 电子发烧友App
电子发烧友App


摘要:基于IP可重用的设计方法,利用WISHBONE总线协议,把两个已成功开发出的具有自主知识产权的THUMP内核在一个芯片上,实现了片上多处理器FPGA。开发重点是实现基于片内WISHBONE总线的高速缓存一致性协议。
关键词:WISHBONE总线 片上多处理器 高缓一致性 SOC IP
清华大学嵌入式微处理器芯片设计为国家重点863项目,单芯片多处理器设计为项目的一个延伸。单芯片多处理器是提高处理器性能的有效途径,具有低耦合度、粗粒度并行性的主要特点。清华大学已成功开发出具有自主知识产权的MIPS 4Kc架构的32位微处理器--THUMPl07。该处理器具有内核性能高、面积小、功耗低的优点。使其经过裁减非常适合作为单芯片多处理器的内核。
本次单芯片多处理器的设计将两个Thumpl07内核集成在一个芯片上,两个内核处于完全对等地位,实现进程级的粗粒度并行。由于已经具有可以利用的内核,开发的重点就集中在高速缓存(Cache)一致性的实现上。芯片采用了基于内部总线写更新监听的高速缓存一致性协议,具有控制逻辑简单、可扩展性好的特点。内部总线采用适合片上系统通信、高可配置性的WISHBONE总线。使用该片上总线有效地解决了IP核可移植性、设计复用的问题[2l]。
1 WISHBONE总线
WISHBONE最先由Silicore公司提出,现在被移交给OpenCores组织维护。由于其开放性,现在已有不少用户群体。特别是一些免费的IP核,大多数都采用WISH-BONE标准。该总线结构具有公用的接口规范方便结构化设计,有效地解决了IP核可移植性、设计复用的问题。
WISHBON耳总线为半导体内核提供了可配置的互连方式,能够使各种内核互连起来形成片上系统;WISH-BONE总线具有很强的兼容性,提高了设计的可重用性;WISHBONE总线的接口独立于半导体技术,其互连方式既可以支持FPGA设备,也可以支持ASIC设备;WISHBONE总线协议简单、易懂。
WISHBONE总线是一种主/从接口架构的总线技术,如果具有有效的仲裁机制,总线系统可以支持多个ne/从接口;WISHBONE总线的可配置性主要体现在支持点到点、共享总线、数据流、交叉开关型的互连方式;WISHBONE总线协议既包含了一种容易使用、可靠性高、易测试、所有总线事务都可以在一个时钟周期内协同的同步传输协议,也包含了标准时钟周期的异步传输协议;WISHBONE总线的同步传输协议可以工作在一个大范围的时钟频率上。这样WISHBONE总线接口既可以与内核时钟周期同步,也可与不同的目标设备同步,时序都非常简单。此外,WISHBONE总线还具有如下特点:
·简单、紧凑的硬件逻辑接口,需要更少的逻辑门;
·支持流行的单字读/写、块读/写、读-修改-写的总线协议;
·可调整的总线和操作数位宽;
·支持大端(big endian)和小端(1ittle endian)两种数据表示方法;
·握手协议能够控制数据传输速率;
·支持单周期数据传输;
·从接口的部分地址解码;
·根据系统需要,用户可自定义增加接口信号;
·系统包含多个MASTER接口时,用户可以自定义总线仲裁方式与算法。
图2
2 实现方案
单芯片多处理器的每个内核都有分离的16KB指令高速缓存(1Cache)和16KB数据高速缓存(DCache);指令高速缓存和数据高速缓存都采用两路组相联的映射方式;每块都包含8个字;采用虚拟地址定位、物理地址比较的寻址方法;替换方式为LBU(最近最少使用替换)。
指令高速缓存不涉及一致性问题,不多做说明。数据高速缓存采用基于监听总线的写更新一致性协议Dragonl[3]
协议状态说明见表1。
表1 协议状态
状 态 说 明
干净独占(E) 只有一个缓存有这一存储块的拷贝,并且还没有被修改(主存状态也有效)。
干净修改(SC) 潜在的两个或多个缓冲有这一存储块,主存不一定是最新的。
共享已修改(SM) 潜在的两个或多个缓冲有这一存储块,主存不是最新的。该块在被替换时,要更新主存(写回)。一个存储块在一定时间内只能在一个缓冲内共享已修改状态。
独点已修改(M) 存储块的内容已经被修改,并且只在该存储块里,发生替换需要更新主存的内容。
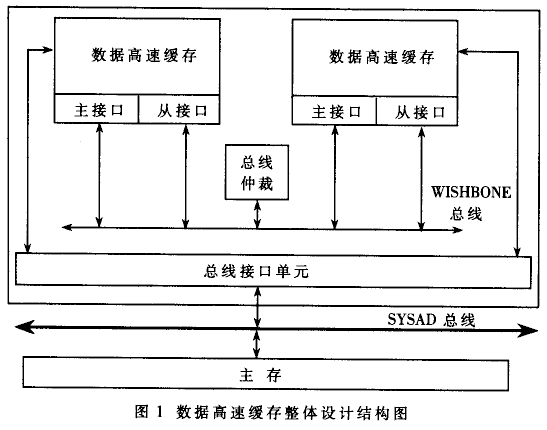
确定一致性协议后,单芯片多处理器的数据高速缓存单元整体设计见图1。
片内总线采用WISHBONE总线共享型连接,每个内核的数据高速缓存的控制单元都包含WISHBONE总线的一个主接口(MASTER)和一个从接口(SLAVE);数据总线为32位;地址总线为33位,其中最高位是两个从接口的选择位;片内总线采用预先同步传输协议;仲裁方式为轮换型;片外总线接口与广泛应用的工业标准SYSAD系统总线兼容。
在UNCAHCE空间发生的读写操作,直接访问外部总线,与主存通信;在CACHE空间发生的读写操作,过程如下所述:
读缺失:当一个内核的数据高速缓存发生读缺失,由本地主接口通过片内总线向远端数据高速缓存发出读请求,远端从接口通过片内总线应答请求。如果应答有该单元数据,就由远端数据高速缓存调来一个数据块(8个字);如果没有,本地主接口结束片内总线周期,转而访问外部总线,由主存调人数据。
写缺失:内核发生写缺失时,前半部分的操作与读缺失完全一致;只是如果缺失单元是从远端数据高速缓存调来的,由于采用基于写更新的Dragon协议,所以在完成片内总线块传输事务后还要产生一个单字写总线事务,更新远端数据高速缓存单元。
读命中:不会产生任何总线事务。
写命中:如果该单元的原来状态是SC或SM,基于写更新协议,由本地主接口通过片内总线向远端数据高速缓存发出写请求,远端从接口通过片内总线应答请求。如果应答有该单元数据,则通过一个单字写总线事务更新远端数据高速缓存单元;如果没有,结束片内总线周期。
替换:实现写回协议,只有被替换出的单元状态为SM或M状态,才通过外部总线更新主存,其他情况抛弃即可。
注意:完成上述操作后要根据DRAGON协议,更新本地和远端DCahe单元的相关状态。
3 总线事务时序分析
由前部分的说明发现在内部总线上可以产生三种类型的总线事务:读缺失时,块传输总线事务;SM或SC状态写命中时,发生单宇写总线事务;写缺失时,先是一个块传输总线事务而后在本地写操作完成后,一个单字写总线事务更新远端的数据高速缓存单元。以下是块传输和单字写总线周期具体的时序分析,下文提到的具体信号其意义可以查阅参考文献[1]。
块传输时序:主接口通过声明CYC_O申请总线的使用权,同时也给出STB_O、CTI_0(010)、WE_O(低电平)和ADR_O;经过若干时钟周期等待后,如果远端从接口给出ACK_I信号,同时给出的SHARE_I信号为低电平(说明远端数据高速缓存没有所需要的数据块,.SHARE_I为自定义的信号),这时主接口忽略DAT-I信号,下一个时钟周期撤销CYC_O信号,结束片内总线周期;如果给出AClI信号的同时,SHARE_I信号为高电平(说明远端数据高速缓存有所需要的数据块),接收DAT-I上的数据;而后7个时钟周期内,每个时钟周期ADR_O数据加4,DAII上的数据根据地址相应地变化,在第7个数据传输的时钟周期CTI_O变为111,告诉远端从接口这是最后一个传输时钟周期,下一个时钟周期:降完成这个总线事务;最后一个时钟周期主接口撤销CYC_O信号,结束片内总线周期。
内块传输时序见图2。
单字写总线周期:主接口通过声明CYC_O申请总线的使用权,同时也给出STB_O、CTI_O(111)、WE_O(高电子)、ADlO和DAT-0;经过若干时钟周期等待后,如果远端从接口给出ACK_I信号, 同时给出的SHARE信号为低电子(说明远端数据高速缓存没有所需要的数_I据块),主接口下一个时钟周期撤销CYC_O信号,结束片内总线周期;如果给出ACK_I信号的同时,SHARK-I信号为高电子(说明远端数据高速缓存有所需要的数据块),说明从接口已经用DAT-O上的数据更新了相应的数据单元,下一个时钟周期撤销CYC_O信号,结束片内总线周期。
单字写时序见图3。
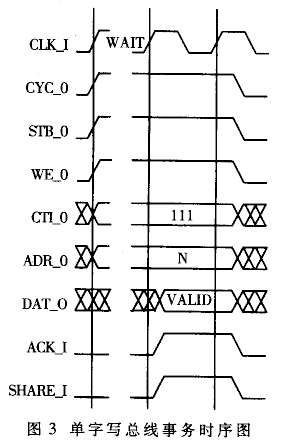
块传输总线事务时序图2,单字写总线事务时序图3中WAIT表示主接口等待总线仲裁和从接口的应答,需若干时钟周期,最快的情况下只要一个时钟周期。 总线仲裁:如果两个数据高速缓存的主接口同时请求,由仲裁单元决定哪个主接口可以使用片内总线,仲裁的优先级算法是轮换法。数据高速缓存的主接口,在声明CYC_O申请总线后,如果AClI一直是低电平无效,但同时该数据高速缓存从接口的CYC_I信号有效,说明数据高速缓存主接口没有得到总线使用权,主接口撤销CYC_O信号,该数据高速缓存响应从接口的操作,操作完成后,主接口再次声明CYC_O信号请求总线;相反,如果数据高速缓存主接口的ACK_I信号高电平有效,说明得到了总线使用权,可以使用总线。
综上所述,片内总线采用WISHBONE总线地址增量的传输方式,与内核时钟同步,最快可以在9个时钟周期从另一个数据高速缓存调来一个块(8个宇)的内容,可在2个时钟周期更新远端数据高速缓存的一个相关单元;数据高速缓存实现写回、写更新机制,减少了向外部总线写操作的频度。该结构具有可扩展性,只要把片内WISHBONE·总线的地址线的位数扩展(用于选择多个从接口)就可以把多个内核集成在该芯片上,协议无需变化。该种体系结构运行两个耦合度很低的程序,性能最好。
该方案利用WISHBONE总线,基于监听总线的写更新一致性协议,把两个IP核集成在一块芯片上,实现了单芯片多处理器结构的FPGA。该体系结构采用开放的片上总线标准,具有公用的主从接口规范,实现了IP核可移植性,具有设计可复用的优点。










 工商网监
工商网监
评论