什么是3D图形芯片?3D图像生成算法的原理是什么?
2021-06-04 06:29:06
3D图像的主流技术有哪几种?Bora传感器的功能亮点是什么?
2021-05-28 06:37:34
你好! 现在我有个问题想请教大家, 我怎么做一个3D图像的涡轮扇叶然后通过控制器调整它的速度然后再3D图像中开始转并且根据控制量改变在3D图像中转的快慢?怎么在3D图像中仿真水平面 并且有相应的变化!希望大家能给我有任何指教!
2016-11-30 23:25:31
,3D检测系统移动。激光器发出的光照射在PCB板上,3D高速相机采集激光器照射在主板针脚上的图像信息,并能够直接将数据实时输出给计算机,通过图像处理算法计算出PCB板针脚的高度值,实现当前针脚检测效果
2016-01-05 10:50:26
全称加工需要人工介入0,遇到中空结构更是难上加难。但对于3d打印来说,任何的结构形状都不成问题,无论多么复杂的装饰,都是可以用层层堆叠方式的原理轻松实现的。Olivier正式利用的这点,把大自然的艺术
2019-12-13 11:02:46
3D打印将精准的数字技术、工厂的可重复性和工匠的设计自由结合在一起,解放了人类创造东西的能力。本文是对当下3D打印技术带来便利的总结,节选自中信出版社《3D打印:从想象到现实》一书。虎嗅会继续摘编该书精华。
2019-07-09 07:02:03
要谈3D视觉应用方案,就必须先弄清楚光学测量分类以及其原理。光学测量分为主动测距法和被动测距法。 主动测距方法的基本思想是利用特定的、人为控制光源和声源对物体目标进行照射,根据物体表面的反射
2020-12-01 15:08:04
的解决方案:支持 12路摄像头 并发输入,并通过高效的视频编解码与 RTSP 推流,实现端到端仅约 120~150ms 的低延迟体验,成为车载环视的理想硬件平台。 米尔RK3576开发板标注图一、车载360
2025-10-11 17:55:41
摄像头实时取景,将四个摄像头所采集的图像组合在一起显示在驾驶室的显示屏上,司机可以一眼了解到本车周围的全部情况,提高汽车的综合安全系数。 3 功能实现 3.1 激光测距的功能实现 原理图如图2
2011-07-27 09:36:00
源码:[hide][/hide]工业相机的运行模式有以下几种:1)连续采集模式:连续曝光,曝光完成后输出图像上图可以看到连续采集时,从采集执行到图像输出之间最高可能会达到较高的延时,一般用于静态检测
2021-05-17 11:18:52
LabVIEW控制CCD相机实现采集图像,求程序,各位大神帮帮忙,急急急啊!
2017-04-06 17:36:06
[hide][/hide]一直有小伙伴在问labviewnimax能看到并打开cameralink相机图像,但是在labview中无法检索到相机nimax中能采集图像labview罗列相机无法找到
2021-06-10 19:47:49
动态模糊,确保高耐光性,同时输出2D(红外)和3D(深度)数据。
◆ Testing Principles
※ 测量脉冲光的飞行时间,以检测 TOF 相机与被测物体之间的距离。
◆ ToF 产品
2025-09-05 07:24:33
无论2D相机还是3D相机,提到相机不可避免地涉及到机器视觉。机器视觉与计算机视觉并没有一个明显的定义去划分。但在实际应用中,...
2021-07-02 06:50:13
环视、RVC后视、BSD盲区监测、DMS驾驶员行为检测、CMS后视镜,以及两轮车、小汽车、商用车的DVR行车记录仪等;
非车载应用:可视锚鱼器、可视门铃、监控相机等。
产品优势:
功耗低、低成本优势,底噪度好、夜视亮度更高
2024-03-29 14:12:31
、高精准度的可视化基于Windows开发的可视化3D设计软件,选项卡、功能命令、操作习惯和主流的3D软件或常用的office办公软件基本相似,最大程度的提升了用户入门速度。通过结构树的形式实现对模型各
2020-05-13 14:33:30
光学3D表面轮廓仪是基于白光干涉技术,结合精密Z向扫描模块、3D 建模算法等快速、准确测量物体表面的形状和轮廓的检测仪器。它利用光学投射原理,通过光学传感器对物体表面进行扫描,并根据反射光的信息来
2023-08-21 13:41:46
处理计算带来误差,为了消除这些误差,我们在进行3D视觉建模的过程中需要对我们使用的摄像机进行标定,获取相机内外参数,然后再根据内外参数对计算进行纠正。摄像机采集到的图像发生的畸变通常分为径向畸变和切向
2018-09-28 10:32:24
什么是活体检测?什么又是3D活体检测?以及怎么实现恶劣环境(如人脸遮挡、恶劣光照等)与人脸多姿态变化(如侧脸、表情等)应用场景下的活体检测呢?本文将会围绕这些问题,介绍数迹智能的最新成果——基于ToF的3D活体检测算法。
2021-01-06 07:30:13
检测,检测准确性和检测稳定性较差、容易误判。 基于深度学习和3D图像处理的精密加工件外观缺陷检测系统创新性结合深度学习以及3D图像处理办法,利用非接触式三维成像完成精密加工件的外观缺陷检测,解决行业
2022-03-08 13:59:00
间提供简单、灵活的通信接口。 通常情况下,图像采集系统以CCD或CMOS等数字式相机为基础,还需要采集卡来完成数据采集,常见的采集卡有基于DSP实现的和基于FPGA实现的,MV-D1024E系列相机
2019-07-02 08:11:34
如何利用相位延迟改善3D音效?如何利用相位延迟消除串扰?
2021-06-04 06:01:17
本文介绍的三个应用案例展示了业界上先进的机器视觉软件和及其图像预处理技术如何促使2D和3D视觉检测的性能成倍提升。
2021-02-22 06:56:21
一、程序功能 1.通过选择相机实现电脑摄像头或CCD连续图像采集。 2.控制图像采集时间。 3.显示图像采集速率和程序运行时间。 4.给采集到的图像命名并保存到特定的文件夹。 二、程序介绍
2019-06-13 08:00:00
如需在汽车工业等生产线使用3D相机自动检测目标体积或目标的多角度视图,则必须快速生成和处理高分辨率的3D数据。配备500万像素大尺寸传感器和可变基线的立体相机系统可提供理想数据。但是,在此类性能要求
2021-12-23 07:54:55
如需在汽车工业等生产线使用3D相机自动检测目标体积或目标的多角度视图,则必须快速生成和处理高分辨率的3D数据。配备500万像素大尺寸传感器和可变基线的立体相机系统可提供理想数据。但是,在此类性能要求
2021-12-23 07:20:35
要求能够实现LabVIEW对CCD相机的控制,从而控制CCD相机采集图像,求程序!!!各位大神,帮帮忙,拜托了!!!
2017-04-06 17:10:15
为主,也可支持3D,有影像输入功能;高档为SXGA或更高解析度的荧幕,动态3D绘图,多重影像输入。 实现应用中完美图像功能的第一步,是针对应用目标选择一款适合的GDC,并以合理的价位获得所需功能
2014-08-14 14:00:59
以及3D眼镜的局限性,导致在2010年推出的3D立体显示并未在游戏和家庭娱乐中得到大规模的普及。 DLP® 技术可以实现具有出色图像质量的多视角自动立体显示解决方案。通过将观看者与虚拟物体之间的距离
2022-11-07 07:32:53
三维(3D)扫描是一种功能强大的工具,可以获取各种用于计量设备、检测设备、探测设备和3D成像设备的体积数据。当设计人员需要进行毫米到微米分辨率的快速高精度扫描时,经常选择基于TI DLP®技术的结构光系统。
2019-08-06 08:09:48
洛微科技D3-标准款3D工业相机托盘识别抓取识别产品简介D3系列是专为工业环境应用设计的3D TOF智能相机。产品系列基于行业领先的Sony DepthSense® 像素技术开发,具有毫米级测量精度
2024-08-22 15:34:34
洛微科技D3C-RGBD-融合款3D工业相机体积测量AGV避障产品简介产品具备毫米级测量精度,支持点云和RGB对齐,可实现RGB图像与TOF图像微秒级同步输出,支持高速拍摄,不受环境光干扰,实现高
2024-08-22 15:40:19
洛微科技DM 3D工业相机抓取引导目标识别产品型号:LWP-D325-I & LWP-D325C-I & LWP-D325W-I产品介绍洛微科技DM 3D工业相机是一款工业级
2024-10-30 11:42:37
3D图像引擎,3D图像引擎原理
产生的背景和定义 随着计算机软、硬件突飞猛进的发展,计算机图形学在各个行业的应用也得
2010-03-26 15:54:07 1633
1633 本文给出了利用PADS实现3D可视化的 具体过程,并对PADS和3D技术进行了必要的说明。
2011-10-10 16:03:51 478
478 相机采集的。为了提高平面提取的速度,我们首先计算深度图像中点的法向量,通过法向量来判断这些点是否在一个平面上。运用求点的法向量可以同时检测多个复杂的平面,而且实验结果显示该方法比传统的3D Hough Transform以及RANSAC方法要快。此种方
2017-11-16 10:10:124 由于基于机器视觉输送带检测中输送带运动速度快、上下输送带间隔距离近(物距小)、采集范围大(视场大),造成图像信息采集困难。本文提出了利用单个线阵CCD相机输送带图像的采集方法,该方法采集图像的视场角
2017-12-27 11:07:046 研究和实现了一个基于OMAP3530的2D到3D视频自动转换系统,重点研究深度图获取和深度信息渲染等主要核心技术及其实现。该系统利用OMAP3530其特有的双核结构,进行系统优化:由其ARM处理器
2018-03-06 14:20:551 据麦姆斯咨询报道,全球领先的沉浸式3D媒体技术公司Matterport于英国当地时间2018年2月15日发布了新款3D相机——Pro2 Lite。这款售价仅为2195英镑的3D相机是该公司迄今为止售价最低的产品,目标商业用户定位于对3D成像要求较低的新产品。
2018-03-13 16:41:2810846 致力于亚太地区市场的领先半导体元器件分销商---大联大控股宣布,其旗下世平联合驰晶科技推出基于众多国际大厂产品的Full-HD 3D 360°全景环视与ADAS系统解决方案,支持360°车载全景可视
2018-04-10 14:26:0014255 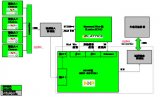
分享到 据外媒报道, 麦格纳 与 瑞萨电子 开展合作,双方正在研发一款更具成本效益的 3D环视系统 ,该系统专为入门级及中档汽车量身定制。 双方表示,新款摄像头的应用使得众多车企得以将3D摄像头技术
2018-05-29 15:26:001487 美科学家研制新型相机可黑暗中拍3D照片 关键词:相机,黑暗,3D照片 家用电子 时间:2014-01-09 15:55:24来源:互联网 美国麻省理工学院的科学家研制了一种新型相机,能够在几乎完全漆黑的环境下拍摄3D照片。这种相机利用几乎不可见的物体反射的光子绘制3D图像。
2019-06-07 15:34:002474 投影到图像,得到4个perspective keypoint,这4个点在3D bbox regression起到一定的作用,我们在下一部分再介绍。
2019-03-12 09:43:475006 
利用3D表面定向,特别是它对反射光的影响,工业应用的光度立体产生对比度图像,突出了局部3D表面变化。
2019-06-13 08:56:356388 麦格纳的3D环视系统是一款车载摄像头系统,可在泊车和低速行驶时为驾驶员提供360度全景视图支持。 驾驶员可以通过易于使用的界面调整画面,而系统自带的物体检测功能则会通知驾驶员路径上的障碍物。
2019-08-02 11:40:023002 完成在实验室和目标平台车辆上的测试后,现在需要再次集中注意。你想要看你的设备在潜在的硬件平台上的表现。这个时候,你或许想使用你的 Apalis iMX6 计算机模块和 Ioxra 载板(如果你没有的话可以从 Toradex 购买),以及针对目标平台的 TES 3D 环视软件。
2019-08-08 10:21:543142 3月13日消息,谷歌宣布推出 MediaPipe Objectron,这是一种适用于日常物体的移动端实时3D目标检测 pipeline,它能够检测 2D 图像中的目标,并通过新创建 3D 数据集上
2020-03-13 15:41:103284 3D相机的不同之处在于,它可以测量普通数码相机无法测量的深度数据。所谓深度数据,就是像素到相机的距离。所以3D相机可以获取四个值,分别是RGB值和深度信息,即RGB-D。
2020-09-24 12:40:1620623 具体到3D机器视觉检测设备的发展,公司介绍,一是公司基于3D机器视觉技术的3D AOI、3D SPI已实现批量销售和进口替代,获得诸如和硕集团、比亚迪、京东方等行业标杆客户的高度认可。
2020-10-09 09:54:043064 ,ZIVID全新第二代彩色3D相机克服了传统3D相机在图像质量、真实度和速度等各方面的限制,在物流和制造业中实现了更好的目标识别、精确的零件处理和更短的工作周期。 这一采用许多先进技术设计的超紧凑型相机大幅提升了3D图像的精确度、物体识别的真实度、图像获取的时间
2020-11-19 11:49:272897 随着对精度和自动化的需求不断增加,3D机器视觉会变得越来越流行。业界认为,从2D到3D的过渡将成为继黑白到彩色、低分辨率到高分辨率以及静态图像到电影之后的第四次革命。 1、什么是3D相机? 3D即
2020-11-26 16:17:0314475 电子发烧友网站提供《3D目标检测是否可以用层级图网络来完成.pdf》资料免费下载
2020-11-26 16:55:299 1.前言无论2D相机还是3D相机,提到相机不可避免地涉及到机器视觉。 机器视觉与计算机视觉并没有一个明显的定义去划分。但在实际应用中,应用于工业检测的时候更多地被称为机器视觉而非计算机视觉。这时候
2020-11-27 09:46:039319 最新的iphone 12系列使用后置激光雷达传感器,可以拍摄令人印象深刻的3D照片和扫描图像,但是iPhone 12没有3D屏幕无法显示3D图像,现在售价349美元的Looking Glass
2020-12-04 14:46:004954 谷歌发明的由2D图像生成3D图像的技术,利用3D估计神经网络图像信息的补全以及预测,融合了拍摄角度、光照等信息,让生成的3D图像看起来更加逼真,这种技术对于三维建模以及工业应用都具有极大的指导意义。
2020-12-24 12:55:235465 
的USB接口,利用PC机作为参数輸入和显示界面,完成一个从图像采集到存储、显示的高帧频图像采集系统的设计。该系统可靠性妤、集成度高、功耗低,且满足不依赖于PC机的图像采集系统的应用要求。
2021-01-29 16:00:006 对室内人员有无及生命体征状态的判断。 在此基础上,加特兰基于AiP毫米波雷达芯片的新方案又率先实现了3D目标跟踪、房间面积测量等功能,为智能家居、消费电子、养老等市场提供了新方向和选择。 3D目标跟踪 3D目标跟踪 基于加特兰AiP的毫米波雷达具备很高
2021-03-05 11:53:034888 3D视觉定位指的是根据事先构建的3D模型及相关信息,计算取得某张图像在拍摄时相机的位置和姿态。这是3D视觉的一项十分重要的技术,可以用来帮助实现人员定位与导航。
2021-04-03 14:39:0010507 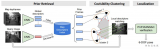
引言 所谓3D视觉定位指的是根据事先构建的3D模型及相关信息,计算取得某张图像在拍摄时相机的位置和姿态。这是3D视觉的一项十分重要的技术,可以用来帮助实现人员定位与导航。本博文将基于2019年
2021-04-01 14:46:045083 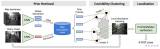
环视鱼眼图像具有目标形变大和图像失真的缺点,导致传统网络结构在对鱼眼图像进行目标检测时效果不佳。为解决环视鱼眼图像中由于目标几何畸变而导致的目标检测难度大的问题,提出一种基于可变形卷积网络的鱼眼
2021-04-27 16:37:044 据悉,ZIVID全新第二代彩色3D相机大幅提升了3D图像的精确度、物体识别的真实度,缩短了图像获取的时间以及有效抑制无用的伪像数据等,在物流和制造业中实现了更好的目标识别、精确的零件处理和更短的工作周期。
2021-06-18 10:32:044400 华为3D建模服务(3D Modeling Kit)是华为在图形图像领域又一技术开放,面向有3D模型、动画制作等能力诉求的应用开发者,基于AI技术,提供3D物体模型自动生成和PBR材质生成功能,实现3D数字内容高效生产。
2021-08-12 14:50:156126 该项研究采用了基于多序列的3D卷积神经网络模型,由数坤科技自主研发,用于肝脏MR图像的精准分割。
2022-04-02 16:06:114899 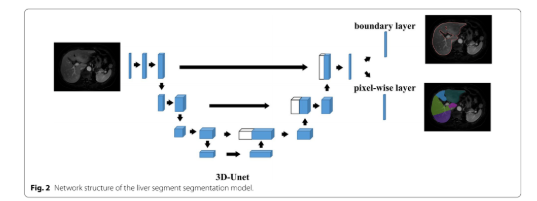
对于机器人来说,实现类似人类的视觉和操作能力是非常具有挑战性的。因为其中涉及到了多种因素包括速度、图像质量、简单性、鲁棒性和成本等。而将3d相机直接架设到机器人手臂上的方式(eye in hand
2022-04-22 10:56:46908 3D 视觉相机现在支持混合多传感器网络,允许用户混合和匹配同系列的3D视觉传感器。以扫描木板为例,其中一半的检查需要精细的特征测量,而另一半则需要的FOV。结合多个激光线轮廓仪的 3D 检测系统通常仅限于使用相同型号类型的3D视觉传感器。
2022-04-22 15:47:562744 
多年来,3D IC技术已从初始阶段发展成为一种成熟的主流制造技术。EDA行业引入了许多工具和技术来帮助设计采用3D IC路径的产品。最近,复杂的SoC实现开始利用3D IC技术来平衡性能和成本目标。
2022-09-16 10:06:411879 基于几何的单目3D目标检测通过2D-3D投影约束估计目标的位置。具体来说,网络预测目标的尺寸(),旋转角。假设一个目标有n个语义关键点,论文回归第i个关键点在图像坐标中的2D坐标和object
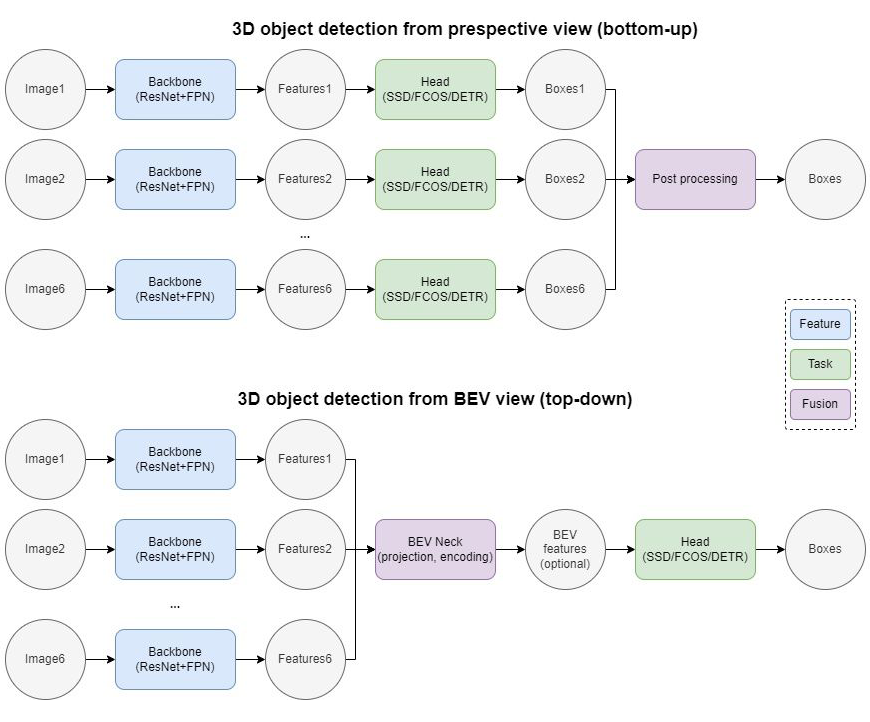
2022-10-09 15:51:321673 基于图像的3D目标检测是自动驾驶领域的一个基本问题,也是一个具有挑战性的问题,近年来受到了业界和学术界越来越多的关注。
2022-11-15 10:15:322624 3D传感器作为3D视觉的眼睛,通过多个摄像头与深度传感器的组合能够获得物体三维位置及尺寸等数据,实现三维信息采集。目前3D视觉传感器主要有双目相机、结构光相机及TOF(Time of flight)相机。
2022-11-22 21:21:195192 3D相机与工业机器人结合,有效地解决了以上痛点。3D相机可获取目标物体的三维坐标信息,引导机械臂进行拆垛码垛,实现自动化。其速度快,效率高,作业柔性化,支持长时间连续工作,大大节约了人工成本,适用于多种混合垛形。
2023-04-11 10:50:471949 嘲风Pro 相机是一款高精度、小型化的3D相机,采用自主研发的Mems结构光,搭载于高效的硬件计算平台,结合优化的系统设计和高效算法加持,能快速稳定获得杰出的3D重建效果。可广泛用于制造业在线检测
2023-05-18 10:21:181 图像的采集。将相机安装在适当的位置上,以保证对整个棉田的拍摄。保持相机的稳定,避免晃动和震动。 3. 图像处理与分析:将采集到的高光谱图像导入图像处理软件。根据虫害特征和相机的光谱响应,进行图像处理和分析。常见的处理方法
2023-05-25 10:31:25920 
3D相机的应用在我们身边已是越来越常见,如何在众多不同的3D相机中挑选到最适合的产品,就需要对3D相机的成像原理、原理优缺点以及特征参数进行深入的了解。
2022-03-21 16:02:305498 
知微传感即将推出高分辨率的工业3D相机-D132
2022-06-15 15:19:501931 
提升,360°全景环视也由原来2D升级到了3D。通过安装在车身前后左右的4枚鱼眼摄像头采集图像信息,经过精细拼接缝处理后,拼接成一整张3D表面网状模型,根据所选的
2022-09-28 15:50:102971 
Technologies Cam Cube 3.0,微软Kinect V2等。 TOF成像可用于大视野、远距离、低精度、低成本的3D图像采集,其特点是:检测速度快、视野范围较大、工作距离远、价格便宜,但
2023-06-25 10:46:063385 
雷达以用于高级驾驶辅助系统(ADAS)多年。然而,尽管雷达在汽车行业中很流行,考虑到3D目标检测时,大多数工作集中在激光雷达[14,23,25,26,40 - 42,45]、相机[2,7,24,35],和激光雷达-相机融合[6,11,12,15,16,21 - 23,37,38,43]。
2023-07-10 14:55:093862 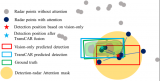
、ply格式、ptx格式、bin格式、obj格式等。 txt格式 读取txt文件生成3D模型一般需要分析txt文件的储存格式,下图是我使用的工业相机储存的部分txt数据: 经过分析,前3列为X、Y、Z坐标,第4列到第6列为每一点的法线坐标nX、nY、nZ,第7列到第9列为灰度值。因此我们采用以下代码重
2023-07-12 10:28:424105 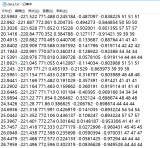
本文介绍在3D 目标检测领域的新工作:SparseBEV。我们所处的 3D 世界是稀疏的,因此稀疏 3D 目标检测是一个重要的发展方向。然而,现有的稀疏 3D 目标检测模型(如 DETR3D[1
2023-09-19 10:00:012072 
针对搭边缺陷检测,基于相机采集的深度图像,导入VM 3D软件中,依据mark点定位到每个料盘的四个角点,分别在角点料坑上下曲小区域计算均值,可取四对或八对区域,比对料坑上下高度差值,正值为OK(绿色非搭边框),负值为NG(红色搭边框)。
2023-09-28 12:50:362319 
总述全景环视系统是通过安装在汽车前、后、左、右四个广角摄像头采集的车辆四周的实时画面,通过摄像头内参标定,外参标定,鱼眼图像畸变矫正,全景模型拼接,亮度均衡等算法,形成一幅准确的2D拼接的鸟瞰图
2022-01-17 09:51:5024 VT6000系列共聚焦显微镜擅长微纳级粗糙轮廓的检测,配备了真彩相机并提供还原的3D真彩图像,具有很强的纵向深度的分辨能力,所展示的图像形态细节更清晰更微细,横向分辨率更高。为国内3D显微检测的应用场景提供更全的解决方案。
2023-02-03 10:31:493 可用于自动驾驶场景下基于图像的3D目标检测的数据集总结。其中一些数据集包括多个任务,这里只报告了3D检测基准(例如KITTI 3D发布了超过40K的图像,其中约15K用于3D检测)。
2024-01-05 10:43:571111 
近年来,机器人技术的快速发展促使对3D相机技术的需求不断增加,原因在于,相机在提高机器人的性能和实现多种功能方面发挥了决定性作用。
2024-01-15 14:09:211192 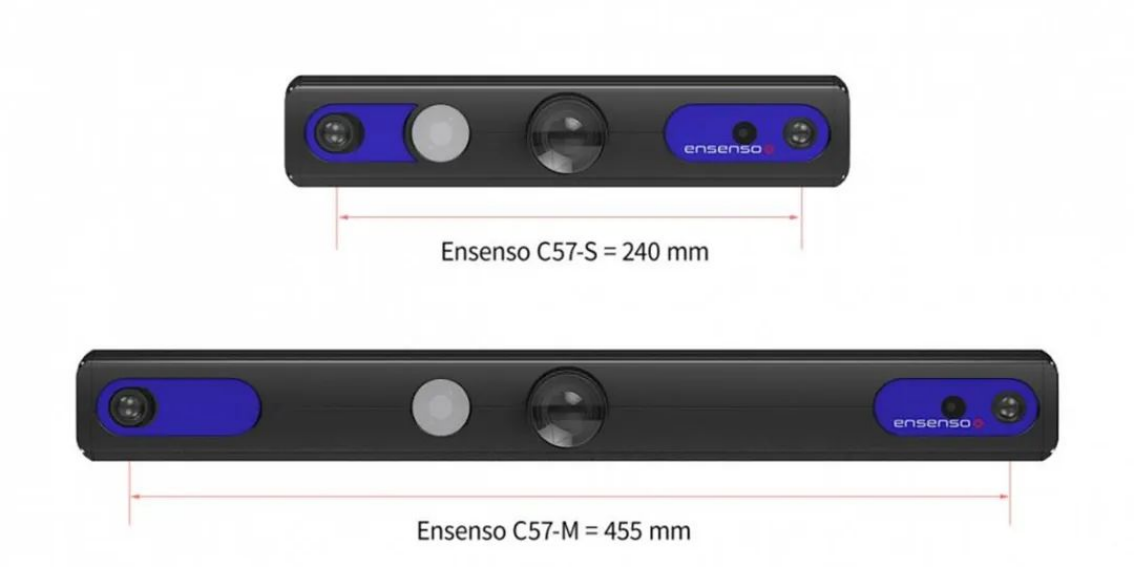
今天上午,计算机视觉领域顶会CVPR公布了最终的论文接收结果,Nullmax感知部门的3D目标检测研究《Enhancing 3D Object Detection with 2D Detection-Guided Query Anchors》入选CVPR 2024,技术实力再获权威认可。
2024-02-27 16:38:121895 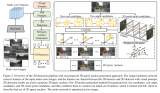
乘用车辆的长期稳定行驶离不开轮胎等零部件的定期检测。友思特 3D相机可实时采集车辆四轮的三维点云图,提取关键信息并进行计算分析,实现车辆四轮定位的精确测量。
2024-04-24 17:00:06935 
导读 精准搜集车辆传感器的 实时数据 是 ADAS系统 稳定运行的关键所在。 友思特 proFRAME 系统 可以同步采集输入数据流并输出处理,成为车载全景环视相机从图像采集至分析结果输出存储的高效
2024-08-22 15:12:371088 
车载多相机采集系统是智能驾驶技术实际应用中的的“眼睛”,友思特车载图像采集和回放系统切实提升了系统的实时同步采集与回放能力,为ADAS等应用的决策系统提供了可靠的核心数据。
2024-10-16 16:14:081619 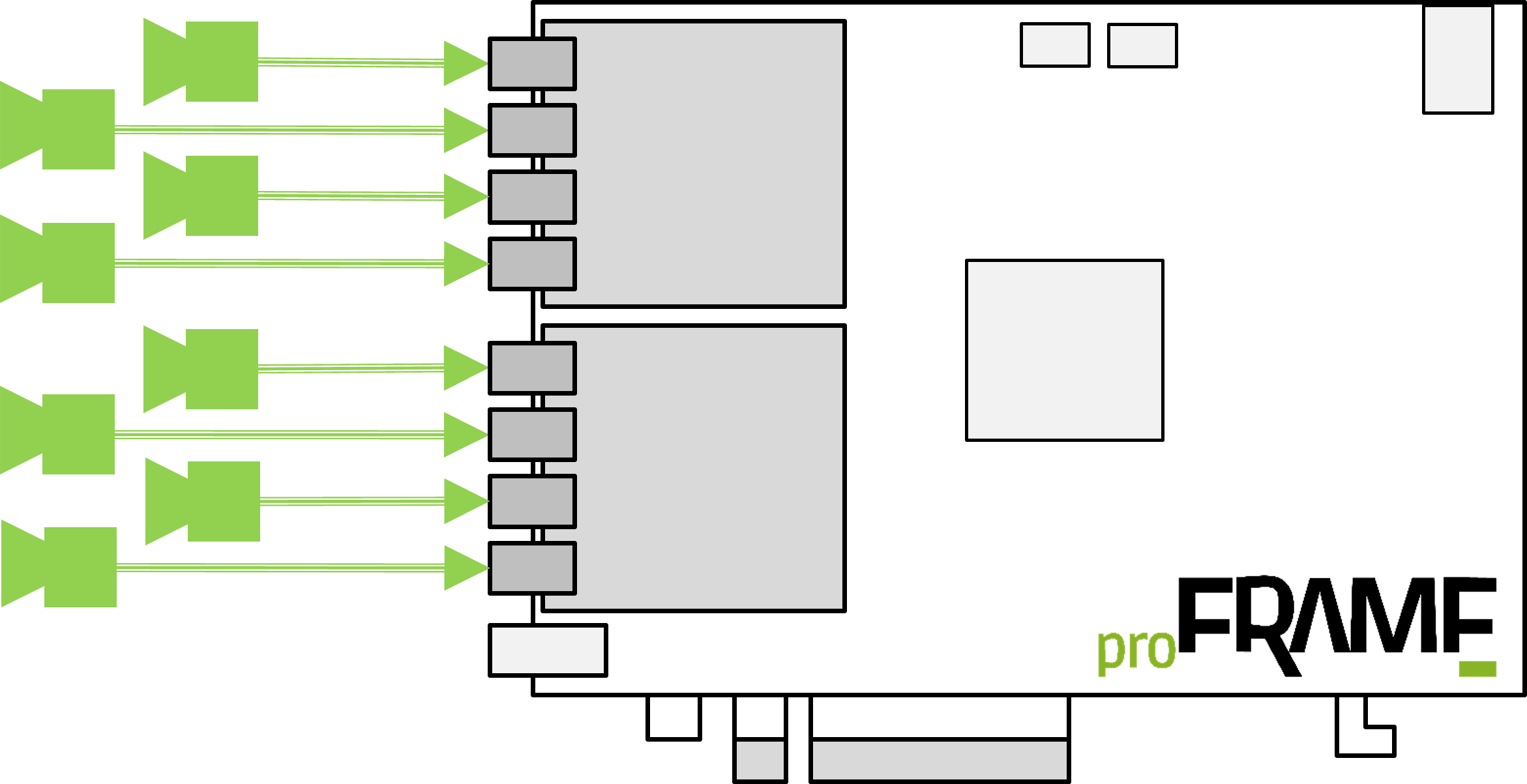
工业相机图像采集卡是用于连接工业相机与计算机的关键硬件设备,主要负责将相机输出的图像信号转换为计算机可处理的数字信号,并实现高速、稳定的数据传输。它在工业自动化、机器视觉、医学影像、科学研究等领域
2025-05-21 12:13:32636 
3D工业相机的选型
2025-05-21 16:49:261373 
3D传感器是实现深度感知的核心技术。这些传感器广泛应用于多种常见的3D视觉技术中,例如立体相机、激光雷达(LiDAR)、飞行时间(ToF)相机和激光三角测量。通常根据应用场景和技术要求选择合适的3D
2025-11-28 17:03:371713 
一、友思特新品 友思特 iDS uEye Nion iTof 3D相机将 120 万像素的卓越空间分辨率与可靠的深度精度相结合—即使在极具挑战性的环境中也能确保获取精细的 3D 数据。 其外壳达到
2025-12-15 14:59:41171 
工业相机是专门为工业应用设计的图像采集设备,具有高精度、高速度、高稳定性和环境适应性强的特点。其核心作用是通过图像处理和分析,为工业自动化提供关键数据支持。工业3D相机
2025-12-24 10:41:2424 
 电子发烧友App
电子发烧友App










 工商网监
工商网监
评论