 电子发烧友App
电子发烧友App



算法介绍
最近要做领域概念的提取,TFIDF作为一个很经典的算法可以作为其中的一步处理。
关于TFIDF算法的介绍可以参考这篇博客【http://www】.ruanyifeng.com/blog/2013/03/tf-idf.html。(请自行把括号去掉)
计算公式比较简单,如下:

预处理
由于需要处理的候选词大约后3w+,并且语料文档数有1w+,直接挨个文本遍历的话很耗时,每个词处理时间都要一分钟以上。
为了缩短时间,首先进行分词,一个词输出为一行方便统计,分词工具选择的是HanLp。
然后,将一个领域的文档合并到一个文件中,并用“$$$”标识符分割,方便记录文档数。

下面是选择的领域语料(PATH目录下):

代码实现
package edu.heu.lawsoutput;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @ClassName: TfIdf
* @Description: TODO
* @author LJH
* @date 2017年11月12日 下午3:55:15
*/
public class TfIdf {
static final String PATH = "E:\\corpus"; // 语料库路径
public static void main(String[] args) throws Exception {
String test = "离退休人员"; // 要计算的候选词
computeTFIDF(PATH, test);
}
/**
* @param @param path 语料路经
* @param @param word 候选词
* @param @throws Exception
* @return void
*/
static void computeTFIDF(String path, String word) throws Exception {
File fileDir = new File(path);
File[] files = fileDir.listFiles();
// 每个领域出现候选词的文档数
Map
// 每个领域的总文档数
Map
// TF = 候选词出现次数/总词数
Map
// scan files
for (File f : files) {
// 候选词词频
double termFrequency = 0;
// 文本总词数
double totalTerm = 0;
// 包含候选词的文档数
int containsKeyDoc = 0;
// 词频文档计数
int totalCount = 0;
int fileCount = 0;
// 标记文件中是否出现候选词
boolean flag = false;
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
String s = "";
// 计算词频和总词数
while ((s = br.readLine()) != null) {
if (s.equals(word)) {
termFrequency++;
flag = true;
}
// 文件标识符
if (s.equals("$$$")) {
if (flag) {
containsKeyDoc++;
}
fileCount++;
flag = false;
}
totalCount++;
}
// 减去文件标识符的数量得到总词数
totalTerm += totalCount - fileCount;
br.close();
// key都为领域的名字
containsKeyMap.put(f.getName(), containsKeyDoc);
totalDocMap.put(f.getName(), fileCount);
tfMap.put(f.getName(), (double) termFrequency / totalTerm);
System.out.println("----------" + f.getName() + "----------");
System.out.println("该领域文档数:" + fileCount);
System.out.println("候选词出现词数:" + termFrequency);
System.out.println("总词数:" + totalTerm);
System.out.println("出现候选词文档总数:" + containsKeyDoc);
System.out.println();
}
//计算TF*IDF
for (File f : files) {
// 其他领域包含候选词文档数
int otherContainsKeyDoc = 0;
// 其他领域文档总数
int otherTotalDoc = 0;
double idf = 0;
double tfidf = 0;
System.out.println("~~~~~" + f.getName() + "~~~~~");
Set
Set
Set
// 计算其他领域包含候选词文档数
for (Map.Entry
if (!entry.getKey().equals(f.getName())) {
otherContainsKeyDoc += entry.getValue();
}
}
// 计算其他领域文档总数
for (Map.Entry
if (!entry.getKey().equals(f.getName())) {
otherTotalDoc += entry.getValue();
}
}
// 计算idf
idf = log((float) otherTotalDoc / (otherContainsKeyDoc + 1), 2);
// 计算tf*idf并输出
for (Map.Entry
if (entry.getKey().equals(f.getName())) {
tfidf = (double) entry.getValue() * idf;
System.out.println("tfidf:" + tfidf);
}
}
}
}
static float log(float value, float base) {
return (float) (Math.log(value) / Math.log(base));
}
}
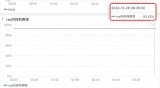
运行结果
测试词为“离退休人员”,中间结果如下:

最终结果:
结论
可以看到“离退休人员”在养老保险和社保领域,tfidf值比较高,可以作为判断是否为领域概念的一个依据。当然TF-IDF算法虽然很经典,但还是有许多不足,不能单独依赖其结果做出判断。很多论文提出了改进方法,本文只是实现了最基本的算法。如果有其他思路和想法欢迎讨论。
文章转载自 没课割绿地 的博客



















 工商网监
工商网监
评论