 电子发烧友App
电子发烧友App


要: 阿里云在和很多企业交流的过程中发现他们在使用MaxCompute的时候往往会遇到一些成本相关的问题,而在与客户不但交流沟通的过程中,阿里云在成本优化方面也积累了大量的经验,因此也希望能够将这些经验沉淀下来分享给更多的企业和开发者,本文就将与大家分享帮助企业做好MaxCompute成本优化的“四步走”战略。
摘要:阿里云在和很多企业交流的过程中发现他们在使用MaxCompute的时候往往会遇到一些成本相关的问题,而在与客户不但交流沟通的过程中,阿里云在成本优化方面也积累了大量的经验,因此也希望能够将这些经验沉淀下来分享给更多的企业和开发者,本文就将与大家分享帮助企业做好MaxCompute成本优化的“四步走”战略。
以下内容根据演讲视频以及PPT整理而成。
本次演讲视频分享,请戳这里!
本次演讲PPT下载,请戳这里!
关于MaxCompute更多精彩文章,请移步云栖社区MaxCompute公众号!
对于MaxCompute的成本优化而言,它绝对不是一次性的任务,而应该是持续不断的。其实,可以将企业MaxCompute的成本优化分为四个主要的方面:正确预估、健康度定制、成本追踪以及成本优化。首先,需要对于企业的服务规模进行预估;其次,需要做好企业资产的健康度规范的制定,就像传统企业在进行开发时需要制定的开发规范一样,为了保障成本不会产生更多的开销,因此需要制定健康度规范;再次,除了企业资产健康度的制定之外,还需要进行成本的追踪,比如消耗的追踪以及用量的追踪,企业需要采用一些手段以及工具来发现异常的账单或者异常的费用;在本文的最后,也会与大家分享在真正的企业实战中能够使用的一些优化技巧。
一、如何做出正确的预估?
MaxCompute的计费策略
其实MaxCompute提供了两种计费方式,第一种是预付费,第二种是后付费。预付费的计算资源是包月或者包年的,想当于每个CU 150元每个月,它的存储和下载是按量后付费的。而后付费的方式则是按照存储进行阶梯定价的,基础价格是0.0192元/GB/天起步;在计算部分,对于SQL而言,需要通过IO输入量乘以复杂度然0.3元/GB,对于MR而言,它的计费则是按照CPU计算时计算的,每个计算时是0.46元。对于下载而言,则是按照公网下行0.8元/GB计算的,内网下行流量则是不收费的。

MaxCompute的服务选型
而阿里云的一些客户经常会问到他们到底是选择包月预付费,还是应该选择按量后付费的问题。那么,企业究竟应该如何正确地做好服务选型呢?这其实也是非常关键的一件事情。
阿里云为用户提供了两种选型工具:TCO工具和成本预估实践。对于TCO工具而言,在阿里云官网上MaxCompute产品的首页是有一个价格计算器的。对于预付费方式而言,用户可通过输入自己想要的数据规模以及想要的计算资源自动地计算所需要的月成本。对于后付费方式而言,阿里云则提供了CostSQL方法,用户可以将自己的数据放到MaxCompute上面计算Cost,当然了这里并不是真实的计算,而是进行预估,这样就可以大致计算出用户所需的费用。
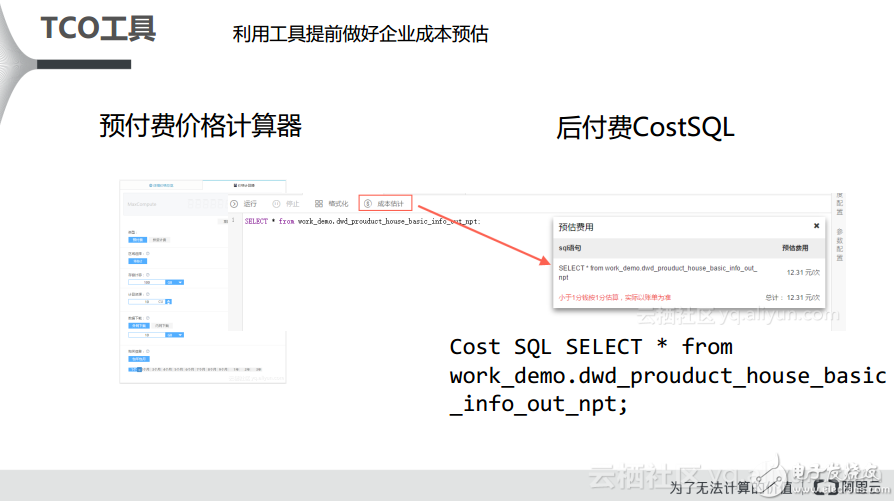
此外,阿里云还提供了一种选型工具,就是成本预估实践。在这里也为大家分享一些成本预估的技巧,比如一个案例就是某一个企业需要处理1TB数据,到底这1TB数据应该购买后付费还是预付费。在当时,阿里云给用户提出了两个建议,一种是密集型计算,另外一种叫做密集型存储,区别就是前者对于CPU资源的要求比较高。阿里云曾经自己做过相关的测试,对于预付费密集型计算而言,相当于使用160CU资源跑了1TB数据,大概能够达到分钟级别的相应速度,这样一个月的资源相当于使用了2.4万元的开销。如果企业对于计算的响应时间要求不高,那么阿里云还是推荐用户使用预付费密集型存储,大概会使用到50CU左右,一个月的开销大约在7500元左右,但是其的响应时间是小时级别的。如果用户选择后付费,按照基础的复杂度也就是1来计算,对于1TB的数据的开销大约是300元每天,那么一个月就应该是大约9000多元,当然这是单次计算,因为预付费是包年包月的,而后付费则是按照次数计费的,如果多次进行1TB数据的计算,那么其开销也会成倍增加。以上这些可以供企业进行参考。其实,阿里云建议对于刚开始上云的企业而言,可以先开通后付费,然后将数据放到后付费里面去做POC测试,看看自己的任务大概需要消耗多少Worker,通过Worker数就能推算出CU数量,这样就能大概估算出最终需要购买资源的数量,这也是一个经验技巧。

此外,一些Hadoop用户也希望做上云迁移,那么他们到底需要购买多少资源呢?举例而言,某个Hadoop集群可能有1个管控节点以及5台计算节点,每台机器32核,也就相当于是32个CPU,那么5台计算节点就是160个CPU,这样计算下来就相当于是每个月2.4万的这样的目录价,也就是标准的官方报价,也就是没有计算任何折扣或者优惠的价格,而实际上对于MaxCompute而言,在阿里云上定期会有一些折扣活动。
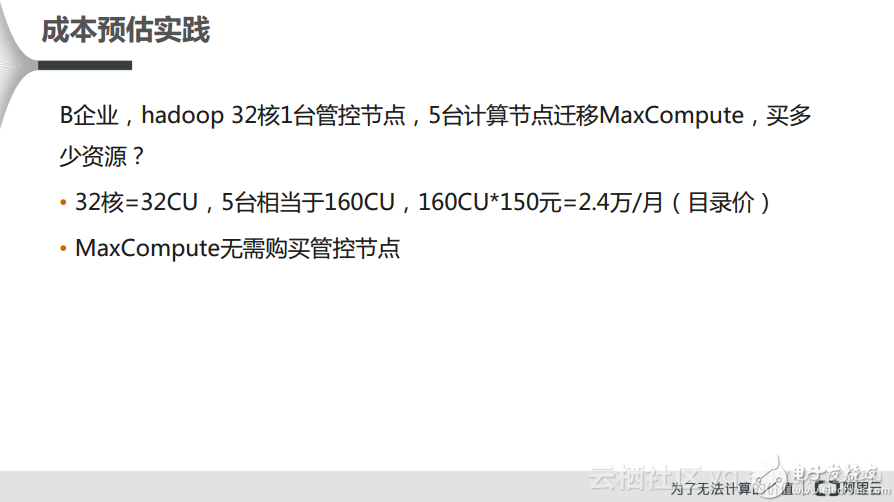
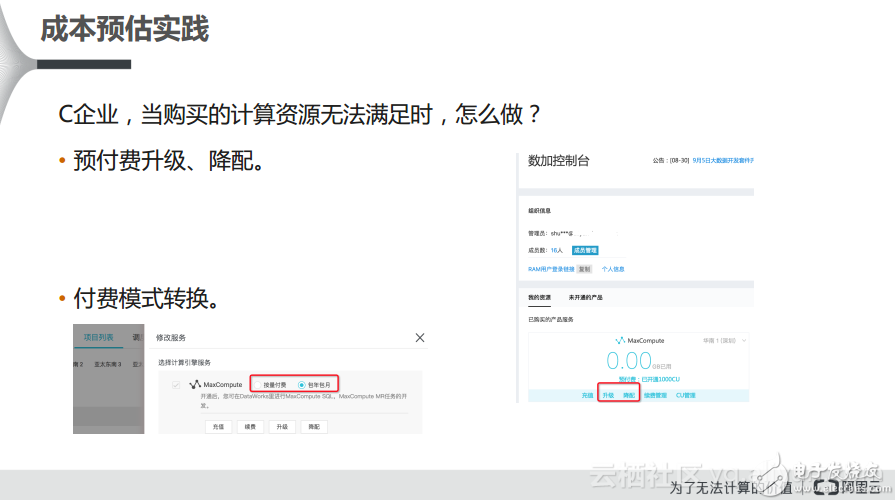
另外一点,就是当用户选择了MaxCompute之后,无需考虑管控节点,这样一来就节省了管控节点的费用。还有MaxCompute比Hive性能快80%,且免运维,又节省了至少一倍的成本。此外,一旦企业选择了预付费的服务,发现购买了50CU,但是不够使用,比如因为业务突然增长导致数据量也突然变大了,而此时企业可以非常方便地选择MaxCompute提供的数加服务,用户可以非常容易地进行升配或者降配的工作,此外还可以进行付费方式的转换,可以从预付费转成后付费,也可以从后付费转换成预付费,这些都是非常方便的,能够帮助用户灵活地选择和转变付费方式。
二、健康度制定
在本文的第一节中,为大家分享了企业如何做好上云的预估。在上云之后,企业要做的就需要制定相应的规范了,但是这样的规范并不能与传统的开发规范混为一谈。在这一节里面,主要与大家分享成本企业资产的健康度规范,当有了这套规范之后,企业中的开发小组就能够更好地约束ETL工程师以及数据分析师等的开销,这样只有在团队中每个人身上都培养起节约成本的文化,企业的资产才能做好优化。对于资产健康度而言,主要分为两部分:计算和存储,MaxCompute的主要资源消耗也就是产生在计算和存储两部分上。
计算健康度
这里为企业计算健康度提供了一些参考,当然了具体如何计算还是需要根据企业具体的规模、投入资源以及自身情况制定。对于计算健康度而言,可以将其作为百分制计算。如果出现了数据倾斜、全表暴力扫描以及相似计算等不良的SQL可以对于健康度进行扣分,而这些扣分项是最终要定位到责任人的,这样团队成员才会不断地优化自己的SQL以及开发习惯,这样一来整体的SQL计算效率会提高,成本也会相应地下降。

存储健康度
对于存储健康度而言,同样可以采用百分制,企业可以对于不经常使用到数据表,比如一些废弃表、空表以及未管理表等进行约束或者规范。

三、成本追踪
在分享完企业资产健康度规范的制定之后,接下来为大家分享如何追踪成本的消耗。因为很多企业在使用MaxCompute有时候会发现一些异常账单,因此这一部分也将与大家分享一些企业自查的方法,其实自查方法也是比较简单的,其实企业不用通过阿里云的帮助也能够自己完成。
成本管理工具
阿里云为企业提供了三个成本管理工具:账单明细,大家可以在阿里云的费用中心看到;使用记录,也就是阿里内部叫做OMS的东西,它会记录每条SQL的使用记录,复杂度、计量时间以及一天24小时的存储情况和下行流量等明细记录;命令行工具,用户可以通过命令行工具还原用户的操作,可以还原出用户当时使用的SQL到底是怎么样的,如何产生了所谓的“贵SQL”。
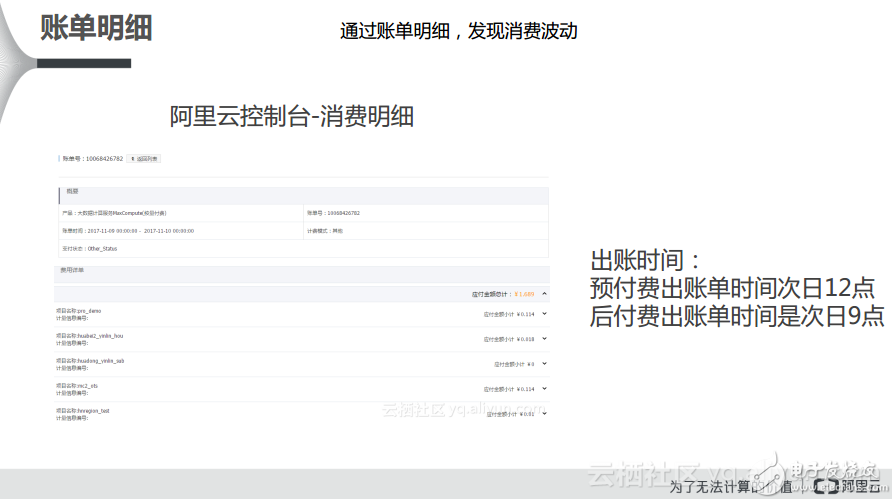
1) 账单明细
对于账单明细而言,预付费大概的出账时间是在次日的12点左右,后付费的出账时间是次日的9点左右,所以如果大家关心自己的账单就可以等到第二天相应的时间段到阿里云的消费中心看自己的消费明细。
2) 使用记录
当用户在自己的账单里面发现某一个Project的计费可能突然在某一天达到了几千元,可能是平常账单的多倍,这样的异常就需要关注,因此就需要去探查它的明细,这时候就需要去阿里云内部的使用记录里面查看。如果是后付费的用户则可以导出后付费的使用记录,如下图所示的就是一张阿里云消费明细的使用记录,它是一张Excel表格的形式,这里面有每个SQL的InstanceID,也就是用户Job任务的ID,通过这个ID可以借助一些还原工具来反查InstanceID对应的SQL到底是什么。大家可以看到,在下图中标红的是异常情况非常明显的SQL量,虽然绝对数字仅有2元,但是相对而言比平常的数据高了很多,这也就是异常的账单。那么如何看使用记录呢?其实大家可以重点看几项,ComputationSQL数据分类下数据的读取量以及SQL的复杂度是比较关键的信息,用SQL的读取量转换成GB乘以复杂度,再乘以0.3就是出账的金额。其实通过这个公式反推一下也能够很容易地获得消费明细。
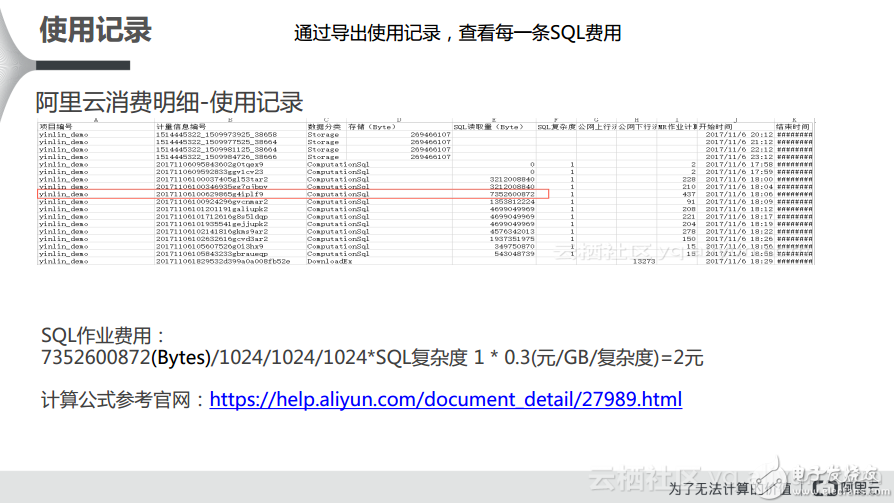
对于存储费用而言,相当于1天有24次,按照小时推送计量信息。计算存储价格时需要将字节数相加并做一个24小时的平均值,取出来之后再按照阶梯定价的公式进行计算最终得到存储价格。在下图中标红的部分指的是结束时间,之所以标记这个区域是因为天的计量信息是以每一条任务的结束时间为准,也就是如果某条任务的结束时间是第二天凌晨,那么这条任务的计量时间就会计入第二天,不会计入第一天,这也是大家在做计量处理的时候需要注意的细节。

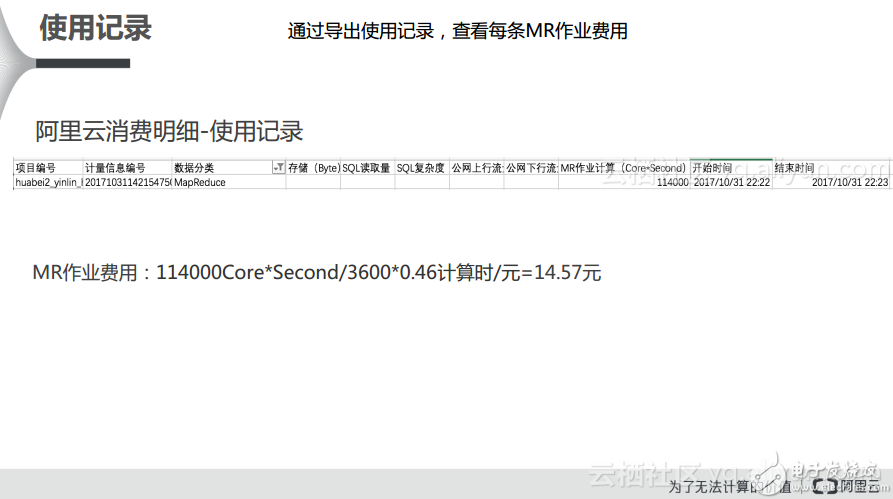
对于MR部分,首先有一个数据分类是MapReduce,其次对于MR作业的费用计算有这样的一个Core*Second这样的一个类,因为其精确到秒级,所以需要转换成小时级别,因此需要除以3600并乘以标准计价0.46,这样就能够得到MR使用记录的开销。
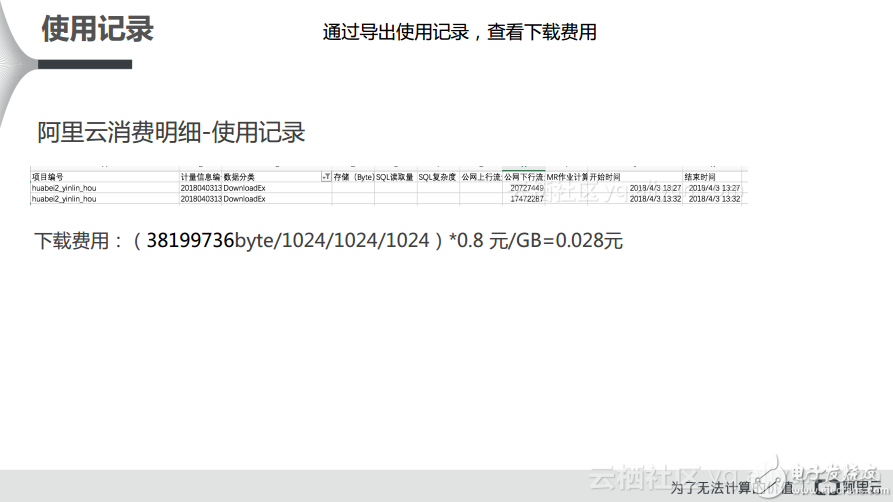
对于下载费用而言,其实它的计算比较简单。内网也就是经典网络的下行流量是不收费的,上行也是不收费的。只有走公网的时候,下行流量才会计费,在数据分类中有一个DownloadEx,这就对应了下行的数据量,将其转化成GB并乘以0.8元/GB,这样就可以得到下载明细了。
3) 命令行
当发现所谓的“贵SQL”的时候,应该如何还原它呢?因为当我们看到instid以及jobid并不能具有太多的感知和感觉,因此需要一些工具来介入进行SQL还原。这里有几个常用的方法,第一个就是当拿到instid的时候直接使用wait命令来获取logview,也就是获取SQL的详细日志,并将logview打印出来看一下当时究竟进行了什么样的SQL处理。还有一种方法就是“desc instance instid”,这种方法更为直接,可以直接将SQL显示在控制台里面,这两种方法都可以帮助用户更好地还原SQL信息。而第一种获取logview需要注意目前存在一个关于时间周期的问题,可能目前只能获取大约1周7天之内的logview信息,更早的信息或许是无法获得的。
四、成本优化
分享完成本追溯或者说是开销的查看之后,接下来和大家分享在公共云上针对于企业所遇到的一些“贵SQL”或者“贵存储”问题的优化技巧。
计算作业
对于计算作业而言,遇到最多的问题可能就是全表扫描,大部分企业公有云的“贵SQL”都是由全表扫描引起的。还有一个比较典型的问题就是新手因为频繁调度引起“贵SQL”,因为调度频繁就可能会产生任务的堆积,在后付费的情况下会造成排队现象,如果任务多又出现了排队,那么异常账单会出现在第二天,所以可能令人感觉当天没有问题,然而第二天就发现问题很大。
1) 控制全表扫描
在控制全表扫描部分的优化策略将重点论述几个关键点。第一点就是养成加分区列的习惯,这样可以帮助我们降低数据规模。预付费的模式可能不需要太多考虑IO问题和计算资源以及成本问题,但是预付费同样也会遇到另外一个问题,就是如果开发习惯不够好,那么就会引起性能的问题,这就可能会导致预付费大排队,其他的资源都在等待,同样会影响到企业的开发效率。第二点就是在进行Join的时候,一定要先做分区裁剪在做Join,不然的话就可能会先做全表扫描。最后还有一种方法来控制全表扫描,就是阿里云最近推出的对于全表扫描的开关,其可以做到Session级别也可以做到Project级别,阿里云更加推荐使用Project级别的开关,运维的同学可以将这个开关打开来禁止全表扫描,如此就能有效地帮助企业控制成本。

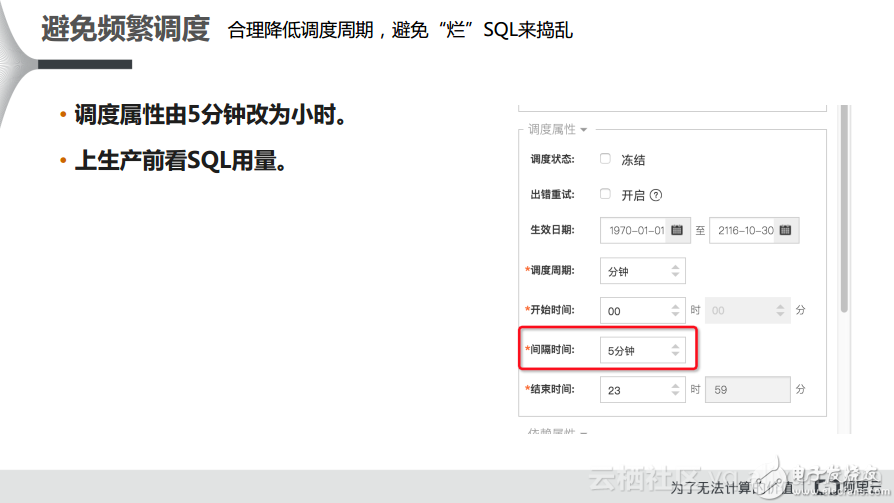
2) 避免频繁调度
大家经常会遇到调度周期修改得比较频繁的情况,因为MaxCompute是批量计算的服务,虽然MaxCompute一直在向实时计算的方向上不断演进,但是其距离实时的计算服务还是存在一定距离的。因此间隔时间变短,计算频率的增加,再加上SQL的不良习惯或者较差的健康度就会导致计算费用飙升,也就会产生异常的贵账单。所以在企业做频繁调度之前一定要通过CostSQL等方式预估一下SQL的开销到底有多大,当大家心里真正有底才能上到生产环境运行,不然会造成较大的开销。
存储
对于存储而言,这里有三个主要的关键点。第一个关键点就是要合理地进行数据分区;其次,要合理地设置表的生命周期;最后要定期地删除废表。
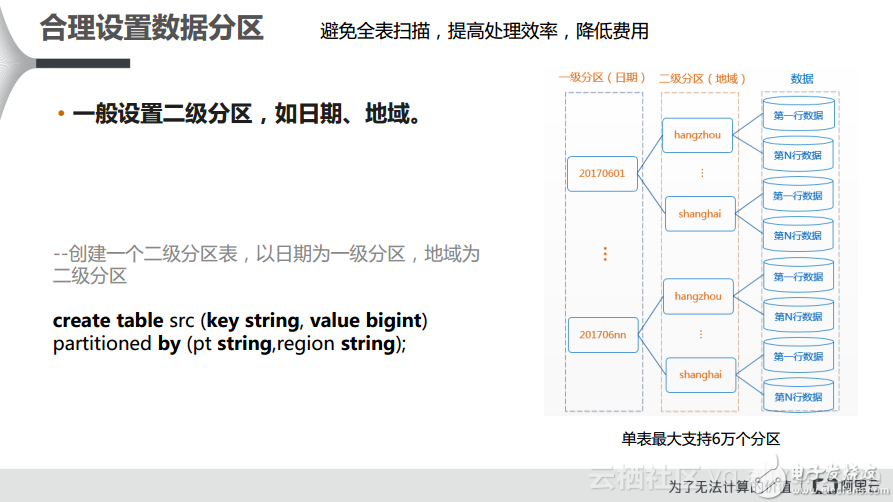
1) 合理设置数据分区
对于MaxCompute而言,首先要设置数据分区,让数据更好地分组。其实每个分区都可以认为是一个目录,那么就可以按照目录进行数据分组就好了。一般而言,推荐使用二级分区。因为最大的单表也就支持6万个分区,分区过多也会影响分区数。所以,对于企业而言,首先需要学会做分区,其次一般而言做二级分区就可以了。可以通过日期,比如天和小时,或者地域和城市实现二级分区,这样基本上就可以满足业务需求。
2) 设置合理的生命周期
很多时候,大家会发现在自己的数仓里面,很多的表都是临时表。对于临时表而言,如果最初不加生命周期,那么管理起来就会很困难,所以建议对于临时表加上生命周期,比如一个月。当过了设定的生命周期之后,系统就会自动地将临时表删除掉,同时也实现了企业存储空间的节省以及费用的下降。

3) 删除访问跨度大的废表
最后一点就是定期地删除访问跨度大的废表,所谓访问跨度大就是长期不会访问的表,对于这些表需要作出定期的清理,因为这些表的意义并不大,因此一定要做好资产的管理和表的管理。

以上就是关于企业MaxCompute成本优化的实践的分享,更多精彩的分享也会在云栖社区不断更新,希望大家持续关注。
本文为云栖社区原创内容,未经允许不得转载。


























 工商网监
工商网监
评论