 电子发烧友App
电子发烧友App


利用FPGA虚拟化突破时空限制
在传统的FPGA开发模型中,使用者通常使用硬件描述语言(HDL)对应用场景进行建模,然后通过特定的FPGA开发工具将硬件模型映射到FPGA上,最终生成可以运行的FPGA映像。
这种开发模式的另外一个主要缺点是,FPGA只能由单一用户开发和使用,而与应用场景、FPGA的产品种类等无关。比如对于一个对资源需求不大、而且不需要连续运行的应用而言,大部分FPGA的硬件资源在大部分时间内都会闲置。很显然,这样很难在时空范围内对FPGA进行充分利用,见下图。

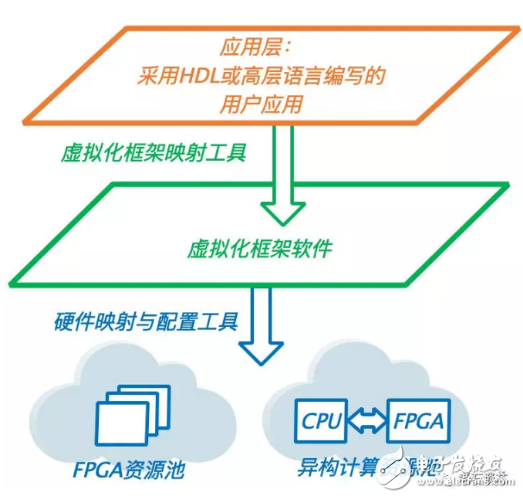
为了提高FPGA的开发效率、更好的利用FPGA的逻辑资源、方便FPGA的大规模部署和应用,需要将FPGA进行一定程度的逻辑抽象,使顶层用户不必太多关注于FPGA硬件逻辑的实现方式与细节。由此,FPGA虚拟化技术就应运而生。
可以说,FPGA虚拟化技术打破了时间和空间维度的限制,使用户能够轻松的在不同时间,对多个FPGA的各类资源进行充分的调度与使用,见上图。
FPGA虚拟化技术目前仍在发展初期,是工业界和学术界研究的热点。在本文中将介绍三种主流的FPGA虚拟化技术的实现方法:
FPGA Overlay
部分重构与虚拟化管理器
FPGA资源池与虚拟化框架
FPGA Overlay
Overlay本意是覆盖或叠加,它在网络技术里是一种构建虚拟逻辑网络的方法。它的实现方法通常是在物理网络架构的基础上,增加一层虚拟的网络平面,使得上层应用与底层物理网络相分离。这个虚拟的网络平面本质上可以通过隧道封装技术实现,在数据中心网络中常用的VxLAN就是Overlay的主流标准之一。
Overlay中增加虚拟层次的方法与本章开头给出的FPGA虚拟化方法非常类似。事实上,FPGA Overlay可以说是目前应用最广泛的FPGA虚拟化方法之一。和网络技术相似,FPGA Overlay是一层位于FPGA硬件层之上,并连接顶层应用的虚拟可编程架构,如下图所示。
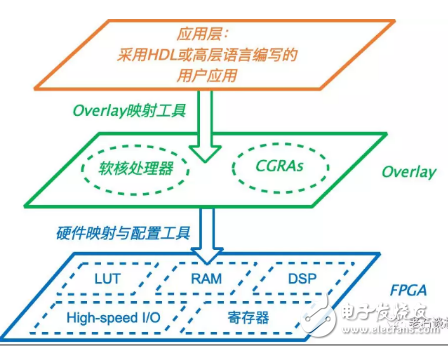
Overlay的具体实现形式有很多种,它既可以是工程中常用的软核通用处理器,也可以是一组支持更高级编程模型的可编程逻辑处理单元,称为CGRA(Coarse-Grained Reconfigurable Array),或者是一些实现特定功能的专用处理器,如Virtual Box公司开发的针对加速向量计算的向量处理器(Vector Processor)等等。
使用Overlay的主要目的是为上层用户提供一个他们更为熟悉的编程架构与接口,便于他们通过诸如C语言等高层语言对Overlay中的通用处理器等进行编程,而不需担心具体的硬件电路实现,由此实现了对FPGA底层硬件资源的抽象和虚拟化。
另外,由于Overlay层提供的逻辑处理单元或软核处理器通常与底层FPGA硬件无关,因此方便了上层设计在不同FPGA架构之间的移植。
使用Overlay的另外一个好处是可以在很大程度上缩短FPGA的编译时间。相比通常只有几分钟的软件编译时间,FPGA的编译需要经过逻辑综合、映射、布局布线等多项步骤,对于一个中等规模的FPGA设计而言,整个编译过程通常会长达几个小时之久。由于Overlay层的逻辑架构相对固定,因此可以由Overlay的提供者提前进行全部或部分编译。用户在使用时,就只需编译自己编写的逻辑部分即可,这样大大缩短了整体的开发时间,也方便对应用进行调试和修改。
Overlay技术与高层次综合(High-Level Synthesis,简称HLS)技术的主要区别在于,前者引入的Overlay层往往并不能完全隐藏底层的FPGA结构,由此可能带来额外的开发难度和成本。这通常体现在两个方面:
第一,Overlay层往往不能实现上层用户的全部逻辑。例如,使用软核处理器时,通常用它们进行数据通路和逻辑的控制,此时仍然需要专门的硬件工程师开发数据通路的部分。
第二,Overlay还没有一个业界统一的标准化开发模型。如果在Overlay中使用专门的处理器阵列或CGRA,由于目前并没有一个类似在HLS中采用的通用标准,那么就需要软件工程师提前学习和掌握所用的CGRA的编程模型,也需要有硬件工程师团队负责在FPGA中实现和优化Overlay层中的CRGA硬件电路。
部分可重构与虚拟化管理器
部分可重构(Partial Reconfiguration)是FPGA的主要特点之一,它体现了FPGA特有的灵活性。具体来说,部分可重构是指,可以将FPGA内部划分出一个或多个区域,并在FPGA运行过程中单独对这些区域进行编程和配置,以改变区域内电路的逻辑,但并不影响FPGA其他电路的正常运行。
部分可重构使得FPGA可以在时间和空间两个维度,由硬件直接进行多任务的切换,如下图所示。
利用部分可重构技术,可以将FPGA划分成若干个子区域,作为虚拟FPGA供单个或多个用户使用,同时保留一部分逻辑资源作为不可重配置区域,用来实现必要的基础架构,如内存管理与网络通信等。
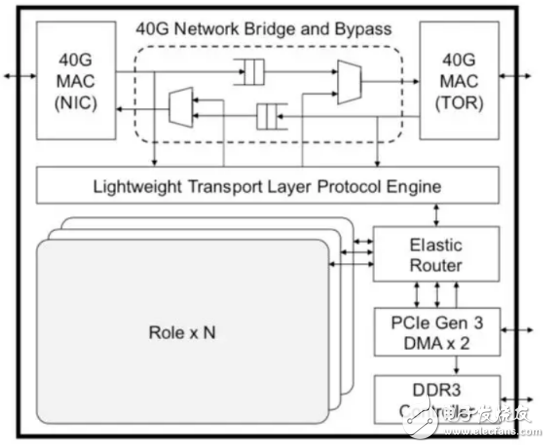
一个典型的例子是微软的Catapult项目。在他们2014年ISCA会议上发表的文章中介绍,每个FPGA都在逻辑上被划分成“Role”和“Shell”两部分,如下图所示。
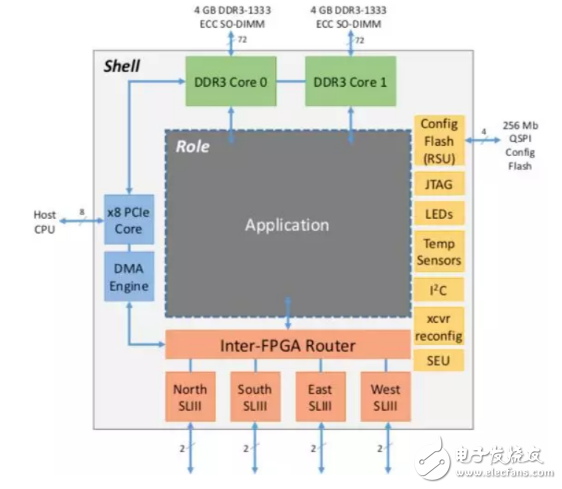
其中,Role为可重构的逻辑单元,可以根据不同用户应用进行编程和配置;Shell为不可重配置区域,包含了不同应用都可能需要的基础架构,比如DRAM控制器、高速串行收发器、负责与主机通信的PCIe模块与DMA、控制重构的Flash读写模块,以及其他各种I/O接口等等。
在这篇文章中,微软在其数据中心的1632台服务器中部署了Intel的Stratix V系列FPGA,在Role部分对微软必应(Bing)搜索引擎的文件排名运算进行了硬件加速,并达到了高达95%的吞吐量提升,同时功耗的增加不超过10%,总成本增加不超过30%。
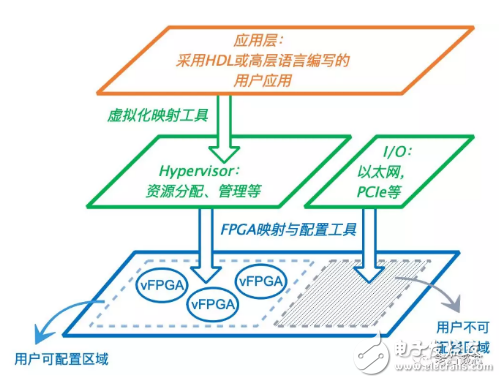
另外一个基于FPGA部分可重构技术进行FPGA虚拟化的例子,是IBM的cloudFPGA项目。在它2015年发表的文章中,FPGA被划分成三部分:管理层(Management Layer)、网络服务层(Network Service Layer)以及虚拟FPGA层(vFPGA),如下图所示。
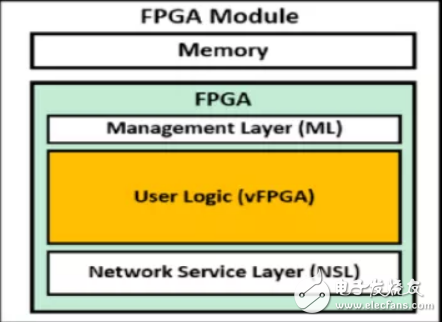
其中,vFPGA本质上就是一个或多个可以动态重构的FPGA区域,它们可以共同属于一个用户,或分属多个用户,运行着相同或不同的应用。
在一个vFPGA进行动态重构时,其他vFPGA的运行不会受到影响。管理层是不可被用户配置的区域,主要负责对这些vFPGA进行内存的分配和管理。vFPGA和管理层类似于传统虚拟化架构中虚拟机和Hypervisor的关系。网络服务层则主要负责控制多个vFPGA与数据中心网络的通信,并在FPGA硬件上实现了L2-L4层网络协议,供所有vFPGA使用。
为了通过部分重构技术进行FPGA虚拟化,通常都需要引入额外的管理层。与Hypervisor类似,管理层对虚拟后的FPGA进行各类资源的统一管理与调度,如Catapult项目中的Shell层,以及cloudFPGA项目中的Management层。
但是,管理层的引入势必会占用原本可以用于应用逻辑的可编程资源,同时对系统的整体性能带来负面影响。
另外,对FPGA强行划分多个可重构区域,也可能会严重影响系统性能。比如,一旦划分了可重构区域,就代表着其他应用逻辑不能使用该区域内的硬件资源,这样会严重影响编译时布局布线的灵活度,导致某些时序路径必须“绕道”,以避免这些可重构区域,从而造成过长的布线延时。另一方面,如果划分了过少的可重构区域,就可能会造成FPGA资源的空置和浪费。
因此,如何优化FPGA上可重构区域的划分数目,以及针对动态重构进行布局布线工具的优化设计,是当前学术界和工业界正在探索的问题。
FPGA资源池与虚拟化框架
为了实现多用户的支持,与其在单一FPGA芯片上使用动态重构技术划分多个可重构区域,也可以使用多个FPGA级联,使每个FPGA负责单个或少量用户,并通过一个整体的虚拟化框架完成系统的集成与资源调度。同样的,这个架构也可以支持单一个用户同时需求多个FPGA的应用场景。这种多租户的FPGA虚拟化架构通常需要软硬件两个层面的支持:
硬件层面,需要实现多FPGA互联,形成FPGA“资源池”,同时也要支持其他硬件结构,比如CPU、GPU,或者其他硬件加速器等。
软件层面,需要有一个虚拟化框架,对用户任务进行有效的FPGA部署。具体来说,就是对各类硬件资源进行分配调度,管理包括FPGA在内的各个加速器之间的通信和数据传输,控制FPGA的连接方式,以及对FPGA进行动态重构和配置等等。
上文提到的微软Catapult项目和IBM cloudFPGA项目都有各自的对多租户的支持。比如,微软在2016年MICRO会议上发表的论文提到,每个FPGA内都集成了一个Elastic Router,多个用户可配置模块(Role)可以通过Elastic Router提供的虚拟通道与外界进行网络通信,如下图所示。
在更高层面,Catapult提出了一种“硬件即服务(Hardware-as-a-Service)”的使用模型,如下图所示。
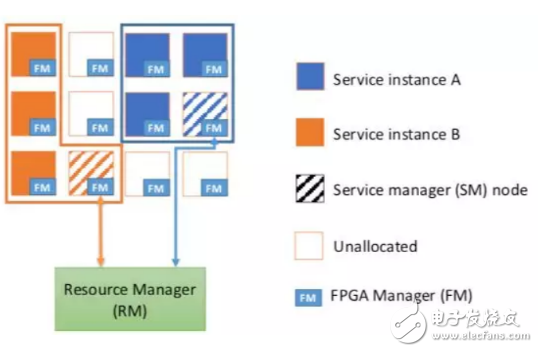
这个HaaS模型通过一个中心化的资源管理器(Resource Manager,RM),对数据中心里的FPGA资源进行统一管理和调度。每个FPGA资源池中,都有一个服务管理器(Service Manager,SM)通过API与RM进行通信。SM对整个资源池的FPGA进行管理,实现诸如FPGA负载均衡、互联管理、故障处理等功能。
在cloudFPGA项目中,FPGA与CPU完全解耦,直接作为网络设备接入数据中心网络,并成为池化的硬件加速资源。同时,IBM提出了一个基于OpenStack的虚拟化框架和加速服务,使得用户可以通过在FPGA中预先设定的management IP地址对FPGA资源池进行服务注册、任务分配、FPGA配置以及使用。
在池化FPGA和虚拟化框架领域其他的代表性工作还有来自英国Maxeler公司开发的基于FPGA的数据流引擎(Dataflow Engine),及其一系列开发环境与框架。在传统的基于CPU的计算架构中(见下图),CPU通过读取内存中的指令和数据进行相应的计算,当前指令的计算结果会写入内存,并在读取下一条指令和数据,直到程序运行结束。
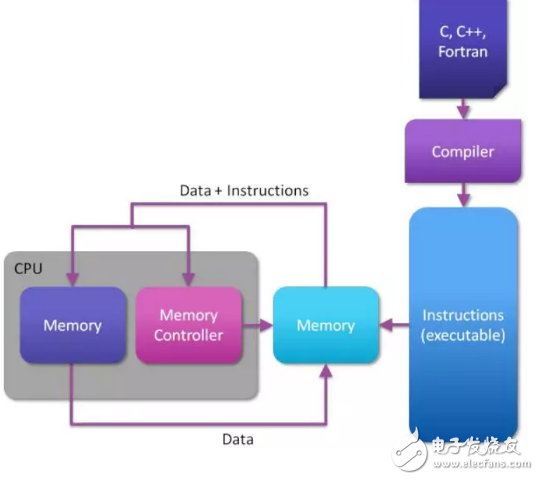
与之对应的,在基于数据流的架构中,只需在应用开始时从内存中读取数据,随后会在FPGA上进行数据流处理和计算,所有中间数据不会返回内存,直到计算结束。这样从根本上杜绝了访存的性能瓶颈。多个数据流引擎的计算节点可以互联,并与x86 CPU、网络单元、存储单元等共同组成完整的计算集群,如下图所示。
Maxeler还提供了一种类似于Java的编程语言,称为MaxJ,用来对数据流图进行描述和建模。然后通过对应的编译器MaxCompiler,将数据流图映射到底层的FPGA硬件平台,从而对上层用户虚拟化了底层电路逻辑的具体实现。
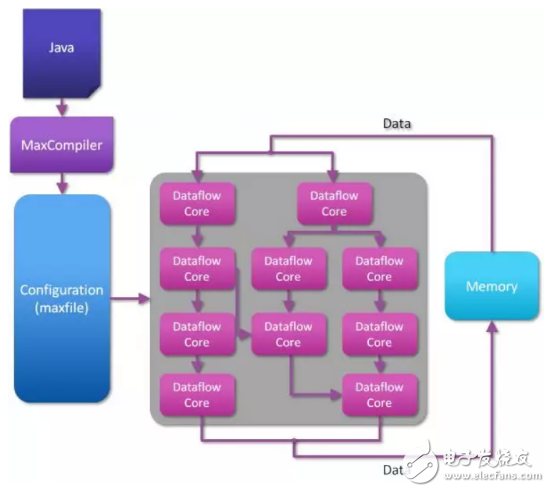
目前,这套数据流引擎架构已经被用在多个高性能计算的应用场景,比如蒙特卡洛仿真、金融风险计算、科学计算,以及一些新兴的应用场景,如卷积神经网络(CNN)的硬件加速等等。
在虚拟化框架协议方面的另一个主要工作是对MapReduce框架的FPGA支持。MapReduce是Google提出的针对大规模数据处理的并行计算框架,已被用于多种计算平台和架构,如多核CPU、Xeon Phi和GPU等等。通过MapReduce框架,上层用户只需要调用给定的软件库和API,而不需要知道底层的硬件结构。
MapReduce的核心即为map和reduce两个函数的实现,为了对MapReduce增加FPGA支持,可以首先设计map和reduce的FPGA硬件模块以及对应的编程接口,然后通过MapReduce框架调用,这样可以实现FPGA的分布式部署和配置。在这里,map和reduce的FPGA设计可以通过传统的硬件描述语言(HDL)完成,也可以通过高层语言,如OpenCL等,并借助高层次综合工具完成设计。
小结
与软件虚拟化类似,FPGA虚拟化技术抽象了具体的FPGA体系结构与硬件资源,使得用户能在更高的逻辑层级上利用FPGA进行应用的硬件加速。









 工商网监
工商网监
评论