深入了解 S32K312EVB-Q172 开发板:硬件特性与使用指南 在嵌入式开发领域,一款优秀的开发板能够极大地提升开发效率和项目的成功率。NXP 的 S32K312EVB-Q172 开发板就是
2025-12-25 09:30:21 106
106 深入了解SRF7038A系列共模扼流圈 在电子设计的领域中,共模扼流圈是解决电磁干扰(EMI)问题的关键元件之一。今天,我们就来详细探讨一下BOURNS的SRF7038A系列共模扼流圈,看看它有
2025-12-22 14:10:05186 在教育信息化2.0时代,智慧教室作为教学改革的核心载体,正从“设备升级”向“场景重构”加速演进。一起来了解一下现在智慧教室建设方案的设计思路吧~
2025-12-17 11:33:12238 
不断的有朋友问到1000路监控点位用什么交换机合适?200路监控如何选择交换机?如何进行组网等?在选择交换机之前,我先要了解项目的组网框架,确实了组网框架,选择相关设备显得更加清楚。 我们一起
2025-12-17 10:27:42303 
贴片电容在现代电子电路中广泛应用,低容值与高容值贴片电容因不同的设计、材料和工艺,在诸多方面存在显著差异。这些差异涵盖了电容值范围、应用场景、电气性能(如等效串联电阻、等效串联电感、耐压值)、尺寸与成本等维度。了解它们的区别,对于电子工程师精准选型,确保电路性能至关重要。本文将深入剖析两者区别,
2025-12-10 15:31:15316 
;淮安移动则在某科技园区采用了FTTO(光纤到桌面)技术,使工作人员能使用高达1Gbps的专属带宽。
结语
网络接口虽小,却是连接数字世界的桥梁。了解网络接口的基础知识,不仅能帮助我们更好地使用网络设备
2025-11-26 18:53:58
广凌科技(广凌股份)作为智慧教室领域的领军企业,其整体解决方案以“场景适配、数据驱动、开放兼容”为核心理念,智慧教室的类型与适用场景整理好了,一起来了解一下吧~
2025-11-26 18:05:13210 
对于工作需要用到IGBT、但从未专业学习过IGBT的人来说, IGBT到底是什么、它为什么叫IGBT、它的核心关键词是什么、要怎么理解它 等一系列问题并无法一次性在某个地方获取到,都需要查阅大量的资料,学习大量的基础才能有个初步的了解。 为了让更多的人在更少的时间内掌握IGBT,我将在
2025-11-25 17:38:091066 
想了解如何高效管理工商储能系统?本文将介绍ZWS工商储能管理云平台的五大核心功能,助力企业提升运营效率与收益。ZWS工商储能管理云平台功能解析ZWS工商储能管理云平台不仅拥有Web应用端,还提供移动
2025-11-21 11:34:03235 
矢量网络分析仪是射频测试的核心工具,它能精确测量信号的幅度和相位,确保从5G基站到军用雷达等各类设备的性能与可靠性。本文将带你深入了解其原理、关键作用及各行业应用。
2025-11-20 18:01:491157 
。面对复杂多变的工业环境和严格的品质标准,企业如何借助自动化X射线检测设备优化生产流程、提升检测准确度?本文将围绕X-ray自动设备的核心优势与应用领域展开详尽解读,帮助您深入了解该技术带来的变革与价值。无论您是工厂质量管
2025-11-04 14:34:34193 的高压清洗机,旨在为大家的清洁工作提供便利。然而,很多人对于高压清洗机的安全性及正确使用方法存在疑惑。今天我们就来一探究竟,了解高压清洗机的安全性以及使用过程中需要
2025-10-27 17:23:32260 
,可以了解10 Pin引脚的具体功能:
其中:
3V3_M:主控供电
SW_TXEN:发送使能,对应GPIO1
SW_RXEN:接收使能,对应GPIO2
GPIO_0:普通 GPIO,支持 GPIO
2025-10-15 21:17:54
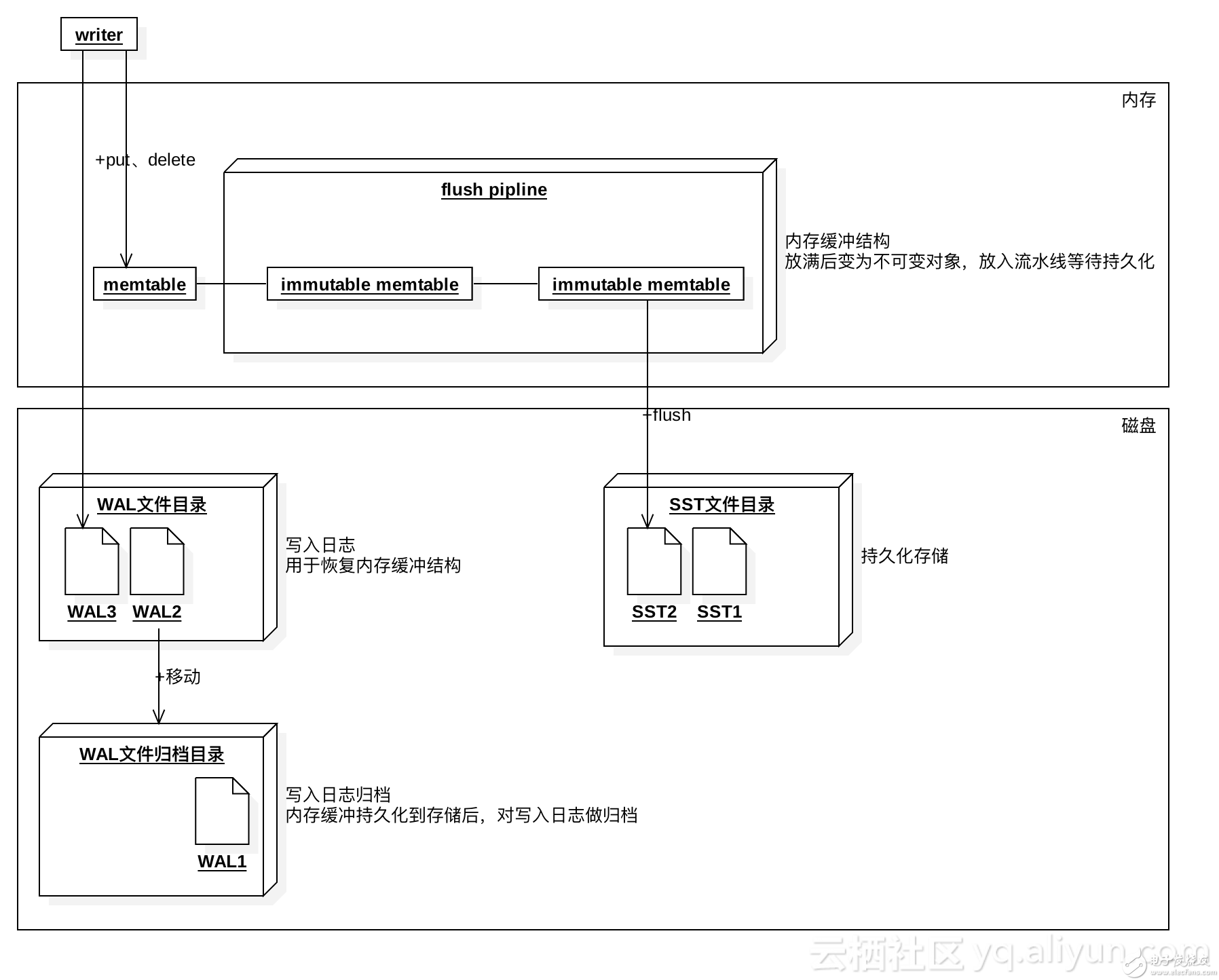
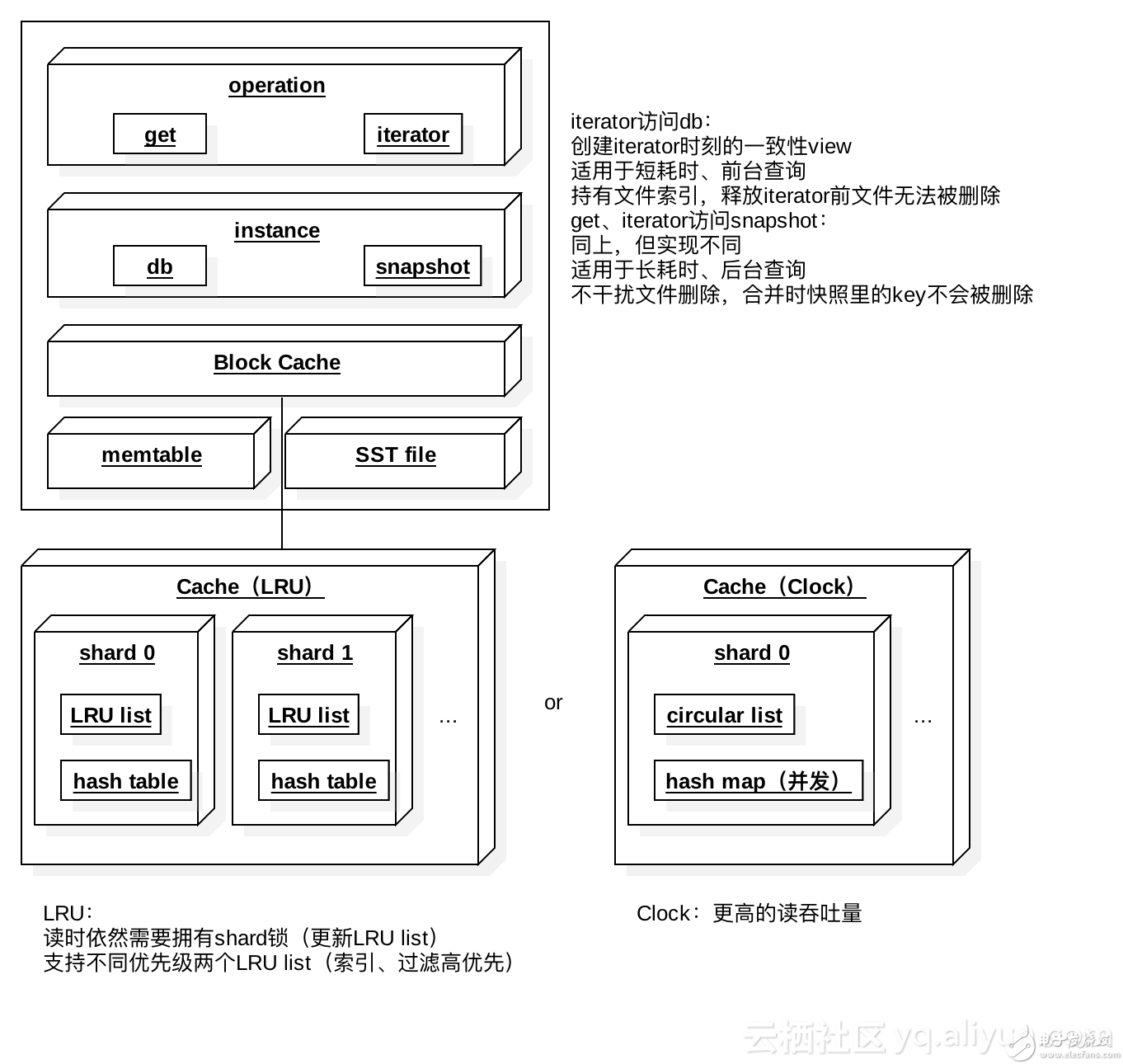
Kioxia Corporation今日宣布推出一款功能升级的RocksDB插件,可在多驱动器独立磁盘冗余阵列(RAID)环境中提升固态硬盘(SSD)的寿命和性能。基于早前展示的运行RocksDB且
2025-10-13 11:15:34267 深耕B2B电商十余年,亲历1688拍立淘接口20+坑:从图像预处理、权限申请到工厂排序。本文详解核心参数、实战代码及多图验证、定制方案生成等高级技巧,助你实现“看图找厂”精准匹配,附可运行代码,新手也能少走两年弯路。
2025-10-09 10:39:18421 、过滤导致电磁干扰 (EMI) 的高频成分,并吸收瞬态负载电流,以防止这些因素影响电源一次侧。这类电源应用的电容器必须可靠、紧凑、轻便、寿命长,并具有良好的高频性能。 虽然薄膜电容器非常适合这些电源应用,但设计人员必须了解其结构和特性,做出正确选择。 本文将简要介绍
2025-10-03 17:33:002129 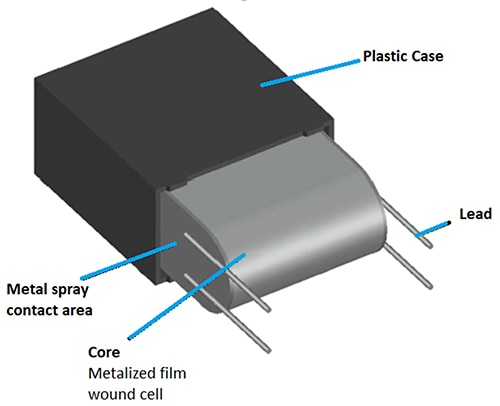
详情可下载PDF文档了解或咨询我们。
2025-09-22 14:17:58
电池老化仪是一种用于测试电池性能和寿命的设备。它可以模拟电池在不同条件下的使用情况,帮助人们了解电池的耐久性和可靠性。这种仪器在电池生产和研发过程中起着重要作用。
2025-09-19 18:18:25622 什么是ALM(应用生命周期管理)?它远不止是SDLC!一文了解其概念、关键阶段以及如何借助Perforce ALM这类工具,实现端到端的可追溯性、加速发布并保障合规性。
2025-09-19 11:03:521417 
报错;详情请看图片,我尝试了从github上拉取最新的packages的包到本地bsp的工程中,但是依旧解决不了问题。
2025-09-11 08:28:30
▲点击☆星标我,以防失联在WiFi7(IEEE802.11be)技术中,经常会听到前端模块(FEM)产品分为线性和非线性两种类型,其核心差异是否了解呢?本文将从性能特点、应用场景等方面详细分析两者
2025-09-10 16:33:188359 
一部智能手机的无线能力,究竟由哪些环节共同塑造?业内普遍将其拆分为射频、基带、电源、外设与软件五大子系统。其中,射频系统负责把比特流转化为电磁波,再让电磁波跨越空间回到比特流;基带系统则专精于符号运算与协议栈;二者相辅相成,却又各司其职。本文尝试以“信号的一生”为主线,抽丝剥茧地还原射频芯片从设计、制造到封装的完整旅程。
2025-08-22 15:10:171971 什么是毫米波雷达?毫米波雷达有什么特点?毫米波雷达有什么作用?海凌科有哪些系列毫米波雷达?一文带你了解!毫米波的定义毫米波是指频率在30GHz至300GHz之间、波长为1~10毫米的电磁波,兼具微波
2025-08-11 12:04:491614 
。LaserSharp激光自动对焦利用其内置激光测距仪来计算并显示与指定目标之间的距离,并即时调整焦距。。 借助高达 640 x 480 分辨率的图像,查看图像中
2025-08-09 11:07:46
串行通信是一种数据传输方式,它将数据按 逐位顺序 (bit by bit)在一条传输线上发送和接收,与并行通信(同时传输多位数据)形成对比。以下是其核心概念、工作原理、特点及应用的详细解释: 一、核心概念 数据传输方式 : 串行通信 :数据在单条线路上依次传输,每个时钟周期传输1位(0或1)。 并行通信 :数据通过多条线路同时传输多位(如8位、16位),适合短距离高速传输。 关键术语 : 位(Bit) :数据的最小单元,表示0或1。 帧(Frame)
2025-07-19 14:13:241438 在现代生活中,电机广泛使用在家电产品、汽车电子、工业控制等众多应用领域,每一个电机的运转都离不开合适的驱动芯片。纳芯微提供丰富的电机驱动产品选择,本期技术分享将重点介绍常见电机种类与感性负载应用,帮助大家更深入了解如何选择合适的电机驱动芯片。
2025-07-17 14:00:001611 
以前看过不少关于微电机的资讯,如微电机应用、微电机原理等等,那么什么是微电机呢?目前还是有不少人对微电机不了解,很多人觉得就是小电机,实际上微电机除了体积小之外,还具有普通电机不具备的优点。微电机
2025-07-17 08:46:58905 ,回车进入命令模式。通过命令查询。df -hfree -h
可以查阅到开发板存储空间8GB,内存1GB。
至此,对开发板有了初步了解,后面继续。
2025-07-13 22:50:01
定义:峰均比是一种对波形的测量参数,等于波形的振幅除以有效值(RMS)所得到的一个比值。对这个定义还有一种理解:峰值的功率和平均功率之比。这里先了解峰值功率:很多信号从
2025-07-02 17:32:152544 
在当今电子与电力技术飞速发展的时代,各类电子设备、电力系统以及新能源相关产品的研发、生产和维护过程中,电源测试系统扮演着至关重要的角色。本文将带你了解源仪电子的电源测试系统的功能。
2025-07-02 09:10:11709 
感谢合众恒跃与发烧友论坛提供的开发板与平台,收到实物如下
下面来了解下开发板
开发板由底板和核心板组成,核心板基于瑞芯微RK3568J处理器设计,支持图像H.264编解码处理,内置3D GPU可图像
2025-06-28 23:42:05
我们经常会听到谐波,到底什么是谐波,怎么定义的?为什么要关注谐波?什么时候关注谐波?谐波如何计算或标准规定的谐波的算法是怎样的?GB关于电压谐波又是如何评估的?带着诸多的问题,我们一起来了解。
2025-06-28 17:23:304161 
定位(Positioning)为万物互联提供了最基础信息;当今以GPS、GLONASS、Galileo和Beidou为代表的全球定位系统为人们带来了极大便利;而对于它们你是不是真正的了解,回答完以下
2025-06-28 07:06:202384 
关于SFP连接器你必须了解的那些知识 一、SFP光笼子的作用及材料组成 1.光笼子的概念与作用 ① 光笼子是什么? SFP Cage(Small Form-factor Pluggable Cage
2025-06-17 09:42:22888 
,比如元器件的正确选用等,笔者在此就不逐一列举了,下面笔者就来说一些非常实用的电子知识,希望大家都能向高手之路再迈上一步。注:下文内容最好结合图一和后续图片进行阅读。 看图识元件"
2025-06-09 16:55:17
日前,浩辰CAD看图王等国产工业软件正式完成了对鸿蒙电脑、鸿蒙手机、鸿蒙平板等多终端设备的全面适配,结合鸿蒙的多端互通、协同能力,为用户带来全新体验。深度适配鸿蒙系统全量全功能整合浩辰软件作为
2025-05-30 12:50:04947 
,设计人员必须注意电路板布局并使用适当的导线和连接器,从而最大限度地减少反射、噪声和串扰。此外,还必须了解传输线、阻抗、回波损耗和共振等基本原理。 本文将介绍讨论信号完整性时使用的一些术语,以及设计人员需要考虑的问题,然后介绍 [Amphenol] 优异的电缆和
2025-05-25 11:54:001055 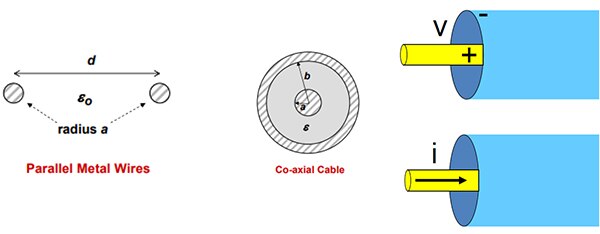
“ 新版的华秋 DFM 已支持打开源生的 KiCad PCB 文件。现在要进行裸板或 SMT 的 DFM 检查更方便了! ” 低调的看图神器 作为一个不怎么正经的电子工程师,我的电脑里常年安装
2025-05-23 11:16:501657 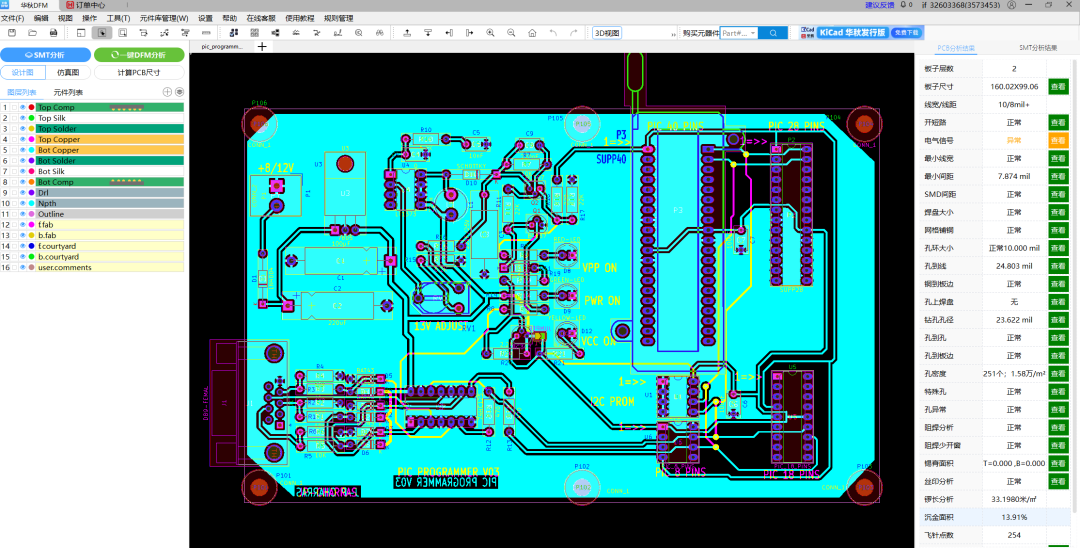
不同的类型吗?今天,我们就来详细了解一下USB接口的三大类型:Type-A、Type-B和Type-C。 Type-A:最常见的“USB口” 外观特征:扁平的矩形接口,通常用于电脑、电视等设备。 常见
2025-05-18 17:39:193702 什么是超级电容?你对超级电容了解多少?1、双电层电容:是在电极/溶液界面通过电子或离子的定向排列造成电荷的对峙而产生的。对一个电极/溶液体系,会在电子导电的电极和离子导电的电解质溶液界面上形成双电层
2025-05-16 08:52:221002 
在电子电路的复杂世界里,各种电路模块设备需要相互通信才能协同工作 ,I2C接口就像是电路模块设备间的沟通桥梁,今天就带大家深入了解它。
2025-05-08 14:15:392258 
如需了解产品详情请联系我们
2025-04-30 11:28:42
一项艰巨的任务。本博客将指导您了解关键的工业计算机尺寸、使用案例。关键工业计算机外形要素及其使用案例一、工业微型PC尺寸范围:宽度:100毫米-180毫米深度:10
2025-04-24 13:35:25871 
如需了解产品详情请联系我们
2025-04-18 16:48:23
如需了解产品详情请联系我们
2025-04-18 16:44:28
了解产品详情请联系我们
2025-04-18 16:36:53
如需了解产品详情请联系我们
2025-04-18 16:01:06
如需了解产品详情请联系我们
2025-04-18 15:15:28
如需了解产品详情请联系我们
2025-04-17 17:21:19
如需了解产品详情请联系我们
2025-04-17 17:01:46
如需了解产品详情请联系我们
2025-04-17 16:01:55
如需了解产品详情请联系我们
2025-04-17 15:34:09
如需了解产品详情请联系我们
2025-04-17 15:18:14
如需了解产品详情请联系我们
2025-04-17 15:10:48
如需了解产品详情请联系我们
2025-04-17 14:54:52
如需了解产品详情请联系我们
2025-04-17 14:45:32
如需了解产品详情请联系我们
2025-04-17 14:40:43
如需了解产品详情请联系我们
2025-04-14 16:37:20
如需了解产品详情请联系我们
2025-04-14 16:17:20
如需了解产品详情请联系我们
2025-04-14 16:13:45
如需了解产品详情请联系我们
2025-04-14 16:00:33
步进电机选型时,必须要了解以下几个方面的信息以确保所选电机能够满足特定的应用需求: 1. 转矩需求: ● 步进电机的保持转矩类似于传统电机的“功率”,但物理结构和输出特性有所不同
2025-04-14 07:38:161015 如需了解产品详情请联系我们
2025-04-11 16:36:35
如需了解产品详情请联系我们
2025-04-11 16:26:01
如需了解产品详情请联系我们
2025-04-11 16:22:40
如需了解产品详情请联系我们
2025-04-11 16:15:20
如需了解产品详情请联系我们
2025-04-11 16:00:22
如需了解产品详情请联系我们
2025-04-11 15:55:31
如需了解产品详情请联系我们
2025-04-11 15:45:55
如需了解产品详情请联系我们
2025-04-10 17:35:40
如需了解产品详情请联系我们
2025-04-10 17:21:38
如需了解产品详情请联系我们
2025-04-10 16:49:27
如需了解产品详情请联系我们
2025-04-10 16:31:04
如需了解产品详情请联系我们
2025-04-10 15:58:44
如需了解产品详情请联系我们
2025-04-10 15:27:55
如需了解产品详情请联系我们
2025-04-10 14:59:12
如需了解产品详情请联系我们
2025-04-10 14:51:48
如需了解产品详情请联系我们
2025-04-10 13:59:39
需了解产品详情请联系我们
2025-04-10 13:54:37
在GUTOR UPS备品备件采购之路上,困难重重,选型、渠道甄别、成本把控、安装部署、售后保障,桩桩件件都是棘手难题。隐藏的“雷区” 你了解吗?
2025-03-21 16:08:40
陶瓷电路板厚膜工艺是一种先进的印刷电路板制造技术,广泛应用于电子、通信、航空航天等领域。本文将详细介绍陶瓷电路板厚膜工艺的原理、流程、优势以及应用,带您全面了解这一技术……
2025-03-17 16:30:451140 买工业主板,找集特智能。 本期就带大家了解一下我们集特的主板。什么是工控主板?工控主板,也称为工业主板或工业电脑主板,是专为工业场合设计的主板,用于支持工业电脑(工控机)的稳定运行。 以下
2025-03-14 13:52:25613 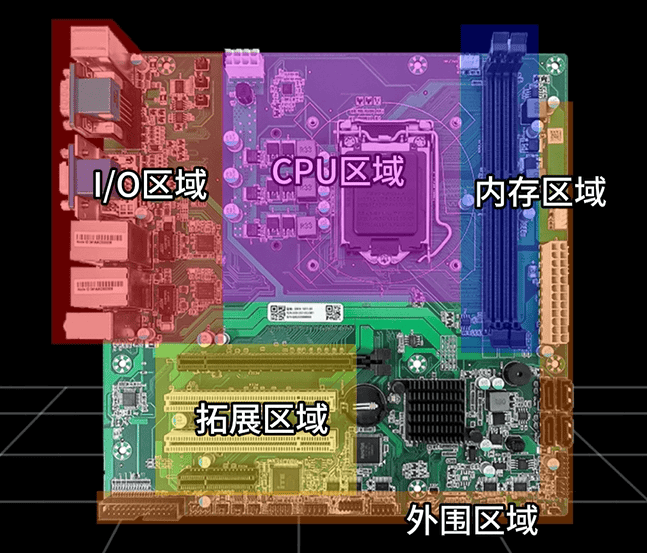
如需了解产品详情请联系我们
2025-03-13 14:00:20
频谱分析仪是一种用于分析信号频谱的仪器,主要用于测量和显示信号在频域中的分布。通过对信号进行频率分析,频谱分析仪可以帮助工程师、研究人员、技术人员等了解信号的频率成分、功率分布、调制特性等,从而
2025-03-06 17:47:351407 代料加工工厂了解并遵循一些常见的PCB板要求,有助于优化整个生产流程,确保产品的稳定性和高效性。 PCBA加工过程中对PCB板的常见要求 1. 板材选择 技术背景:PCB板材的选择会直接影响到电路的性能和生产工艺。常见的板材包括FR-4(玻纤环氧树脂覆铜板)和其他特殊材料,如陶
2025-03-03 09:30:271157 在单片机开发领域,图形显示功能变得越来越重要。无论是工业控制界面、智能家居设备,还是手持仪器仪表,都需要一个高效且易用的图形库来实现丰富的可视化效果。U8g2 和 LVGL 就是其中两款备受关注的图形库,它们各有特点,适用于不同的应用场景。今天,我们就来深入了解这两个图形库。
2025-02-13 11:01:403712 了 PCB 铣削的复杂性、铣削工艺、其优势、挑战和应用。 了解 PCB 铣削 PCB 铣削涉及从覆铜板上机械去除材料,以创建电气隔离并形成电路图案。与使用化学溶液溶解不需要的铜的传统蚀刻方法不同,铣削使用精确控制的铣削钻头来物理雕刻出所需的痕迹。该过程通
2025-01-26 21:25:001257 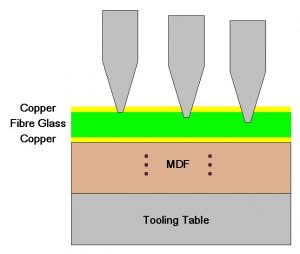
作者: Steven Keeping 在设计无线物联网 (IoT) 产品时,你需要了解天线及其作为产品与外部世界之间唯一接口的作用。如果天线选择不当,最终产品虽然可以通信,但性能会大打折扣,致使用户
2025-01-25 17:50:001375 
Arm 对未来技术的发展方向及可能出现的趋势有着广泛而深刻的洞察。在上周的文章中,我们预测了 AI 和芯片设计方面的未来趋势,本期将带你深入了解 2025 年及未来在不同技术市场的关键技术方向
2025-01-24 16:14:171981 电子发烧友网站提供《AN029:了解SiC功率肖特基二极管的数据表.pdf》资料免费下载
2025-01-23 16:40:42 0
0 只有深入了解M12接头A和D在各方面的区别,才能在选型时做到精准无误,确保电气连接系统高效、稳定运行。如果你在选型过程中还有其他具体问题,欢迎随时与我交流。
2025-01-22 16:00:001194 
回流焊过程中的材料兼容性和焊接效果。
3、仿真图渲染
提高的仿真图渲染效果可以让用户更直观地了解实际焊接后的样子,帮助预测可能出现的问题,并提前做出调整。
4、预判焊接质量
通过使用华秋DFM检查设计文件
2025-01-15 09:44:32
。因此,深入了解OBC与DCDC的技术特点及其测试系统显得尤为重要。 吉事励车载充电机OBC/DC-DC转换器测试系统 OBC作为车载充电机,主要功能是将电网电压通过地面交流充电桩或交流充电口,转换为适合电动汽车电池充电的直流电压。根据国家标
2025-01-14 16:48:311912 
CAD快速看图
2025-01-07 13:44:386 电子发烧友网站提供《EE-69:了解和使用SHARC处理器上的链接器描述文件.pdf》资料免费下载
2025-01-06 16:06:570 涡街流量计是一种常用的流量测量仪表,LUB系列涡街流量计的内部构造与原理密切相关,共同构成了其高精度、宽量程比和稳定运行的基础。本文将深入介绍涡街流量计的原理及内部构造,以便更好地了解涡街流量计
2025-01-06 15:17:471905 标题 描述图表的文本。通常位于图表的顶部。 系列 图表上显示的一个或多个数据序列。 提示框 将鼠标悬停在图表上的序列或点上时,您可以获得描述图表特定部分中的值的工具提示。 传说 图例在图表中显示数据系列,并允许您启用和禁用一个或多个系列。 轴 大多数图表(如典型的笛卡尔折线图和柱形图)都有两个轴来度量和分类数据:垂直轴(y 轴)和水平轴(x 轴)。3D 图表具有第三个轴,即深度轴(z 轴)。极坐标图(也称为雷达图)只有一个
2025-01-06 11:33:151044 
 电子发烧友App
电子发烧友App










 工商网监
工商网监
评论