 电子发烧友App
电子发烧友App


据麦姆斯咨询报道,随着自动驾驶汽车市场的成熟,传感器和感知工程师评估系统效率、可靠性和性能等工作变得越来越复杂。许多行业领导者已经认识到,用于激光雷达(LiDAR)数据收集的常规指标,例如帧率(frame rate)、全帧分辨率(full frame resolution)和探测距离(detection range)已不再能充分衡量激光雷达解决自动驾驶实际用例的有效性。
第一代激光雷达被动地搜索场景并使用背景图案来探测物体,而背景图案在时间(无法通过快速重新访问进行增强)和空间(无法在诸如路面或行人之类的高度感兴趣区域额外增加分辨率)两个维度都是固定的。新型先进固态激光雷达可实现智能信息捕获,从而将其功能从“被动搜索”或目标探测扩展到“主动搜索”,在许多情况下,还可以实时获取目标的分类属性。
由于早期的激光雷达使用固定光栅扫描,因此行业采用的是非常简单的性能指标,无法表达出自动驾驶对所需传感器的细微要求差别。因此,以AEye在内的许多激光雷达行业领导厂商正提议采用三项新指标来扩展对激光雷达性能的评估。具体而言:对“帧率(Rate)”指标进行扩展,以包括“目标重访速度”;对“分辨率(Resolution)”指标进行扩展,以获得“瞬时分辨率”;对“探测距离(Range)”指标进行扩展,以反映更重要的“目标分类距离”。
我们建议将这些新指标与摄像头、雷达和被动激光雷达性能的现有指标结合使用。这些扩展的指标可衡量传感器智能增强感知能力,并对传感器系统在现实环境中改善自动驾驶汽车安全性和性能进行更全面的评估。
自动驾驶行业利用了经先进机器视觉研究验证后的架构,并将其应用于特定激光雷达产品。事实证明,相比于目标识别,“搜索、采集(或分类)和采取行动”的架构具有通用性和指导性。
搜索是探测到所有目标而不会丢失任何目标的能力。
采集被定义为能够进行搜索探测并增强对目标属性的理解,以加速分类并确定意图的能力(可通过对目标类型进行分类或计算来实现)。
采取行动指由车辆感知系统或域控制器经过训练或建议对传感器定义的响应。响应大致可分为四类:(1)继续对新目标进行扫描,不需要增强信息;(2)对目标继续扫描并进一步询问,收集有关目标属性的更多信息以进行分类;(3)对目标继续扫描并跟踪分类为非威胁性目标;(4)对目标继续扫描并命令控制系统采取规避措施。
此架构的最终目标就是车辆完全安全运行所要求的性能指标和系统有效性。但是,由于目前大多数激光雷达系统都是被动的,只能进行基本搜索。因此,用于评估这些系统性能的常规指标与基本的目标探测功能有关:帧率(Rate)、分辨率(Resolution)和探测距离(Range)。如果以安全性为最终目标,则“搜索”需要更加智能,“采集(或分类)”操作必须更快速准确地进行,以便传感器或车辆确定如何立即“采取行动”。
汽车激光雷达系统的制造商经常被问及产品帧率,以及技术是否有能力在一定距离内(通常为230米)探测到反射率为10%的物体。我们认为这些是必须的基本指标,但无法证明其捕捉关键细节(例如目标尺寸,被探测和识别所需的速度,或收集信息的成本),因而无法满足要求。我们认为,在评估汽车激光雷达系统时,采用更全面的方法将对该行业产生积极影响。我们必须从整体审视与感知系统相关的指标,而不是将其作为单一的传感器,然后问自己:“哪些信息将使感知系统做出更好、更快的决策?”
传统指标一:10Hz~20Hz的帧率
扩展:目标重访速度(Object Revisit Rate),对某一点或多点两次拍摄的时间差
仅定义单点探测距离是不够的,因为单个询问点(单次拍摄)很难提供足够的置信度——仅具有参考价值。因此,被动激光雷达系统需要对同一位置进行多次询问/探测,或者在同一目标上进行多次询问/探测以验证目标或场景。在探测系统中,探测目标所需的时间取决于许多变量,例如距离、询问模式、分辨率、反射率、物体的形状和扫描速率。
传统度量标准缺少的一个关键因素是对时间更精细的定义。因此,我们建议将目标重新访问速度作为汽车激光雷达的一项新指标,诸如AEye推出的高灵敏度激光雷达iDAR能够重新访问同一帧内的目标。对目标的第一次测量与第二次测量之间的时间差非常关键,因为较短的目标重访时间可以缩短关联场景中多个运动目标先进算法的处理时间。当样本的时间差过长时,关联/相关多个运动目标的最佳算法可能会出现混乱。冗长的合并处理时间或延迟是该行业面临的主要问题。
高灵敏度iDAR平台通过允许在一帧内进行智能拍摄调度来加快重访速度。iDAR不仅可以在传统架构内多次询问位置或目标,而且还可以维持背景搜索模式,同时覆盖其它智能拍摄结果。例如,iDAR传感器可以快速连续(30微秒)安排对目标进行两次重复拍摄。这些多重询问可以与用户(人类或计算机)的需求进行情景集成,从而提高置信度,减少延时,增加探测距离。
这些额外的询问与数据相关。例如,出现低置信度时重新探测目标,并且期望快速验证或拒绝,启动次级数据和测量。在图1中,传统被动激光雷达典型帧率为10Hz。对于传统被动激光雷达,这就是目标的重访速度。现在,借助AEye的iDAR技术,目标重访速度与帧率有所不同,并且对关键点/目标的重访时间差可以低至数十微秒,轻松实现比传统被动激光雷达快100倍到1000倍的性能。
这意味着使用动态对象重新访问功能的感知工程团队可以创建一种感知系统,该系统至少比传统被动激光雷达快一个数量级,且不会破坏背景扫描模式。我们认为,此功能对于实现Level 4和Level 5自动驾驶汽车来讲是非常重要的,因为车辆将需要处理复杂的边缘计算情况,例如识别朝着车辆前灯迎面驶来的行人或横穿车辆行驶路径的平板式半挂车。
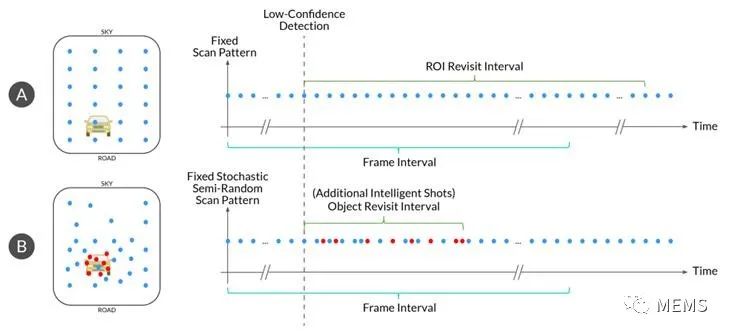
图1:先进的高灵敏度激光雷达利用智能扫描模式来实现目标重访间隔(Object Revisit Interval),如图(B)所示AEye iDAR的随机扫描模式,与典型固定模式激光雷达(A)的“重访间隔”进行比较。可以看出,iDAR(B)能够在一帧内对车辆进行八次目标重访/探测,而典型的固定模式激光雷达(A)只能实现一次。
因此,在“搜索、采集和采取行动”的架构中,加快目标重访速度可以加快采集速度,因为这可以识别并自动重访目标,从而在场景中描绘出更完整的画面。最终允许传感器进行目标属性分类,并高效地询问和跟踪潜在威胁。
实际用例1:正面探测
当您驾驶车辆时,眼前的世界会在十分之一秒之内发生巨大变化。实际上,两辆车以每小时100公里速度相向而行时,0.1秒后距离就减少5.5米。通过提高目标重访速度,由于在两次拍摄之间目标明显移动的可能性降低,增加了下一次拍摄到相同目标的可能性。这有助于用户解决“目标对应问题”,确定动态场景的一个快照的哪些部分对应于同一场景另一快照的哪些部分。做到这一点的同时,使用户能够快速建立置信度更高的统计数据,并生成下游处理器可能需要的聚合信息,例如目标的速度和加速度。有选择地提高目标重访速度,同时降低对稀疏区域(如天空)的重访率,显著帮助实现更高层次的推测算法,从而使感知和路径规划系统能够更快地确定最佳的自动决策。
实际用例2:横向探测
横向进入场景的车辆最难追踪。即使是多普勒雷达,在这种情况下也很难应对。但是,当探测已成为采集过程的一部分时,有选择地分配拍摄次数以提取速度和加速度,则会大大减少每帧所需的拍摄次数。iDAR增加二次探测,对每个目标探测建立速度估算,总拍摄次数仅增加1%。而使用固定扫描系统获得速度,所需的拍摄次数增加一倍。速度和特征拍摄消除了歧义,允许更有效地利用资源,让自动驾驶更安全。
传统指标二:固定视场的固定分辨率
扩展:瞬时分辨率(Instantaneous Resolution),增加激光雷达同一帧内关键区域的分辨率
传统的分辨率,假定以恒定的模式和均匀的功率对视场内目标进行扫描。这对于收集能力较差、智能级别较低的被动传感器来说,非常有意义。另外,传统的分辨率是假设场景内的显著信息在空间和时间上是统一的,我们知道这并不正确,这对于行驶中的车辆来讲更不正确。但是,正是由于这些假设,传统激光雷达系统会不加选择地从车辆周围收集千兆字节的数据,并将这些输入发送到CPU进行抽取和解释。该数据中约70%~90%是无用或冗余,需要被过滤。此外,传统激光雷达系统对任何区域都实施相同级别的功率,相当于对车辆的行进路径的目标提供与对天空相同的功率。这样的处理效率极低。
作为人类,我们不会平均地“吸收”周围的一切。我们的视觉皮层会过滤无关信息,例如飞过头顶的飞机,同时(而不是连续地)将我们的眼睛聚焦在特定的兴趣点上。集中在一个兴趣点,将其它次要目标放用余光察觉。这就是所谓的“Foveation视觉模型”,目标被分配了“更高浓度”的视锥细胞,因此可以更加生动地看到它。
iDAR应用仿生技术来扩展人类视觉皮层的人工感知能力。人眼通常只集中看一个区域,而iDAR可以同时(以多种方式)集中在多个区域,同时还可以进行背景扫描以确保不会遗漏任何新进入物体。我们将此功能描述为感兴趣区域(ROI)。此外,由于人类完全依赖于来自太阳、月亮或人造照明发出的光,因此人类的“Foveation视觉模型”是“只能接收”的,即是被动的。相比之下,iDAR集中在发射端(激光选择“绘画”的区域)和接收端(处理被选择的关注位置/时间)两个方面。
图2是一个示例。图2显示了两种系统,即系统A和系统B。这两种系统在同一场景中具有相似数量的拍摄次数(左)。系统A代表传统激光雷达的典型扫描模式,固定的扫描模式会产生固定的帧率,而没有ROI的概念。系统B显示了调整后的灵敏扫描模式。系统B中的拍摄次数在正方形内的ROI(小方框)之内和周围更加密集。此外,背景扫描继续搜索以确保不会遗漏任何新目标,同时对固定区域增加额外的分辨率以帮助采集。从本质上讲,这是利用智能来优化功率和拍摄次数。
查看系统A和B相关图(右),我们发现系统B(灵敏扫描模式)可以在比系统A(固定扫描模式)短得多的时间间隔内重新访问ROI。系统B不仅可以完成一次ROI重访间隔,还能在单帧内实现多个ROI。而系统A无法重新访问。iDAR实现传统激光雷达无法完成的事情:实现动态感知,使系统能够以前所未有的速度专注于特定ROI并收集更全面的数据。
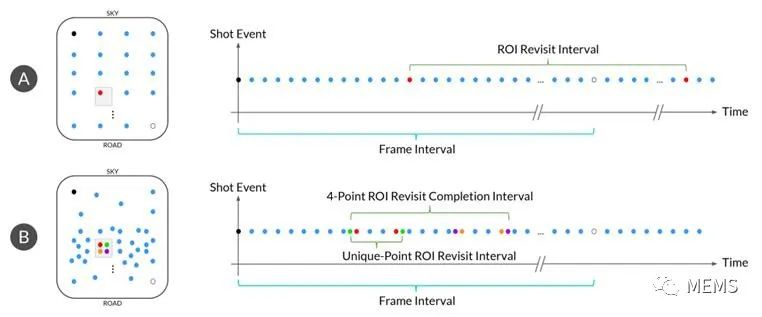
图2:与传统扫描模式(A)相比,iDAR(B)的感兴趣区域(ROI)和Foveation视觉模型展示。
在“搜索、采集和采取行动”架构中,瞬时分辨率使iDAR系统可以搜索整个场景并获取多个目标,并捕获有关它们的更多信息。iDAR还允许在一个场景中创建多个同时的ROI,从而使系统能够关注并收集特定目标更全面的数据,从而更完整地询问并更有效地跟踪目标。
实际用例:目标询问
识别出感兴趣目标后,iDAR可以实现Foveation视觉模型,扫描、收集更多有用信息并采取额外的分类属性。例如,假设车辆在行进路径中遇到了一位正在穿过人行横道的行人。由于iDAR可以动态改变ROI内的时间和空间采样密度(因此我们称之为“瞬时分辨率”),该系统可以更多地关注到人行横道,而较少地关注无关信息,如路边停放的车辆。ROI使iDAR可以快速、有效和准确地识别有关人行横道的关键信息,例如速度和方向。iDAR系统向域控制器提供最有用、最可执行的数据,以确定最及时的行动方案。
有三种利用瞬时分辨率来实现的用例:
固定ROI:如今,被动系统只能分配更多的水平扫描线,这是一种非常简单的Foveation视觉技术,受其固定分辨率限制。具有瞬时分辨率的第二代智能激光雷达(如iDAR),可帮助整车厂或Tier 1厂商利用先进仿真程序来测试数百个(甚至数千个)拍摄模式(无论速度、功率和其他限制条件如何变化)以识别将固定ROI与更高瞬时分辨率集成在一起的最佳模式,获得其所需的结果。
例如,固定ROI可用于优化不同倾斜度前窗玻璃后面的拍摄模式。此外,固定ROI还可以用于相对复杂的城市环境,威胁更可能来自路边,例如车门打开,行人和其它交通工具横穿马路或车辆的前进路径。增加覆盖道路两侧和车辆前方路面固定区域的分辨率来定义ROI(请参考图3B)。这样可以为ROI提供出色的垂直分辨率和水平分辨率。模式一旦获得批准,就可以固定以确保功能安全。
触发式ROI:触发式ROI需要软件可定义的系统,该系统可进行编程以接受触发。感知软件团队可以确定,当满足某些条件时,将在现有扫描模式中生成ROI。例如,地图或导航系统可能会发出信号通知您正在接近十字路口,在场景的关键区域上产生目标ROI更多细节(请参考图3C)。
动态ROI:动态ROI需要最高智能水平,并利用战斗机自动瞄准系统(ATS)的相同技术和方法,随时间推移连续询问关注目标。当这些目标移近或离开时,ROI的大小和密度会发生变化。例如,可以探测到场景中的行人、自行车骑行者、车辆或其它物体,并自动应用动态ROI来跟踪其运动(请参考图3D)。
图3:图A展示了车辆接近十字路口时的场景。图B展示了固定ROI覆盖道路两侧和紧邻车辆前方区域的情况。图C展示了触发式ROI:导航系统在车辆接近十字路口时触发特定的ROI。图D展示了动态ROI:当多个目标在场景中移动时,它们会被探测到并被跟踪。
传统指标三:目标探测距离
扩展:目标分类距离(object classification range),拥有足够的数据来以实现对目标分类的距离
在评估汽车激光雷达系统对周围空间的感知水平时,制造商通常认为确定其探测距离很有价值。为了优化安全性,车载计算机系统应尽可能早地探测到障碍物。从理论上讲,速度决定了控制系统是否可以计划和执行及时的规避措施。AEye认为“探测距离”这个指标是必要的,但还不够。感知系统应该能对目标进行分类并将准确及时的信息传递给控制系统。
最重要的不仅是有多快能探测到目标,而且有多快能识别出目标并进行分类,从而做出威胁级别决策并计算出适当的响应。单点探测无法与噪声进行区分。因此,我们使用行业内对探测的通用定义,即每帧和/或多帧之间的相邻拍摄的持久性。我们要求每帧(在相同探测距离内有五个点)和/或从多帧之间(连续五帧的一个相关点)对一个目标进行五次探测,以验证探测到了有效的对象。在20Hz时,定义一次简单的探测需要0.25秒。
当前,分类通常在感知堆栈中进行,对目标进行标记,并最终对其进行更清晰的识别。此数据被用于预测行为模式或轨迹。传感器提供的分类属性越多,感知系统确认和分类的速度就越快。AEye认为,评估这种关键汽车激光雷达能力的更好方法是影响“目标分类距离”的能力。该指标减少了早期感知堆栈的未知数,如与噪声抑制相关的等待时间,从而确定了重要信息。
作为相对较新的领域,尚未确定汽车激光雷达分类所需数据量的定义。因此,我们建议使用视频分类的感知标准作为参考定义。根据视频标准,采用的分类是基于对象的3 x 3像素网格。在此定义下,可以通过汽车激光雷达系统以多快的速度生成高质量、高分辨率的3 x 3点云来进行评估,使感知堆栈能够理解场景中的物体和人物。
对于传统激光雷达系统而言,生成3 x 3点云是一项艰巨的任务。尽管许多系统都宣称可以在一秒钟内显示100万点甚至更多的点云,但这些图像均匀性不佳。对于分类而言,这些固定采样模式可能很难完成,因为域控制器必须每秒处理100万个点,这在许多情况下与所涉及目标的关键采样所需的分辨率无法平衡。如此广泛的点样本意味着它需要执行其它解释,从而占用大量CPU资源。
图4:在探测物周围排列密集的3 x 3网格可以收集更多有用的数据,并大大加快分类速度。在左侧的“扫描1”(scan 1)中,对车辆进行了一次探测。无需等待下一帧对该车辆进行重新采样(如传统激光雷达的典型操作),而是快速形成动态ROI,如“扫描2”(scan 2)所示。在初始单次探测之后和完成下一次扫描之前,将立即执行。
回到“搜索、采集和采取行动”的架构中,一旦我们获得了目标并确定其是有效的潜在威胁,我们就可以分配更多拍摄进行分类,并在需要时采取行动。另外,如果我们确定目标不是立即威胁,我们可以更全面地询问该目标以获取其它分类数据,或者每次扫描拍摄几次就可以对其进行简单跟踪。
实际用例:无保护左转弯
对不同目标需要不同响应。在具有挑战性的驾驶场景尤其如此,例如在高速行驶过程中的无保护左转弯。想象一下,在四车道道路上的自动驾驶汽车,其时速限制为100公里/小时,在两条行车道上进行无保护左转弯。在迎面而来的交通中,一条车道有摩托车,另一条车道有小轿车。在这种情况下,目标分类距离至关重要,在足够的距离内将一个目标分类为摩托车,高速行驶的自动驾驶汽车会更加谨慎,这是由于摩托车行驶速度较快且路径不可预测。
实际用例:校车(特殊目标)
在特定距离对目标进行分类的意义比即时响应更为重要。一个很好的例子就是遇到一辆满员的校车。该目标被归类为校车的速度越快,自动驾驶车辆启动适当协议的速度就越快——减慢车速并部署其它工具,如在校车周围区域增加瞬时分辨率(触发式ROI),以立即捕获儿童朝车道移动的任何动作。此功能可用于警车、救护车、消防车或任何需要自动驾驶车辆改变询问场景、改变速度或路径的特殊车辆。
结论
在本文中,我们讨论了减少同一帧内对目标探测时间差至关重要的原因。由于需要捕获同一点/目标的多次探测才能完全理解该目标或场景,因此对于汽车激光雷达来讲,目标重访速度是比帧速率更为关键的指标。
另外,我们认为分辨率是不够的。量化瞬时分辨率更加重要,因为智能、高灵敏度的分辨率更有效,并且可以通过更短的响应时间提供更高的安全性,尤其是在将ROI与卷积神经网络配合时。
最后,我们证明了探测距离这个指标远远不够,目标分类距离(即识别和分类目标的速度)更为重要。仅仅量化传感器可以探测到潜在目标的距离还不够。还必须量化从实际事件发生到被传感器探测的延迟,并加上从传感器探测到CPU决策的延迟。在此架构下,激光雷达系统可提供的属性越多,感知系统的分类速度就越快。
传统的激光雷达传感器虽然具有开创性意义,但它用固定的扫描模式对空间被动地搜索。新一代智能传感器从被动探测目标转变为实时主动搜索目标并识别其分类属性。随着感知技术和传感器系统的发展,用于衡量其性能的指标也必须随之演进。
对自动驾驶车辆来讲,安全性永远排第一。这些扩展指标不仅应展示激光雷达能够实现的功能,而且还应展示出这些功能如何使车辆在现实驾驶场景中更接近最佳安全条件。
文章来源:Aeye官网,由麦姆斯咨询编译。



















 工商网监
工商网监
评论