P2P也就可以理解为"伙伴对伙伴"的意思,或称为对等联网。目前人们认为其在加强网络上人的交流、文件交换、分布计算等方面大有前途。
2011-11-21 15:38:28 2012
2012 目前,P2P已经作为一种流行的网络技术被越来越多地应用于互联网的文件共享、分布式计算、资源搜索等领域。P2P技术将各个用户节点互相结合成一个网络,共享其中的带宽,共同处理其中的信息。P2P网络是去
2020-03-16 07:32:39
上世纪末期,基于 C/S 模式的思想,人们发展了 HTTP 、 FTP 等应用层协议。然而 C/S 模式的弊端很明显:服务器的负载过大,下载速率过慢。基于上述背景,有人结合 P2P 网络与负载均衡
2022-11-03 19:10:16
编者按: 上世纪末期,基于 C/S 模式的思想,人们发展了 HTTP 、 FTP 等应用层协议。然而 C/S 模式的弊端很明显:服务器的负载过大,下载速率过慢。基于上述背景,有人结合 P2P 网络
2022-09-06 10:17:49
ARM的发展前景怎么样这项技术对于找工作是否有优势 在找工作中与单片机比较又有哪些优劣谢谢
2013-11-20 10:47:34
DSP的发展前景怎么样这项技术对于找工作是否有优势 在找工作中与单片机、ARM比较又有哪些优劣谢谢
2013-11-20 10:49:50
各位大神们,STATCOM发展前景怎么样啊?我是交大的研究生,最近学校要开题答辩了。我想将论文与以后的工作结合起来,找一个比较火的方向做题目。STATCOM发展前景怎么样啊?适合作为研究生的论文吗!
2013-05-12 15:54:16
各位大侠和TI老师:你们好!
使用CC3200 LUNCHXL开发板,下载CC3200SDK_1.1.0中的P2P样例,运行以后,终端出现如下信息
2018-06-21 01:39:59
labview的发展前景
2012-11-18 21:27:36
现在有二块tq210v4开发板,分别有一个rtl8189的wifi模块,想通过wifi实现二个板子之间的通信(p2p模式),系统平台为Linux,请问下要怎么配置呢,有什么好的连接也请贴上,非常感谢,。爬楼好几天还是不知道怎么办,
2015-07-01 16:10:12
` 本帖最后由 蓝天的云朵7 于 2016-8-30 19:35 编辑
【P2P物联网试用体验】+ P2P模块常规功能测试一、P2P模块内网设置在使P2P模块正常工作前,我们首先需要对模块进行
2016-08-29 19:33:45
搜索可以和本地局域网设备一样去管理和修改P2P的设备。注意P2P设备的类型显示为“手动”。虽然板子内置代码,只需要借助软件添加IP地址即可实现网络通信。可感觉没有技术含量,毕竟源码是人家的,所以最近
2016-09-04 10:22:56
7月底收到的P2P物联网开发板,开箱并初步应用一下,写一下开箱体验先`~“P2P物联网开发板”ZLAN9303C是上海卓岚信息科技有限公司开发的一款基于P2P通信方式的开发板。当时申请样品的主要目
2016-08-08 16:59:33
通过开发板串口与外界进行通讯。这套板子的特色主要是在P2P通信了,什么是P2P通信呢?这里常识拓展一下,学过《计算机网络》的同学应该很熟悉普通的联网技术:使用“ IP +端口”的方式和设备连接,该通信
2016-07-28 11:06:58
由于最近p2p终结者破解版在网络流行,被很多人滥用,造成很多人网速很慢,无法正常上网,饱受流量控制p2p终结者对你的流量的控制,希望这个软件可以帮到所有热爱学习却饱受流量控制的朋友~~&
2008-05-27 12:32:44
嵌入式发展前景
2021-01-13 08:00:04
车载设备GPS的发展前景如何?Prima具有什么特点?
2021-05-13 06:47:49
分析了深度业务感知的需求与现状,及其用于识别P2P的应用;对比了现有网络和NGN的区别,总结了运营商应对P2P的措施及各措施的优缺点,以及运营P2P的可能性和必要性。分析了
2009-01-01 00:06:16 19
19 分析现有信誉模型,提出一种使用信任机制和推荐机制的P2P 信誉模型,利用决策树思想优化该模型。给出一种在分布式P2P 系统中存取全局信任值的方法,解决了单点失效问题。实验
2009-03-24 09:52:044 分析并比较几种典型P2P 流媒体模型的可扩展性、启动延时和系统稳定性,指出基于gossip 协议的媒体服务模型与基于多播树协议的P2P 流媒体服务模型的区别。总结P2P 流媒体服务体系
2009-03-28 09:25:2215 P2P 下载与网络蠕虫具有相似的搜索机制,导致网络蠕虫难以被检测并定位。该文提出一种融合危险理论和ID3 分类算法的检测算法D-ID3。利用熵理论分析P2P 应用、蠕虫、正常主机的属
2009-03-29 11:11:3610 提出一种采用P2P的良性蠕虫传播策略,建立了数学模型,在理论上分析各项参数对其传播情况的影响,并使用SSFNET网络仿真工具对传播模型进行了仿真。仿真结果证明,P2P良性蠕虫
2009-04-06 08:45:1411 实施大规模分布式可视化操纵系统的一个重要瓶颈在于节点间海量数据的传输。P2P Streaming技术逐渐成为解决该瓶颈的可行方案之一。主流P2P Streaming模型由于实时性上的缺陷并不适于
2009-04-10 09:38:3521 基于一种改进型的Chord路由模型,将层次分类技术应用到P2P结构中,设计了一种名为CTI-Chord的P2P文件共享机制。利用Chord高效定位优势,引入层次分类方法,将分类树作为模型的中心
2009-04-10 09:40:079 P2P蠕虫对P2P网络和Internet构成巨大安全威胁。该文根据P2P网络报文之间的关系,提出一种P2P蠕虫检测方法,通过建立过滤规则实现对P2P蠕虫的检测与抑制。模拟实验结果表明,该方法
2009-04-11 09:34:1510 结构化P2P网络具有良好的可扩展性,但难以支持多关键词查询、范围查询等复杂查询。该文分析已有复杂查询方法,提出一种基于Kademlia的P2P多维范围查询系统K-net。K-net在进行多维
2009-04-13 08:43:0713 P2P对于分布式文件共享具有很好的前景,但当前的P2P系统仍然缺乏有效的信息管理机制。该文在构建超级节点叠加网络时考虑信任和语义的因素,语义相似的节点尽量分布在同一个
2009-04-13 09:14:3721 P2P网络是当前网络研究的热点之一,被认为是构建下一代网络的基础。该文基于混合式结构的P2P网络提出一种事务管理策略。该策略利用P2P网络中的超级节点处理能力强的特点,由
2009-04-16 08:57:1912 P2P网络中的搜索性能是影响P2P网络发展的关键问题。该文研究非结构化分散型P2P网络中的搜索机制,提出2个改进算法。改进算法利用节点的共享情况和查询历史发掘节点的兴趣爱好
2009-04-21 09:51:2615 课题研究使用JXTA 搭建P2P 网络,完成即时通信系统。即时通信系统分为发送、中继转发和接收三部分。其中中继转发部分在启动时加入P2P 网络,并且在P2P 网络中发布提供即时通信服
2009-06-20 09:00:5115 为了解决没有第三方认证的情况下,P2P 网络通信过程中对等点的授权问题,本文基于P2P 网络中对等点的信任度管理,提出了利用P2P 网络结构的特点来构造一个多态性密码的新方法
2009-06-20 09:35:108 基于DHT 的P2P 系统中,各种因素例如结点异构性和不同的文件访问率等,都可能会影响DHT 系统的效率。本文提出一个基于DHT 的P2P 系统中有效的负载均衡算法。该算法提出一个全
2009-08-10 12:13:3519 P2P 技术是一种分布式控制网络技术,它将逐渐取代集中式的客户/服务器结构。P2P的发展非常迅速,目前研究P2P 技术流行使用的仿真器存在可仿真协议种类少等问题。文章通过分
2009-08-13 11:33:3916 近年来,基于P2P 流媒体技术的网络电视已经成为网络舆论传播的重要手段之一,而P2P 技术的无中心和自组织特性将大大增加对网络电视服务进行识别和监管的难度。本文首先通过
2009-08-14 09:03:3523 网格和P2P(Peer to Peer)都是分布式计算模型,它们的总体目标相似。利用P2P 与网格技术之间的协同和互补,构造了一个二层的网格和P2P 计算混合模型,上层是网格层,下层是P
2009-08-18 09:33:539 随着计算机网络的迅速发展,新一代网络技术P2P得到了广泛应用,由于P2P技术所带来的诸多问题比如大量占用网络带宽,加重网络负担等等,因此对P2P应用流量的准确识别对于网
2009-08-28 14:36:3321 数字签名技术可以提供网络身份认证等功能,具有广泛的应用。本文利用门限密码技术设计一个基于P2P 网络的分布式多重数字签名方案。本方案由P2P 网络中的可信任节点共
2009-08-31 11:47:285 P2P 蠕虫是利用P2P 机制进行传播的恶意代码。本文针对基于P2P(peer-to-peer)的大规模网络,对P2P 蠕虫的传播展开相关研究。首先介绍三个基本的蠕虫传播模型,分析了引入良性蠕
2009-09-02 17:26:1817 P2P 打破了传统C/S 模式服务器对网络资源的集中化管理和提供,解放了服务器响应的压力和降低了带宽负载,应用于IPTV 系统。然而P2P 技术为IPTV 业务实现带来灵活和高效率等优点的
2009-09-12 16:24:3819 P2P自组织性带来的挑战:【摘要】对P2P网络的工作原理和典型应用进行了介绍,分析了P2P在商业应用和业务监管带来的挑战,提出了可管控P2P的思路,指出了需要研究的内容。【关
2009-10-22 10:40:177 由于P2P 系统可以高效地对资源进行共享而受到关注,但现在的P2P 仅支持精确查找或者通过洪泛方式进行低效率文本检索。为了解决这个问题,该文提出了一种结构化P2P 环境中的文
2009-11-20 16:41:446 本文提出一种基于兴趣的 P2P 网络架构,该架构结合了非结构化网络和兴趣网络。文章基于兴趣网络的社区结构改进搜索机制,并且基于兴趣网络提出应用于P2P 网络的基于用户和
2009-12-18 17:23:4515 P2P网络中智猪博弈
2009-12-25 15:03:309 现有P2P 网络规模大、动态性高、异构性强,有效的搜索技术一直是P2P 系统研究中的核心问题。本文针对无结构P2P 网络泛洪搜索机制的盲目性所导致的查询开销大、效率低的问题,
2009-12-30 11:45:289 P2P 具有良好的可用性、扩展性和容错性,在许多领域已经得到了广泛的应用。其中,P2P 在互联网中的相关技术可以应用于移动通信网络中,为用户提供资源共享等服务,然而其
2010-01-15 15:42:5913 本文介绍了一个基于 P2P 网络建立的全文信息检索系统的路由机制,在实现系统路由时采用了分层机制,将P2P 网络中的节点分成超级节点和普通节点,超级节点间采用非结构化的P
2010-01-15 16:53:275 随着 Windows Vista 和 .NET Framework 3.0 的发布,P2P 应用程序的传统开发门槛将明显降低。技术的进步(如 PNRP、IPv6)加上更具生产力的新型平台的问世(如 PeerChannel 和 PNM)将在 P2P 应用程序开
2010-01-16 15:13:0618 本文首先从P2P 的定义出发,介绍了结构化P2P 与非结构化P2P 的区别以及结构化P2P 的核心技术DHT。而后,本文深入介绍了几种主流的DHT 算法与协议并对每种协议进行了讨论。文
2010-01-16 16:32:4911 P2P VoIP 应用的性能评测摘要 基于IP 技术的语音分组传输(VoIP)电话目前被广泛使用,Skype 与GTalk 是VoIP 应用的两个典型代表。在可控网络环境下,通过调整信道容量、时延、
2010-01-17 09:35:2923 P2P 作为一种崭新的传输模式,不仅能提供隐私保护与匿名通信,还能提高网络的健壮性和抗毁性。然而,P2P 技术也由于其自身存在的一些缺陷,如缺乏相互信任机制和内容鉴别
2010-01-26 17:47:2713 基于P2P 技术的媒体电信网作者:肖遂 张欣 田洪亮融合了 P2P 技术、利用电信运营商业务平台的媒体电信网(MTN)能够提供有服务质量保证、安全诚信的数字媒体业务。与现有客
2010-02-05 08:28:0621 与P2P 技术相关的信息安全问题关键词: P2P 安全 防御体系,IPSec 测试 即时通信 知识产权 网络 计算机IEEE 网络安全 局域网 VPN摘要 本文分析了和P2P 技术相关的信息安全问题,
2010-02-06 17:10:5312 P2P网络是一个自组织的动态网络,对等点可以随意的加入或者离开网络,因此如何控制数据的一致性成了P2P网络平台应用扩展应用的关键点,本文引入数据一致性算法到P2P网络平台中来,
2010-02-25 16:06:2015 提高资源搜索效率、提高网络的扩展性一直是P2P网络的关键技术问题。在分析现有的P2P网络资源搜索的算法及其存在的问题的基础上,作者提出并设计了一种基于“最近Query消息查询
2010-02-26 14:27:5716 分析了几类主要的P2P业务识别方法,重点分析了基于流的内在特征的各种识别方法,并对其优缺点作出评价,指出了P2P识别技术进一步的发展方向。
2010-07-01 18:35:1010 本论文首先,对研究背景进行介绍,并对P2P模式和C/S模式进行分析和对比。其次,根据P2P业务模式的特点和发展趋势,对P2P网络信息交瓦平台进行需求分析。依据分析结果,
2010-08-31 16:11:5610 网络的组织与维护对于P2P流媒体直播系统的性能有着极其重要的影响。根据覆盖网络拓扑组织形式的不同,分别研究了基于单树结构、多树结构、随机拓扑结构的现有P2P流媒体直
2010-08-31 16:13:3413 研究了P2P流量识别与控制技术,分析了国内某运营商现网中P2P业务流量分布情况,并实际试验验证了现网部署P2P业务识别与管控系统的实际流量控制效果,为P2P流量管控策略的制
2010-10-14 16:42:430 P2P网络具有动态性、匿名性、可扩展性等特征。由于P2P应用是一种分散的、去中心化、无控制的自发行为,并且具有匿名发布的特性,如何控制信息内容的安全已经成为一个
2010-11-26 15:33:2020 随着P2P系统的发展,它在Internet上的应用越来越广泛,尤其是对分布式数据对象的查找。为此,提出一种基于对等网络系统的简单查找方法。在假设具有N个固定节点的良好状
2010-12-20 16:21:260 JXTA技术主要用于提供P2P应用系统所需的基础服务。在总结传统B/S架构的远程学习系统许多弊端的基础上,分析JXTA技术的体系结构、核心协议及开发P2P应用系统的优势,利用JXTA技术
2010-12-28 10:51:420 P2P将主导以媒体为中心的网络时代
虽然各种P2P应用占用了运营商大量的网络资源,但他们却深受广大用户
2009-06-15 09:58:00940 什么是P2P下载
大家都知道下载东西会伤害电脑的硬盘,例如迅雷、电驴、比特之类的P2P软件。人人都说“P2P软件猛于虎”,
2010-02-23 14:57:085656 企业P2P通信网络检测与防护技术发展
谈到老北京生活的代表画面,可能很多人都会想到美丽的四合院。可是一旦真的走在北京的大街小巷,身临其境,你可能会发现很
2010-04-12 14:42:55479 P2P网络资源搜索C
2011-01-06 17:13:4839 NI端到端网络(P2P)流技术使用PCI Express接口在多个设备之间直接,点对点传输,而不必通过主处理器或存储器。这可使同一个系统中的设备共享信息而不必占用其它的系统资源。NI P2P技术
2011-03-31 15:55:3126 本文将针对P2P IPTV技术作一简单介绍。首先我们将先介绍P2P IPTV之系统架构以及现况,再针对现有技术之瓶颈,提供解决方法
2011-04-22 11:35:131839 P2P技术将各个用户节点互相结合成一个网络,共享其中的带宽,共同处理其中的信息。P2P网络是去中心,自组织和从单纯意义上来说的动态的(网络),并且为传统的服务器-客户端计算模
2011-06-14 09:41:501810 对等(P2P)计算是未来网络中的关键技术,对等网络是实现下一代互联网的重要组成部分。如何高效地搜索P2P 网络上的资源是P2P 网络实现的最为关键的问题。在讲述对等网络的基本搜
2011-06-28 17:11:2820 本文从铁路公安网络的特点出发,研究了基于JXTA平台的P2P网络传输方案,本文的研究成果对其它专用网络P2P应用程序的设计具有重要的参考价值。
2011-08-17 16:43:132537 
目前在宽带网络上实现时移电视业务主要有两种思路,即基于C/S模式的IPTV建设方案和基于P2P技术的P2P叠加网络方案。
2011-09-17 01:21:541579 
P2P网络作为一种覆盖网络,邻居节点的选择若不考虑网络层、物理层信息,将导致较低的数据传输速度和不必要的跨运营商流量,从而大大限制P2P技术的应用。位置感知策略可以解决这
2011-10-10 16:34:2121 P2P流量占网络流量的50%左右。这些流量占用了大量的网络带宽,是运营商非常头痛的问题。如何对付P2P流量,无非有三种办法:堵、疏、堵疏结合。
2011-10-14 14:56:321412 高通推出了近距离P2P通讯技术AllJoyn,两台同样使用AllJoyn技术的设备可以快速实现数据共享。
2011-11-08 09:19:06900 从电信运营商的角度分析了CDN技术和P2P技术在流媒体分发和交付系统中各自的特点。在此基础上,将CDN与P2P 技术相结合,提出CDN+P2P架构,并阐述了该架构实现流媒体分发和交付系统的优
2012-04-13 15:00:4116 提出了一种基于CDN 网络的P2P 验证方法,有效解决了P2P 网络的用户验证问题。具体的实现方法是:首先分析了P2P 网络的系统架构,接着探讨了基于CDN 网络的P2P 验证原理,最后提炼出基
2012-04-13 15:08:1423 P2P和CDN融合实现流媒体业务是一种高效实用的方案。本文首先对P2P和CDN技术的优缺点进行分析比较,指出二者融合的优势,然后介绍并分析了P2P和现有CDN融合实现流媒体业务的几种解决
2012-04-16 14:00:5725 在CDN和P2P两种主流的流媒体分发技术的基础上,提出了基于系统流量的混合流媒体分发模型,根据系统中节点数量和媒体流量之间的关系,在CDN自治域内实现CDN和P2P的混合式服务,并对上述理
2012-04-17 14:53:1729 P2P网络应用快速发展,带来网络安全防护漏洞和隐患。如何有效地监控P2P流,进行相关的流识别、流筛选、流控制是流管理中的重要问题。通过分析P2P协议及签名特征,提出一种基于签
2012-05-28 17:38:1629 P2P网络摄像机系统及运营
2017-01-14 02:36:100 应用P2P技术的互联网电机控制方法_王湛昱
2017-01-07 18:39:171 P2P网络流量分类对网络管理和网络安全有着十分重要的意义,由于目前P2P流量多样化的发展,传统单一的P2P流量分类方法很难对其准确分类。通过分析现阶段P2P流量分类方法的现状,结合现有P2P流量分类
2017-11-23 11:06:506 信息技术的不断发展促进了网络信息资源向有序化方向发展,同时,随着社会对物质、资金、知识等资源的需求增加和互联网技术的进步,P2P业务模式呈现爆炸式发展。图书是高校师生获取知识的重要来源,对师生
2017-12-01 11:45:380 P2P技术优点:非中心分散化:将以服务器为中心的服务分散到各个网络节点,避免出现服务器性能瓶颈;扩展性:随着更多的用户加入,网络整体资源和服务得到了提升和扩充;
2017-12-16 10:05:2033305 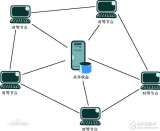
近年来,P2P技术作为一种新型的网络计算技术蓬勃兴起,已经被广泛地应用于信息管理系统领域,具有广阔的发展前景。P2P信息管理系统中各结点的地位平等,每个结点既是客户机又是服务器,不依赖于任何中央
2017-12-19 10:53:040 针对当前隐匿恶意程序多转为使用分布式架构来应对检测和反制的问题,为快速精确地检测出处于隐匿阶段的对等网络( P2P)僵尸主机,最大限度地降低其危害,提出了一种基于统计特征的隐匿P2P主机实时检测系统
2018-01-07 11:25:540 在采用IEEE 1588协议实现时间同步的智能变电站自动化系统中,交换机的时钟模型一般选取为P2P(对等)透明时钟,因此研究P2P透明时钟驻留时间误差的测试方法,对于评估交换机作为P2P透明
2018-01-15 16:55:255 提出了一种基于价格的P2P匿名通信系统激励机制,通过对P2P系统和匿名通信系统研究中提出的激励机制进行归纳和分析,对搭便车用户给P2P匿名通信系统造成的影响进行定性和定量分析.提出在P2P匿名通信
2018-01-18 14:50:080 随着分布式技术的发展和互联网络的普及,P2P技术已广泛应用于协同系统、资源共享、网格计算、及时通信等环境,成为当前重要的网络应用技术。 在传统的C/S模式中,服务器是网络的核心,所有事务都离不开
2018-02-08 11:31:330 p2p汽车共享不仅仅是一个梦想,也不仅仅是kickstarter初创公司的创意。随着越来越多的汽车制造商加入,这是一个日益增长的现实,比如通用汽车(GeneralMotors)推出的Maven P2P汽车共享平台。
2018-08-22 08:25:372296 P2P网络根据其路由查询结构可以分为四种类型,分别是集中式、纯分布式、混合式和结构化模型。这四种类型也代表着P2P网络技术的四个发展阶段。
2018-11-28 11:02:418439 p2p实现原理什么是打洞,为什么要打洞由于Internet的快速发展 IPV4地址不够用,不能每个主机分到
2018-12-09 10:50:146793 P2P全称点对点的互联网金融网络借贷中介平台,能够合理地调配民间资本,有利于中小企业的发展。从经济角度来说,P2P有利于民间资本的流通,将社会闲置资金整合,流动到最需要的人手中。P2P的借贷功能
2019-01-31 15:38:001175 P2P发展前景如何我们一起来探讨分析,既然很火说明前景也不会很差。 P2P从2016的监管元年到2017年的合规元年再到2018年的备案元年,整个行业不论是法律法规的健全还是监管制度以及平台要求都是走向美好的未来。
2019-01-31 15:44:004196 比特币采用了基于互联网的点对点(P2P:peer-to-peer)分布式网络架构。比特币网络可以认为是按照比特币P2P协议运行的一系列节点的集合。
2019-04-23 10:58:166787 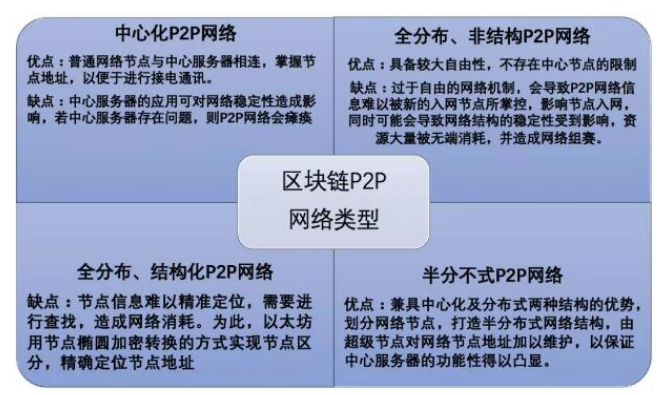
雅特力MCU,国产32位M4单片机,P2P替代STM32
2022-12-08 15:35:003050 
安信可推出TurMass-LPWAN TK8610 evb开发板! TurMass™ P2P 开发套件,简称 P2P 开发套件,主要展示采用 TurMass™技术终端芯片所研发产品的各项功能和性能
2023-08-21 15:16:171318 
文字聊天等)。 P2P可以是一种通信模式、一种逻辑网络模型、一种技术、甚至一种理念。在P2P网络中(如右图所示),所有通信节点的地位都是对等的,每个节点都扮演着客户机和服务器双重角色,节点之间通过直接通信实现文件信息、处理器运算
2023-11-13 10:52:195316 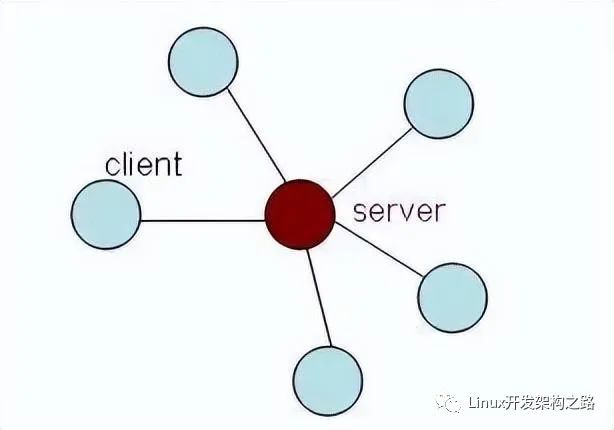
 电子发烧友App
电子发烧友App











 工商网监
工商网监
评论