 电子发烧友App
电子发烧友App


01
数字图像基本概念
数字图像 (Digital Image),是计算机视觉与图像处理的基础,区别于模拟图像。通常直接观测到的图像可以理解成连续的模拟量,模拟量在处理时涉及运算相对复杂,内部相关性较高,难以形成统一定量的标准。随着计算机的发展,为便于计算机的运算与定量处理,同大多数模拟量一样,模拟图像需要通过采样量化转化为离散的数字量,即数字图像。
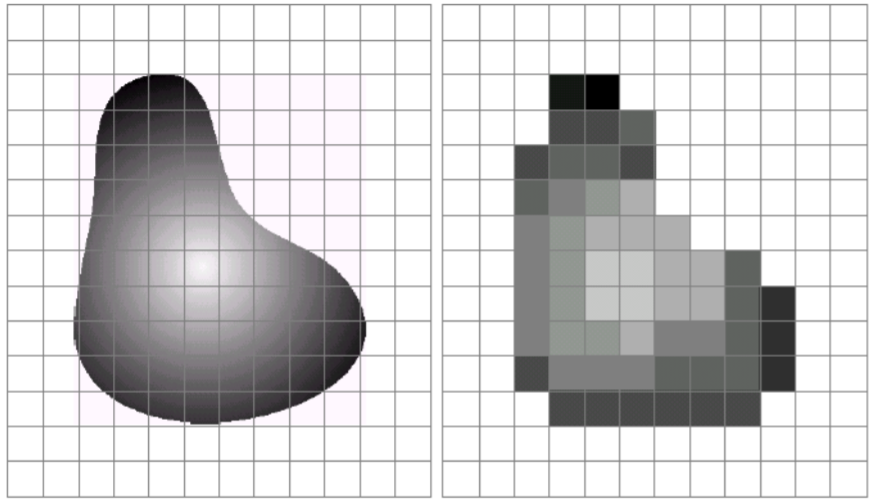
1.1 数字图像提取
数字图像通过对模拟图像采样和量化得到,该过程通常由图像传感器(例如CMOS图像传感器)实现,图像传感器通常为感光元件阵列。图像传感器的性能决定了采集到的数字图像的质量。
1.1.1 采样处理
采样(Sampling) 处理即对图像所在空间坐标进行数字化,将空间上连续的图像转变为离散的采样点。采样处理的评估指标为图像的空间****分辨率。

1.1.2 量化处理
量化(Quantifying) 处理即对采样信号按一定规则赋值,对采样点幅度进行离散化。量化处理的评估指标为图像的 幅度分辨率 ,也称为 灰度级分辨率 。量化通常以图像的明暗信息为标准,考虑人眼识别能力,采用8bit 0255来描述黑白。
量化通常可分为均匀量化和非均匀量化:
均匀量化对连续灰度值等间隔分层,层数越多,产生的量化误差越小;
非均匀量化通常基于不同的特性设置不同的采样间距,例如,基于视觉特征的非均匀量化通常缩小细节丰富地方的采样间距,基于统计特征的非均匀量化通常缩小灰度值出现频繁的采样间距。

通过采样与量化处理后提取的数字图像可以由一个矩阵进行表示,矩阵的大小为图像的空间分辨率,矩阵每个元素的值为对应像素的幅度分辨率。

1.2 数字图像概念
数字图像处理过程中常见概念:
1.2.1 数字图像基本单位——像素
像素(Pixel) ,也称为像元,是数字图像的基本元素。像素在模拟图像离散化过程中生成,即采样过程提取到的每一个采样点就是一个像素。每个像素都具有位置坐标与灰度值(或颜色值)。在其他条件相同的情况下,包含像素越多的图像,清晰度越高。

1.2.2 数字图像的灰度与深度
数字图像的灰度与深度通常用来衡量量化程度。灰度指每个像素取值大小,灰度范围即每个像素取值的范围,通常在其他条件相同的情况下,灰度值范围越大的图像越清晰;深度指每个像素存储所需要的容量,通常也称为灰度级,灰度范围越大,所需要的深度越大。通常用8bit表示256个灰度级,灰度为0~255中某个整数,深度为8。

1.2.3 数字图像的分辨率
数字图像的分辨率包括空间****分辨率和 幅度(灰度)分辨率 。空间分辨率指数字图像所包含的像素个数,用于衡量图像大小(通常利用分辨率描述图像大小不能离开空间单位,例如印刷行业采用dpi表示每英寸像素数); 幅度(灰度)分辨率指数字图像量化灰度的位数,与深度的含义相同。

1.2.4 数字图像的常见种类
- 二值图像 :图像像素亮度值仅由0和1构成;
- 灰度图像 :图像像素亮度值由0
255表示黑白; - 彩色图像 :由RGB三幅不同颜色的灰度图像组成;
- 立体图像 :某物体从不同角度拍摄的一对图像,可以计算出图像深度信息;
- 三维图像 :由一组堆栈的二维图像组成,每幅图像表示物体的一个横截面;
1.2.5 数字图像的常见格式
- JPG格式 :全称为JPEG,以24为颜色存储单个光栅图像,支持最高级别的有损压缩,压缩比率可达100:1,但会牺牲大量图像质量,通常在10:1到20:1的压缩比下保证图像质量。JPEG压缩可以很好得处理类似色调,但不能很好得处理亮度差异大和纯色区域。JPEG支持隔行渐进显示,但不支持透明性和动画,对JPEG图像进行除旋转裁剪外得编辑操作通常会导致图像质量损失,因此在编辑过程通常以PNG作为过渡格式;
- PNG格式 :流式网络图形格式(Portable Network Graphic Format,PNG)是20世纪90年代中期开始开发的图像文件存储格式,其目的是企图替代GIF和TIFF文件格式,同时增加一些GIF文件格式所不具备的特性PNG采用从LZ77派生的无损数据压缩算法,用来存储灰度图像时,灰度图像的深度可多到16位,存储彩色图像时,彩色图像的深度可多到48位,并且还可存储多到16位的α通道数据。PNG格式包括许多类,实践中大致可分为256色和全色,其中256色PNG可以代替GIF格式,全色PNG可以代替JPEG格式。PNG支持alpha透明,即支持透明、不透明和半透明,图像颜色较少且主要以纯色或平滑渐变色填充和亮度差异大的图像适合以PNG8格式存储;
- GIF格式 :GIF(GraphicsInterchange Format)图像互换格式是CompuServe公司在1987年开发的图像文件格式。GIF文件的数据采用了可变长度等压缩算法,是一种基于LZW算法的连续色调的无损压缩格式,压缩率一般在50%左右。它不属于任何应用程序,目前几乎所有相关软件都支持。GIF的图像深度从1bit到8bit,最多支持 256 种色彩图像。在一个 GIF文件中可以存多幅彩色图像,如果把存于一个文件中的多幅图像数据逐幅读出并显示到屏幕上,就可构成一种最简单的动画。GIF支持动画和布尔透明,即不支持半透明(alpha透明),GIF支持可选择性的间隔渐进显示,同时LZW水平扫描压缩使得同一图片横向GIF比竖向GIF占用空间更小;
- BMP格式 :BMP是一种与硬件设备无关的图像文件格式,采用位映射存储格式,除了图像深度可选可选1bit、4bit、8bit及24bit以外,不采用其他任何压缩,因此BMP 文件所占用的空间很大。BMP支持索引色和直接色,存储数据时,图像按从左到右、从下到上的顺序进行扫描;
- SVG格式 :可缩放矢量图形 (Scalable Vector Graphics)是由万维网联盟制定的一个基于可扩展标记语言(标准通用标记语言的子集)的开放标准,用于描述二维矢量图形的一种图形格式,因此在放大时不会失真,线不会变为像素点。SVG使用XML格式定义图形,与DOM和XSL等W3C标准是一个整体;
02
数字图像处理算法
数字图像处理算法通常包括图像增强、图像拼接、图像分割、图像压缩、图像识别、图像变换、图像复原、图像重建等研究领域。
2.1 图像增强
图像增强技术针对光照不足、雨雾影响等噪声较大的图像,改善画质,提高图像清晰度。常用算法包括直方图均衡化、Retinex理论、深度学习等。
2.1.1 直方图均衡化
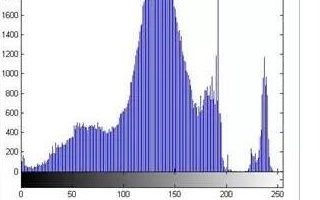
图像直方图和图像像素之间存在直接映射关系,直方图均衡化可以将这一映射表达出来。直方图均衡化的基本思想是对图像像素统计个数多的灰度级进行展宽,对像素统计个数少的灰度级进行缩减,改变图像通道的直方图分布以达到视觉上对比度增强的效果。
直方图均衡化图像增强通过利用直方图可以进行层次差分表达的特性,增强图像的对比度,并将相邻像素间的灰度差放大,从而提高图像对比度。

直方图均衡化仅对图像像素进行映射,计算像素强度而忽略其空间信息,导致图像的局部亮度调节能力不够好,从而影响到某些场景的整体亮度,同时可能会引入其他噪声。
2.1.2 Retinex理论
Retinex的基本思想是,将待增强图像S分解为图像的反射成分R(x)与光照成分L(x)的积,即对象自身色彩与光照成分无关,取决于对象表面的反射特性,因而从输入图像中移除干扰图像强度的成分可以获得图像的增强。
将固有先验引入到分解模型中来增强对比度,在反射层和光照层分别引入约束条件(反射层通过颜色相似性对相邻像素进行规范约束,光照层通过分段平滑进行约束)可以解决增强图像出现过亮等问题。

2.1.3 深度学习
随着深度学习的发展,基于卷积神经网络(CNN)、对抗生成网络(GAN)等图像增强算法也相继被提出。下图是在Retinex原理启发下提出的CNN网络方法流程图,将网络分成用来调节光线和用来消除噪声两部分。

无监督深度网络模型,零参考深度曲线估计网络(Zero-DCE)方法利用深度网络将增强作为图像特定曲线估计的任务,该方法不要求有成对或不成对的数据,而是训练一种用于估算像素水平和高次曲线的网络以适应给定的图像动态范围。

2.2 图像拼接
图像拼接技术针对单镜头拍摄图像显示范围的局限性,将多幅图像拼接为一幅以克服图像视野的限制、扩大图像范围进而更好地展示细节。图像拼接的主要方法有两种:基于区域的图像拼接方法和基于特征的图像拼接方法。
2.2.1 基于区域的图像拼接方法
基于区域的图像拼接方法通过对两张待拼接图像在同一区域内的强度差进行计算得到拼接后图像。基于区域的拼接方法有:像素点匹配法、基于互信息的方法和基于拉普拉斯金字塔的方法。此类方法的优点是最优地利用了图像对齐信息,但是计算量大,配准精度低,对常见几何变换没有不变性。
2.2.2 基于特征的图像拼接方法
基于特征的图像拼接方法是通过像素得到图像特征信息进而匹配和拼接图像,步骤包括:图像的特征提取与描述、特征匹配、重投影拼接和图像融合。图像特征提取与描述是描述一块与其他区域高度可区分的区域,局部特征应准确、有效、区分性强。特征匹配要找同一场景的待拼接图像间的匹配点。重投影拼接和图像融合是指使用几何变换将图像对齐到一个统一的坐标系统中并消除由光照影响产生的拼接缝。此步中首先要描绘输入图像的几何变换关系,一般的变换关系是8个自由度的单应性矩阵,然后进行重投影拼接,最后融合拼接缝处光照突变的像素。
基于特征的图像拼接技术普适性好、在各领域使用频率最高、范围最广,因此是实现图像拼接最好的选择。图像配准常用算法包括Harris角点检测、SIFT、PCA-SIFT、FAST、ORB、SURF等算法;图像重投影拼接与融合常用算法为RANSAC算法。
2.3 图像分割
图像分割技术针对图像中某些特定物体进行研究,将待研究物体分离以更清晰得研究物体变化特点。图像分割技术主要应用于医学和科研领域,医学图像中不同的人体器官、组织和病变区域所表现的复杂特点,以及医学图像自身的复杂性和多模态性,对适用于各种类型的医学图像分割任务的图像分割算法提出了很高的要求。图像分割技术根据图像特征手工提取和自动学习方式可划分为两大类:传统图像分割方法和基于深度学习的图像分割方法。

2.3.1 传统图像分割方法
传统医学图像分割方法主要依赖于图像中强度值的不连续性和相似性特征。例如基于边缘检测的方法根据图像中强度级别或图像灰度级别的瞬时变化,利用其不连续性实现图像的分割,其主要关注孤立点的识别。阈值分割或区域分割等根据图像分割的预设标准,基于一定范围内的像素相似性来分割图像。传统的医学图像分割方法可大致分为阈值分割法、基于区域的分割方法、聚类分割法、基于边缘检测的分割方法、基于模型的分割方法。
2.3.2 基于深度学习的图像分割方法
基于深度学习的分割方法克服了传统手工特征分割的局限性,在特征自动学习方面凸显优势。其中,全卷积网络(Fully Convolutional Network, FCN)在语义分割取得优异的效果,为语义分割提供了新的思路和方向,在医学图像语义分割任务中得到了广泛的应用,并在该领域取得了大量的研究成果。从数据驱动技术的角度出发,深度学习在医学图像分割中的方法可大致划分为监督学习、弱监督学习和其他方法。
2.4 图像压缩
图像压缩技术针对图像数据冗余度较大的问题,将图像中的冗余度压缩以减小图像数据量,从而加速图像的传输于处理过程。图像压缩技术的研究方向主要包括两个方面:传统的图像压缩技术研究和基于深度学习的图像压缩技术研究。
2.4.1 传统的图像压缩技术研究
传统的图像压缩技术研究从信息恢复的角度主要分为无损压缩和有损压缩两类:
无损压缩编码:压缩过程不损失任何信息,重建后的图像与原来的图像完全相同,在数据压缩过程中尽量降低冗余度,常用编码包括Huffman编码、算数编码、行程编码等;
有损压缩编码:压缩过程通过损失一定的信息实现更高的压缩率,重建后的图像与原图有差距,常用编码包括JPEG,H.264等。

2.4.2 基于深度学习的图像压缩技术研究
传统的编码质量评估通常针对一些客观的性能指标,对于比较主观的质量指标和语义质量指标比较难以满足其要求,也无法获得图像深层次的语义信息。因此,传统的图像压缩编码在这方面已经无法满足现代的要求,深度学习和计算机视觉的发展进步带来一种新的解决图像压缩编码的问题方式:端到端的图像压缩能够将图像编码中的各个模块进行联合优化,依靠数据自身进行评估。
2.5 图像识别
图像识别技术针对通过计算机视觉识别物体这一方向深入研究发展,在神经网络等技术的发展下取得优异成就。图像识别技术可划分为两类:传统图像识别算法和基于深度学习的图像识别算法。
2.5.1 传统图像识别算法
传统的图像识别算法包括微分算子边缘检测算法、Canny边缘检测算法、角点检测算法等。
Canny边缘检测算法: 一般包含4个步骤:滤波、梯度幅值和梯度方向计算、非极大值抑制计算、边缘检测与连接。首先通过高斯滤波函数去除图像的噪声,并对图像进行平滑处理,接着通过一阶有限差分法分别对滤波后的图像水平和垂直方向的像素点进行偏导求解,再使用非极大值抑制算法将局部最大值之外的正负梯度值设置为0,最后通过不相同的2个阈值对候选边缘图像中的像素进行处理,保留两阈值范围内的像素,最终检测出物体。传统的Canny边缘检测算法降噪能力较差,同时使用4个具有各向异性的5阶差分模板检测多个方向上的像素点,不仅能够检测上下左右4个领域的灰度加权值,同时还能够检测对角线方向的值。为了提高Canny算法的自适应能力,采用自适应中值滤波和形态学闭合运算来防止多方向梯度幅值计算时边缘信息被弱化,同时利用目标与背景的最佳分离点是最优梯度下最大的类间方差与最小的类内方差这一概念,来计算Canny算法中的上下阈值,以此来提高其自适应能力。
角点检测算法: 是通过一个固定像素窗口在图像中进行任意方向的滑动,比较滑动前后窗口中的像素灰度值,如果存在较大的变化,则可判断出该像素内存在角点。角点检测算法分为3类:基于二值图像的角点检测、基于灰度图像的角点检测和基于边缘轮廓的角点检测。传统的Harris角点检测算法精度较低,抗噪性差,将Sobel算法和Harris算法结合可以有效提高算法性能(首先使用Sobel算法进行角点初选,将非极大值抑制算法中的矩形模板用圆周模板替代,以此来提高检测精度,最后使用临近点剔除法提高算法的抗噪性)。通过比较阶梯边缘、L型拐角、Y或T型拐角、X型拐角和星型拐角的强度变化特性后,利用多尺度各向异性高斯方向导数滤波器,从输入图像中提取灰度变化的新方法能够连续地提取图像中的边缘点和角点特征。
2.5.2 基于神经网络学习的图像识别算法
基于神经网络学习的图像识别算法主要可以分为卷积神经网络、注意力神经网络、自编码神经网络、生成网络和时空网络。卷积神经网络是所有其他复杂网络的基础,基于CNN卷积神经网络提出了一系列典型的框架: Le Net、Alex Net、Goole Net、VGGNet、Res Net、Inception、DenseNet。
03
FPGA与数字图像处理
数字图像由大量的像素组成,数字图像处理算法通常基于未压缩的原图,以19201080 RGB格式 256灰度图像为例,单幅图像的数据量为1920108038bit=6.22MB。DSP、GPU、CPU通常以帧为单位对图像的处理,需要将采集图像从内存读取后进行处理,处理一帧的图像都将耗费大量的时间,使得视频图像的帧率难以提高。
FPGA数字图像处理的优势在于以行为单位实时流水线运算,从而达到最高的实时性。FPGA可以直接与图像传感器芯片连接获得图像数据流,RAW格式还可以进行插值以获得RGB图像数据。FPGA通过内部Block RAM缓存若干行图像数据实现实时流水线处理,FPGA的Block RAM类似于CPU的Cache,但是Cache不能完全控制,Block RAM完全可控,因此可以用它实现各种灵活的运算处理。
由于Block RAM在FPGA中的有限性,通常也可采用外接DDR将图像缓存后读出,但是这种处理模式类似于CPU从内存中读取处理,无法达到最高的实时性。因此,如何合理利用Block RAM这一稀缺资源是充分发挥FPGA图像处理实时性的关键。
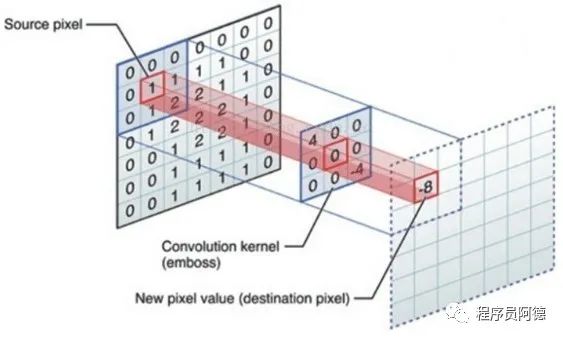
FPGA对图像数据流处理通常采用顺序读取,可以快速高效实现以3x3到NxN算子进行的滤波、腐蚀、膨胀、边缘提取等算法,以及卷积神经网络的卷积层运算,FPGA的并行特性决定了处理这种类型算法相比于其他处理器速度最快,优势最大。尽管这种算法运算较为简单,但通过不同算子的配合可以实现例如边缘提取,运动目标识别等不同功能,同时可以满足实时性的要求。
因此,FPGA的并行特性使之在图像处理和深度学习领域存在一定的优势,由于FPGA开发相对于DSP等嵌入式需要一定的门槛,导致该领域的工程师数量相对较少,对于FPGA擅长的功能有待进一步发掘。















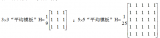
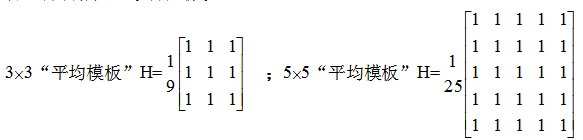





 工商网监
工商网监
评论