Spansion公司(纽约证交所代码:CODE)今天宣布推出Spansion®语音协处理器,这是业界首款支持语音控制系统接口的人机接口(HMI)协处理器。凭借Nuance Communications公司(纳斯达克代码:
2012-07-04 09:21:42 1150
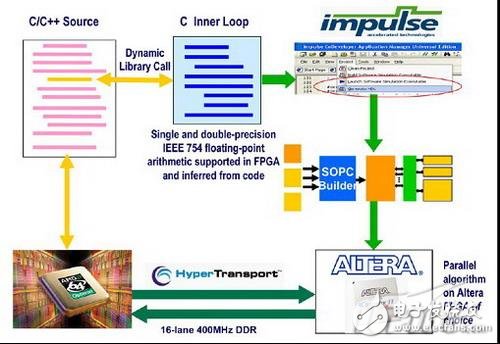
1150 传统的、基于通用DSP处理器并运行由C语言开发的算法的高性能DSP平台,正在朝着使用FPGA预处理器和/或协处理器的方向发展。这一最新发展能够为产品提供巨大的性能、功耗和成本优势。 尽管优势如此明显
2023-10-21 16:55:022727 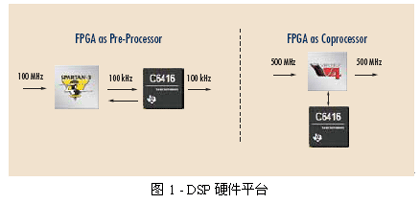
ARM架构通过支持协处理器来扩展处理器的功能。ARM架构的处理器支持最多16个协处理器,通常称为CP0~CP15。下述的协处理器被ARM用于特殊用途。
2023-10-31 16:07:403831 
BlueNRG 系列芯片从最早的一代 BlueNRG-MS 开始就支持协处理器模式。
2024-01-05 18:16:103256 
有谁来阐述一下FPGA协处理的优势有哪些?如何去使用FPGA协处理?怎样借助FPGA协处理去提升性能?怎样借助FPGA嵌入式处理去降低成本?从C程序到系统门指的是什么?采用FPGA协处理的障碍是什么?
2021-04-14 06:07:36
传统的、基于通用DSP处理器并运行由C语言开发的算法的高性能DSP平台,正在朝着使用FPGA预处理器和/或协处理器的方向发展。这一最新发展能够为产品提供巨大的性能、功耗和成本优势。
2011-09-29 16:28:38
ARM的MMU主要实现什么功能?协处理器cp15主要主要实现何功能?简述MMU使能时存储访问过程
2021-03-16 07:57:10
有了解AM335x的协处理器来做IO控制的吗? 我目前看资料就只了解有PRU-ICSS这个协处理器,看了TI的一些维基百科的一些资料,知道要操作协处理器,必选要linux的SDK支持PRU,然后具体的就不知道怎么做了?
2018-11-29 16:52:29
本帖最后由 qzq378271387 于 2012-8-15 16:56 编辑
Altera的DSP_Builder现支持FPGA协处理器
2012-08-15 16:37:33
谁能向我解释 BlueNRG-2 SoC 和 BlueNRG-2N 协处理器之间的区别?
2022-12-09 07:34:29
本设计首先根据MD5协处理器的功能设计MD5算法IP核,软件部分使用串口程序助手进行64位加解密结果的输出,E203内核根据地址取出对应的数据,使用相关的指令进行传输显示。通过NICE接口将MD5协
2025-10-30 07:54:24
实现思路:
1.硬件设计,编写相应的verilog文件,需要注意的是NICE协处理器定义了一些基本的接口;
2.编写驱动,通过内联汇编的伪指令.insn配置相关的驱动设置;
3.编写用于测试
2025-10-23 07:05:09
使用扩展指令调用NICE协处理器完成预定操作,给出的优势通常为代替CPU处理数据,但其实使用片上总线挂一个外设,然后驱动外设完成操作也可以实现相同的功能,所以想问一下协处理器相比于外设实现还有没有其它方面的优势
2025-05-28 08:31:12
cpu发送的信号,demo中状态机在到达需要访存的时刻把该信号置为有效,如下图所示。
nice_icb_cmd_ready信号是cpu告知协处理器收到了访存请求的反馈信号
2025-10-31 08:01:35
NICE协处理器最多可以处理多少个周期再抬高nice_rsp_valid啊?
2023-08-16 07:56:35
赛普拉斯的 PSoC® 模拟协处理器是可编程模拟协处理器的可扩展和可重配置的平台架构;它能够简化带有多个传感器的嵌入式系统的设计。 PSoC 模拟协处理器设备集成了 PSoC 的灵活模拟前端
2020-09-01 16:50:45
XMC1300的MATH协处理器 1XMC1300芯片带有一个MATH协处理器,它包含以下两个子模块除法器Cordic协处理器 2 除法器特性可做32位/32位,32位/16位,16位/16位除法
2018-12-11 10:57:03
呵呵,s3c2410...在vivi中的s3c2410.h文件中设置时钟时 有这么一段mrc p15,0,r1,c1,c0,0orr r1,r1,#0xc0000000;mcr p15,0,r1,c1,c0,0这段的每句 的意思是什么?为什么要用到些处理器指令?协处理器指令的作用是干什么?
2019-02-25 12:34:48
处理器功能在硬件中实现以替代几种软件指令。通过减少多种代码指令为单一指令,以及在硬件中直接实现指令的方式,从而实现代码加速。最常用的协处理器是浮点单元(FPU),这是与CPU紧密结合的唯一普通协处理器
2015-02-02 14:18:19
代码加速和代码转换到硬件协处理器的方法如何采用FPGA协处理器实现算法加速?
2021-04-13 06:39:25
举例说明FPGA作为协处理器在实时系统中有哪些应用?FPGA用于协处理器有什么结构特点和设计原则?
2021-04-08 06:48:20
问题一:在vivado中编写约束文件时,由于nice接口的指令是由CPU、协处理器和内存互相发送的,因此是否只需要约束clk和复位信号即可?
问题二:从软件示例程序中可知,数据是由软件输入的,那
2023-08-16 07:24:08
本次给大家介绍的是利用Verdi调试协处理器的实现步骤。
有时为了观察协处理器运行情况,需要查看协处理器接口的信号波形,此时可以用Verdi来查看主处理器发给协处理器的自定义指令以进一步追踪协处理器
2025-10-30 08:26:28
国一的协处理器应用
(1) 概念
领域特定架构(Domain SpecificArchitecture,DSA),使用特定的硬件做特定的事情[18],也就是说,将主处理器和协处理器加速器适当
2025-10-21 14:35:54
实现功能:基于官方提供的demo nice的硬件代码,设计一个基于e203 nice协处理的加法器。
NICE协处理器理论学习
nice协处理器的作用主要是用于控制通路的管理
去年国一的协处理器
2025-10-21 10:39:24
要跟上日益提高的性能需求,还得注意保持成本低廉有效利用基于串行RapidIO的FPGA作为DSP协处理器就能达到这些目的。那么,我们该怎么做呢?
2019-08-07 06:47:06
按照这句话的意思,协处理器拓展指令只能实现读写操作吗,官方的案例貌似也只是读写指令。那如何用协处理器拓展指令实现更高级运算呢,用内联汇编吗
2023-08-16 07:41:54
本文讲述汽车娱乐系统的需求,讨论主流系统构架,以及FPGA协处理器是如何集成到软硬件体系中,以满足高性能处理、灵活性和降低成本的要求。
2021-04-30 07:21:43
。5.协处理器寄存器传送除了以上情况,在ARM和协处理器寄存器之间传送数据有时是有用的。再以使用浮点协处理器为例,FIX指令从协处理器寄存器取得浮点数据,将它转换为整数,并将整数传送到ARM寄存器中
2022-04-24 09:36:47
`微机原理--数学协处理器[hide][/hide]`
2017-04-30 21:19:48
协处理器进行gpio操作,执行完成后 ULP RISC-V 协处理器退出,等待下一个ULP唤醒周期。可当在主MCU程序中使能 esp_sleep_enable_ulp_wakeup() 函数后,每当
2023-02-09 06:52:26
指令操作的协处理器名.标准名为pn,n,为0~15 opcode1协处理器的特定操作码. 对于CP15寄存器来说,opcode1永远为0,不为0时,操作结果不可预知CRd 作为目标寄存器的协处理器
2017-01-12 21:10:30
,各种不同的组合代表了不同的指令类型,我们用到了预定义的custom-3指令扩展协处理器指令,因此指令的opcode为7’b1111011。
由于蜂鸟E203处理器核基于Custom指令进行协
2025-10-24 07:23:37
当今的设计工程师受到面积、功率和成本的约束,不能采用GHz级的计算机实现嵌入式设计。在嵌入式系统中,通常是由相对数量较少的算法决定最大的运算需求。使用设计自动化工具可以将这些算法快速转换到硬件协处理器中。然后,协处理器可以有效地连接到处理器,产生“GHz”级的性能。
2019-09-03 06:26:27
请问FPGA协处理器有哪些优势?
2021-05-08 08:29:13
请问E203 Core和 NICE协处理器的主频各是多少?
2023-08-12 08:06:09
我在ULP RISC-V协处理器的例程中,没有发现有对ADC的操作,请问RISC-V协处理器目前还不支持吗?使用的IDF版本为4.4.2。我想在ULP模式下,通过ADC来读取外部器件的数据。
2023-02-13 06:34:36
我在ULP RISC-V协处理器的例程中,没有发现有对ADC的操作,请问RISC-V协处理器目前还不支持吗?使用的IDF版本为4.4.2。我想在ULP模式下,通过ADC来读取外部器件的数据。
2023-03-06 06:33:44
使用扩展指令调用NICE协处理器完成预定操作,给出的优势通常为代替CPU处理数据,但其实使用片上总线挂一个外设,然后驱动外设完成操作也可以实现相同的功能,所以想问一下协处理器相比于外设实现还有没有其它方面的优势
2025-05-29 08:21:02
;
:\"=r\"(zero)
:\"r\"(addr));}
这里把addr赋给x0,但是x0作为零寄存器不会保存任何信息?
然后func3和func7定义为2,2的含义是?
.insn是否为实现访问协处理器的意思?
协处理器是否可以实现乘法加速?
2023-08-16 08:00:42
,有这样定义的“协处理器可以附属于 ARM 处理器。一个协处理器通过扩展指令集或提供配置寄存器来扩展内核处理功能。一个或多个协处理器可以通过协处理器接口与 ARM 内核相连。”如果定义“协处理器”为
2019-07-29 15:36:26
处理器。这些可配置协处理器可帮助设计人员解决传统ASIC仿真中存在的许多问题,并更省力、更快捷地实现更精确的设计。
2019-07-23 06:24:16
飞思卡尔C29x加密协处理器:网络数据安全的“门神”
2021-02-02 06:11:09
采用软硬件结合的方法,给出一种基于VLIW 的并行可配置椭圆曲线密码体制(ECC)专用指令协处理器架构。该协处理器采用点加、倍点并行调度算法,功能单元微结构采
2009-03-20 16:14:02 25
25 提出一种能同时在素数域和二进制有限域下支持任意曲线、任意域多项式的高速椭圆曲线密码体系(ECC)协处理器。该协处理器可以完成ECC 中的各种基本运算,根据指令调用基本运算
2009-03-24 09:43:3627 简述了协处理器的概念、任务、发展历程和现状,探讨了协处理器之所以引起人们重视和再重视的原因及其优势,简单介绍和展望了如何用FPGA 等类型协处理器构建高性能计算平台。
2010-01-02 11:23:5718 为性能加速的空间图像处理开发FPGA协处理器快速、精确的图像数据的板上分类是现代卫星图像处理的关键部分。对于地球科学和其它应用而言,空间智能有效载荷利用智能机器
2010-04-27 08:30:3115 利用串行RapidIO实现FPGA协处理
为了支持“三重播放”应用,人们对高速通信和超快速计算的需求日益增大,这向系统开发师
2010-03-25 14:48:251835 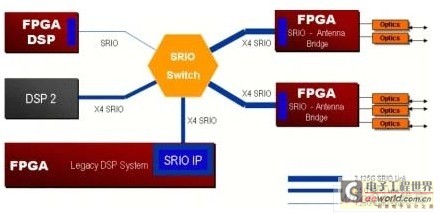
FPGA协处理技术介绍及进展
FPGA的架构使得许多算法得以实现,较之采用四核CPU或通用图形处理器(GPGPU),这些算法的持续性能更接近器件的峰值性能
2010-04-26 18:15:081122 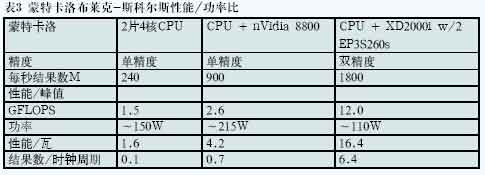
子系统划分选择方案
FPGA可与DSP处理器一起使用,作为独立的预处理器(有时是后处理器)器件,或者作为协
2010-08-11 10:03:47823 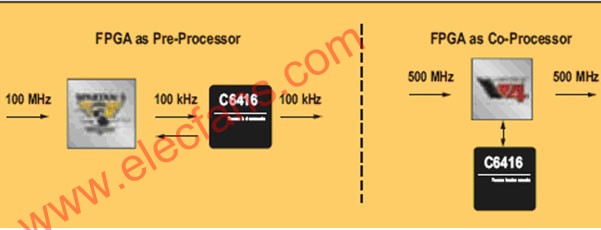
微机原理--数学协处理器
2016-12-12 22:07:220 多核处理器中的超越函数协处理器设计_黄小康
2017-01-07 18:39:172 一种面向流应用加速的可重构协处理器_曹姗
2017-01-07 22:14:030 协处理器(coprocessor),一种芯片,用于减轻系统微处理器的特定处理任务。协处理器,这是一种协助中央处理器完成其无法执行或执行效率、效果低下的处理工作而开发和应用的处理器。
2017-11-10 15:56:353161 当今的设计工程师受到面积、功率和成本的约束,不能采用GHz级的计算机实现嵌入式设计。在嵌入式系统中,通常是由相对数量较少的算法决定最大的运算需求。使用设计自动化工具可以将这些算法快速转换到硬件协处理器中。然后,协处理器可以有效地连接到处理器,产生“GHz”级的性能。
2018-07-22 11:54:001630 
集成了数据通信、本地服务和视频娱乐功能的高端汽车信息娱乐系统需要高性能的可编程处理技术支持,将FPGA协处理器整合进主流汽车信息通讯系统架构是最理想的解决方案。本文提出了汽车娱乐系统的要求,讨论了
2017-12-07 05:25:012229 协处理器,这是一种协助中央处理器完成其无法执行或执行效率、效果低下的处理工作而开发和应用的处理器。这种中央处理器无法执行的工作有很多,比如设备间的信号传输、接入设备的管理等;而执行效率、效果低下的有图形处理、声频处理等。
2018-01-09 13:43:4027647 
协处理器,一种芯片,用于减轻系统微处理器的特定处理任务。CPU的缩写,译为中央处理器。也做叫微处理器。指具有运算器和控制器功能的大规模集成电路。GPU图形处理芯片。是显示卡的“心脏”,也就相当于CPU在电脑中的作用
2018-01-09 14:46:0312086 协处理器共有68条不同的指令,汇编程序在遇到协处理器指令助记符时,都会将其转换成机器语言的ESC指令,ESC指令代表了协处理器的操作码。协处理器指令在执行过程中,需要访问内存单元时,CPU会为其形成内存地址。协处理器在指令执行期间内利用数据总线来传递数据。
2018-01-09 14:58:282451 
Observer协处理器通常在一个特定的事件(诸如Get或Put)之前或之后发生,相当于RDBMS中的触发器。Endpoint协处理器则类似于RDBMS中的存储过程,因为它可以让你在RegionServer上对数据执行自定义计算,而不是在客户端上执行计算。
2018-01-09 16:18:542125 
协处理器,这是一种协助中央处理器完成其无法执行或执行效率、效果低下的处理工作而开发和应用的处理器。
2018-07-15 09:27:004868 供电通道的实时电压和电流,通过计算获得协处理器实时功耗,并在实测数据的基础上分别分析Xeon Phi协处理器启动、空闲、线程和存储系统等的功耗特征。实验结果表明,该功耗模型为功耗优化提供了可信的基础数据,能够指导基于Xeon Phi处理器上的功耗优化。
2018-02-05 15:57:120 本文首先介绍了协处理器概念,其次介绍了协处理器内部结构与手机协处理器的作用,最后介绍了苹果的M8协处理器的作用。
2018-04-24 09:27:1423023 本文主要介绍了五款内置协处理器的手机。协处理器用于减轻系统微处理器的负担,执行特定处理任务。如,控制数字处理、处理图像或视频数据,或者感应和测量运动数据等。
2018-04-24 09:58:2917393 本文首先介绍了协处理器的相关概念,其次分析了骁龙835里是否有协处理器,最后阐述了骁龙835的性能参数。
2018-04-24 15:14:397034 本文首先介绍了ARM处理器特点与主要模式,其次介绍了arm的协处理器有几个,最后介绍了CP14和CP15系统控制协处理器。
2018-04-24 15:34:259690 使用英特尔®至强处理器和英特尔®至强融核™协处理器为您的Fortran应用程序供电
2018-10-30 06:32:004118 性能验证-ON-Intel的Xeon的处理器和Xeon的PHI-协处理器簇
2018-11-07 06:36:004721 使用英特尔®至强处理器和英特尔®至强融核™协处理器为您的Fortran应用程序供电
2018-11-07 06:36:063582 了解协处理的价值,Zynq-7000加速器一致性端口,使用协处理器加速器的方法以及协处理器设计实例的概述。
2018-11-30 06:15:004782 ARM7TDMI处理器指令集使您可以通过协处理器来实现特殊的附加指令。
2020-07-20 14:43:143545 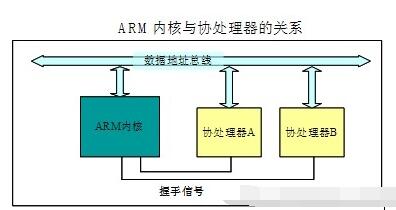
集成了数据通信,定位服务和视频娱乐的高端汽车信息娱乐系统需要高性能的可编程处理技术,其最佳实现方法是在主流汽车信息通信系统构架中集成FPGA协处理器。本文讲述汽车娱乐系统的需求,讨论主流系统构架,以及FPGA协处理器是如何集成到软硬件体系中,以满足高性能处理、灵活性和降低成本的要求。
2020-07-24 15:25:001036 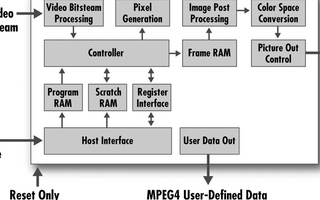
IP核心平台,可在FPGA和ASIC上的SoC环境中加速加密操作,其中包括了加速加密算法,增强篡改和入侵的检测,增强数据和密钥保护的安全性,增强内存访问和I/O。 SoC/FPGA市场正在迅速发展,通过将加密协处理器IP嵌入到相关产品中,使之具有更多明显的优势。与软件层相比,具有加密
2020-07-31 10:45:002805 本应用笔记介绍了 DSSHA1 可合成 SHA-1 协处理器,它可以在专用集成电路 (ASIC) 或现场可编程门阵列 (FPGA) 中实现,作为 DS2460 SHA-1 协处理器或基于微处理器的实现的替代方案.
2021-06-17 11:55:221965 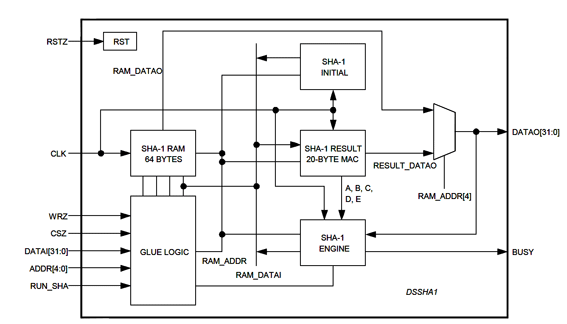
处理器中。然后,协处理器可以有效地连接到处理器,产生“GHz”级的性能。 本文主要研究了代码加速和代码转换到硬件协处理器的方法。我们还分析了通过一个涉及到基于辅助处理器单元(APU)的实际图像显示案例的基准数据均衡决策的过
2021-09-28 10:38:044756 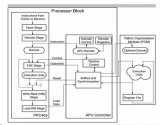
通过Z-Wave OTA协处理器
2021-12-09 14:36:083 协处理器是一个处理单元,该处理单元与一个主处理单元一起使用来承担通常由主处理单元执行的运算。通常,协处理器功能在硬件中实现以替代几种软件指令。通过减少多种代码指令为单一指令,以及在硬件中直接实现指令的方式,从而实现代码加速。
2022-10-27 12:41:271286 WOLA 滤波器组协处理器:介绍性概念和技术
2022-11-15 19:48:1911 的主机处理器。本应用笔记介绍了DSSHA1可合成SHA-1协处理器,该协处理器可在专用集成电路(ASIC)或现场可编程门阵列(FPGA)中实现,作为DS2460 SHA-1协处理器或基于微处理器的替代方案。
2023-02-20 13:44:531507 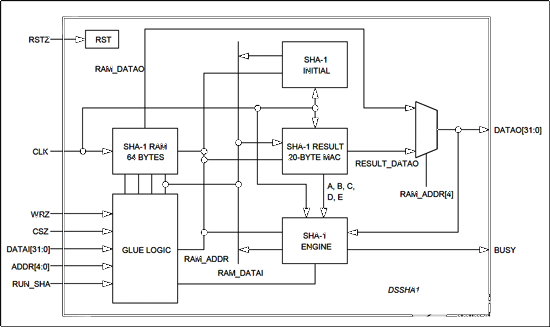
的主机处理器。本应用笔记介绍了DSSHA1可合成SHA-1协处理器,该协处理器可在专用集成电路(ASIC)或现场可编程门阵列(FPGA)中实现,作为DS2460 SHA-1协处理器或基于微处理器的替代方案。
2023-06-13 16:26:331573 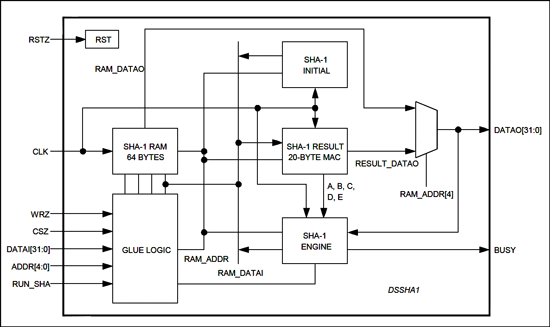
处理器中。然后,协处理器可以有效地连接到处理器,产生“GHz”级的性能。 本文主要研究了代码加速和代码转换到硬件协处理器的方法。我们还分析了通过一个涉及到基于辅助处理器单元(APU)的实际图像显示案例的基准数据均衡决策的过
2023-08-22 18:50:011460 1、 ARM C15 协处理器 在 ARM 嵌入式应用系统中, 很多系统控制由 ARM CP15 协处理器来完成的。CP15 协处理器包含编号 0-15 的 16 个 32 位的寄存器。例如,ARM
2024-02-20 14:28:031372 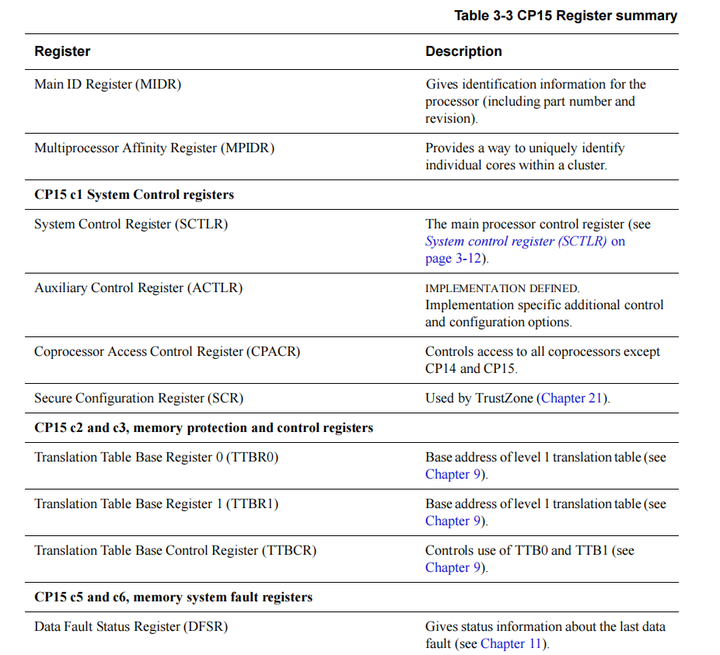
电子发烧友网站提供《使用TMS320C6416协处理器:Viterbi协处理器(VCP).pdf》资料免费下载
2024-10-21 09:36:000 电子发烧友网站提供《使用TMS320C6416协处理器:Turbo协处理器(TCP).pdf》资料免费下载
2024-10-23 10:16:190
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论