用软件从 C 转化来的 RTL 代码其实并不好理解。今天我们就来谈谈,如何在不改变 RTL 代码的情况下,提升设计性能。 本项目所需应用与工具:赛灵思HLS、Plunify Cloud 以及
2020-12-20 11:46:46 2389
2389 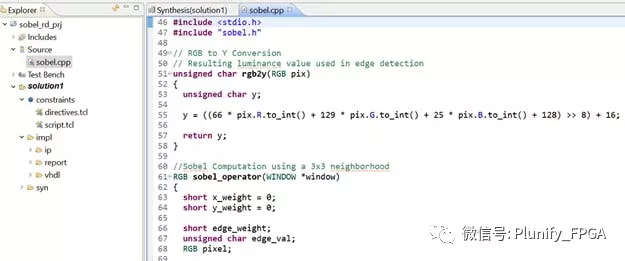
在很大程度上,C++是C的超集,这意味着一个有效的C程序也是一个有效的C++程序。
2022-09-16 10:20:121499 现在编写一个简单的应用程序,提示用户输入整数,通过移位的方式将其与 2 的幕 (2¹〜2ⁿ) 相乘,并用填充前导空格的形式再次显示每个乘积。输入-输出使用 C++。汇编模块将调用 3 个 C++ 编写的函数。程序将由 C++ 模块启动。
2022-10-11 09:52:201382 目前开发C++/C用的比较多的当属Vim、VS code、CLion。
2022-11-25 14:02:19925 当FPGA开发者需要做RTL和C/C++联合仿真的时候,一些常用的方法包括使用MicroBlaze软核,或者使用QEMU仿真ZYNQ的PS部分。
2023-12-13 10:11:503568 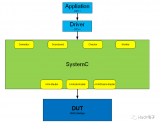
当FPGA开发者需要做RTL和C/C++联合仿真的时候,一些常用的方法包括使用MicroBlaze软核,或者使用QEMU仿真ZYNQ的PS部分。
2023-12-13 10:13:452622 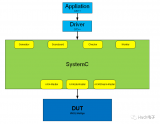
使用DevEco Studio创建一个Native C++应用。应用采用Native C++模板,实现使用NAPI调用C标准库的功能。使用C标准库hypot接口计算两个给定数平方和的平方根。在输入框中输入两个数字,点击计算结果按钮显示计算后的数值。
2024-04-14 11:43:074439 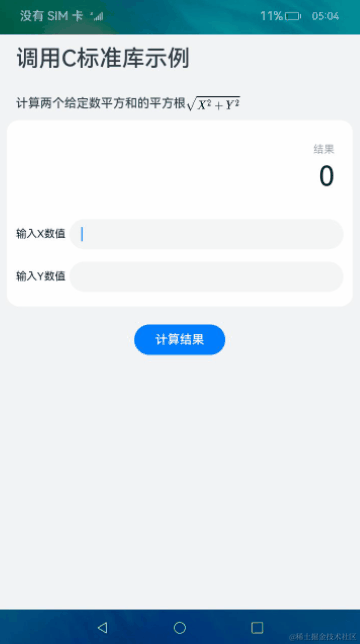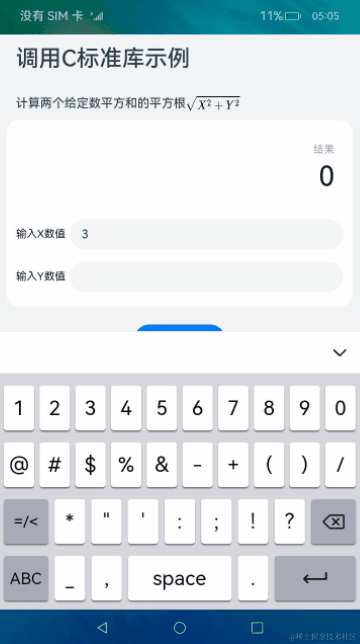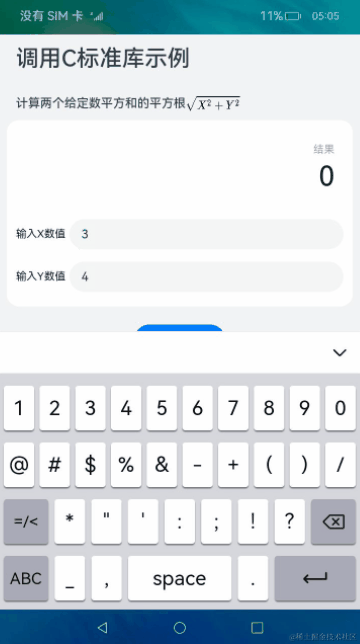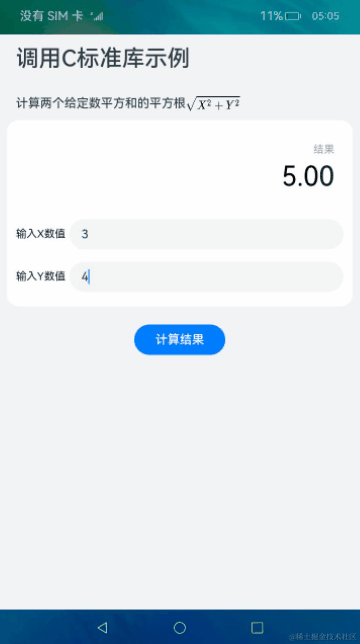
直接使用C、C++或 System C 来对 Xilinx 系列的 FPGA 进行编程,从而提高抽象的层级,大大减少了使用传统 RTL描述进行 FPGA 开发所需的时间。
2025-04-16 10:43:121432 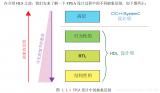
c和c++可以说现在都是比较流行的,但是两者到底有什么联系和区别吗,这是学习c和c++最需要注意的,不要把两者搞混了,我们先开始就来看一下c和c++有什么联系,这两者可以这样说:C++是C的超集
2019-05-07 15:57:06
很多同学在大学都学过C和C++,那么C和C++就业怎么样?薪资高吗?小编今天就给大家详细解读一下。学c++ 好不好?C++ 语言广泛的用于基础软件、桌面系统、网络通信、音频视频、游戏娱乐等诸多领域
2021-11-25 10:47:33
是面向过程语言,而C++是面向对象语言。说C和C++的区别,也就是在比较面向过程和面向对象的区别。
1、面向过程和面向对象的区别
面向过程:面向过程编程就是分析出解决问题的步骤,然后把这些步骤一步
2025-12-24 07:23:44
区别
1、面向对象编程 (OOP):
C语言是一种面向过程的语言,它强调的是通过函数将任务分解为一系列步骤进行执行。
C++在C语言的基础上扩展了面向对象的特性,支持类(class)、封装、继承
2025-12-11 06:23:20
工作快四年了,在一家外企给芯片写驱动程序,C++。但是底层驱动协议也没用到C++高级的功能,大部分时间在读文档,写if-else-.学校里做过FPGA的项目,工作中也做过几个小项目。水平也一般。现在想换工作,比较迷茫该往哪个方向走呢?哪个更有前途呢?求高人指点!
2015-06-02 19:37:58
请教一下,我在HLS里面要将以下程序生成IP核,C Synthesis已经做好了,但是在export RTL的时候一直在运行
int sum_single(int A int B
2023-09-28 06:03:53
和c++的相似之处多于不同之处,但两种语言问几处主要的不同使得Java更容易学习,并且编程环境更为简单。 我在这里不能完全列出不同之处,仅列出比较显著的区别: 1.指针 JAVA语言让编程者无法找到
2016-04-11 15:19:26
和c++的相似之处多于不同之处,但两种语言问几处主要的不同使得Java更容易学习,并且编程环境更为简单。 我在这里不能完全列出不同之处,仅列出比较显著的区别: 1.指针 JAVA语言让编程者无法找到指针
2016-10-10 14:50:32
和c++的相似之处多于不同之处,但两种语言问几处主要的不同使得Java更容易学习,并且编程环境更为简单。 我在这里不能完全列出不同之处,仅列出比较显著的区别: 1.指针 JAVA语言让编程者无法找到指针
2018-09-13 16:02:06
主要可以从“设计的重用”和“抽象层级的提升”这两个方面来考虑。Xilinx推出的Vivado HLS工具可以直接使用C、C++或System C来对Xilinx系列的FPGA进行编程,从而提高抽象的层级
2020-10-10 16:44:42
优化 FPGA HLS 设计
用工具用 C 生成 RTL 的代码基本不可读。以下是如何在不更改任何 RTL 的情况下提高设计性能。
介绍
高级设计能够以简洁的方式捕获设计,从而
2024-08-16 19:56:07
嗨,大家好,我有一个问题,在VIVADO HLS 2017.1中运行C \ RTL协同仿真。我已成功运行2014和2016版本的代码。任何人都可以告诉我为什么报告NA仅用于间隔
2020-05-22 15:59:30
可执行文件。图26请参考基于Vivado的FPGA程序加载与固化手册加载.bit格式可执行文件,即可看到评估底板的LED2进行闪烁。综合本小节演示将C/C++等程序综合成为RTL设计,并生成综合报告。点击
2021-02-19 18:36:48
认,conv2d我们将比较结果是否足够接近在 PyTorch 的 C++ API (libtorch) 上执行的卷积计算。每个测试包括以下两个步骤。C. 验证C/RTL 协同验证1、C 验证类似于正常的软件开发
2023-02-24 15:41:16
相比,能够为通信和多媒体应用提供高达10倍速的更高的设计和验证能力。Synphony HLS为ASIC 和 FPGA的应用、架构和快速原型生成最优化的RTL。Synphony HLS解决方案架构图
2019-08-13 08:21:49
您好我有一个关于vivado hls的问题。RTL是否来自xivix FPGA的vivado hls onyl?我们可以在Design Compiler上使用它进行综合吗?谢谢
2020-04-13 09:12:32
。Vivado HLS作为该套件的一个组件,能帮助设计人员将采用C/C++语言开发的算法编译为RTL,以便在FPGA逻辑中运行。Vivado HLS工具非常适用于嵌入式视觉设计。在此流程中,您用C/C++
2014-04-21 15:49:33
*1.1 从C到C++*1.2 最简单的C++程序 1.3 C++程序的构成和书写形式 1.4 C++程序的编写和实现 1.5 关于C++上机实践计算机诞生初期,人们要
2008-09-08 09:35:20 108
108 VISUAL C++ MFC编程实例:用Visual C++ 和M F C创建的应用程序大多会自动生成窗口,并且可以处理消息,进行绘图。M i c r o s o f t在这方面做了大量的工作,隐藏了内部工作,使我们能够
2009-07-12 15:20:270 C++简介
目录1.0 本科程在专业学习中的地位1.1 程序设计语言 1.2 C++前史 1.3 C++ 1.4 C++编程流程 1.5 最小样板程序1.6&
2010-02-24 09:34:4428 现在市面上,主流的C/C++编译器包括M$的CL、gcc、Intel的icl、PGI的pgcc及Codegear的bcc(原来属于Borland公司)。Windows上使用最多的自然是cl,而在更广阔的平台上,gcc则是C/C++
2010-09-10 11:54:518 C++课件,关于MFC的使用,以及一些关于C++方面的内容,对初学者帮助比较大
2015-11-12 11:41:250 C++ 入门自学教程从入门知识开始讲起,比较有利于初学者入门掌握,比较好懂,能够对C++有一个全面认识
2015-11-17 10:36:280 C++基础知识,简要介绍了C++的一些简单知识,概念,函数
2015-12-25 10:15:060 C++标准库英文版。
C++强大的功能来源于其丰富的类库及库函数资源。
2016-05-13 14:41:310 学习C++非常不错的课件,各项程序实例比较齐全,方便初学者熟悉C++的编程规范等
2016-05-27 17:04:390 在之前HLS的基本概念1里有提及,HLS会把c的参数映射成rtl的端口实现。本章开始总结下HLS端口综合的一些知识。 1.HLS综合后的rtl端口大体可以分成2类: Clock Reset端口
2017-02-08 03:29:111162 
相信通过前面5篇fir滤波器的实现和优化过程,大家对HLS已经有了基本的认识。是时候提炼一些HLS的基本概念了。 HLS支持C,C++,和SystemC作为输入,输出为Verilog(2001
2017-02-08 05:23:111111 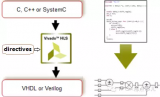
高层次综合(High Level Synthesis, HLS)是Xilinx公司推出的最新一代的FPGA设计工具,它能让用户通过编写C/C++等高级语言代码实现RTL级的硬件功能。随着这款工具
2018-07-14 06:42:008006 C和C++语言参考手册
2017-06-19 11:12:0123 RTL8139C RTL8139C-LF RTL8139CL RTL8139CL-LF
2017-10-25 14:48:5423 对算法FPGA的实现难度。其中包括:
使用VivadoHLS开发效率比手写RTL实现快5-10倍,而实现的FPGA资源效率与手写RTL接近
由于C/C++仿真验证比传统FPGA RTL要快100倍,Vivado HLS实现可以大大缩短用户的代码开发时间和仿真验证时间,从而大幅提高生产效率。
2017-11-17 17:47:434363 
通常基于传统处理器的C是串行执行,本文介绍Xilinx Vivado-HLS基于FPGA与传统处理器对C编译比较,差别。对传统软件工程师看来C是串行执行,本文将有助于软件工程师理解
2017-11-18 12:23:093066 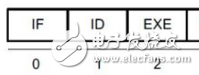
速度要比C++慢10-30倍.即使采用just-in-time compiling (读取类文件字节后,编译成本地机器码)技术,速度也要比C++慢好多. 2)java程序有要从网络上加载类字节,然后
2017-12-01 09:12:25582 C/C++编译技术
2017-12-04 17:19:1325 C++是在C语言的基础上发展来的,但是并不是C++比C语言高级,两者的编程思想不一样,应用的领域也不一样。在各自的领域,谁也不能替代谁。
2017-12-11 10:17:5234825 c280x / c2801x C / C++头文件和示例项目促进写在C / C++代码为德克萨斯仪器tms320x280x DSP。这些代码可以作为学习工具或作为开发平台的基础,这取决于用户当前的需求。
2018-04-13 11:18:327 应用大比拼开擂 基于vivado HLS的帧差图像实现 基于FPGA的实时移动目标的追踪 类似嵌入式 C/C++/OpenCL 应用开发的体验 SDSoC 开发环境可为异构 Zynq SoC 及 MPSoC 部署
2018-05-21 14:16:002572 Vivado HLS 是 Xilinx 提供的一个工具,是 Vivado Design Suite 的一部分,能把基于 C 的设计 (C、C++ 或 SystemC)转换成在 Xilinx 全可编程芯片上实现用的 RTL 设计文件 (VHDL/Verilog 或 SystemC)。
2018-06-05 10:31:007419 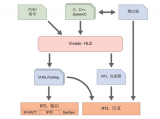
HLS,高层综合)。这个工具直接使用C、C++或SystemC 开发的高层描述来综合数字硬件,这样就不再需要人工做出用于硬件的设计,像是VHDL 或Verilog 这样的文件,而是由HLS 工具来做这个事情。
2018-06-04 01:43:007738 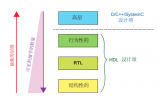
一般学C++前都要学C,所以通常叫它们C/C++。C/C++历经40余年,也是经久不衰的号称“永不过时的开发语言 ”。因为C/C++在国内外的应用范围非常广泛,无论是在PC、移动设备、网络、通讯
2018-08-15 10:24:002671 C和C++安全编码是C/C++安全编码领域的权威著作,被视为“标准”参考书,由国际资深软件安全专家撰写,美国CERT主管亲自作序推荐。本书结合国际标准C11和C++11,以及C和C++语言的最新发展
2018-08-28 08:00:000 结合对FPGA重配置方案的软硬件设计,本文通过PC机并通过总线(如PCI总线)将配置数据流下载到硬件功能模块的有关配置芯片,从而完成配置FPGA的全过程。该方法的软件部分基于Visual C++的开发环境,并用C++语言开发动态连接库,以用于软件设计应用程序部分的调用。
2018-12-30 09:26:003644 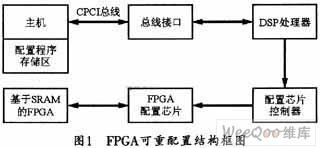
赛灵思公司(Xilinx)推出针对 OpenCL、C 和 C++的S DAccel 开发环境,将单位功耗性能提高达25倍,从而利用 FPGA 实现数据中心应用加速。SDAccel 是赛灵思 SDx
2018-08-30 17:00:001497 了解如何使用GUI界面创建Vivado HLS项目,编译和执行C,C ++或SystemC算法,将C设计合成到RTL实现,查看报告并了解输出文件。
2018-11-20 06:09:004500 本文档的主要内容详细介绍的是C++入门教程之C++程序设计的课件资料免费下载主要内容包括了:1. 认识C++2. C++的现状和发展3. C++程序的一般开发过程4. 简单的C++程序5. C++程序的构成、书写6. 集成开发环境
2018-12-07 08:00:0033 用软件从 C 转化来的 RTL 代码其实并不好理解。今天我们就来谈谈,如何在不改变 RTL 代码的情况下,提升设计性能。 本项目所需应用与工具:赛灵思HLS、Plunify Cloud 以及 InTime。 前言 高层次的设计可以让设计以更简洁的方法捕捉,从而让错误更少,调试更轻松。
2019-09-15 11:56:00767 本文档的主要内容详细介绍的是VISUAL C++教程之VISUAL C++的安装和使用方法资料免费下载。
2018-12-27 16:32:1620 C++程序设计教程之C++的初步知识的详细资料说明包括了:1. 从C到C++,2 . 最简单的C++程序,3 . C++程序的构成和书写形式,4 . C++程序的编写和实现,5 . 关于C++上机实践
2019-03-14 14:48:2231 本文档的主要内容详细介绍的是C++程序设计的基础知识初步了解C++的资料免费下载包括了:1 认识C++,2 C++的现状和发展,3 C++程序的一般开发过程,4 简单的C++程序,5 C++程序的构成、书写,6 集成开发环境
2019-06-10 08:00:0025 尽管 Vivado HLS支持C、C++和System C,但支持力度是不一样的。在v2017.4版本ug871 第56页有如下描述。可见,当设计中如果使用到任意精度的数据类型时,采用C++ 和System C 是可以使用Vivado HLS的调试环境的,但是C 描述的算法却是不可以的。
2019-07-29 11:07:166103 
Xilinx 战略应用高级工程师。专注于 C/C++ 高层次综合,拥有多年利用 Xilinx FPGA 实现数字信号处理算法的经验,对 Xilinx FPGA 的架构、开发工具和设计理念有深入的理解
2019-08-01 15:43:094314 RTL代码),也可以在某些场合加速设计与验证(例如在FPGA上实现OpenCV函数),但个人还是喜欢直接从RTL入手,这样可以更好的把握硬件结构。Xilinx官方文档表示利用HLS进行设计可以大大加速设计进度:
2019-07-31 09:45:177434 
本文档的主要内容详细介绍的是使用C++语言实现的解题的实例说明。
2020-04-21 11:50:456 C++封装:类的作用域和实例化
2020-06-29 14:28:444044 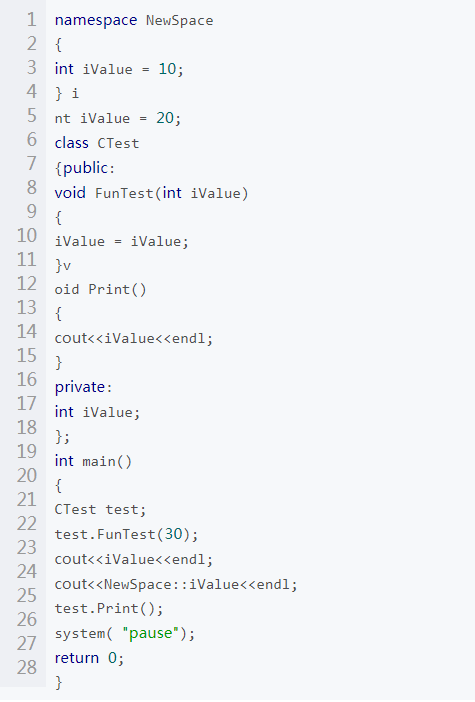
在学习了C语言和C++之后,这两者之间的区别我们需要仔细的捋一捋!
2020-06-29 14:56:346591 
1C与C++相互调用 在一个嵌入式系统中大部分的底层和驱动层更多的是采用C语言来进行开发,而上层应用、服务更多的采用C++等高级语言来进行面向对象等方面的开发方式,那么就存在一个上层调用底层
2021-01-18 11:05:064025 
前段时间给部门做了个C++专题的分享,主要分享了C++语言里一些常见的坑,在这里也分享给大家。 首先说下C++和C语言有什么区别?分享一个我在知乎上看见的回答: C++ ≈ C
2021-05-20 11:38:382637 C++ Socket网络编程大全源代码下载
2021-06-21 09:36:1227 一、秋招 Linux C/C++ offer 情况二、Linux C/C++ 方向的一些思考三、计算机基础知识的梳理四、C++ 方向的深入学习路线五、项目 + 亮点 + 面试的一些思考六、总结前言
2021-11-06 19:36:0014 C和C++经典著作-C专家编程.PDF
2021-12-13 17:11:050 这一章开始编写代码,主要是两个方面,一是C++,二是进行简单的IO封装。其它教程一般是用C语言,从按键或LED灯开始,比较直观,容易上手,但与实际应用有一定的区别,这里要做的是实用控制程序,开始
2022-01-12 17:40:184 C和C++经典著作《C和指针》
2022-01-17 09:46:430 C和C++实物精选《C专家编程》
2022-01-17 09:55:470 在上一则教程中,通过与 C 语言相比较引出了 C++ 的相关特性,其中就包括函数重载,引用,this 指针,以及在脱离 IDE 编写 C++ 程序时,...
2022-01-25 19:13:081 虚拟机的设计与实现:C\C++
2022-02-21 15:10:390 相对而言,C语言和C++相关的面试题比较少见,没有Java方向写的人那么多,这是一篇 C 语言与 C++面试知识点总结的文章,个人感觉非常难得,希望能对大家有所帮助。
2022-05-12 14:59:521922 相对而言,C语言和C++相关的面试题比较少见,没有Java方向写的人那么多,这是一篇 C 语言与 C++面试知识点总结的文章,个人感觉非常难得,希望能对大家有所帮助。
2022-05-13 11:59:392426 Vitis HLS 是一种高层次综合工具,支持将 C、C++ 和 OpenCL 函数硬连线到器件逻辑互连结构和 RAM/DSP 块上。Vitis HLS 可在Vitis 应用加速开发流程中实现硬件
2022-05-25 09:43:363450 在整个流程中,用户先创建一个设计 C、C++ 或 SystemC 源代码,以及一个C的测试平台。通过 Vivado HLS Synthesis 运行设计,生成 RTL 设计,代码可以是 Verilog,也可以是 VHDL。
2022-06-02 09:48:178680 1、HLS简介 HLS(High-Level Synthesis)高层综合,就是将 C/C++的功能用 RTL 来实现,将 FPGA 的组件在一个软件环境中来开发,这个模块的功能验证在软件环境中来
2022-12-02 12:30:027407 HLS (high-level synthesis)称为高级综合, 它的主要功能是用 C/C++为 FPGA开发 算法。这将提升FPGA 算法开发的生产力。 Xilinx 最新的HLS
2023-01-15 12:10:046467 的重要手段。没有虚函数,C++和C的区别就不大,都需要借助大量的“函数指针”,进行面向对象的程序设计(特别是功能扩展方面)。
2023-02-15 11:14:101461 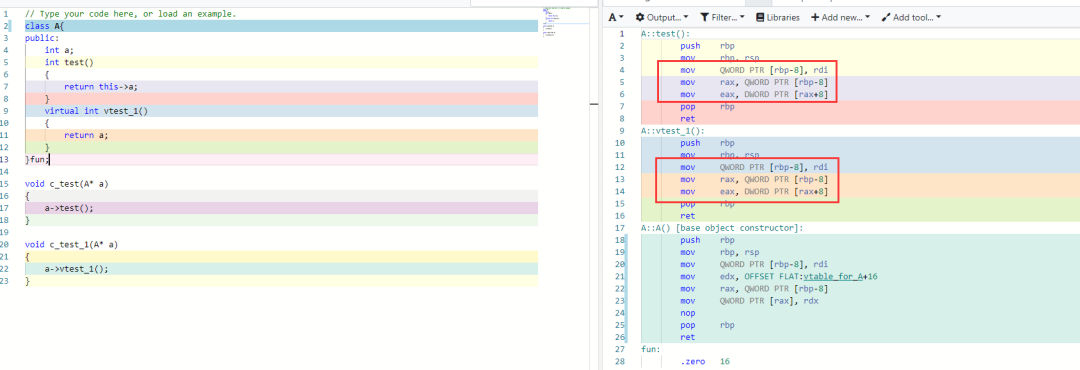
C++中struct和class的区别是什么?C++中struct和class的最大区别在于: struct的成员默认是公有的, 而class的成员默认是私有的,
2023-03-10 17:41:321150 自这篇文章我们即将开始C++的奇幻之旅,其内容主要是读C++ Primer的总结和笔记,有兴趣可以找原版书看看,对于学习C++还是有很大帮助的。这篇文章将从一个经典的程序开始介绍C++的类型、变量、表达式、语句、控制流和函数的相关内容,由此可以建立起对于C++总体上的认识
2023-03-17 13:57:161295 AMD Vitis HLS 工具允许用户通过将 C/C++ 函数综合成 RTL,轻松创建复杂的 FPGA 算法。Vitis HLS 工具与 Vivado Design Suite(用于综合、布置和布线)及 Vitis 统一软件平台(用于所有异构系统设计和应用)高度集成。
2023-04-23 10:41:011730 
C++开发人员将有这些问题归咎于C,而C开发人员则认为C++过于疯狂。我觉得站在C的角度看C++,这种说法也很正确。作为C的超集,C++确实很疯狂。一个经验丰富的C开发人员面对C++可能没有熟悉的感觉。C++不是C,这就足以引发互联网上的激烈争论。
2023-05-26 09:27:47877 
本文章将介绍使用 OpenVINO 2023.0 C++ API 开发YOLOv8-Seg 实例分割(Instance Segmentation)模型的 AI 推理程序。本文 C++ 范例程序的开发环境是 Windows + Visual Studio Community 2022。
2023-06-25 16:09:442926 
当前在 AI、无线、视频/图像处理、医疗和消费领域使用的算法,复杂性已显著提升。 Vitis 高层次综合 (HLS) 可通过在选定的 AMD 器件上将 C/C++ 代码综合为可编程逻辑的 RTL
2023-07-05 08:15:021189 
编写了自己的业务爱好项目。那么,为什么我没有抛弃 C 而选择其他语言呢?我对于 C++的看法又是如何的呢? 1 为什么说C不是最好的语言? 首先,这个世上没有最好的编程语言。每种语言都有独特的优势以及适用情况,所以尽管你可以在 Excel 中
2023-07-06 14:29:191638 需要手工在 C++ 代码里明确指定可并行执行的任务(用 task,添加头文件 hls_task.h),同时可并行执行的 task 接口(对应 C++ 函数的形参)必须是 stream 或 stream_of_blocks。
2023-08-11 11:23:501276 为了帮助大家解决这些痛点问题,让大家领略现代C++之美,掌握其中的精髓,更好地使用C++,C++之父Bjarne Stroustrup坐不住了,他亲自操刀写就了这本《C++之旅》!
2023-10-30 16:35:031745 
MISRA C++:2023,MISRA® C++ 标准的下一个版本,来了!为了帮助您做好准备,我们介绍了 Perforce 首席技术支持工程师 Frank van den Beuken 博士撰写
2024-01-11 09:00:511488 
VB语言和C++语言是两种不同的编程语言,虽然它们都属于高级编程语言,但在设计和用途上有很多区别。下面将详细比较VB语言和C++语言的区别。 设计目标: VB语言(Visual Basic)是由
2024-02-01 10:20:074129 C语言、C++、Java和Python是四种常见的编程语言,各有优点和特点。 C语言: C语言是一种面向过程的编程语言。它具有底层的特性,能够对计算机硬件进行直接操作。C语言简洁、高效,常用于开发
2024-02-05 14:11:064203 很多人都比较反感用C/C++开发(HLS)FPGA,大家第一拒绝的理由就是耗费资源太多。但是HLS也有自己的优点,除了快速构建算法外,还有一个就是接口的生成,尤其对于AXI类接口,按照标准语法就可以很方便地生成相关接口。
2024-07-16 18:01:031940 
同样是结构体,看看在C语言和C++中有什么区别?
2024-10-30 15:11:201175 同样是函数,在 C 和 C++ 中有什么区别? 第一个返回值。 C语言的函数可以不写返回值类型,编译器会默认为返回 int。 但是 C++ 的函数,除了构造和析构这两个特殊的函数,必须得写上返回值
2024-11-29 10:25:521319
 电子发烧友App
电子发烧友App











 工商网监
工商网监
评论