 电子发烧友App
电子发烧友App


采用Spartan-6 FPGA加速纹理映射:这种要求严苛的图形流程曾经是定制ASIC内核的应用,而如今却成为低成本FPGA的天下。
作为一种以 FPGA 为构建基础,而非采用专业多媒体片上系统的手持设备,Milkymist One 无须计算机的辅助即能为聚会和音乐会提供视频特效。在 Milkymist One 中,Spartan-6 FPGA 基本可实现系统的整个数字化部分。另外,FPGA 的强大功能还足以处理纹理映射,这种高端图形功能代表了系统必须执行的最密集的数据处理任务。在传统上,纹理映射属于 ASIC 图形处理单元的领地,而在更早以前则是高端工作站的属地。
新应用领域的出色表现
无论是音乐节目主持人、综艺节目主持人还是其他活动的组织者都能在音乐会、节日以及俱乐部中使用Milymist One(见图1)营造出具有极强娱乐性的视频效果。将摄像头与视频投影仪连接在一起,按下电源按钮,数秒钟后拍摄的一切就变成栩栩如生、似幻似真的光色效果。将摄像头聚焦于舞台上的舞者,指向参加聚会的人群乃至玩具或其他对象,让观众为这种特效营造的效果如痴如醉。如果没有摄像系统的加入,Milymist One可以单纯地根据环境声响生成效果,特别适用于希望能以交钥匙解决方案实现简单视觉效果的乐队、俱乐部和聚会组织者。

该器件可支持来自多个源头的输入:MIDI键盘、USB计算机键盘、DMX桌面以及OpenSoundControl (OSC)客户端。用户甚至能够使用智能手机与视觉效果无线地互动,只需要将一个WiFi路由器连接至以太网端口即可。另一个选择是使用广受青睐的 Arduino 电路板,利用其大量的传感器界面来通过MIDI对Milymist One进行控制。
我们必须克服设计这种器件的重大挑战。我们的处理算法要求将相当数量的计算功能和存储器带宽用于处理高帧率和低时延的视频。另外,器件还必须与多种I/O协议实现接口相连。就本应用而言,包含CPU和图形加速功能的多媒体片上系统是许多工程师的首选。然后,他们会选用一些外部芯片来处理所有的接口。通过充分发挥赛灵思器件的功能和灵活性,我们能够在单个Spartan-6 FPGA中实现我们系统几乎全部的数字部分,从而既可以降低成本、精减芯片数量,又能够显著提升灵活性。
Milymist One的硬件
Milkymist One系统电路板的核心是一块赛灵思XC6SLX45(见图2)。该FPGA包含我们系统的所有数字逻辑,如软核CPU、存储器控制器、硬件加速器以及I/O外设等。

通过使用Spartan-6的“主BPI”模式,FPGA 可从NOR闪存芯片中读取配置数据。该闪存芯片随后使用“现场执行 (execute-in-place)”方案运行引导载入程序,即一边从NOR闪存获取处理器指令,一边对其进行执行。引导载入程序随后激活 SDRAM,并加载应用软件。该闪存芯片还负责存储这类应用软件,并保留使用YAFFS2的用户数据。YAFFS2 是一种可提供损耗均衡和日志功能的闪存优化型文件系统。
我们的应用软件能够从互联网下载 FPGA 数据流更新,并将它们写入闪存中。拜Spartan-6 FPGA所具有的多重载入 (MultiBoot)特性所赐,如果某个失效的更新会导致错误的数据流,则系统能够进行失效保护。
与FPGA直接连接的一对DDR SDRAM芯片可提供128MB的系统存储器。为有助于满足该接口严格的时序要求,Spartan-6 FPGA可为其提供双数据速率I/O寄存器、运行时间可编程延迟锁相环(带DCM)以及I/O延迟元件。
我们的器件可支持两个全速的USB主机端口。FPGA在此处再一次负责提供大部分硬件。Spartan 6可直接驱动模拟收发器芯片,以便轻松将LVCMOS 3.3V电平转换为能够完美符合USB标准的信号。串行接口引擎和主控制器逻辑采用FPGA架构实现。在原型设计阶段,甚至能够仅使用电阻和USB连接器与赛灵思ML401开发板的I/O扩展连接器相连,就能成功地将USB器件直接与FPGA相连。
在视频输出方面,FPGA可驱动一个3通道数模转换器,以生成VGA端口的RGB分量。Spartan-6中包含的DCM CLKGEN原语具有高度的灵活性,能够针对像素时钟将多种不同频率进行综合,从而使器件能够支持大量的视频模式。
此外,如何对由VGA端口输出的复合视频信号(CVBS)进行综合也在研究中。市面上已经有一些计算机图形卡,能够使用低成本的无源适配器将CVBC器件与VGA输出相连接。不过,在一套采用FPGA的系统上生成原色分量也是完全可行的。我们仅需要使用数字信号处理技术实现CVBS信号发生器,然后将生成的数据送给VGA数模转换器即可。这样,我们的器件就能轻松地与音乐以及现场表演场地仍然大量使用的传统视频投影仪和视频混合控制台相连接。
我们的设计可将Spartan 6与一对RS485收发器相连接,为DMX512提供支持。该协议可用于进行舞台上的灯光控制,能够让器件将周边的灯光与可视效果进行同步。在此,整个DMX512信号发送系统也是采用FPGA来实现的,而外部组件基本都是模拟组件。
此外,为了能与常用的控制器和传感器进行交互,我们的系统还支持MIDI。我们的设计实现与DMX512类似,只有模拟外部组件。我们还支持以太网(仅使用一颗PHY芯片)、音频(通过通用的AC97编解码器)以及PAL、SECAM和NTSC击JJ式视频输入。
这些外设大多数都能从FPGA获取时钟,而FPGA则使用其数字时钟管理器(DCM)从统一的50MHz时钟源将必要的频率进行综合。我们的电路板上只有两个额外的晶振,而且为进一步减少成本,正在考虑在将来的PCB版本中使用更多FPGA生成的时钟将其更换。
何谓纹理映射?
在所有Milkymist器件的FPGA必须执行的数据处理任务中,纹理映射是密集程度最高的。纹理映射是OpenGL及DirectX等已加速3D API的一种通用计算机图形运算,通常用于在屏幕上绘制带纹理的3D多边形。此外,其还能扭曲图像(见图3),而且我们也常将其用于此目的。

通用的图形处理单元在三角形上执行纹理映射,并且将更加复杂的多边形分解为一系列的三角形。输入到算法中的是待填充的三角形3个顶点的2D位置(也可能是原始3D坐标的投影),以及这3个顶点的2D纹理坐标。之后,该算法再逐像素绘制有纹理的三角形,方法是为每个像素线性地内插纹理坐标,然后复制这些坐标处的纹理像素(也称为纹理元素)。
通过简单地改变各顶点的位置或者每个顶点的纹理坐标的位置,纹理映射能够实现缩放、旋转或者比例尺变化等图像处理运算。但常见的问题是线性内插的结果并非整数,这就意味着应该在四个相邻的像素(见图4)中对纹理进行采样。在这种情况下,为了实现更理想的渲染,应读取四个像素,并将其色彩值进行平均(根据比例取不同的权重),这个流程被称为双线性滤波。我们的应用需要双线性滤波来实现理想的可视结果。

纹理映射,是一个计算强度大以及所需存储器非常密集的进程,这从性能的角度即决定了软件实现的不可行,在需要双线性滤波的时候尤为如此。
FPGA实现
预计用于读取帧缓冲器的存储器延迟将成为性能制约因素。我们没有采用高级预获取技术等复杂且资源密集的技术来降低存储延迟,而是简单地采用直接映射的像素元素高速缓存,不仅简单而且还能快速命中。另外,在设计纹理映射单元其余部分的时候,还需要注意让存储器读取延迟成为唯一的制约因素。
采用这种高速缓存可实现高达90%的命中率,以每个周期命中一次,每9个周期失的一次计算,存储器的平均存取时间为1.8个周期。采用80MHz的系统时钟,则此类高速缓存的每秒吞吐能力为44M像素,足以满足我们的应用所需。
为确保存储器存取时间是唯一的制约因素,我们在设计系统其余部分时,使之能够支持每个时钟周期大约一个输出像素的处理能力。与之相对应,算法的实现以占用空间为主(硬件组件很少或者根本没有基于时间的资源共享),但不要求复制资源密集的大型硬件单元。以空间为主的实现所用面积比时间共享的大,但更简单明了,需要的多路复用器数量越少,也能够更好地避免走线拥塞,从而更加简便地实现FPGA的时序收敛。为此,我们为纹理映射算法选择了深度流水线实现。

流水线的头几级用于从存储器中获取低带宽的顶点信息,然后使用某种Bresenham算法的变体计算内插纹理坐标与目标坐标。我们通过采用行为Verilog HDL来实现这些级,随后使用免费的XST综合器(1SE WebPACK设计套件的组成部分)进行处理以生成经优化的网表。地址生成器能够充分利用Spartan—6 FPGA的DSP48A1 Slice提供的硬件乘法器,高效率地计算与内插坐标对应的纹理帧缓冲器中的存储器地址。XST综合器能够根据HDL源代码中乘法运算符自动推导硬件乘法器,从而使其使用方法既简单又方便。
若要从存储器中获取纹理元素数据,则会变得更加复杂。在每个时钟周期,我们都需要从高速缓存中获取4个不同的像素。准备4个不同的高速缓存没有必要,因为双线性滤波器的不同通道通常使用来自同一高速缓存线路的数据。因此我们需要一个4端口SRAM,但这看似在FPGA中比较困难。
幸运的是,Spartan-6 FPGA中真正的双端口SRAM可提供理想的解决方案。我们通过使用两个原始的双端口SRAM复制数据,以适当的代价实现了4端口SRAM。在正常运行状态下(命中),每个端口为一个通道服务。在失的后重新填充高速缓存的时候,读取被禁用,而且可将两个端口(每个原始双端MSRAM各一个)用于将数据送给存储器。
图6是纹理元素高速缓存的简化方框图。在每个时钟周期中,纹理元素高速缓存均以流水线的方式处理来自每个通道的存储器地址。如果这些存储器地址命中高速缓存,并且“命中”信号始终保持高电平,那么流水线就会一直运行。
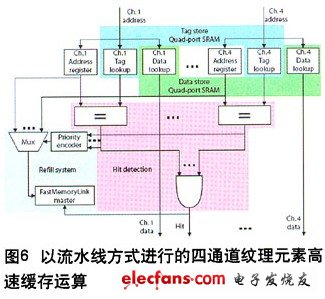
如果发生失的,“命中”信号会转为低电平(流水线停顿),随即由优先级编码器和多路复用器(mux)选择失的的地址之一(可以是1个,也可以是多个)。存储器总线主系统发出一个存储器交易事务以从系统存储器中检索数据,然后替换高速缓存线路的内容,并对标签进行重写。该地址现在变成命中高速缓存状态。如果没有其他地址未命中高速缓存,纹理元素高速缓存就已经成功地处理该4通道交易事务,而且“命中”信号会再次转为高电平,以进行到下一个周期的处理。否则,该流程将重复进行,直到所有的地址都命中高速缓存为止。
可以看到,在现代FPGA中,只要将用于存储的Block RAM的数量翻倍,同时辅以合理数量的控制逻辑,就能够实现理想的4端口高速缓存系统。
紧随纹理元素高速缓存之后,双线性滤波器将4个获取到的纹理元素的结果混合在一起。在此,我们的设计再次充分发挥了Spartan 6中DSP48A1Slice的性能,能够迅速计算出加权和。最后,可使用写入缓冲器将结果存储到基于SDRAM的系统存储器中。
一旦与我们的软核片上系统相集成后,我们的纹理映射单元就会仅使用低成本Spartan 6 FPGA的一小部分资源,却能提供每秒7000万像素的峰值填充速率以及每秒3700万像素的平均填充速率。与纯软件相比,即便是与使用运行在高性能(及高能耗)ASIC CPU的软件相比,性能也是一大飞跃,能够充分满足我们应用的要求。
高度灵活的单芯片
采用高性能可重配置 FPGA,可在高度灵活的单芯片中将过去只有ASIC才能处理的繁重图形处理功能与非常特定的I/O接口结合在一起。
Milkymist系统能够充分利用Spartan 6 FPGA的众多特性:I/O延迟组、DDR寄存器、大型真双端口Block RAM、DSP Slice、灵活的DCM CLKGEN组件,能够从NOR闪存进行配置以及多重引导功能。我们的完整设计仅使用了FPGA资源的大约一半,为将来的改良和特性预留了充裕的空间。这对成本像XC6SLX45这样低的芯片来说是非常了不起的。
对于未来的功能改进而言,整个FPGA设计是属于开源的,而且其许可和开发模式与Linux内核一样。设计人员能够使用免费的ISE WebPACK设计软件(同时提供Linux版和Windows版)重新构建完整的比特流。
最后需要指出的是,该器件的总功耗不足5W,从而不仅充分凸现了以单芯片FPGA为核心的解决方案的又一优势所在,同时还进一步推翻了所有FPGA系统都是高功耗系统的错误认识。










 工商网监
工商网监
评论