 电子发烧友App
电子发烧友App


大模型最初叫Large languagemodel,LLM,即大规模语言模型,其没有准确的定义,在2018年一般定义为参数达到数十亿以上的模型。如今这个定义应该是1000亿参数以上的模型,它是与预训练(Pre-Training Model, PTM)同时出现的,彼此相辅相成,大模型自2018年Bert和GPT的问世而宣告正式出现。
大模型的海量参数意味着其疯狂消耗存储成本,基本上能够对应大模型的芯片单单存储成本都在2000美元以上,这意味着真正的大模型不可能上车。不过汽车行业,超过10亿参数的模型或许也能叫大模型,这与真正的大模型有着天壤之别,它又会有什么影响呢?
首先是运算芯片领域,需要更高带宽的存储器,非常昂贵的HBM有可能出现在汽车芯片上,这意味着汽车运算芯片价格会超过1000美元;
其次是老旧的针对CNN网络设计的加速器完全无法使用或效率极低,GPU或基于CPU+GPU的系统更合适,也更能应对未来模型的变化;
最后是PTM让数据训练的成本大大降低,数据集的含金量缩水了。
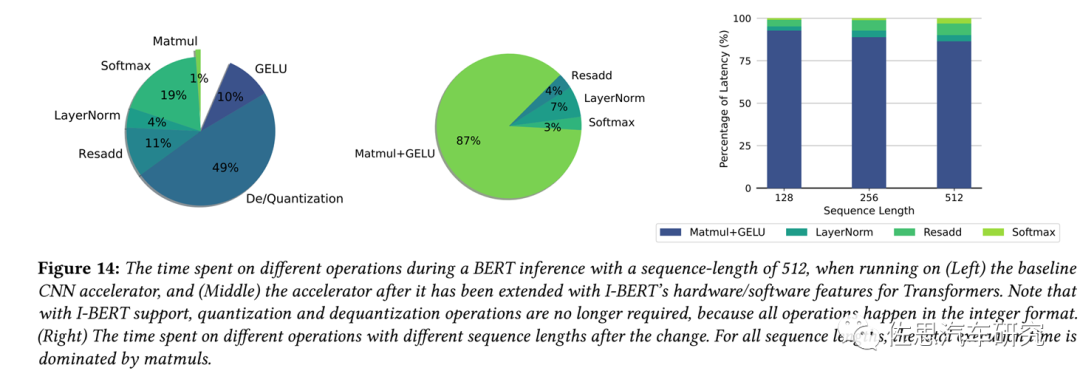
要分析大模型或者说Transformer对运算硬件的影响,可以看这篇论文:英伟达与巴克利大学的《Full Stack Optimization of Transformer Inference: a Survey》。论文做了非常详细的描述,长达45页,有兴趣的可以去看全文。
该论文指出Transformer加速器运算中瓶颈主要在CPU,非矩阵运算部分消耗的时间占了总时间的96%。换句话说,CPU远比加速器重要,Transformer时代,加速器没有存在的必要,CPU+GPU是最好的选择。如果非要用加速器的话,也得订做一个高性能的CPU。
另外还得指出,目前大模型都可算是Transformer的一种。
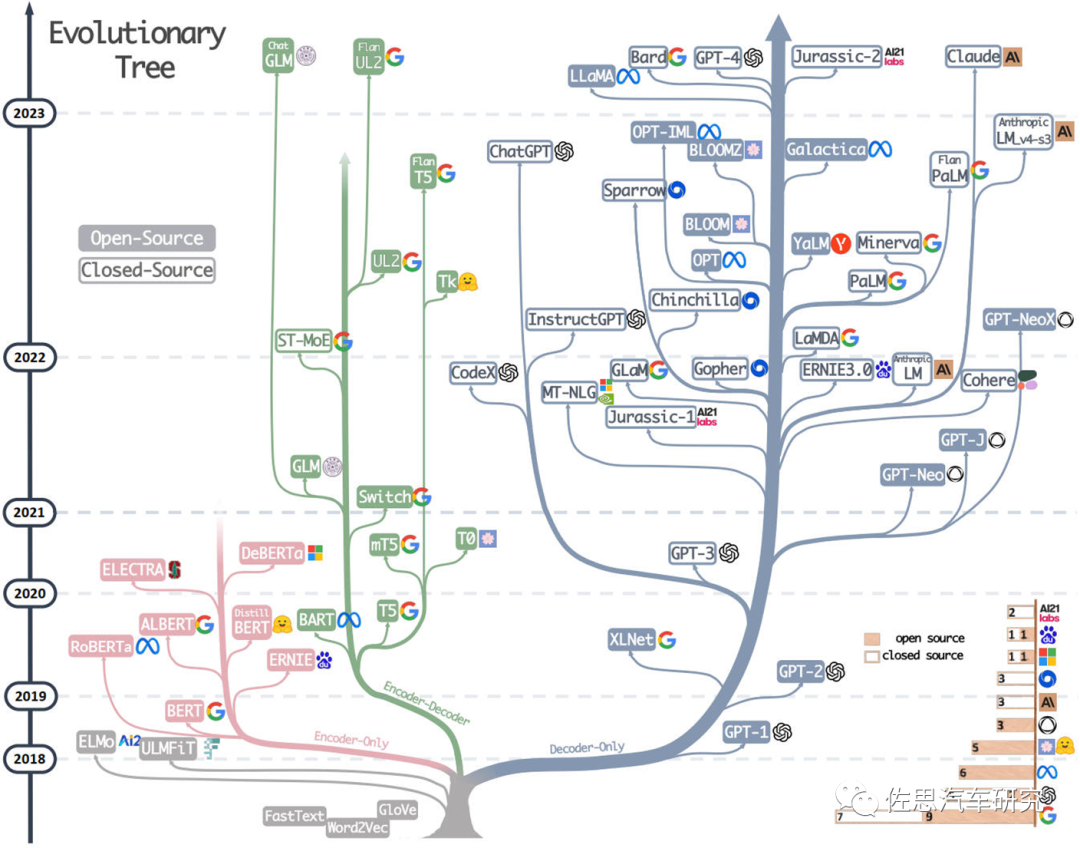
大模型进化树,其根基就是Transformer。Transformer是2017年提出的一个语言模型,最初被用于解决机器翻译的问题,但随着研究的深入,Transformer在不同问题,甚至不同领域上大放异彩,在自然语言领域的文本表征、分类、生成、问答等问题上都成为了强劲的解决方案,在视觉领域也很出色。
与传统的CNN聚焦设计相比,Transformer主要由矩阵乘法(矩阵模数)和内存密集型的非线性操作组成。Transformer模型的计算图和数据流比CNN更复杂,有更多的操作节点,更多的数据流分割和连接。而上一代传统的汽车领域AI加速器基本都是针对CNN的,无法应对数据流分割,传统AI加速器都是最大可能地让数据在运算单元之间流动,减少存储和读取,面对数据流分割就无能为力。
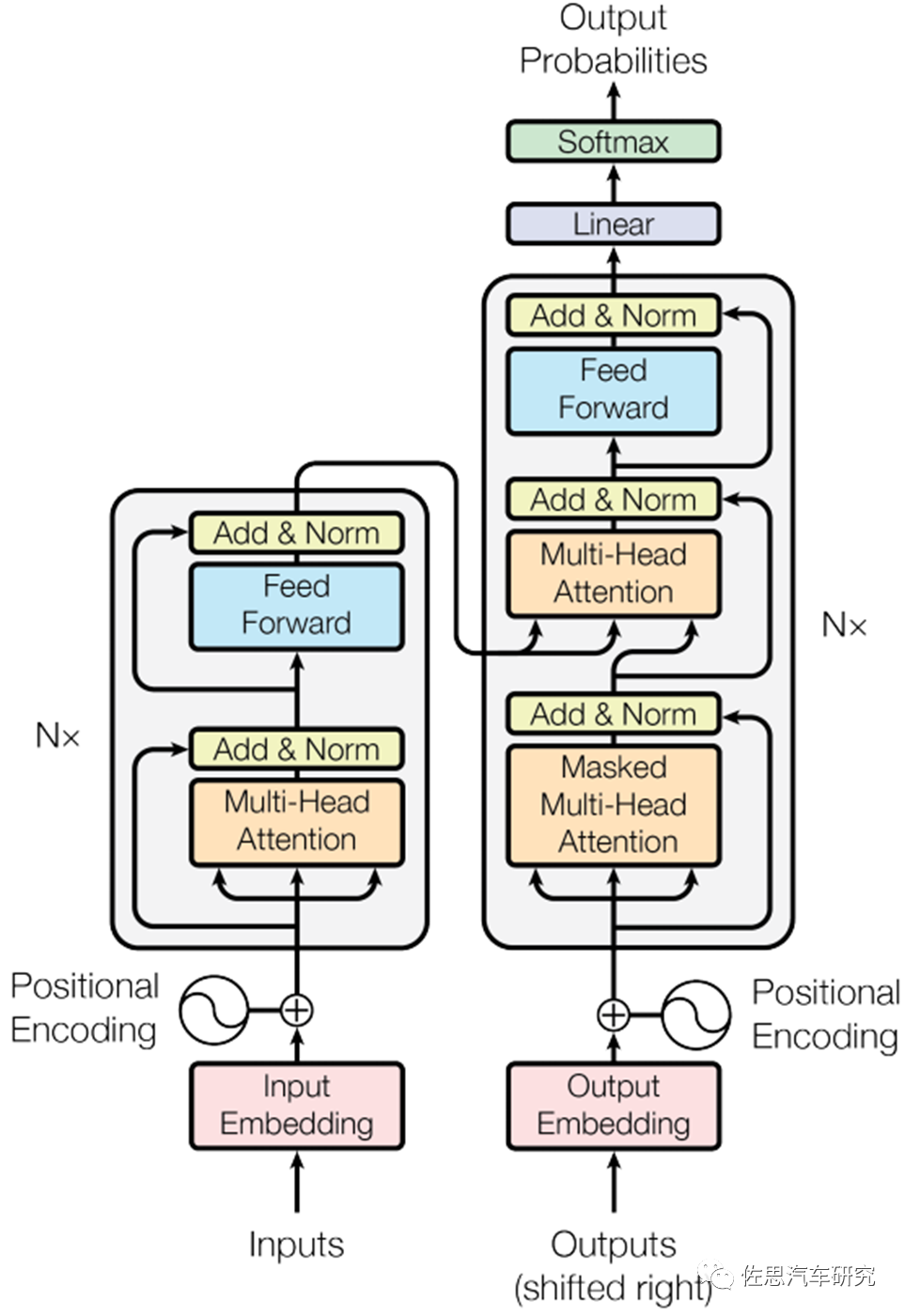
上面是Transformer示意图,编码器由相同的层堆叠,每层的结构有两部分,多头注意力和前馈。解码器亦由相同的层堆叠,每层的结构为多头注意力、编码器-解码器注意力和前馈。编码器中的每个元素对整个序列来说都是可见的。解码器的每一层中有两个多头注意力,一个是解码器的输入部分作为qkv的自注意力,一个是上一个解码器层的输出作为q,最后一个编码器层的输出作为kv的编码-解码注意力。
编码器层和解码器层的每一个部分都是残差块的形式而且包括了一个layer norm。在编码器和解码器的输入处都有位置编码,位置编码和token嵌入相加。Transformer采用的是三角式位置编码,这就意味着三角函数运算,三角函数运算属于标量运算,CPU最擅长,AI加速器对此无能为力,AI加速器只能计算矩阵的乘积和累加。即使GPU也需要CPU的大力配合,这也是英伟达一心要自研CPU的原因之一。

现在LLM模型的架构都是以Transformer为主,进一步分成Encoder-Only、Decoder-Only、Encoder-Decoder三种,选取了Bert (Encoder),GPT2 (Decoder)这两个代表模型进行分析。
由于大模型参数巨大,即便是H100这样每片3万美元的芯片也放不下1750亿参数,因此英伟达提出了张量并行的计算方法,这也再次说明真正的大模型上不了车。英伟达论文题目为《Megatron-LM: Training Multi-Billion Parameter Language Models UsingModel Parallelism》。
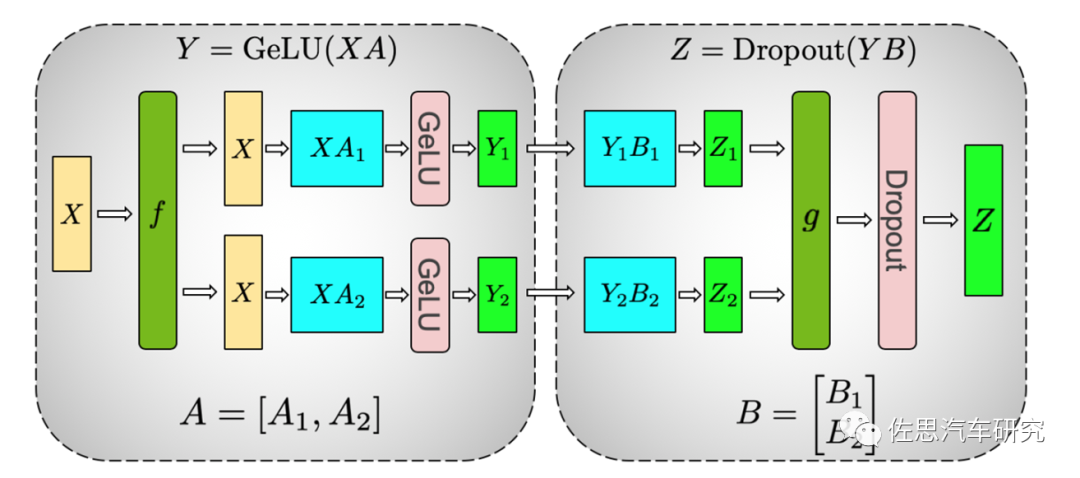
简单来说就是给参数模型(即权重模型)竖着切一刀,横着切一刀,然后插入一个AllReduce。
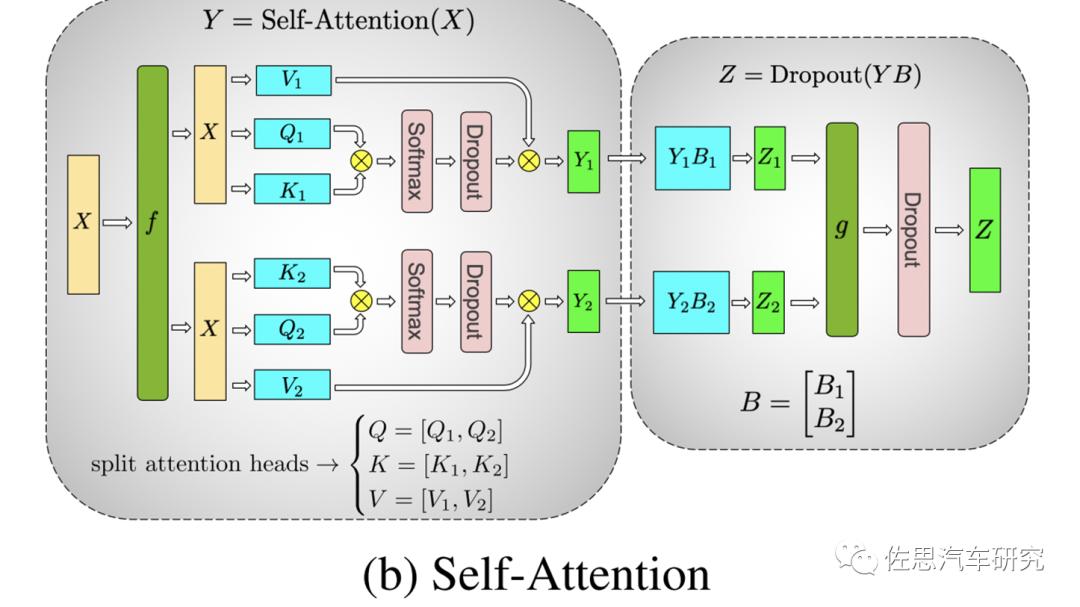
Attention的多头计算简直是为张量模型并行量身定做的,因为每个头上都可以独立计算,最后再将结果concat起来。也就是说,可以把每个头的参数放到一块GPU上。对三个参数矩阵Q,K,V,按照“列切割”,每个头放到一块GPU上,做并行计算。对线性层B,按照“行切割”。切割的方式和MLP层基本一致,其forward与backward原理也一致,这里不再赘述。
关于模型切割在此不做深入解析,大家只需要知道目前大模型都是基于多张GPU运算就行。通常是8张GPU加2个CPU作为一个节点node,8张GPU之间用NVLink连接,节点与节点之间用NVIDIAConnect TX-7智能网卡连接,这个网卡可不一般,台积电7nm工艺,800亿个晶体管,400G GPUDirect吞吐量,400G加密加速,4.05亿/秒信息率,成本估计也在500美元以上。
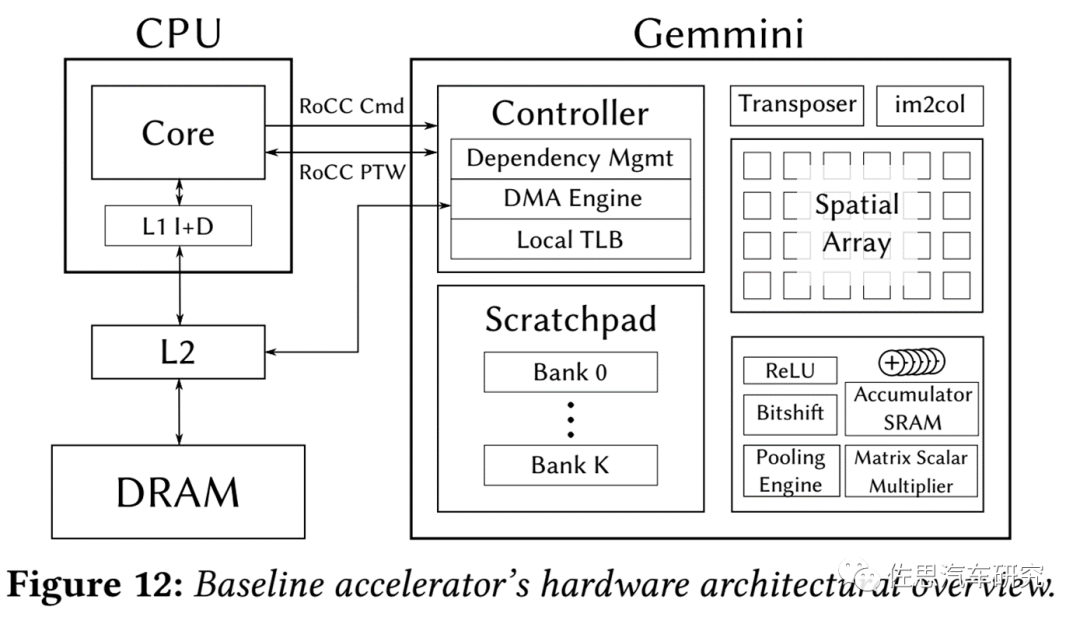
典型的AI加速器框架图,没有CPU调度任务,加速器就是无头苍蝇,没法工作。
模型数据的切割与任务调度的安排都是由CPU来做更合适,GPU不适合这种有中断分支的计算,但GPU至少可以对应矢量。AI加速器更差,AI加速器基本只能对应张量或者说矩阵,要求数据与数据之间没有任何关联。而Transformer有前反馈,也有时序关联,同时AI加速器需要CPU全力配合,排除那些低效率运算的任务,只做适合自己的任务,CPU的话语权远高于AI加速器。CPU也需要很高的算力,如特斯拉的HW4.0中的二代FSD,用了多达24核的Cortex-A72,英伟达的Thor至少是32核心的ARM V1。
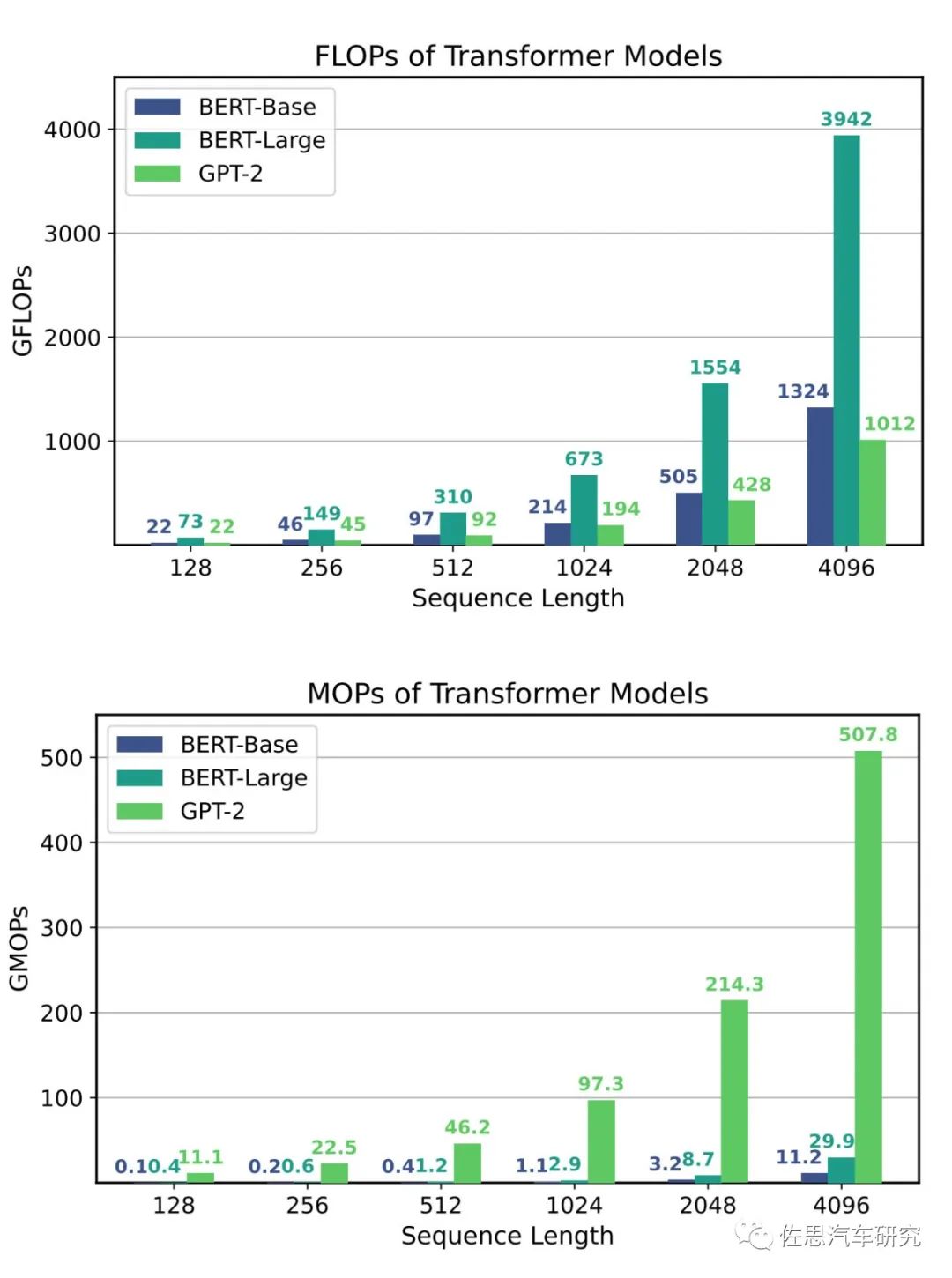
MOPs就是每秒存取次数,模型越大,MOPs就越高。对于低于1亿参数的模型,GDDR6这样的内存还勉强可以接受,特斯拉和Mobileye EyeQ6H已经采用昂贵的GDDR6。不过大部分厂家还是用廉价的LPDDR5,只能对应1千万参数的模型,未来必须使用昂贵的HBM。HBM本身不算太昂贵,比GDDR6贵几倍而已,但一旦用HBM就必须配合台积电的CoWoS工艺。这个CoWoS工艺产能异常紧张,价格极高,一般只有服务器芯片才会使用。
接下来我们说说预训练,理解PTM要从人类的学习机制谈起,利用深度学习自动学习特征已经逐步取代了人工构建特征和统计方法。但其中一个关键问题是需要大量的数据,否则会因为参数过多过拟合。但是这个成本非常高昂,以图像描述任务为例,MSCOCO数据集只标记了12万张图片,每张图片给出5个标记,总共花费了10.8W美金。而自动驾驶领域每张图片最少10个标记,数据集是百万级起跳。
众所周知,Transformer最初是自然语言处理(NLP)领域的产物,NLP领域采用了自监督学习进行预训练,其动机是利用文本内在关联作为监督信号取代人工标注。最初的探索聚焦在浅层预训练模型获取词的语义,比如Word2Vec和Glove,但它们的局限是无法很好地表征一词多义。自然而然地,就想到了利用 RNN 来提供上下文表征,但彼时的模型表现仍受限于模型大小和深度。
2018 年 GPT 和 BERT 横空出世,将 NLP 的 PTM 带入了新时代。这些新模型都很大,大量的参数可以从文本中捕捉到一词多义、词法、句法结构、现实知识等信息,通过对模型微调,只要很少的样例就可以在下游任务上取得惊人的表现。
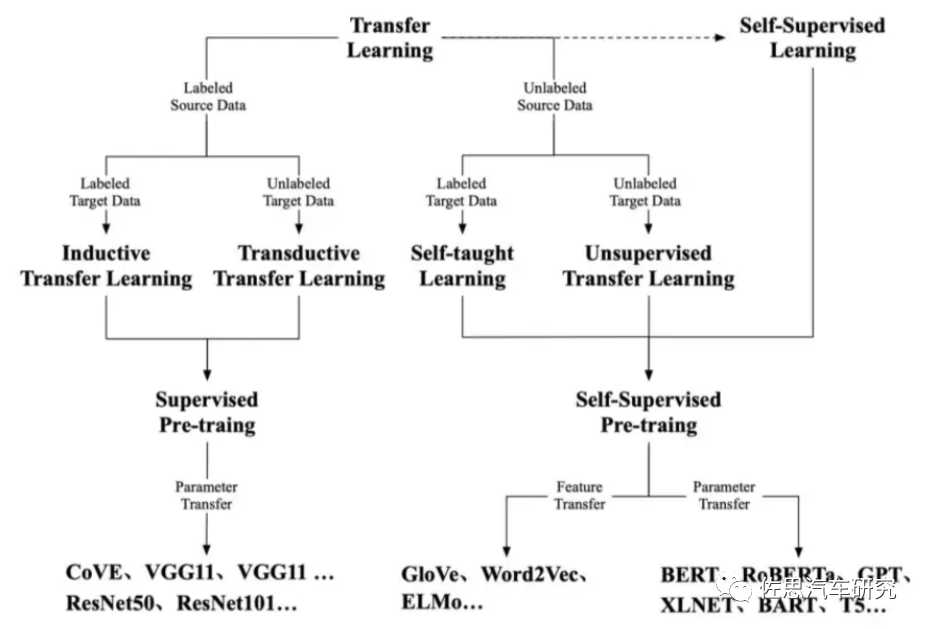
这种预训练实际专业的说法是迁移学习(TransferLearning),迁移学习的初衷是节省人工标注样本的时间,让模型可以通过已有的标记数据(source domain data)向未标记数据(target domain data)迁移。从而训练出适用于target domain目标域的模型。需要指出Transfer Learning是机器学习的分支,不需要神经网络也可以实现的,但现在神经网络基本与迁移学习合二为一。通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。
迁移学习在深度学习上的应用有两种策略,但目前这两种策略的命名还没有统一。一种策略是微调(finetuning)——其中包括使用基础数据集上的预训练网络以及在目标数据集中训练所有层;另一种则是冻结与训练(freeze and train)——其中包括冻结除最后一层的所有层(权重不更新)并训练最后一层。当然迁移学习并不仅仅局限于深度学习,但目前在深度学习上的应用确实很多。
最典型的做法可以参考论文《Image as a Foreign Language: BEIT Pretraining for All Vision andVision-Language Tasks》,微软亚洲研究院出品。
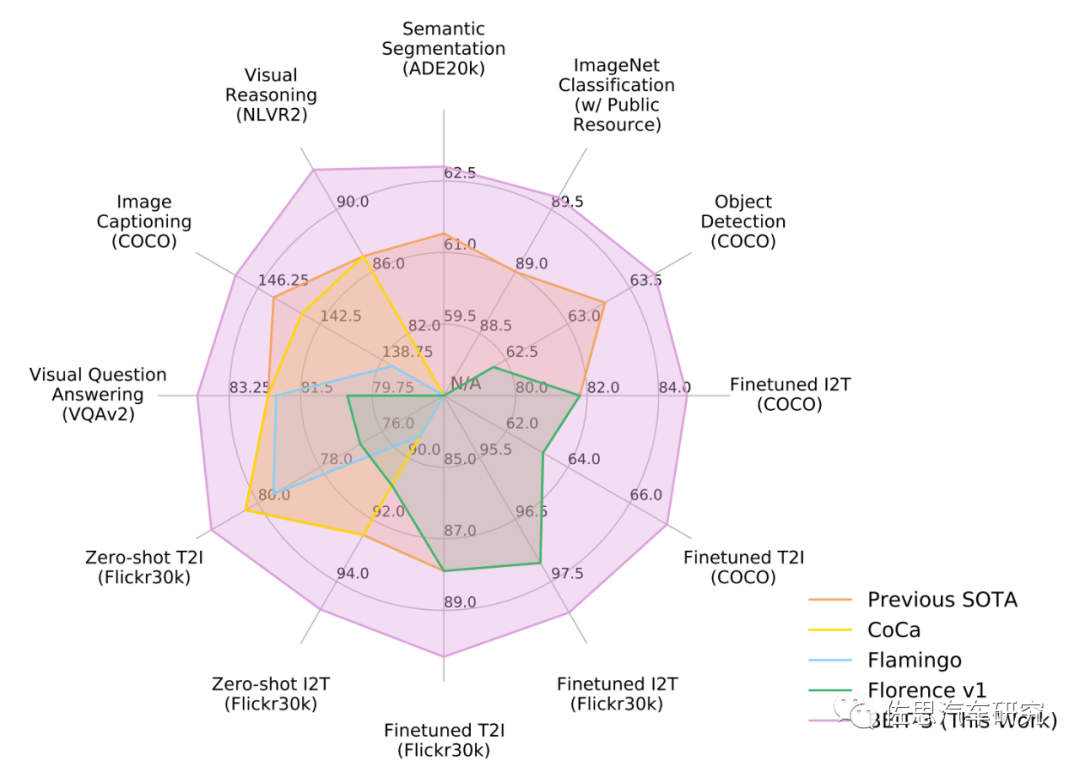
思路很精简的,就是把图片看成语言,与文本一样,采用生成式自监督方式的预训练,BEiT-3 利用一个共享的 Multiway Transformer 结构,通过在单模态和多模态数据上进行掩码数据建模完成预训练,并可迁移到各种视觉、视觉-语言的下游任务中。通俗地说就是只需要很少的精细标注视频,用这个精细标注过的数据集训练一个模型,再用这个模型训练大量的无标注视频,最终得到一个更好的权重模型。其原理类似我们学习外语时,遇到不认识的单词(掩码数据),我们不需要知道这个单词的准确意思,我们可以通过以前的经验来猜测这个词的意思,把这个猜测的意思作为一个准确的标注。
尽管已经取得了很大的成功,但还有一些基本的问题无法解决,我们仍然不清楚隐藏在大量模型参数中的本质,训练这些庞然大物的巨大计算成本也阻碍了进一步探索大模型的本质,而这一切可能很快就将大模型推到天花板级别,无力再进一步。
审核编辑:刘清
















 工商网监
工商网监
评论