 电子发烧友App
电子发烧友App


本方案利用 HLS 功能创建图像处理解决方案,在可编程逻辑中实现边缘检测 (Sobel)。
介绍
高级综合 (HLS) 允许我们在开发 FPGA 应用程序时在更高的抽象级别上工作,如果是商业项目,有望节省时间并降低非经常性成本。
HLS 的一个重要应用是图像或信号处理,我们可能已经用 C 或 C++ 创建了一个高级模型,或者我们希望使用开源行业标准框架,例如 OpenCV。
在本项目中,我们将研究如何使用 HLS 构建 Sobel 边缘检测 IP 核,然后将其包含在我们选择的 Xilinx FPGA 中。
所选器件可以是传统的 FPGA,例如 Spartan Seven 或 Artix,或者也可以在异构 SoC 的可编程逻辑中实现,例如 Zynq 7000 或 Zynq MPSoC。
理论
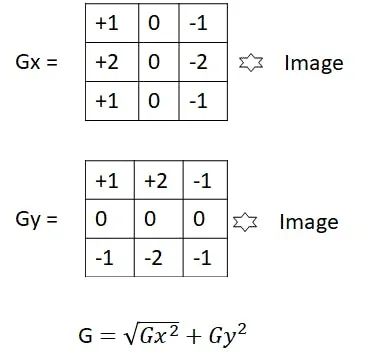
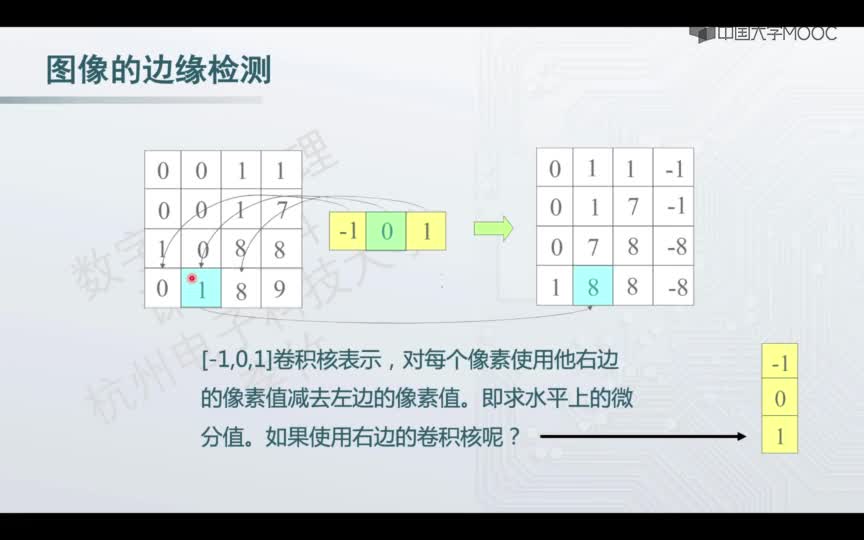
在我们进入应用程序之前,我应该先简单介绍一下 Sobel 算法的工作原理。Sobel 算法通过识别图像中的边缘并强调它们以便可以轻松识别它们来发挥作用。通常这将创建一个灰度图像,其中边缘被识别为灰色/白色阴影。
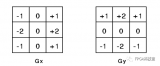
Sobel 边缘检测的工作原理是检测图像在水平和垂直方向上的梯度变化。为此,将两个卷积滤波器应用于原始图像,然后组合这些卷积滤波器的结果以确定梯度的大小。
执行
如果我们使用传统的 VHDL / Verilog RTL 方法在 FPGA 中实现这一点,那么开发时间将不会很短。因为我们需要为卷积创建行缓冲区,然后实现幅度计算。我们还需要创建一个测试平台,以确保我们的代码在进行实施之前按预期工作。
幸运的是,当我们使用 HLS 时,我们真的可以跳过很多繁重的工作,让 Vivado HLS 实现较低级别的 Verilog/VHDL RTL 实现。
为了在这个更高的抽象级别上工作,我们将使用 Vivado HLS 及其 HLS_OpenCV 和 HLS_Video 库。
第一个库 HLS_OpenCV 允许我们使用非常流行的 OpenCV 框架。而 HLS 视频库提供了许多可以加速为可编程逻辑的图像处理功能。
而是有益的HLS视频库包括我们需要创建一个索贝尔IP核心,内容包括:-
HLS::CvtColor - 这将根据其配置在颜色和灰度之间转换颜色方案。
HLS::Gaussian - 这将对图像执行高斯模糊以减少图像中存在的噪声。
HLS::Sobel - 根据其配置在垂直或水平方向执行 Sobel 卷积。我们将需要在我们的 IP 核中使用这两个实现。
HLS::AddWeighted - 这允许我们使用来自垂直和水平 Sobel 算子的结果来执行结果幅度计算。
这些不是我们将使用的所有 HLS 函数,因为我们需要使用其他函数。我们需要包含这些附加功能,以便更轻松地使用 HLS 优化和与 Vivado 设计的接口。
界面
在可编程逻辑内部移动图像数据的最佳方法是使用 AXI 流。
这允许创建高性能图像处理路径,其中元素可以根据需要轻松添加或创建。
Vivado IP 库中存在多个 IP 模块,可实现视频输入和输出与 AXI 流之间的转换。以及其他图像处理功能,例如混合器和色彩空间转换器。
因此,我们希望我们的 Sobel IP 核能够接受 AXI Stream 输入并以相同的 AXI Stream 格式生成其输出。为此,我们使用以下函数允许在 AXI 流和 HLS 函数使用的 HLS::Mat 格式之间进行转换。
HLS::AXIvideo2Mat - 从 AXI 流转换为用于 AXI 流输入的 HLS::Mat 格式。
HLS::Mat2AXIvideo - 从 HLS::Mat 格式转换为 AXI Stream 格式,用于 AXI Stream 输出。
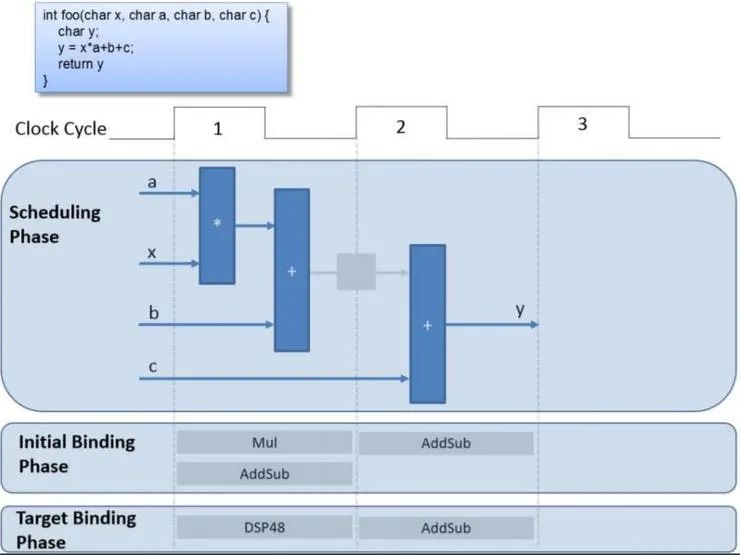
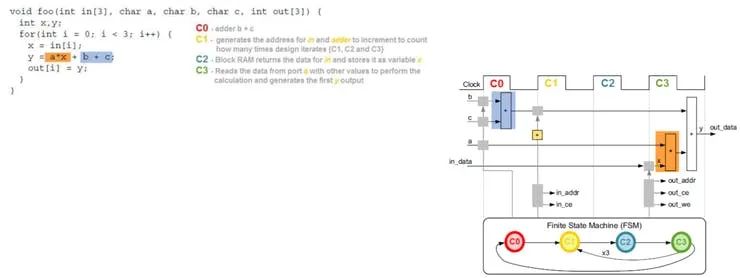
C 综合和优化
与 Verilog 和 VHDL 设计不同,我们用来描述设计的高级语言是不定时的。这意味着当 HLS 工具将 C 转换为 Verilog 或 VHDL 时,它必须经过多个阶段才能创建输出 RTL
调度 - 确定操作及其发生的顺序。
绑定 - 将操作分配给设备内可用的逻辑资源。
控制逻辑提取 - 提取控制逻辑并创建控制结构,例如状态机以控制模块的行为。
由于 HLS 工具在运行综合时必须在性能和逻辑资源之间进行权衡,因此在实现过程中将遵循许多规则。这些可能会影响生成的 IP 核的性能,例如循环(HLS 编码中的常见结构)保持滚动。
当然,我们可能希望更改 HLS 工具在 C 综合期间做出的决定以获得更好的性能。我们可以在我们的 C 中使用 #pragmas 来做到这一点,我们可以使用几个。
对于这个实现,我们将使用 Dataflow pragma 来确保我们可以达到最高的帧速率。
为了能够使用此编译指示,我们需要确保 HLS 综合工具并行执行两个 Sobel 操作。这将允许我们在 HLS C 综合期间指定数据流优化,从而优化通过函数的数据流。实际上,数据流优化是粗粒度流水线。
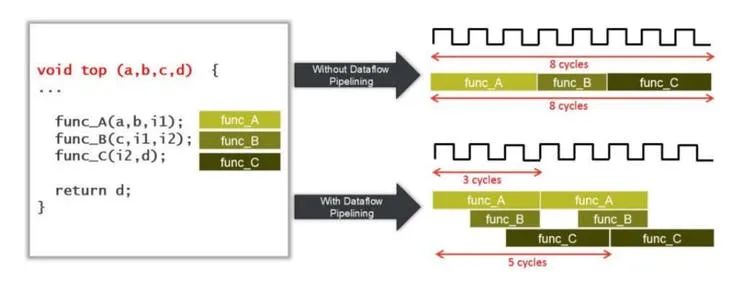
如果我们先执行一个 Sobel 操作,然后按顺序执行另一个操作,我们将无法应用此优化。
因此,我们需要将高斯模糊的结果分成两条平行路径,然后在 AddWeighted 阶段重新组合。为此,我们使用函数
HLS::Duplicate - 这将输入图像复制到两个单独的输出图像中,我们可以并行处理这些图像。
软件
了解所有这些之后,我们就可以编写用于 Sobel IP 核的代码
#include "cvt_colour.hpp"
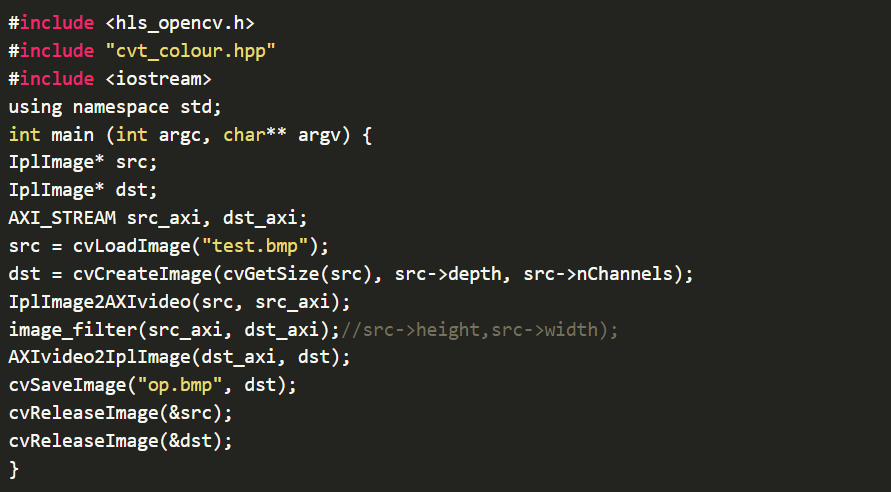
void image_filter(AXI_STREAM& INPUT_STREAM, AXI_STREAM& OUTPUT_STREAM)//, int rows, int cols)
{
#pragma HLS INTERFACE axis port=INPUT_STREAM
#pragma HLS INTERFACE axis port=OUTPUT_STREAM
RGB_IMAGE img_0(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_1(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_2(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_2a(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_2b(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_3(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_4(MAX_HEIGHT, MAX_WIDTH);
GRAY_IMAGE img_5(MAX_HEIGHT, MAX_WIDTH);
RGB_IMAGE img_6(MAX_HEIGHT, MAX_WIDTH);
;
#pragma HLS dataflow
hls::AXIvideo2Mat(INPUT_STREAM, img_0);
hls::CvtColor
hls::GaussianBlur<3,3>(img_1,img_2);
hls::Duplicate(img_2,img_2a,img_2b);
hls::Sobel<1,0,3>(img_2a, img_3);
hls::Sobel<0,1,3>(img_2b, img_4);
hls::AddWeighted(img_4,0.5,img_3,0.5,0.0,img_5);
hls::CvtColor
hls::Mat2AXIvideo(img_6, OUTPUT_STREAM);
}
#include "hls_video.h"
#include
#define MAX_WIDTH 1280
#define MAX_HEIGHT 720
typedef hls::stream
typedef hls::Mat
typedef hls::Mat
void image_filter(AXI_STREAM& INPUT_STREAM, AXI_STREAM& OUTPUT_STREAM);//int rows, int cols);
当然,我们希望能够同时运行 C Simulation 和 Co Simulation,因此我们需要一个可以用来测试算法的测试台。
当我们运行 C Simulation 时,我们可以看到测试输入图像的结果如下。


有了 C 仿真和 Co 仿真结果,我们可以导出内核并将其添加到 Vivado 硬件设计中。
但是,在我们执行此操作之前,您可能需要检查分析、在 Vivado HLS 中查看并确认两个 Sobel 函数并行运行。

我们可以使用 Vivado HLS 中的导出 RTL 选项导出 IP 核,如果我们希望我们可以进一步配置 IP 核参数
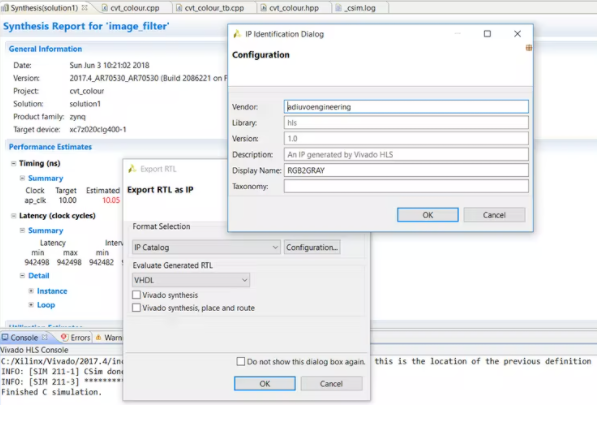
实现核心
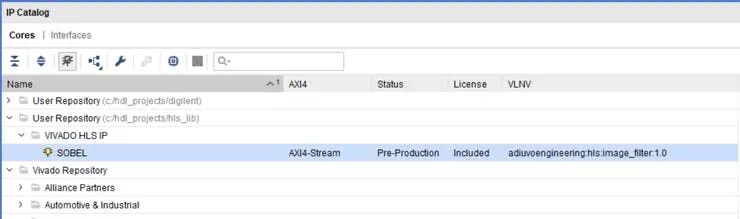
导出核心后,您将在
该文件可以添加到我们的 Vivado IP 存储库中,然后包含在 Vivado 框图中
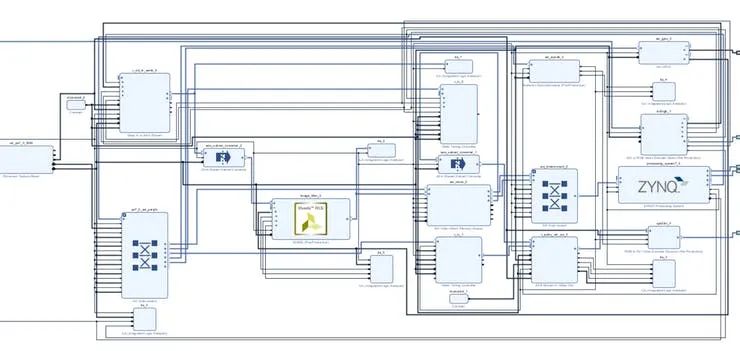
有了这一切集成,您可以构建应用程序和目标到您选择的开发板。
编辑:黄飞









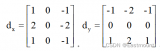






 工商网监
工商网监
评论