 电子发烧友App
电子发烧友App


摘要: 本文介绍了如何使用MaxCompute UDF对JSON格式的日志进行信息提取和转换。
一、业务场景分析:
由于业务的复杂性,数据开发者需要面对不同来源的不同类型数据,需要把这些数据抽取到数据平台,按照设计好的数据模型对关键业务字段进行抽取,形成一张二维表,以便后续在大数据平台/数据仓库中进行统计分析、关联计算。
本文结合一个具体的案例来介绍如何使用MaxCompute对json格式的日志数据进行转换处理。
1.数据来源:应用实时写入ECS主机的指定目录下的日志文件中;
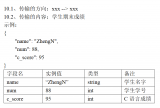
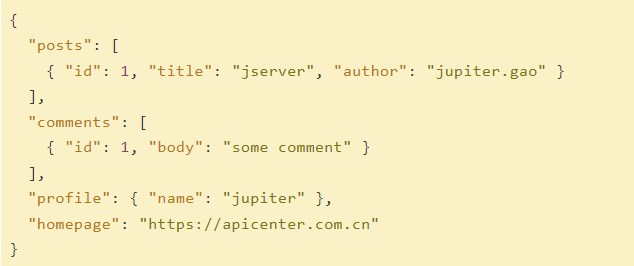
2.数据格式:日志文件中,每条日志的格式如下图所示(示例中对数据进行了简化和脱敏),每一条日志中包含了设备信息,以及1个或多个Session信息,且每条日志中的Session数量是动态的:1个或多个Session。每条日志的内容示例如下:
3.数据处理需求:采集日志数据,对日志数据进行解析、转换,对转换后的日志数据在MaxCompute进行统计分析。由于日志数据是json格式的,其中包含了多个业务字段信息,需要将业务字段提前出来,才能在MaxCompute进行后续的业务统计(如进行按照时段进行PV/UV统计、按照设备类型进行统计、关联设备ID与会员信息进行统计等),所以本文的关键需求就是如何把json格式数据的关键信息解析为一张包含业务字段的二维表。
二、解决方案:
本文的解决方案中,选择使用阿里云的日志服务+MaxCompute产品组合来满足以上业务需求,其中日志服务仅仅完成日志采集和投递的职能,不做数据解析和转化工作。
1.日志采集:通过日志服务获取日志数据到logstore(这部分内容可参考日志服务帮助文档)
2.通过日志服务的投递功能(帮助文档)将日志定时投递归档到MaxCompute的1张原始日志表,其中每条日志所有信息都写入到原始日志表的1个字段content中。
3.利用MaxCompute对原始数据进行字段解析和提取。
1)利用内建函数get_json_object进行数据提取
selectget_json_object(content,'$.DeviceID') as DeviceID,get_json_object(content,'$.UniqueIdentifier') as UniqueIdentifier,get_json_object(content,'$.GameID') as GameID,get_json_object(content,'$.Device') as Device,get_json_object(content,'$.Sessions\[0].SessionID') as Session1_ID,get_json_object(content,'$.Sessions\[0].Events\[0].Name') as Session1_EventName,get_json_object(content,'$.Sessions\[1].SessionID') as Session2_ID,get_json_object(content,'$.Sessions\[1].Events\[0].Name') as Session2_EventNamefrom log_target_json where pt='20180725' limit 10
提取的结果如下:
方案总结:以上处理逻辑,是把一条日志的业务字段分别提取成为行字段,适合每个json记录中的信息固定且可以映射为表字段,例如上面的例子,把session1和session2的信息提取出来后,分别看做不同的列字段来处理。但如果每条日志记录包含的session数量是动态不固定的时候,这种处理逻辑就难以满足需要,例如下一条日志就包含了3个session,如果要提取每个session的信息,就要求解析的SQL增加Session3_ID, Session3_EventName逻辑,如果再下一条日志包含100个session呢?这种提取方式就很难处理了。
这种情况,可以使用UDTF自定义函数来实现。
2)开发MaxCompute UDTF函数,对日志进行处理
根据数据特点,1条日志包含了多个session信息,属于1:N的关系,转换到数据仓库的二维表时,需要解析到最小粒度的session信息,把1行转成N行,提取所有session信息。业务目标如下所示:
在MaxCompute中,对1行记录处理转换为多行记录需要使用UDTF来实现。
我们这里以JAVA UDTF为例,对content字段中的每条json记录进行解析,获取并返回需要提取的业务字段。这里的UDTF的处理逻辑会深入到json的第3级,循环解析出最小粒度的数据并返回多条记录。
package com.aliyun.odps;import com.aliyun.odps.udf.UDFException;import com.aliyun.odps.udf.UDTF;import com.aliyun.odps.udf.annotation.Resolve;import com.google.gson.Gson;import java.io.IOException;import java.util.List;import java.util.Map;@Resolve("string->string,string,string,string,string,string,string,string")public class get_json_udtf extends UDTF {
@Override
public void process(Object[] objects) throws UDFException, IOException {
String input = (String) objects[0];
Map map = new Gson().fromJson(input, Map.class);
Object deviceID = map.get("DeviceID");
Object uniqueIdentifier = map.get("UniqueIdentifier");
Object gameID = map.get("GameID");
Object device = map.get("Device");
List sessions = (List) map.get("Sessions");
for (Object session : sessions) {
Map sMap = (Map) session;
Object sessionID = sMap.get("SessionID");
List events = (List) sMap.get("Events");
for (Object event : events) {
String name = (String) ((Map) event).get("Name");
String timestamp = (String) ((Map) event).get("Timestamp");
String networkStatus = (String) ((Map) event).get("NetworkStatus");
forward(deviceID, uniqueIdentifier,gameID,device,
sessionID,name,timestamp,networkStatus);
}
}
}}注:关于UDF本身编写、打包上传、创建Function等知识请参阅官方文档https://help.aliyun.com/document_detail/27867.html。
程序编写完毕后,需要打包、上传UDTF并创建UDF函数:
对编译好的程序进行打包处理,生成jar包,在MaxCompute客户端(odpscmd)中,上传这个资源:
add jar maxcompute_demo-1.0-SNAPSHOT.jar -f;
然后通过命令行创建function:
create function get_json_udtf as com.aliyun.odps.get_json_udtf using maxcompute_demo-1.0-SNAPSHOT.jar';
创建后查看函数:
测试验证:
对包含原始日志的表进行查询,使用创建的get_json_udtf对content字段进行查询:
查询结果如下,UDFT函数对每条json记录进行处理,生成了多条记录,符合预期:
同时,如需要固化处理逻辑,还可以使用insert into语法,将解析后的结果查询到一张新表,通过作业调度来实现周期性的数据转换。
三、总结:
本文通过一个日志分析的大数据分析场景,通过一个常见的json日志处理的需求为例,介绍了通过日志服务采集日志到MaxCompute,同时使用MaxCompute的内建函数/UDF等方式,对json格式的日志数据进行解析和转换,提取关键业务字段、生成了可用于后续分析的日志表。
本文为云栖社区原创内容,未经允许不得转载。




















 工商网监
工商网监
评论