 电子发烧友App
电子发烧友App


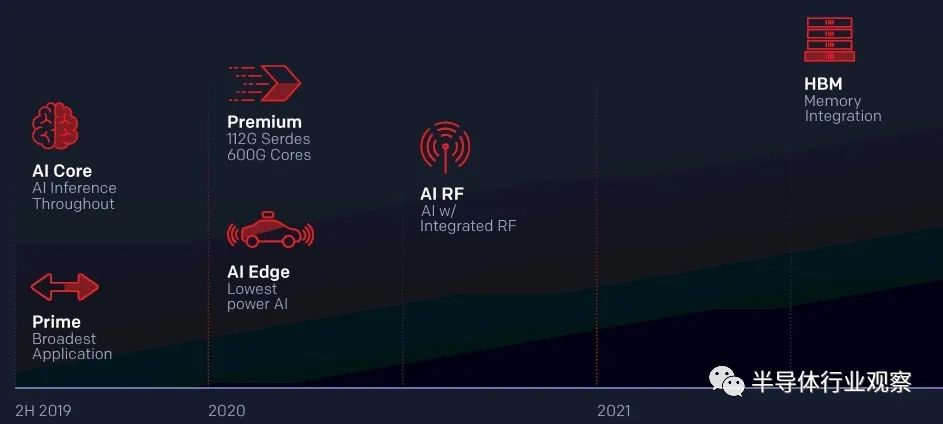
很多年前,我们曾开过一个玩笑,认为未来的计算引擎看起来更像是 GPU 卡,而不是我们当时所知道的服务器那样。该信念的核心原则之一是,考虑到有多少 HPC 和 AI 应用程序受内存带宽(而不是计算容量甚至内存容量)的约束,某种形式的极其接近、非常高带宽的内存将适用于所有方式计算芯片:包括但不限于GPU、CPU、FPGA、矢量引擎等等。 事实证明,这在很大程度上是正确的,至少在另一种存储被发明之前是这样。
如果 FPGA——更准确地说,我们称之为 FPGA 的混合计算和网络复合体,即使它们不仅仅是可编程逻辑块——要竞争计算工作,它就必须拥有某种形式的高带宽主存储器与它紧密结合。这就是赛灵思谈论其高端 Versal HBM 器件的原因,该器件自 2018 年以来,一直在赛灵思路线图中有所暗示,并将在大约 9 个月后上市。
Virtex UltraScale+ 高级产品线经理 Mike Thompson Xilinx 告诉The Next Platform. 这比预期晚了大约 6 个月——很难说许多供应商路线图上 X 轴的变幻莫测,因为它们离 Y 轴更远,但请自行估计:
Xilinx 与其他几家设备制造商一起开辟了高带宽主存储器的道路,这不是作为一项科学实验,而是因为网络、航空航天和国防、电信和金融服务行业中的许多延迟敏感的工作负载根本无法通过使用标准 DRAM 或什至嵌入在 FPGA 逻辑块中的非常快的 SRAM完成。 高带宽内存最初有两种用于数据中心计算引擎的形式,但市场已经围绕其中一种发力。 来自英特尔和美光科技的称为混合内存立方体 (HMC) 的 MCDRAM 变体部署在英特尔“Knights Landing”至强融核设备上,这些设备本身可以用作计算引擎,也可以用作普通 CPU 的加速器。Xeon Phi 可以通过 16 GB 的 HMC 内存向芯片上高度矢量化的 Atom 内核提供略高于 400 GB/秒的内存带宽,这在当时非常重要。
这种 HMC 变体还用于富士通的 Sparc64-IXfx 处理器,该处理器针对超级计算机,具有 32 GB 的容量,并在其四个内存库中提供 480 GB/秒的带宽。 但是随着富士通为世界上最强大的机器“Fugaku”设计基于 A64FX Arm 的处理器后,富士通转而使用更常见的堆叠并行 DRAM 的第二代高带宽内存 (HBM2) 变体,这是最初由 AMD 和内存制造商三星和 SK 海力士创建,并首次用于“Fiji”一代 Radeon 显卡。大约同期,英特尔推出带有 MCDRAM 的 Xeon Phi 芯片的同时。
富士通在芯片上放置了四个通道,可提供 32 GB 的容量和非常可观的 1 TB/秒的带宽——比 CPU 插槽提供的带宽高出一个数量级左右。 鉴于需要比集成 SRAM 提供更高带宽和更大容量,赛灵思在其上一代 Virtex UltraScale+ FPGA 上放置了 16 GB HBM2 内存,提供 460 GB/秒的带宽。正如您所看到的,这大约是当时的 flops-heavy CPU 计算引擎提供的性能的一半,您将再次看到这种模式。
速度与工作负载的需求和客户需要的价格点相平衡。那些购买强大 FPGA 的人同样需要高速 SerDes 进行信号传输,因此他们必须权衡网络和内存,以保持在对用例有意义的热范围内。 Nvidia 已将 HBM容量和带宽发挥到极致,因为它在其 GPU 加速器上提供了三代 HBM2 内存,当前的“Ampere”设备具有最大 80 GB 的容量,产生了令人印象深刻的 2 TB/秒的带宽。而这种对速度和容量的需求是由贪婪的人工智能工作负载驱动的,这些工作负载有爆炸式的数据集需要“咀嚼”。
在混合 CPU-GPU 系统上运行的 HPC 代码可以使用比许多 AI 代码更小的内存占用,这是幸运的,但如果内存可用,情况就不会如此。所有应用程序和数据集最终都会扩展到消耗所有容量和带宽。 当涉及到 HBM 内存时,一些设备适合这两种极端情况的中间。NEC四年前推出的“Aurora”矢量加速器拥有 48 GB 的 HBM2 内存和 1.2 TB/秒的带宽,击败了当时 Nvidia 的“Volta”一代 GPU 加速器。但今年推出的更新版 Ampere 只是在 HBM2 容量和带宽方面击败了其他一切。英特尔刚刚宣布,其未来的“Sapphire Rapids” 至强处理器SP,现在预计,明年将有一个变体,支持HBM2内存,当然,英特尔的 HPC GPU 加速器也将拥有 HBM2 内存堆栈。我们不知道英特尔的 CPU 和 GPU 在 HBM2 频谱上的最终位置,但如果英特尔真的认真对待竞争,它可能介于 CPU 的极端和 GPU 的极端之间。
Xilinx 即将推出的 Versal HBM 器件也采取了中间路线,其原因与 Virtex UltraScale+ 器件在 2016 年 11 月发布时所做的相同。但赛灵思还加入了其他 HBM 创新,在每单位容量和带宽上比其他创新更进一步减少延迟。 Versal HBM 设备基于我们在 2020 年 3 月详细介绍的 Versal Premium 而设计。Versal Premium 复合体有四个超级逻辑区域,或赛灵思所称的 SLR,其中一个 SLR 被替换为两组 8 堆栈的 HBM2e 存储器。每个堆栈最多有 16 GB,总共 32 GB,跨 SKU 的内存有 8 GB、16 GB 和 32 GB,具有不同的计算量和互连量。
紧邻交换的 HBM 存储器的 SLR 嵌入了一个 HBM 控制器和一个 HBM 开关——两者都是由赛灵思设计的——Thompson 说这些开关相对较小。这个 HBM 开关是一个关键的区别。 “HBM 面临的一个挑战是您可以从任何内存端口访问每个内存位置,我们在该设备上有 32 个内存端口,”Thompson 解释说。“市场上的其他产品也没有内置开关,这意味着他们必须花费大量的软逻辑来创建自己的开关,这会占用这些设备中的大部分逻辑,并且介于 4瓦和 5 瓦的功率。对于使用 HBM 的其他设备,没有交换机会导致大量开销和额外延迟,因为内存映射最终会比应有的更烦人。” 还有一部分 FPGA 逻辑与 SerDes 和许多其他加速器一起被硬编码在晶体管中以提高效率。Versal HBM 框图如下所示:
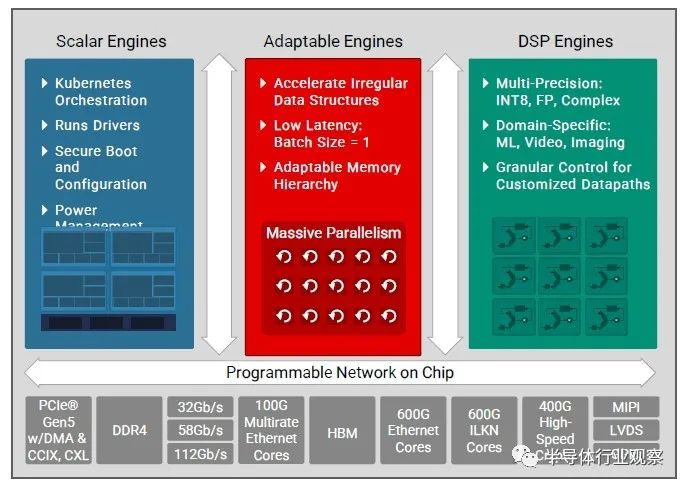
与 Versal Premium 设备一样,Versal HBM 设备具有一些基于 Arm 内核的标量处理引擎、一些实现 FPGA 功能及其内部和各种存储器的可编程逻辑,以及为机器学习、成像进行混合精度数学运算的 DSP 引擎和信号处理应用。与之相连的是 HBM 内存和大量硬编码 I/O 控制器和 SerDes,它们使数据以闪电般的速度进出这些芯片。
FPGA 客户需要在此类设备上使用 HBM 存储器的原因之一是,它具有如此多的不同 I/O,加起来如此之多的总带宽。PCI-Express 5.0 控制器支持 DMA、CCIX 和 CXL 协议以实现内存延迟,总带宽为 1.5 Tb/秒;芯片到芯片 Interlaken 互连具有集成的前向纠错 (FEC) 加速器,可提供 600 Gb/秒的总带宽。加密引擎也像 PCI-Express 和 Interlaken 控制器一样采用硬编码,支持 128 位和 256 位的 AES-GCM 以及 MACsec 和 IPsec 协议,并提供 1.2 Tb/秒的聚合带宽,并且可以进行加密400 Gb/秒以匹配 400 Gb/秒以太网端口的线路速率。
硬编码以太网控制器可以驱动 400 Gb/秒端口(带有 58 Gb/秒 PAM4 信号)和 800 Gb/秒端口(带有 112 Gb/秒 PAM4 信号)以及任何低至 10 Gb/秒的以太网步骤使用传统的 32 Gb/秒 NRZ 信令; 总而言之,该芯片的以太网总带宽为 2.4 Tb/秒。
这个 Versal HBM 设备是 I/O 上的带宽野兽,对于某些应用程序,这意味着它需要成为内存带宽野兽来平衡它。Versal HBM 设备比它将取代的 Virtex UltraScale+ HBM 设备更像野兽,并在 HBM 内存容量和带宽之外的许多不同指标上证明了这一点。这是通过架构变化和从 16 纳米工艺到 7 纳米的转变(感谢晶圆厂合作伙伴台湾半导体制造公司)实现的。
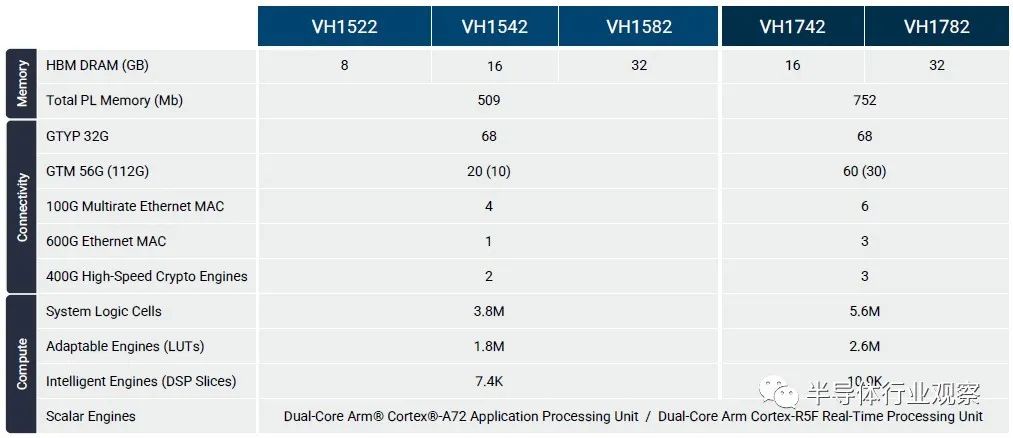
Thompson 表示,Versal HBM 设备具有相当于 14 个 FPGA 的逻辑,而 HBM 具有相当于 32 个 DDR5-6400 DRAM 模块的带宽。 Xilinx 估计,与四个相同容量的 DDR5-6400 模块相比,该器件具有 8 倍的内存带宽和 63% 的功耗:
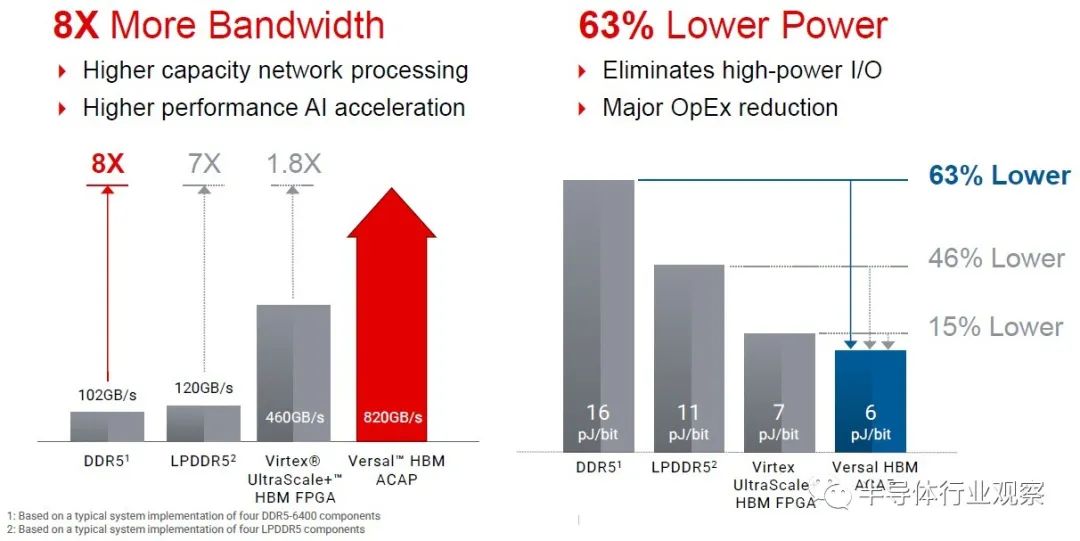
那么,Versal HBM 器件与之前的 Xilinx 器件和 Intel Agilex 器件以及 Intel 和 AMD CPU 相比如何?好吧,在以 350 亿美元收购 Xilinx 的过程中,您可以忘记将 AMD Epyc CPU 与AMD 进行任何比较。
Thompson 也没有与英特尔 ACAP 等效设备进行任何比较。但他确实带来了一些图表,将两路英特尔“冰湖”至强 SP 系统与 Virtex HBM 和 Versal HBM 设备进行对比,如下所示:

在上图左侧的临床记录推荐引擎测试中,仅使用 CPU 的系统需要几秒到几分钟才能运行,但旧的 Virtex HBM 设备能够容纳两倍大的数据库,因为它的速度是它可以将数据流式传输到设备中,并且在提出治疗建议方面的速度提高了 100 倍。
Versal HBM 设备拥有两倍大的数据库,并且以两倍的速度导出建议。右侧的实时欺诈检测基准也具有相同的相对性能。 Thompson 说,这是考虑如何使用 Versal HBM 设备的另一种方式。
假设您想构建一个内置机器学习智能的下一代 800 Gb/秒防火墙。如果您想使用只能驱动 400 Gb/秒端口的 Marvell Octeon 网络处理器 SoC,您将需要其中的两个,而且他们没有机器学习。因此,您将需要两个 Virtex UltraScale+ FPGA 来将该功能添加到 Octeons 对中。还需要十几个 DDR4 DRAM 模块才能提供 250 GB/秒的内存吞吐量。像这样:

据推测,Versal HBM 系统不仅在设备更少、吞吐量更大和功耗更低方面表现更好,而且购买成本也更低。我们不知道,因为 Xilinx 没有给出定价。如果没有,它肯定必须提供更好的性价比和更好的每瓦特性能,否则玩这个游戏根本没有意义。
编辑:黄飞










 工商网监
工商网监
评论