 电子发烧友App
电子发烧友App


与传统ASIC相比,FPGA和结构化ASIC的优势在于重用灵活性高、上市时间快、性能佳而成本低。FPGA和专用的IP模块可用于现有的商用AdvancedTCA平台,可用来开发可扩展的交换接口控制器(FIC),以加快产品开发的设计并使线卡方案具有鲁棒性和成本效益。
当今通信和计算系统制造商正在基于模块化系统架构设计下一代平台,以缩短开发周期、降低新设备的资本开支,并在增加新功能和服务时最大限度地减少运营费用。模块化平台使设备制造商能够在一套通用的构建模块上设计多种类型的系统,从而通过实现一定的规模经济效应保持竞争力。

图1:一个SPI4.2到ASI交换接口控制器的功能图。左边是SPI4.2到NPU的接口,右边是ASI到交换结构的连接。
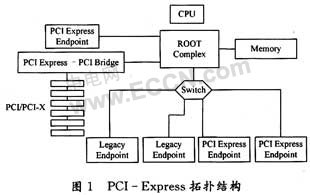
实现模块化的必不可少的一步是使设备制造商共同创建一组用于电路板和机架的通用物理互连标准。AdvancedTCA就是由PCI工业计算机制造商组织(PICMG)定义的一种系统构造参数,它为诸如机架尺寸、线卡、I/O模块、交换接口(星状和网状结构拓扑)、额定功率等等平台单元提供了标准规范。AdvancedTCA标准的主要目标是提供一个基于标准的硬件平台,这个硬件平台由机架和存储刀片、网络处理器卡、控制平面刀片,以及管理模块的组合来构建模块化运营级产品,这些产品针对电信接入汇聚平台和边缘平台应用。
AdvancedTCA背板接口的工业标准集的定义,使系统集成商在他们的交换接口卡和线卡之间互连具有更大的灵活性和互操作性。AdvancedTCA网络接口采用开放的接口协议,并采用子规范PICMG 3.1-3.5提供可互操作的电路板。这些子规范支持以太网、光纤通道、Infiniband、PCI Express、StarFabric、高级交换互连(ASI)和串行RapidIO。一些大型OEM向AdvancedTCA规范的转移标志着从定制、专有的和基于互连的平台向基于开放标准的COTS平台转移。
PCI Express和ASI
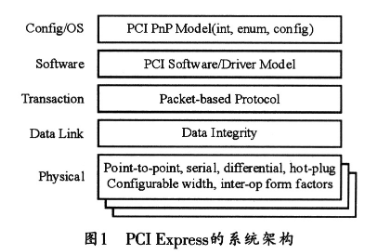
系统可扩展性和模块化需要通用互连以支持多种应用中芯片和/或子系统的无缝集成。随着背板性能从40Gbps提升到160甚至320Gbps,必须仔细设计以确保交换结构和数据流源头之间的接口不会出现传输瓶颈。交换接口必须在支持关键的结构需求,诸如数据吞吐、流控制和按流排队的同时,以良好的信号完整性高效地传输2.5Gbps到超过10Gbps的数据流。

图2:包含ASI报头、可选的PI0和PI1报头及一个PI2报头的TLP。
PCI Express和ASI是两种标准的交换结构技术,它们有潜力使标准、最新的交换设备和交换接口器件的市场急剧增长。PCI Express具有跨越从计算到通信生态系统的制造、技术支持和产品开发的经济规模。把PCI Express移植到串行互连的好处在于:具有物理和性能上的可扩展性;改善了可靠性;实现了全双工传输;布线和电缆连接更简单、成本更低。
ASI通过定义兼容的扩展来增强PCI Express,从而解决诸如对等通信的支持、QoS、多播和支持多协议封装的要求。PCI Express和ASI是互补协议,许多系统两者都采用以满足目前尚无法实现的设计要求。随着新型组帧器、网络处理单元(NPU)和交换结构采用ASI,有必要将ASI与其它接口规范桥接起来,例如与SPI3、SPI4.2和CSIX桥接。这种桥接功能可以方便地与交换接口控制器集成在一起。
FIC架构:
一个SPI4.2到ASI控制器的功能(图1)包括:
1. ASI到SPI4.2的双向桥接,可从2.5Gbps扩展到20Gbps(x1、x4或x8路);
2. 为端点和桥接组装和分拆ASI事务层数据包(TLP);
3. 支持1到64,000个连接队列(CQ);
4. 在SPI4.2上支持多达16个通道;
5. 可编程通道映射到SPI4.2;
6. 支持一个可旁路的、三个有序的和一个多播虚拟通道(VC);
7. 可编程最大数据包长度为64到80字节;
8. 链路层基于信用量的流控制;


图3:PI2封装示例。通过去除SPI4.2协议控制字(PCW)并增加ASI报头、可选PI0和PI1报头以及PI2报头,初始SPI4.2突发数据流被转换到ASI TLP之中。
9. CRC生成和误码校验;
10. 处理连续的背靠背数据包结束符(EOP);
11. DIP4奇偶位生成和校验;
12. 状态通道组帧、DIP2生成和校验;
13. 状态同步生成丢失和检测;
14. 训练序列生成和检测;
15. 全同步设计(800Mbps);
16. 与OIF兼容的SPI4阶段2;
17. 与ASI-SIG兼容,ASI核心架构规范修订版1.0。
在SPI4.2到ASI方向,必要时对进入的SPI4.2数据包进行分段,并根据流量类型(单播或多播)和等级映射到VC FIFO缓冲器。用户在SPI4到VC映射表中对缓冲到SPI4.2接口的通道映射信息进行编程,接口上的数据包按照表中所示传输到相应的缓冲器。ASI调度器读取队列并将TLP发送到交换结构。
每一个SPI4.2通道FIFO缓冲器的填充水平被转换为“空虚-未满-饱满”状态,并通过接收状态通道(RSTAT)发送到对等的SPI4.2发送器。当有空间时,在SPI4.2接口上接收的数据包被传输到相应的VC FIFO缓冲器。
SPI4.2和每一个VC支持最多16个通道(通道0到15)。下面是从SPI4.2到VC的示范通道分配:
1. SPI4.2通道0到7被映射为8个可旁路虚拟通道(BVC);
2. SPI4.2通道8到11被映射为4个有序虚拟通道(OVC);
3. SPI4.2通道12到15被映射为4个多播虚拟通道(MVC)。
ASI到SPI4.2的输出数据包流
在ASI到SPI4.2方向,采用可编程地址映射表(图2),从指定VC的交换结构输出的ASI TLP和流量等级被映射到16个SPI4.2通道中的一个。用户在VC到SPI4表中对VC到SPI4.2接口的通道映射信息进行编程。数据复用(MUX)记录表RAM(VCS4记录表RAM)包含从VC接口FIFO缓冲器读数据到把数据传送至SPI4.2接口的调度。VCS4记录表RAM有16个位置。
VCS4数据MUX和地址映射模块根据VCS4记录表RAM规定的顺序从VC FIFO通道读数据。SPI4.2源模块在必要时分拆队列并重组数据包,增加SPI4.2有效载荷控制操作,并通过SPI4.2接口将它们发往NPU。SPI4.2源模块也执行信用量管理,并根据从对等的SPI4.2接收器收到的流控制信息进行调度。
ASI提供若干协议接口(PI),它们提供可选功能或使各种协议适配到ASI基础架构。
协议接口描述
PI0封装被用于多播路由。为0的第二个PI表示生成树数据包,非0的第二个PI表示多播路由,多播组寻址通过多播组索引字段实现。
PI1将连接队列识别信息传递到下游对等交换单元或端点。当发生拥塞时,下游对等交换单元可以发送识别上游对等交换单元的违规连接队列的PI5拥塞管理消息。
PI2提供分段和重组(SAR)服务及封装。PI2报头包含有利于数据包描述的包起始(SOP)和包结束(EOP)信息。此外,PI2封装规定了可以在PI2容器内排列有效载荷数据的可选前置块(PPD)和末块(EPD)字节。
如果SPI4.2突发数据包长度与ASI TLP有效载荷长度相等的话(图3),PI2封装可以用于描述数据包并将数据流映射到关联域(Context)。此时,所接收到的SPI4.2突发数据已经被分段为ASI接口支持的有效载荷长度。因此,以数据包描述的观点来看,PI2仅仅需要表示SOP和EOP。
对于中间的突发数据,PI2 SAR代码就是“居中的”。注意,由于非EOP SPI4.2突发数据必须是多个16字节,所以中间数据包SPI4.2有效载荷将始终是32位排列,与ASI有效载荷匹配。
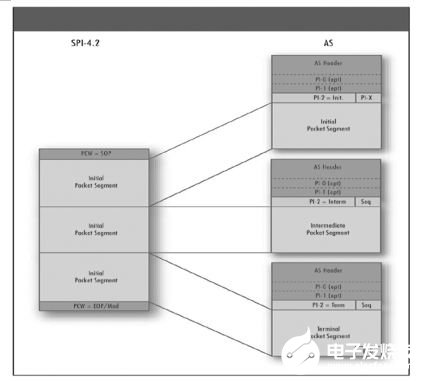
图4:在PI2分段的例子中,SPI4.2数据包被分为三个ASI TLP,去掉了SPI4.2协议控制字,对于每一个TLP,ASI报头要加上可选的PI0和PI1报头及PI2报头。
对于终端突发数据,如果在最后的TLP字中的所有字节都有效或与末块终接(terminal with end pad),则PI2 SAR代码就是“终端”,来表示最后的字中有效字节的数目。
如果SPI4.2突发数据包长度超过ASI TLP有效载荷长度的话,PI2 SAR被用于将SPI4.2数据包分段和重组。接收到的SPI4.2突发数据包在桥接中被分段为ASI接口支持的有效载荷的长度(图4)。
至于封装,三个TLP的PI2 SAR代码被分别设置为代表“初始”、“中间”和“终止”或“末块终接”。对于重组,来自每一个关联域的AS片段被重组成完整的数据包。一旦获得完整的数据包,它就被映射到一个SPI4.2通道并在突发数据包中输出。来自SPI4.2不同通道的突发数据包可以交织在一起。
映射流量类型、等级和目的端口
交换接口必须与数据一起传输若干重要属性。这些属性包括流量类型(单播或多播)、等级、目的端口和拥塞管理。这些参数都在AS中得到支持。然而,在SPI4.2中,该信息被映射在SPI4.2通道编号中或SPI4.2有效载荷内的专有报头。
SPI4.2利用三级拥塞指示(空虚、未满、饱满)进行基于信用量的流控制。通过预置与空虚和未满状态相对应的最大突发数据量(Maxburst1和Maxburst2),发送器会再次装满信用量。
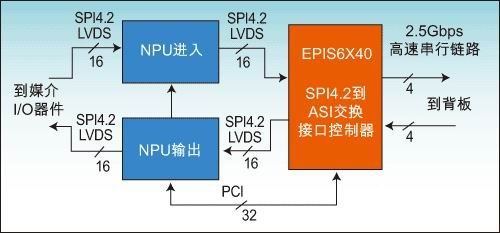
图5:典型单10Gbps端口中的双网络处理器及配备专用FIC的全双工线卡。
ASI具有多个流控制选项:VC,它是一个基于信用量的流控制;用于源速率控制的令牌桶;按照类或者流队列的基于状态的流控制。
桥接内的拥塞管理是桥接架构和缓冲机制的不可缺少的组成部分。桥接可以采用两种基本架构,或者采用具有很少或没有缓冲的直通(flow-through),或者每一个接口采用单级或两级缓冲。
在直通架构中,流控制信息被生成并在外部作用于桥上。该方法简化了桥的设计,但是,增加了源和流控制的目的端口之间的延迟时间,因此可能需要增加缓冲资源。
在有缓冲的架构中,桥接本身遵照流控制信息,因此需要内部缓冲。内部桥接缓冲可以由两个接口共享(单级),或每一个接口配备自己的关联缓冲器,称为两级缓冲处理。
入口网络处理器接收端口被配置为物理器件接口的SPI4,而发送端口被配置为交换接口的SPI4.2,连接到专有的FIC(图5)。FIC支持全双工SPI4.2接口和多达24个速率为2.5Gbps的全双工PCI Express SERDES(串行化/解串化)链路,一个10Gbps的全双工链路端口需要4个SERDES链路。不用的SERDES链路可以通过器件配置寄存器的设置来关闭供电。在这个10Gbps的例子中,NPU通过PCI本地总线接口配置EP1SGX40内部的“配置和状态”寄存器。
专有FIC参考设计
专有FIC参考设计平台是采用英特尔的IXDP2401先进开发平台设计和验证的。AdvancedTCA机架把连接AdvancedTCA高速交换接口的两个IXMB2401网络处理器承载卡(carrier card)互连起来,承载卡是采用一块IXP2400处理器设计的PICMG3.x兼容板。承载卡采用标准组件结构,包含4个子卡槽位和一个可选交换接口子卡槽位,以便连接到AdvancedTCA背板上区域2的交换接口引脚。
专有的、基于FPGA的交换接口子卡(mezzanine card)槽位的设计使其可插入承载卡,并提供一个可重配置的FIC和可选的流量管理开发板。FIC使处理器与AdvancedTCA交换结构相互连接。利用包含兼容PCI Express与XAUI的多通道收发器的可重复编程器件,可以提供可扩展的开发平台,以便快速设计和验证2.5Gbps到10Gbps的AdvancedTCA FIC设计(图6)。
工作模式
参考设计的主要工作模式接收来自处理器入口端的32位SPI3或16位SPI4.2数据,通过FPGA集成收发器将数据流传输到AdvancedTCA背板,并将背板数据流通过32位SPI3或16位SPI4.2接口传回处理器的出口端。
集成收发器经由处理器的SlowPort出口来配置。参考设计支持若干其它工作模式,包括SPI4.2接口环回、ASI接口环回、流量管理、交换结构数据包生成和监测。
FPGA和结构化ASIC FIC
采用专有的多FPGA和结构化ASIC技术,可以开发可扩展的PCI Express、ASI桥和端点。内建兼容PCI Express收发器的高密度、高性能的FPGA,可以提供:1. 具有可扩展的2.5链路的整体解决方案;2. 对每一个通道运行速率高达1Gbps的接口进行动态相位校正(DPA);3. 多种封装选择和高达40,000逻辑单元的密度选项。

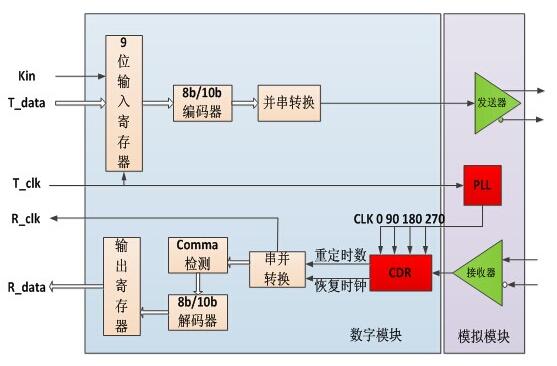
图6:功能模块框图。
可选的FPGA结合独立的兼容PCI Express的SERDES,如PMC-Sierra的PM8358 QuadPHY 10GX器件可用于对成本的关注超过对性能和扩展功能需求的应用,从而提供低成本的1x、2x和4x(路)灵活的解决方案。高密度、高性能FPGA与独立的、兼容PCI Express的SERDES的结合,可被移植到专用的结构化ASIC,以提供所需要的最高密度、最快性能和最大数量的应用。
责任编辑:gt













 工商网监
工商网监
评论