 电子发烧友App
电子发烧友App


引言
课题研究背景
智能交通系统是将先进的信息技术、移动通信技术和计算机技术应用在交通网络,建设一种全方位的、实时准确的综合运输和管理系统,实现道路交通和机动车辆的自动化管理。自动化的发展在交通管理领域产生了一系列的应用,比如道路收费、车载导航系统和车联网等。这些应用对于车辆的识别检测、安全管理也提出了越来越高的要求。
车牌识别系统研究现状及难点
车牌识别系统,采用的主要方法是通过图像处理技术,对采集的包含车牌的图像进行分析,提取车牌的位置,完成字符分割和识别的功能。随着计算机技术的发展,对于单个字符的识别已经有非常完善的解决方法,车牌识别系统准确性主要受限于图像信息的获取,识别失败也大多数是由获取图像不理想导致。存在的问题包括车牌图像的倾斜、车牌自身的磨损、光线的干扰都会影响到定位的精度。对于车牌识别系统来说,识别车牌的准确性和快速性往往是互相矛盾的存在,快速实时的捕捉和处理图像往往会使用来识别的字符产生较大的失真,而不能满足识别算法的要求,同时为了保证车牌识别的准确性经常会牺牲识别的速度,比如需要车牌在摄像头前保持更长的一段时间才能完成识别。
1、设计和系统模块概述
1.1 作品介绍
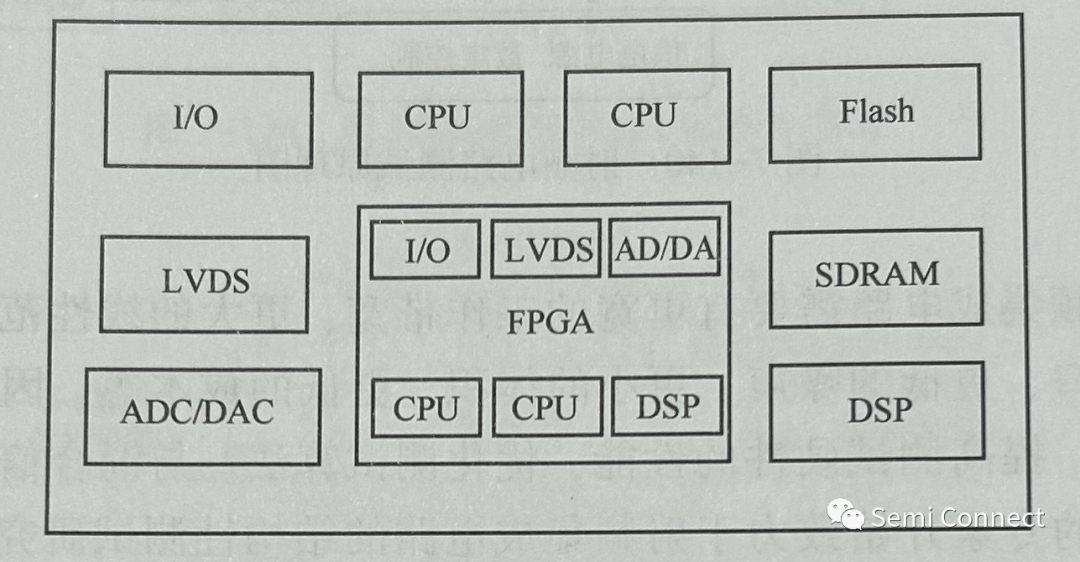
本作品是基于紫光PGT180H的车牌识别系统,包括了紫光开发板、带FIFO的OV7725摄像头、像素为320x240的LCD显示屏以及搭载了摄像头和LCD的PCB板。
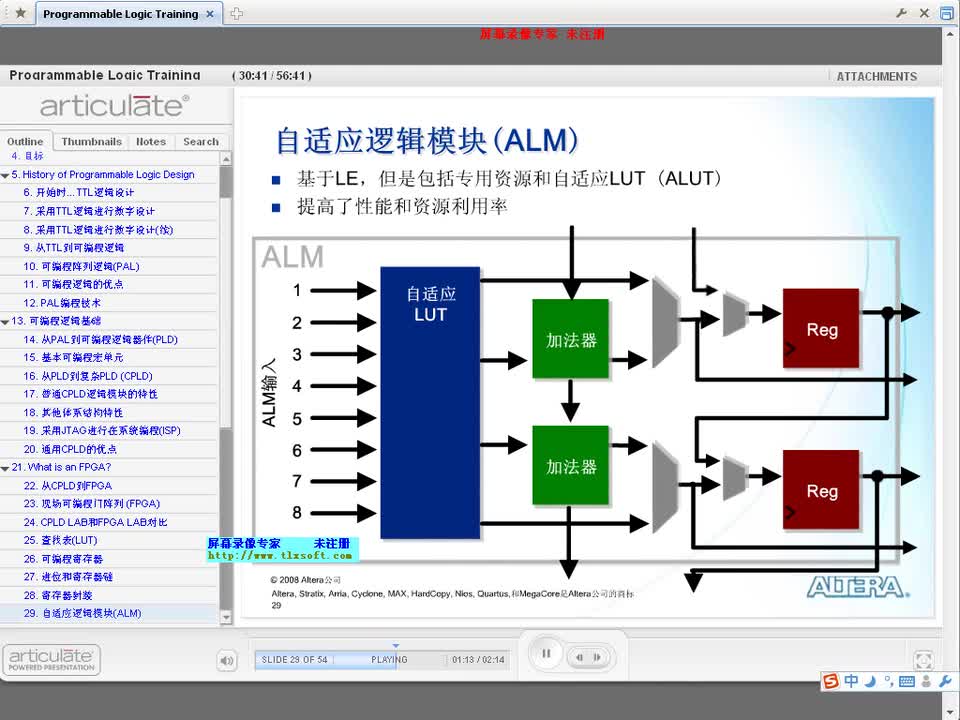
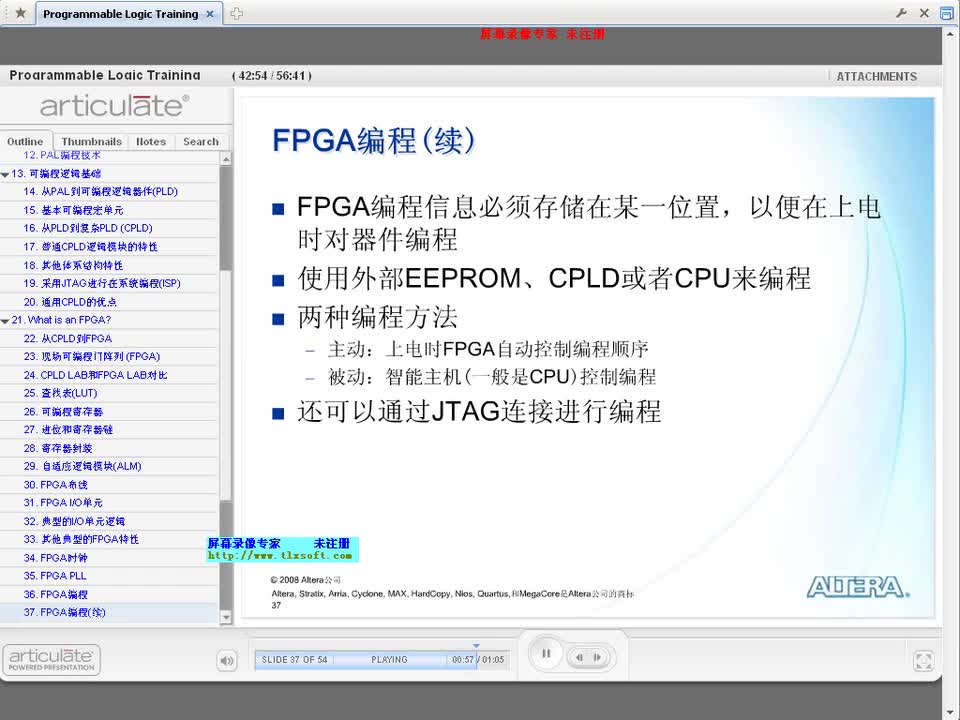
系统采用OV7725摄像头采集图片,通过RGB转HSV的模块并根据HSV值提取出蓝色部分,经过detect模块检测有无车牌,然后对图像进行处理得到车牌的四个顶点,利用线性内插的方法获得固定大小的图像,提取出车牌中的7个包含字符的图像矩阵,然后使用训练好的神经网络分别对其进行运算分析,最后识别出结果并显示到LCD上。
本项目的具体工作如下。
⑴车牌定位检测。针对摄像头获取的图像受到车牌模糊、光照强度的影响,采用HSV格式的图像二值化方法,提出了一种通过扫描二值化图像检测车牌四个顶点的方法,得到了车牌的位置区域,根据设定判断依据检测车牌是否存在于摄像头前,检测成功后自动完成识别功能。
⑵字符分割。根据已经提取的图像定点,采用一种线性内插的方法将原始图像转换为固定大小图像,这一方法也可以适应发生旋转后的车牌,再将固定大小的图像顺序分割成单个字符用来识别。
⑶字符识别。采用神经网络算法完成字符识别功能,将已经训练好的神经网络矩阵存在存储器中,在FPGA上建立相应并行与流水线结构的乘累加模块设计,利用查找表以及线性内插的方法对激活函数sigmoid进行逼近,提高计算精度和算法效率。
1.2 系统工作流程
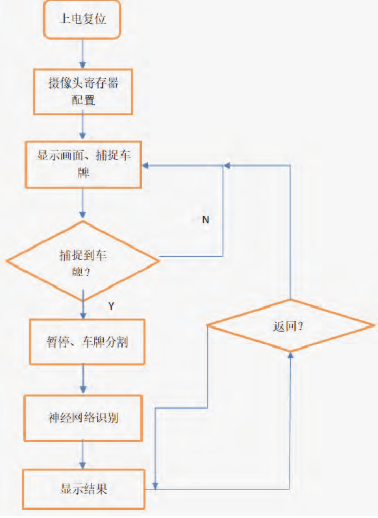
上电后,先进行摄像头寄存器配置,然后将摄像头捕捉到的画面显示到LCD显示屏上,同时RGB转HSV和detect模块运行;一旦detect模块提取到车牌,LCD画面将转化为暂停的黑白画面,紧接着运行车牌分割和显示的模块image_pro和segment,然后是神经网络识别车牌,最后将结果显示至LCD左侧并且暂停。若想进行第二次识别,则按下按键将会回到摄像头捕捉画面的状态。
2、车牌检测和图像处理
2.1 HSV格式
从摄像头获得RGB565值的大小会随着环境光线的变化而变化,直接利用RGB三个值进行二值化是很困难的,我们采取将RGB格式转换成HSV格式,再设置二值化相应的阈值。HSV分别表示色相、饱和度和亮度。其中主要的二值化指标是色度和饱和度,表示偏向某个颜色和偏向的尺度,通过判断色相和饱和度,我们将车牌中蓝色的部分提取出来供后面使用。
我们使用的阈值如下:饱和度大于30,色相大于200 且小于280,亮度大于30。
2.2 图像检测
提取出蓝色部分后,利用算法找到车牌的四个顶点,通过四个顶点的相对位置,所表示的矩形的长宽比来检测车牌是否被放在摄像头正前方。
为了提取出车牌,我们需要分析车牌的特征。在画面中,车牌占了一大部分,意味着连续的行和列都会呈现蓝色,车牌的四个顶点分别位于左上、左下、右上、右下,所计算出的长宽比在1:3到1:4内。检测算法如下。
⑴一行一行地遍历整幅图。
⑵当一行中检测到连续的10个蓝色点时,flag10赋值为1,视为检测到车牌的初步状态,当连续的10个蓝色点消失时,flag10赋值为0。
⑶当flag10为1时,记录连续点中的左顶点和右顶点。
⑷记录车牌的左上、左下、右上、右下的坐标,即每次的左右顶点分别计算x+y和x-y的最大最小值与所记录的坐标进行比较。
⑸若存在连续的10行,flag10都被赋值为1,视为找到了一大块蓝色区域。
⑹当遍历完整幅图并且找到了蓝色区域之后,计算长宽比,达到要求后视为找到了车牌。
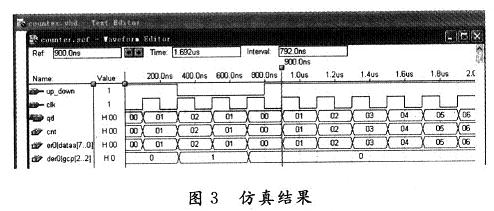
⑺MATLAB进行的算法验证,如图2所示。
2.3 图像分割
在车牌检测模块是我们已经提取出来了4个顶点的坐标,通过其中的3个顶点,可以将车牌部分映射到大小为1687的图片中,设新图片中的点坐标为,根据以下公式完成图片映射。
图形分割方法如下:按行和列将上图分割成7个字符,每个字符出去最边缘一行,再将上图中红色框内的点出去,最终得到71410的字符存进RAM中。
映射与图形分割的效果如图3。
3、神经网络与字符识别
3.1 神经网络算法
3.1.1 神经网络的设计
前文中,我们已经将车牌上的字符提取了出来,每个字符都是一个1410的由0、1构成的矩阵。已经完成了卷积神经网络中类似池化的操作,我们不太需要更加复杂的CNN网络,而可以使用最简单的神经网络结构。
于是我们设计了如下的神经网络。
⑴整个神经网络由3层感知机组成,输入层、隐含层和输出层。
⑵输入层140个神经元,对应1410中的每个像素点;隐含层80个神经元;输出层34个神经元,可分别对应10个数字和24个除去I、O的字母(车牌中这两个字母由于和1、0比较像,故不存在),或34个省级行政区域。
⑶输入层无激活函数,仅隐含层和输出层含有激活函数sigmoid。
3.1.2 神经网络的训练
神经网络的训练采用了梯度下降法,通过误差反馈调整权值矩阵以减少误差,使得神经网络的输出逐渐收敛至我们想要的输出。
3.2 FPGA实现模块
神经网络中包含两种运算,分别是矩阵乘法和sigmoid函数映射的运算,主要通过以下的模块实现。
3.2.1 选择累加模块
本模块神经网络的第一层计算,将输入的1410的二值化像素点的向量和训练完成的神经网络权值矩阵W1相乘,得出结果,结果输出至sigmoid模块。因为图像点阵数据格式已二值化,仅含有数字0、1,所以做乘法时相当于在做选择,故采用选择累加的方法计算向量与矩阵的乘积。
3.2.2 sigmoid模块
Sigmoid函数是一个连续的函数,但是FPGA难以直接地计算该函数,于是我们通过通信中PCM编码得到的灵感,找到斜率为2的幂次方的折线段的端点坐标存入查找表,对输入的x即可找到对应区间,然后通过移位即可进行对sigmoid曲线的线性逼近。
3.2.3 乘累加模块
本模块中,神经网络中第一层算出的80个结点为输入,与训练完成的神经网络权值矩阵W2进行矩阵运算。模块调用乘累加IP核,在模块内调用神经网络的权值矩阵rom2,与顶层的ram2读取的80个结点数据进行乘累加运算,每次运算完成后进行数据的流水输出至Sigmoid模块,同时给出相应ram写入使能的控制。当接收到开始信号有效,模块开始工作,结束后输出完成信号。
3.3 神经网络训练
神经网络的训练应采用准确的数据进行训练,才可以达到完美的训练效果。于是我们在FPGA上实现了车牌的字符提取之后,编写了一个串口通信模块,将采集好的字符矩阵传输至电脑端,并以此作为训练数据。在MATLAB上将权值矩阵训练好以后,存储进FPGA的矩阵。
4、硬件实现结果
4.1 硬件实现
我们使用OV7725摄像头和LCD作为外设,负责图像的采集和输出显示,自行设计了PCB板,该外设可以通过插拔的简单方式连接起来,上电后可以直接使用。
4.2 结果验证
图4是系统实现的最终效果图,我们的车牌对经过轻度旋转的图像也有很好的处理效果,在做板级验证的时候,我们也测试了轻度旋转的图片识别,可以看出,该系统成功地识别出了车牌。
5 、创新点
本作品利用FPGA可编程逻辑器件和简单的系统设计,实现了准确性较高的车牌识别系统,创新的采用HSV格式用作图片二值化方法,获得了很好的区分效果,能够适应光线变化的不同场景,图像的提取和字符分割也取得了理想的效果,保证了车牌识别的正确率,实现了以神经网络为核心的专用FPGA图像识别处理器及结构,将神经网络和图像处理模块在FPGA芯片上实现。
责任编辑:gt












 工商网监
工商网监
评论