ /nfs mkdir -p /nfs/training umount /nfs
2.3 创建NAS的PV, 以下为示例nas-dist-pv.yaml
apiVersion: v1 kind: PersistentVolume metadata: name: kubeflow-dist-nas-mnist labels: tfjob: kubeflow-dist-nas-mnist spec: capacity: storage: 10Gi accessModes: - ReadWriteMany storageClassName: nas flexVolume: driver: "alicloud/nas" options: mode: "755" path: /training server: xxxxxxx.cn-hangzhou.nas.aliyuncs.com vers: "4.0"
将该模板保存到nas-dist-pv.yaml, 并且创建pv:
# kubectl create -f nas-dist-pv.yamlpersistentvolume "kubeflow-dist-nas-mnist" created
2.4 利用nas-dist-pvc.yaml创建PVC
kind: PersistentVolumeClaim apiVersion: v1metadata: name: kubeflow-dist-nas-mnistspec: storageClassName: nas accessModes: - ReadWriteMany resources: requests: storage: 5Gi selector: matchLabels: tfjob: kubeflow-dist-nas-mnist
具体命令:
# kubectl create -f nas-dist-pvc.yamlpersistentvolumeclaim "kubeflow-dist-nas-mnist" created
2.5 创建TFJob
apiVersion: kubeflow.org/v1alpha1 kind: TFJob metadata: name: mnist-simple-gpu-dist spec: replicaSpecs: - replicas: 1 # 1 Master tfReplicaType: MASTER template: spec: containers: - image: registry.aliyuncs.com/tensorflow-samples/tf-mnist-distributed:gpu name: tensorflow env: - name: TEST_TMPDIR value: /training command: ["python", "/app/main.py"] resources: limits: nvidia.com/gpu: 1 volumeMounts: - name: kubeflow-dist-nas-mnist mountPath: "/training" volumes: - name: kubeflow-dist-nas-mnist persistentVolumeClaim: claimName: kubeflow-dist-nas-mnist restartPolicy: OnFailure - replicas: 1 # 1 or 2 Workers depends on how many gpus you have tfReplicaType: WORKER template: spec: containers: - image: registry.aliyuncs.com/tensorflow-samples/tf-mnist-distributed:gpu name: tensorflow env: - name: TEST_TMPDIR value: /training command: ["python", "/app/main.py"] imagePullPolicy: Always resources: limits: nvidia.com/gpu: 1 volumeMounts: - name: kubeflow-dist-nas-mnist mountPath: "/training" volumes: - name: kubeflow-dist-nas-mnist persistentVolumeClaim: claimName: kubeflow-dist-nas-mnist restartPolicy: OnFailure - replicas: 1 # 1 Parameter server tfReplicaType: PS template: spec: containers: - image: registry.aliyuncs.com/tensorflow-samples/tf-mnist-distributed:cpu name: tensorflow command: ["python", "/app/main.py"] env: - name: TEST_TMPDIR value: /training imagePullPolicy: Always volumeMounts: - name: kubeflow-dist-nas-mnist mountPath: "/training" volumes: - name: kubeflow-dist-nas-mnist persistentVolumeClaim: claimName: kubeflow-dist-nas-mnist restartPolicy: OnFailure
将该模板保存到mnist-simple-gpu-dist.yaml, 并且创建分布式训练的TFJob:
# kubectl create -f mnist-simple-gpu-dist.yamltfjob "mnist-simple-gpu-dist" created
检查所有运行的Pod
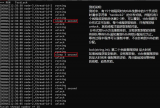
# RUNTIMEID=$(kubectl get tfjob mnist-simple-gpu-dist -o=jsonpath='{.spec.RuntimeId}')# kubectl get po -lruntime_id=$RUNTIMEIDNAME READY STATUS RESTARTS AGE
mnist-simple-gpu-dist-master-z5z4-0-ipy0s 1/1 Running 0 31smnist-simple-gpu-dist-ps-z5z4-0-3nzpa 1/1 Running 0 31smnist-simple-gpu-dist-worker-z5z4-0-zm0zm 1/1 Running 0 31s查看master的日志,可以看到ClusterSpec已经成功的构建出来了
# kubectl logs -l runtime_id=$RUNTIMEID,job_type=MASTER2018-06-10 09:31:55.342689: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1105] Found device 0 with properties:
name: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285pciBusID: 0000:00:08.0totalMemory: 15.89GiB freeMemory: 15.60GiB2018-06-10 09:31:55.342724: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:08.0, compute capability: 6.0)
2018-06-10 09:31:55.805747: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job master -> {0 -> localhost:2222}2018-06-10 09:31:55.805786: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> mnist-simple-gpu-dist-ps-m5yi-0:2222}2018-06-10 09:31:55.805794: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> mnist-simple-gpu-dist-worker-m5yi-0:2222}2018-06-10 09:31:55.807119: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:2222...
Accuracy at step 900: 0.9709Accuracy at step 910: 0.971Accuracy at step 920: 0.9735Accuracy at step 930: 0.9716Accuracy at step 940: 0.972Accuracy at step 950: 0.9697Accuracy at step 960: 0.9718Accuracy at step 970: 0.9738Accuracy at step 980: 0.9725Accuracy at step 990: 0.9724Adding run metadata for 9992.6 部署TensorBoard,并且查看训练效果
为了更方便 TensorFlow 程序的理解、调试与优化,可以用 TensorBoard 来观察 TensorFlow 训练效果,理解训练框架和优化算法, 而TensorBoard通过读取TensorFlow的事件日志获取运行时的信息。
在之前的分布式训练样例中已经记录了事件日志,并且保存到文件events.out.tfevents*中
# tree. └── tensorflow ├── input_data │ ├── t10k-images-idx3-ubyte.gz │ ├── t10k-labels-idx1-ubyte.gz │ ├── train-images-idx3-ubyte.gz │ └── train-labels-idx1-ubyte.gz └── logs ├── checkpoint ├── events.out.tfevents.1528760350.mnist-simple-gpu-dist-master-fziz-0-74je9 ├── graph.pbtxt ├── model.ckpt-0.data-00000-of-00001 ├── model.ckpt-0.index ├── model.ckpt-0.meta ├── test │ ├── events.out.tfevents.1528760351.mnist-simple-gpu-dist-master-fziz-0-74je9 │ └── events.out.tfevents.1528760356.mnist-simple-gpu-dist-worker-fziz-0-9mvsd └── train ├── events.out.tfevents.1528760350.mnist-simple-gpu-dist-master-fziz-0-74je9 └── events.out.tfevents.1528760355.mnist-simple-gpu-dist-worker-fziz-0-9mvsd5 directories, 14 files
在Kubernetes部署TensorBoard, 并且指定之前训练的NAS存储
apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: tensorboard name: tensorboard spec: replicas: 1 selector: matchLabels: app: tensorboard template: metadata: labels: app: tensorboard spec: volumes: - name: kubeflow-dist-nas-mnist persistentVolumeClaim: claimName: kubeflow-dist-nas-mnist containers: - name: tensorboard image: tensorflow/tensorflow:1.7.0 imagePullPolicy: Always command: - /usr/local/bin/tensorboard args: - --logdir - /training/tensorflow/logs volumeMounts: - name: kubeflow-dist-nas-mnist mountPath: "/training" ports: - containerPort: 6006 protocol: TCP dnsPolicy: ClusterFirst restartPolicy: Always
将该模板保存到tensorboard.yaml, 并且创建tensorboard:
# kubectl create -f tensorboard.yamldeployment "tensorboard" created
TensorBoard创建成功后,通过kubectl port-forward命令进行访问
PODNAME=$(kubectl get pod -l app=tensorboard -o jsonpath='{.items[0].metadata.name}')
kubectl port-forward ${PODNAME} 6006:6006通过http://127.0.0.1:6006登录TensorBoard,查看分布式训练的模型和效果:
总结
利用tf-operator可以解决分布式训练的问题,简化数据科学家进行分布式训练工作。同时使用Tensorboard查看训练效果, 再利用NAS或者OSS来存放数据和模型,这样一方面有效的重用训练数据和保存实验结果,另外一方面也是为模型预测的发布做准备。如何把模型训练,验证,预测串联起来构成机器学习的工作流(workflow), 也是Kubeflow的核心价值,我们在后面的文章中也会进行介绍。
本文为云栖社区原创内容,未经允许不得转载。





































 工商网监
工商网监
评论