本文采用的是ALTERA公司的EP1C6Q240C8型号的FPGA,整个体统采用模块化设计的思想,将各个模块用VHDL语言描述出来再进行连接。
2020-08-04 09:39:44 1670
1670 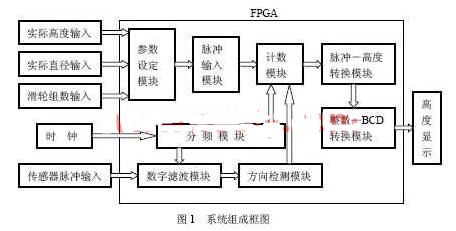
该系统采用C8051系列单片机中的 C8051F121作为控制器,CvcloneⅢ系列EP3C40F484C8型FPGA为数字信号算法处理单元。
2015-02-03 15:58:265087 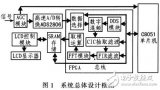
EP2S60F484I4N特价 EP2S60F484I4N货期EP2S60F484I4N 价格EP2S60F484I4N国宇航芯特价订货EP2S60F484C4N国宇航芯特价订货
2020-01-06 09:07:44
采集数据中的量化噪声,在进行数据压缩前采用滤波的预处理技术。介绍LZW算法和滑动滤波算法的基本理论,详细阐述用单片FPGA实现两种算法的方法。最终测试结果表明,该设计方案能够有效滤除数据中的高频噪声
2010-04-24 09:05:21
的数目之外,就是采用可编程逻辑器件,主要是FPGA芯片来实现。本课程以DSP设计在FPGA芯片上的开发为主线,遵照由浅入深的基本步骤和思路进行详细讲解,每一个知识点都给出了基于ISE(HDL语言
2009-07-21 09:22:42
H.264。采用TI公司1GHz主频的DSP芯片需要4颗芯片,而采用Altera的StraTIxII EP2S130芯片只需要一颗就可以完成相同的任务。FPGA的实现流程和ASIC芯片的前端设计相似
2020-10-26 14:35:32
最近,需要使用fpga实现iec-61850-9-2报文编码,设计中涉及到的 字段非常多,以至于逻辑特别复杂,占用资源太多,设计的频率上不去。有没有哪位同道做过fpga报文编码类的设计,请不吝赐教。
2013-11-12 23:20:19
fpga实现滤波器fpga实现滤波器在利用FPGA实现数字信号处理方面,分布式算法发挥着关键作用,与传统的乘加结构相比,具有并行处理的高效性特点。本文研究了一种16阶FIR滤波器的FPGA设计方法
2012-08-12 11:50:16
。本文研究了一种16阶FIR滤波器的FPGA设计方法,采用Verilog HDI语言描述设计文件,在Xilinx ISE 7.1i及ModelSim SE 6.1b平台上进行了实验仿真及时序分析,并探讨了实际工程中硬件资源利用率及运算速度等问题。
2012-08-11 18:27:41
,采用核心板和底层板结合的硬件结构。系统原理框图如图1所示,FPGA 芯片采用Atera 公司的Cyclone Ⅱ 系列EP2C5Q208C8N,它采用90 nm 工艺,具有4 608个逻辑单元。此外
2019-06-24 07:16:30
在单片上集成实现。由于现代电子技术的飞速发展,可编程逻辑芯片FPGA的集成度越来越高,受到很多厂家和研究机构的关注,利用它的可编程性和可扩展,可将绝大部分的功能集成到FPGA芯片中。如文献采用FPGA
2019-05-16 07:00:09
就已经出现,随着FPGA芯片价格的不断降低,其在工业领域的应用正在飞速发展,采用FPGA来实现SVPWM调制算法也将层出不穷2. 系统任务分析及实现SVPWM调制算法相对比较复杂,在完成系统控制任务
2022-01-20 09:34:26
CAS。我们的设计(图1)采用Altera公司Cyclone III系列型号为EP3C16F484C6N的FPGA作为控制器,以Micron公司生产的型号为MT47H16M16BG-5E(16M
2019-05-31 05:00:05
CAN过滤器的配置(f103 hal1.8 系列)can的过滤器的配置是对can接收到的报文进行过滤的配置,在STM32芯片中,可以对can的报文进行过滤,从而省略cpu的处理过程。can的过滤模式
2021-08-19 06:11:28
我现在使用CC3200 transceiver mode,我想将报文过滤下,请问transceiver mode下支持sl_WlanRxFilterAdd 过滤条件添加吗?如果能,我想要根据field:FRAME_SUBTYPE_FIELD来过滤,能给一个例子吗
2016-04-27 10:12:25
FPGA实现的 FFT 处理器的硬件结构。接收单元采用乒乓RAM 结构, 扩大了数据吞吐量。中间数据缓存单元采用双口RAM , 减少了访问RAM 的时钟消耗。计算单元采用基 2 算法, 流水线结构, 可在
2017-11-21 15:55:13
的要求和FPGA芯片设计的灵活性结合起来,采用Alter公司的CycloneⅡ系列FPGA芯片EP2C35F672C8,用VHDL语言编程,最后分别使用Quartus Ⅱ和Matlab软件开发工具验证实现
2010-05-28 13:38:38
求助!STC12C5A60S2无法实现开平方算法(sqrt函数),以及atan2和asin怎么办?我已经包含了相关的头文件了,但是编译通不过。
2020-05-20 09:07:38
下面内容为转载:一、在STM32互联型产品中,CAN1和CAN2分享28个过滤器组,其它STM32F103xx系列产品中有14个过滤器组,用以对接收到的帧进行过滤。1、过滤器组 每组过滤器包括了2个
2021-08-23 07:29:40
TC39x的can报文过滤规则怎么设置
2024-02-19 06:12:48
处理器的数目之外,就是采用可编程逻辑器件,主要是FPGA芯片来实现。本课程以DSP设计在FPGA芯片上的开发为主线,遵照由浅入深的基本步骤和思路进行详细讲解,每一个知识点都给出了基于ISE(HDL语言
2009-07-21 09:20:11
处理器的数目之外,就是采用可编程逻辑器件,主要是FPGA芯片来实现。本课程以DSP设计在FPGA芯片上的开发为主线,遵照由浅入深的基本步骤和思路进行详细讲解,每一个知识点都给出了基于ISE(HDL语言
2009-07-24 13:07:08
的不足,同时也方便在现场可编程门阵列(FPGA)中增加一些其他相关的应用功能,因此在FPGA中实现CVSD语音编译码调制功能的前景将是非常广阔的。这里将详细介绍什么是CVSD?其算法分析如何在FPGA中实现?
2019-08-07 07:04:27
基于FPGA的FFT算法研究
2012-08-24 01:09:50
码力分享基于FPGA的可变祖冲之(ZUC)算法的设计与实现1:概述基于FPGA的可变祖冲之(ZUC)算法的设计与实现软件:ISE语言:Verilog HDL,C语言 2:功能通过加入可配置模块(如S
2015-10-14 21:56:52
基于FPGA的模糊PID控制算法的研究及实现
2013-03-18 14:25:05
进行了校验,通过了功能仿真。同时,借助于QuatusII综合布线工具,使用Altera公司的StratixII EP2S60 FPGA芯片进行了综合、布线,模块的运行频率达到107MHz,RLDRAM
2008-10-07 11:00:19
必须具备A/D转换功能。采用专门的A/D转换芯片,固然可实现输出电压的检测,但电路变得复杂且成本偏高。经综合考虑,本系统采用STC12C5A60S2单片机作为系统的主控制器。 STC12C5A60S2
2018-10-18 16:55:48
具备A/D转换功能。采用专门的A/D转换芯片,固然可实现输出电压的检测,但电路变得复杂且成本偏高。经综合考虑,本系统采用STC12C5A60S2单片机作为系统的主控制器。 STC12C5A60S2
2018-09-30 16:26:35
本设计方案采用了一种改进的快速中值滤波算法,成功地在Altera公司的高性能Stratix II EP2S60上实现整个数字红外图像滤波,在保证实时性的同时,使得硬件体积大为缩减,大大降低了成本
2021-04-23 06:00:55
使用TMS320C6455芯片,FPGA采用ALTERA的高端FPGA芯片Stratix II EP2S系列EP2S60,板卡使用FPGA用于获取双通道数据采集,实现1路的Base CameraLink
2012-07-06 16:17:50
ALTERA的高端FPGA芯片Stratix II EP2S系列EP2S60,板卡使用FPGA用于获取双通道数据采集,实现1路的Base CameraLink输入,一路Base CameraLink
2012-06-13 11:39:49
ALTERA的高端FPGA芯片Stratix II EP2S系列EP2S60,板卡使用FPGA用于获取双通道数据采集,实现1路的Base CameraLink输入,一路Base CameraLink
2012-06-13 12:01:23
本设计中采用了ALTERA公司的 EP1C3T144芯片进行设计,实际测试表明系统的各项设计要求均得到满足并且系统工作良好,该设计采用了SOPC技术和FPGA,几乎将整个系统下载于同一芯片中,实现了
2021-04-30 06:56:14
如何采用FPGA芯片完成基于LMS算法的自适应谱线增强系统的设计?
2021-04-29 06:55:16
请问如何采用Altera公司Cyclom系列FPGA来实现ATM层UTOPIA LEVEL2主接口,与物理层UTOPIA从接口连接?
2021-04-08 06:32:34
请问一下有没有采用EEPROM对大容量FPGA芯片数据实现串行加载的实际方案?
2021-04-08 06:01:39
如何采用STC12C5A60S2实现无线多功能防火报警系统的设计?
2021-10-13 07:07:03
和模式识别的主要特征提取手段,在计算机视觉、图像分析等应用中起着重要的作用,是图像分析与处理中研究的热点问题。数字信号和图像处理算法的实现有多种途径,传统上多采用高级语言编程实现,便于使用的还有
2019-07-31 06:38:07
介绍了利用现场可编程逻辑门阵列FPGA实现直接数字频率合成(DDS)的原理、电路结构和优化方法。重点介绍了DDS技术在FPGA中的实现方法,给出了采用ALTERA公司的ACEX系列FPGA芯片EP1K30TC进行直接数字频率合成的VHDL源程序。
2021-04-30 06:29:00
如何去实现一种基于stc15f2k60s2芯片的流水灯编程呢?
2021-10-25 06:48:41
如何在ALTERA公司的Quartus II环境下用VHDL、Verilog HDL实现设计输入,采用同步时钟,成功编译、综合、适配和仿真,并下载到Stratix系列FPGA芯片EP1S25F780C5中。
2021-04-15 06:19:38
主要内容包括:1. 为什么很多人觉得学习FPGA很困难,以及HDL学习的一些误区;2. 软件和硬件在算法实现上的区别;3. 通过具体例子详细讲解了从算法的行为级建模向RTL级建模的转换思想和底层电路
2015-09-18 15:44:39
,采用AGC算法,可提高音频信号系统和音频信号输出的稳定性,解决了AGC调试后的信号失真问题。本文针对基于实用AGC算法的音频信号处理方法与FPGA实现,及其相关内容进行了分析研究。1、 实用AGC算法在
2020-10-21 16:42:15
一种在FPGA中实现的基于软判决的Viterbi译码算法,并以一个(2,1,2)、回溯深度为10的软判决Viterbi译码算法为例验证该算法,在Xilinx的XC3S500E芯片上实现了该译码器,最后对其性能做了分析。 关键词: OFDM;Viterbi译码;软判决;FPGA
2009-09-19 09:41:24
各位朋友好,我的导师要求我设计一个新的报文调度算法,能够实现不同优先级的报文在发送的过程中,实现高优先级报文的低延时和低抖动。要求使用stm32的LWIP协议栈进行报文调度算法的开发,请问要实现
2020-04-07 04:35:59
和Motion JPEG三种算法,有将这3种算法用FPGA实现的大神么?还有就是这3种算法到底适不适合用FPGA实现,麻烦有过研究的大大们分析下啊!谢谢!PS:如果有这3种算法的资料说明麻烦大家分享下,我找到的都是C语言的源码,看起来好吃力!
2017-07-04 11:17:17
本文研究的就是在FPGA设计平台上设计硬件电路,实现数字图像的空域滤波算法。
2021-04-30 06:29:41
方面不支持64位操作,于是RC6修正这个错误,使用4个32位寄存器而不是2个64位寄存器,以更好地实现加解密。利用FPGA来实现RC6算法,可以提高运算速度。芯片设计为RC6算法处理器,辅助计算机处理器完成加解密操作,可以方便地实现对加解密的分析和研究。因此,此芯片可以作为协处理器来看待。
2019-08-19 07:27:09
本帖最后由 eehome 于 2013-1-5 10:04 编辑
指纹识别算法的研究及基于FPGA的硬件实现
2012-05-23 20:14:46
FPGA芯片- CycloneIII EP3C55F484,内含55865 个L C s ,具有2 60万B IT内嵌R AM容量, 4个锁相环( 2 KH Z - 1300MHZ),484个IO引脚。可
2018-03-06 09:30:50
求EP2S60F672详细资料哪位大侠有啊,给我发一个
2009-08-11 22:14:25
设计题目:基于NXP K60的蜂窝物联网数据传输终端设计1. 设计所采用的控制芯片必须是K60系列;2. 蜂窝物联网芯片推荐采用中移物联网公司的NB-IoT系列芯片。3. 数据传输关系:RS485
2019-12-19 21:27:55
和论证的基础上,选取较优化的预处理算法,作为FPGA指纹预处理平台的算法。并用FPGA实现所选算法。1 处理步骤 本系统采用XILINX公司Spartan 3E系列FPGA作为核心控制芯片,通过富士通
2009-09-19 09:38:11
协同过滤算法的原理及实现基于物品的协同过滤算法详解协同过滤算法的原理及实现
2020-11-05 06:51:34
一种基于FPGA技术的虚拟逻辑分析仪的研究与实现:逻辑分析仪的现状" 发展趋势及研制虚拟逻辑分析仪的必要性, 论述了基于FPGA技术的虚拟逻辑分析仪的设计方案及具体实现方法,介绍
2008-11-27 13:13:04 29
29 小波盲源分离算法的仿真及FPGA实现:提出了一种基于小波变换的盲源分离方法,在理论分析和仿真结果的基础上,给出了FPGA 的实现方案。针对传统盲分离算法对源信号统计特征敏
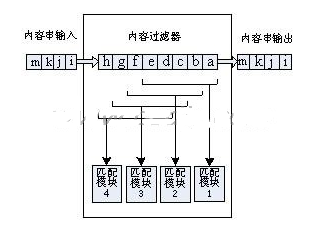
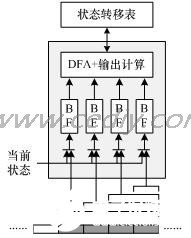
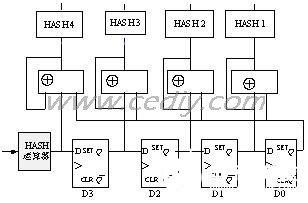
2009-06-21 22:44:0921 IP 过滤是把IP 数据报文分成不同种类的过程,主要取决于IP 报头中的信息。基于软件的字符串匹配已经不能跟上高速的网络传输速度,需要寻找
2009-09-09 09:17:5216 针对信息检索分类技术发展的需求,本文通过对协同过滤推荐算法的综述,提出传统过滤算法无法适用于用户多兴趣下的推荐问题进行了剖析,提出了一种基于用户聚类的协同过滤推荐
2010-03-01 16:09:4711 介绍了AES中,SubBytes算法在FPGA的具体实现.构造SubBytes的S-Box转换表可以直接查找ROM表来实现.通过分析SubBytes算法得到一种可行性硬件逻辑电路,从而实现SubBytes变换的功能.
2010-11-09 16:42:4825 提出一种基于DCT域的数字水印算法,并用FPGA硬件实现其中关键部分DCT变换。采用VHDL语言有效设计和实现DCT变换,分析与仿真结果表明:与软件实现相比,用FPGA实现水印算法具有高
2010-12-28 10:22:1420 用FPGA实现FFT算法
引言 DFT(Discrete Fourier Transformation)是数字信号分析与处理如图形、语音及图像等领域的重
2008-10-30 13:39:201426 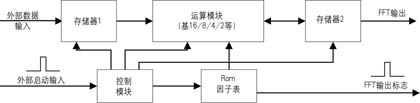
摘要: 针对在FPGA中实现FIR滤波器的关键--乘法运算的高效实现进行了研究,给了了将乘法化为查表的DA算法,并采用这一算法设计了FIR滤波器。通过FPGA仿零点验证
2009-06-20 14:09:36677 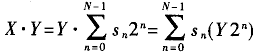
利用FPGA来实现RC6算法的设计与研究
引 言
RC6是作为AES(Advanced Encryption Standard)的候选算法提交给NIST(美国国家标准局)的一种新的分组密码。它是在RC5的基础上
2009-12-28 09:20:151022 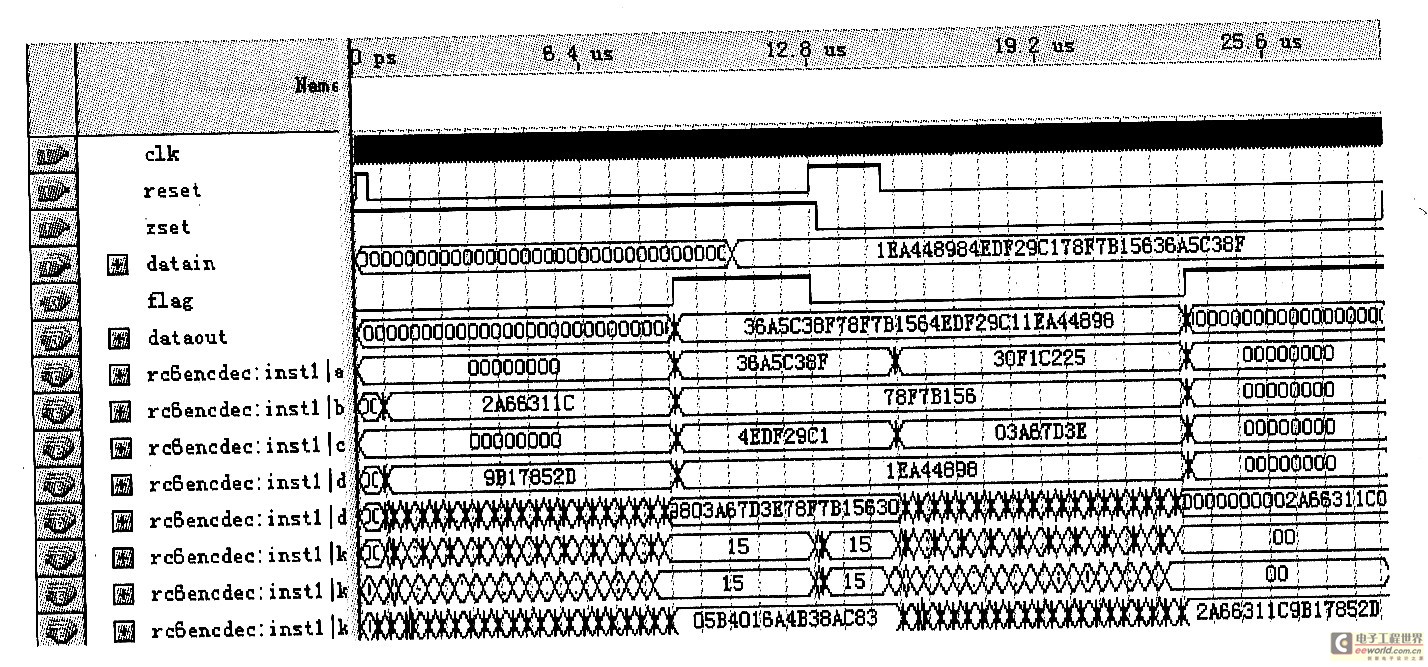
首先分析了8PSK 软解调算法的复杂度以及MAX算法的基本原理,并在Altera 公司的Stratix II 系列FPGA芯片上实现了此软解调硬件模块
2011-04-08 11:22:156901 
本文介绍的电子消像旋系统采用Altera公司的StratixII系列FPGA芯片和ADI公司的ADSP2183为核心,可以满足系统对功能、实时性及精度的要求。
2011-09-13 11:28:001165 
差分功耗分析是破解AES密码算法最为有效的一种攻击技术,为了防范这种攻击技术本文基于FPGA搭建实验平台实现了对AES加密算法的DPA攻击,在此基础上通过掩码技术对AES加密算法进行优
2011-12-05 14:14:3152 以Altera公司的FPGA EP2S60为例,探讨了SOPC系统设计的综合优化方法。
2012-03-12 11:49:281204 
基于FPGA的JPEG解码算法的研究与实现,很好的资料,快来学习吧
2016-02-18 13:53:550 基于FPGA的模糊PID控制算法的研究及实现-2009。
2016-04-05 10:39:2920 CCD图像的颜色插值算法研究及其FPGA实现
2016-08-29 15:02:0312 基于FPGA的JPEG解码算法的研究与实现
2016-08-29 16:05:0111 基于FPGA的数字信号处理算法研究与高效实现
2016-08-29 23:20:5639 空间图像CCSDS压缩算法研究与FPGA实现,感兴趣小伙伴们可以瞧一瞧。
2016-09-18 14:57:4216 算法进行深入研究,面向Xilinx K7 410T FPGA 芯片设计SHA-1算法实现结构,完成SHA-1算法编程,进行测试和后续应用。该算法在FPGA 上实现,可以实现3.2G bit/s的吞吐
2017-10-30 16:25:544 摘要: 介绍了3DES加密算法的原理并详尽描述了该算法的FPGA设计实现。采用了状态机和流水线技术,使得在面积和速度上达到最佳优化;添加了输入和输出接口的设计以增强该算法应用的灵活性。各模块均用硬件
2017-11-06 11:10:094 公司的Spartan6系列FPGA芯片,系统可以实现将四路摄像头采集的视频信号从任意通道放大到1 920x1 080@60 Hz的分辨率显示,结果表明输出视频图像的实时性和细节保持良好。
2017-11-16 11:48:094559 
本文采用Altera公司Stratix II系列的EP2S90F1508C3芯片,以Quartus II 8.1为开发环境[4],采用硬件描述语言VHDL进行SM3算法的FPGA实现。SM3算法实现
2017-11-24 15:33:592445 
针对防火墙粗粒度过滤Modbus/TCP导致工控系统存在安全威胁的问题,研究基于Modbus功能码的细粒度过滤算法。基于Modbus TCP功能码的特征,对其功能码字段进行解析,实现基于白名单规则
2018-01-16 15:32:340 传统的基于几何区域分割的报文分类算法在空间切分时,通常只采用一种切分方法,并不会根据每个域的特点选取不同的对策.提出了一种采用混合切分法的报文分类算法HIC(hybrid intelligent
2018-02-24 14:06:310 语义主题,从语义层面计算用户对各资源的偏好概率,将计算出的偏好概率与协同过滤算法计算出的资源相似度相结合,预测用户偏好值,实现个性化推荐。在Movielens数据集上的实验结果表明,与传统基于标签的推荐算法相比,该算法能消除标签
2018-03-07 13:58:030 中,采用AGC算法,可提高音频信号系统和音频信号输出的稳定性,解决了AGC调试后的信号失真问题。本文针对基于实用AGC算法的音频信号处理方法与FPGA实现,及其相关内容进行了分析研究。
2018-09-30 16:29:142957 
随着深亚微米工艺的发展, FPGA 的容量和密度不断增加,以其强大的并行乘加运算(MAC)能力和灵活的动态可重构性,被广泛应用于通信、图像等许多领域。但是在复杂算法的实现上,FPGA 不如嵌入式
2020-12-23 12:33:001 为进一步提高编码效率,在研究菱形算法的基础上,采用了“十字”形运动估计算法,设计了硬件电路,并用H‘GA(Field-Pmg隐mmable Gate Amy)实现了算法.结合算法的特点,设计了整体
2021-02-03 14:46:0012 提出一种新的高阶FIR滤波器的FPGA实现方法。该方法运用多相分解结构对高阶FIR滤波器进行降阶处理,采用改进的分布式算法来实现降阶后的FIR滤波器。设计了一系列阶数从8到1 024的FIR滤波器
2021-03-23 15:44:5430 基于显式反馈的协同过滤算法只存在3个变量,其相似度计算方法依赖用户评分数据的显式反馈行为,而未考虑现实推荐场景中存在的隐性因素影响,这决定了协同过滤算法被限制于挖掘用户及商品的偏好,而缺乏挖掘用户
2021-04-28 11:30:153 摘要:在对FFT(快速傅立叶变换)算法进行研究的基础上,描述了用FPGA实现FFT的方法,并对其中的整体结构、蝶形单元及性能等进行了分析。
2022-04-12 19:28:254515 有些transceiver有PNC过滤功能,也可以在硬件上设置此过滤功能。针对NXP TJA1145 Transceiver而言,只能过滤通信速率在1Mbps的报文,因此要注意项目中的网络管理报文
2022-08-23 12:09:084078 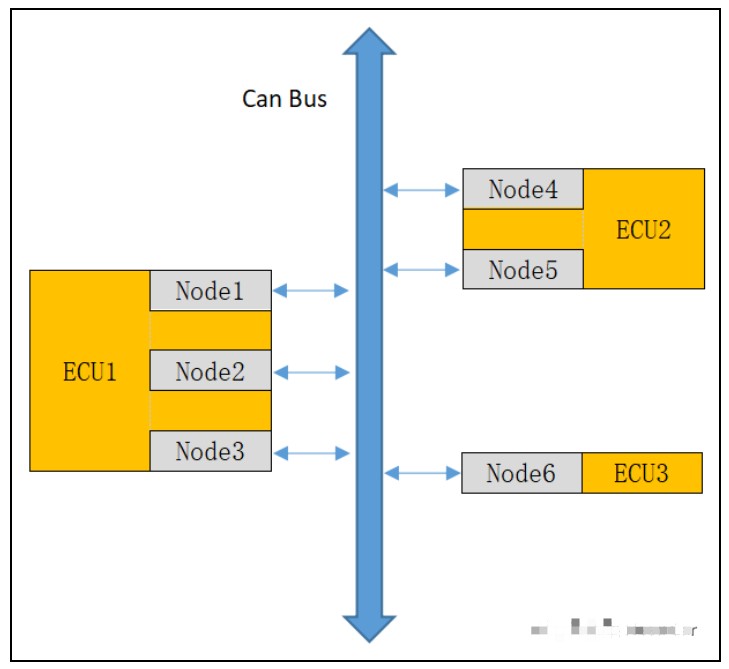
TSMaster软件平台支持对不同总线(CAN、LIN、FlexRay)的报文和信号过滤,过滤方法一般有全局接收过滤、数据流过滤、窗口过滤、字符串过滤、可编程过滤,针对不同的总线信号过滤器的使用方法
2023-12-16 08:21:15206 
 电子发烧友App
电子发烧友App










 工商网监
工商网监
评论