 电子发烧友App
电子发烧友App


本文参考自“未来网络:SmartNIC DPU技术白皮书”,从核心处理器角度来分析,目前 SmartNIC 架构主要有 3 类,分别基于 FPGA, MP ( multi-coreprocessors)和 ASIC。
1、基于 FPGA 的架构
微软研究院是以 FPGA 作为智能网卡核心可编程处理器的重要代表。图 2-1 描述了微软一系列设计架构的演进。2014 年,微软提出了基于高端 FPGA——Altera Stratix V D5 的 Shell(通用逻辑)+Role(可重构处理逻辑)的可重构数据中心云服务加速方案,用于解决商用服务器满足不了飞速增长的数据中心业务需求、定制化加速器成本开销大且灵活性不足的问题。
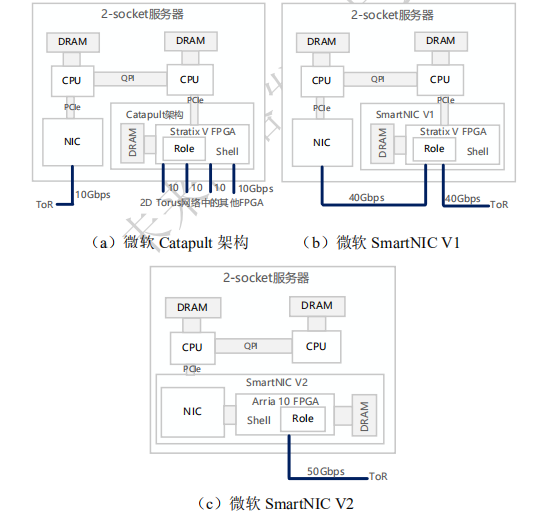
如图(a)所示,其中 Shell 为可重用的通信、管理、配置等通用逻辑,包含 2 个 DRAM 控制器(管理 FPGA 上的 2 块 DRAM)、4 个 10 Gbps 轻量级 FPGA 间串行通信接口 SerialLite 3、管理 DMA 通信的 PCIe 核、路由逻辑(用于管理来自 PCIe,Role,SerialLite 3 的数据)、重新配置逻辑(用于读、写、配置 Flash)、事件翻转逻辑(用于阶段性的监督 FPGA 状态以减少错误);而 Role 则位于 FPGA 芯片的固定区域中,是与用户加速应用紧密相关的逻辑,可以将 Bing 搜索排序逻辑映射到 Role 中进行加速。
在 Catapult 设计中,考虑到 FPGA 的管理和使用,同机架下的所有 FPGA 以 6×8 的 2 维 Torus 网络拓扑的形式组成一套新的网络进行连接,可以将同机架下的所有 FPGA 作为加速资源使用。但是,使用第 2 套网络的设计方式:
一方面,增加了网络的开销和容错管理;另一方面,对于网络流、存储流、分布式应用仅能提供有限的加速。此外,机架内的 2 维 Torus 直连使得用户对跨机架的 FPGA 资源无法进行有效的使用。
微软在2016 年的研究工作中对 Catapult 进行了改进,将 FPGA网络与数据中心网络融合,提出了新的云加速架构设计。如图(b)所示,在 Stratix VD5 FPGA 板卡上设计了 2 个 40 Gbps 的 QSFP端口,分别与主机端已有的普通网卡和架顶交换机(ToR)相连接,对应地,在新的 Shell设计中,原来 Catapult 的 4 端口 SerialLite 3 被替换为轻量级传输层(LTL)引擎用于处理 2 个 40Gbps 端口。
微软在 2018 年的研究中将软件定义网络(SDN)栈卸载到其二代智能网卡,用以更好地支持 SR-IOV。如图(c)所示,此时,二代智能网卡已将通用网卡和高端 Intel Arria 10 FPGA 集成到 1 个板卡上,对外的 ToR 端口已经达到 50 Gbps,但从架构上而言并无实质的变化,仍然采用将 FPGA 放置在通用网卡和 ToR 数据通路之间的设计,用于高效地处理数据流,提供路径上的网络功能、特定应用加速。微软在后来的研究中指出,鉴于当前可编程网卡、可编程交换机的硬件条件支持,充分利用可编程网络设备组成高效的全网可编程云将成为一种趋势。
除微软外,Mellanox、Intel、Xilinx 等也相继推出基于 FPGA 的智能网卡类产品:
1)Mellanox 推出了 Innova 系列基于 Xilinx Kintex UltraScale 高端 FPGA 的智能网卡,包含 Innova 和 Innova-2 Flex 共 2 代产品。
2)Intel 则推出了基于 2 大类可编程 PCIe 加速卡,其中基于Arria10/Arria10 GX FPGA 的可编程加速卡 Intel FPGA PAC N3000,用于加速协议栈处理、NFV 等应用[1];此外,另有基于 Stratix 10 SX 的可编程加速卡 IntelFPGA PAC D5005,面向数据流分析、视频编码转换、金融、人工智能、基因分析等领域。
3)Xilinx 推出的网卡包括 XtremeScale X2 和 8000 共 2 个系列以太网卡。其中,X2 系列产品是面向数据中心的设计,带宽达到10/25/40/100 Gbps,其 Cloud Onload 旁路内核技术、TCP-Direct 技术与 X2 的结合可以在负载均衡、数据库缓存、容器应用、网页服务方面减轻操作系统的开销,提高性能。
2、基于MP的架构
另一种得到业内认可的智能网卡的设计方式为采用片上多核的方式来进行网络数据的可编程加速处理,多数使用片上系统(system on chip,SoC)的实现方案,使用的处理器核可以是专用的网络处理器(network processor,NP),如 Netronome NFP 系列、Cavium Octeon系列,也可以是通用处理器(general processor,GP),如 ARM。下文将从网络处理器和通用处理器两个方面进行介绍。
1)基于 NP-SoC 的智能网卡
Netronome 早期在 2016 年推出了 NFE-3240 系列用于网络安全相关应用的智能网卡,对数据包可达到 20 Gbps 的 C 语言可编程线速处理。在 2018,2019 年,Netronome 陆续推出了 3 大系列 Agilio 智能网卡:
①面向计算节点的 Agilio CX,基于 NFP-4000 或者 NFP-5000 网络处理器,可以完全卸载虚拟交换机对网络功能中数据平面的处理、卸载典型的计算密集型任务;
②面向 Bare-Metal 服务器的Agilio FX,基于 NFP-4000 网络处理器和 4 核 ARM v8 Cortex-A72CPU(可运行 Linux OS);
③面向服务节点的 Agilio LX,基于 NFP-6000 网络处理器,主要用于虚拟化、非虚拟化的 X86 服务节点和广域网网关。Agilio 系列产品支持灵活的包解析和 Match-Action 处理,可以进行 eBPF、C、P4 编程。
Cavium 推出基于 cnMIPS III 网络处理器的 LiquidIO 系列智能网卡。其中,cnMPIS III 是 Cavium 公司实现的基于 MIPS64 指令集架构(instruction set architecture,ISA)的 Octeon 系列第 3 代产品,此外,Octeon 系列产品中还有基于 ARM 的产品。
2)基于 GP-SoC 智能网卡
Mellanox 除了推出基于 FPGA 的 Innova 系列可编程智能网卡,还推出了基于 BlueField IPU(I/O processing unit)系列可编程智能网卡,支持 Ubuntu、Centos 系统。其中 BlueField 初代产品集 ConnectX-5 控制器、ARM v8 A72 处理器阵列(最多 16 核,0.8 GHz)、8/16 GBpsDDR4 内存控制器于一体,最大支持双端口 25/50/100 Gbps 的以太网或者 Infiniband 网络连接。
BlueField-2(也属于一种 DPU)则集成了最新的 ConnectX-6 控制器,仍然使用 ARM 处理器阵列,可支持单口200Gbps 以太网或者 Infiniband 网络连接,该系列智能网卡可用于加速数据中心或者超算中的安全、存储、网络协议及功能的卸载和加速。
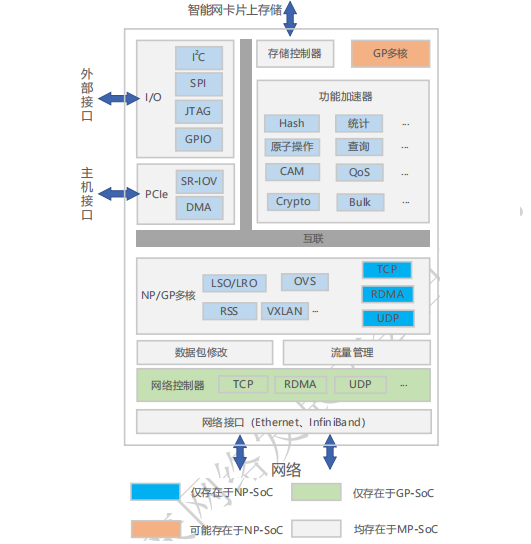
基于 MP 的智能网卡设计框架如图所示,均含有以下重点模块:
①多种已经成熟的加速部件,如 Hash 计算、加解密(Crypto)等等;
②用于与主机通信的 PCIe 接口,多数支持 SR-IOV;
③多种与外设通信的接口,如 I2C,JTAG 等;
④访问智能网卡板上内存的控制器;
⑤片上 NP 或者 GP 多核,用于 OVS,RSS(receive side scaling)等网络功能,以及用户自定义功能。NP 或者 GP 多核的具体片上布局会有差异,多数设计采用 Mesh 方式,但也有例外,如 MPPA 则采用多个 Cluster 的方式,Cluster 内部共享内存。
此外,有的 NP 内部含有多种处理器核,如 Netronome NFP 系列 NP 内部有包处理器核和流处理器核 2 大类,分别用于包的解析、分类和数据流的处理。
3、基于ASIC 的架构
目前,基于 ASIC 的智能网卡并不多,ASIC 芯片主要以网络控制器的角色出现在智能网卡中,如 Mellanox 的 ConnectX 系列、Broadcom 的 NetXtreme 系列、Cavium 的 FastLinQ 系列。此类 ASIC网络芯片除了能够满足传统的网络协议(如 TCP、RoCE)处理需求,又具备一定的卸载 CPU 处理能力和可编程性。
以 Mellanox 最新的ConnectX-6 产品为例,其在一定程度上提供对数据平面的可编程处理和硬件加速,提供虚拟化、SDN 的支持,可硬件卸载网络虚拟化中的VxLAN、NVGRE等协议,卸载网络安全中的部分加解密运算,支持 NVMe-oF 等用于存储场景的存储协议处理,支持 GPU-Direct 等机器学习应用场景中数据零拷贝的低延时通信。
4、架构对比
上述 3 种主要架构的对比如下:
(1)在性价比方面,基于 ASIC 的智能网卡,基本上可以满足多数通用网络处理的应用场景,可以在预定义的范围内对数据平面进行可编程处理,并提供有限范围内的硬件加速支持,如果是批量使用,在性价比上会有较大的优势。
(2)在编程复杂度方面,基于 ASIC 的智能网卡虽不及基于 MP的智能网卡那么简单,却也远易于基于 FPGA 的智能网卡。
(3)在使用灵活性方面,基于 ASIC 的智能网卡相比于其他的智能网卡灵活性最差,对于更复杂的应用场景则显得力不从心,更明确的来说,单纯基于 ASIC 的智能网卡应该称之为卸载网卡,因为其可编程性并不完全。
从长远的角度分析,其定制化的逻辑,对于已经成熟的应用场景虽然能够提供显著的性能提升,但是随着时间的推移,新的应用场景对智能网卡将会提出新的功能要求。目前,很多厂家采用 ASIC+GP 的设计方式来解决这一问题,类似 Mellanox 的 BlueField产品(集成了 ConnectX-5 和 ARM)。同时,商家不断地更新 ASIC 产品,将成熟的技术定制化到网卡中,如 ConnectX 系列已更新到第6代。可见,体系结构中灵活性和性能之间的竞争依然在继续。
编辑:黄飞














 工商网监
工商网监
评论