 电子发烧友App
电子发烧友App


作者:匡吉
自动驾驶技术在20世纪初的概念和实验主要集中在车辆自动化和遥控方面。到了20世纪80年代和90年代,随着计算机技术和人工智能的发展,自动驾驶技术开始取得显著进展。这一时期,一些大学和研究机构开始开发原型车辆,能够在特定条件下实现自动驾驶。
进入21世纪,自动驾驶技术迎来了快速发展期。随着传感器、算法、计算能力和大数据技术的进步,多家科技公司和汽车制造商开始投入巨资研发自动驾驶车辆。 目前,自动驾驶技术正处于逐步成熟阶段,虽然还面临着技术、法律、伦理和安全等多方面的挑战,但其发展潜力仍然不可小觑,将对交通安全、效率、环境保护等产生深远影响。 本文,我们将梳理自动驾驶技术的进化与发展。
如图1是自动驾驶的经典框架,其中,最为重要的任务是场景理解任务,这一任务在学术文章中常常称之为感知任务,伴随AI技术蓬勃发展,感知任务也在不断刷新其性能上限。为辅助车辆控制系统,以及理解周围环境,自动驾驶系统使用了各种感知技术,最为重要且广为人知的就是:SLAM(同步定位与建图)和BEV(鸟瞰视图)技术。这些技术赋予车辆无论在静止还是移动的状态下,理解自身位置、检测周围障碍物、以及估计障碍物方向和距离的能力,这些能力为后续驾驶决策提供信息。

▲图1|经典的自动驾驶框架
SLAM+DL:第一代自动驾驶技术
■2.1 简介
开门见山,第一代自动驾驶感知技术,是以SLAM算法结合深度学习技术相结合为代表的。第一代自动驾驶感知技术框架中的多种任务,例如:目标检测和语义分割任务,都必须和输入数据处于相同坐标系统下实施。如下图2所示,唯一例外的是相机感知任务,它是在2D图像的透视空间中运行的。但是,为了从2D空间升级到3D空间,2D检测任务需要很多关于传感器融合的手动规则,例如使用雷达或者激光雷达等传感器进行3D测量。因此,传统感知系统通常需要在与车载摄像机图像相同的空间内进行处理。为了将2D空间中的位置信息更新到3D空间,后续的预测和规划任务常常用于多传感器融合,如借助毫米波雷达或激光雷达等有源传感器。
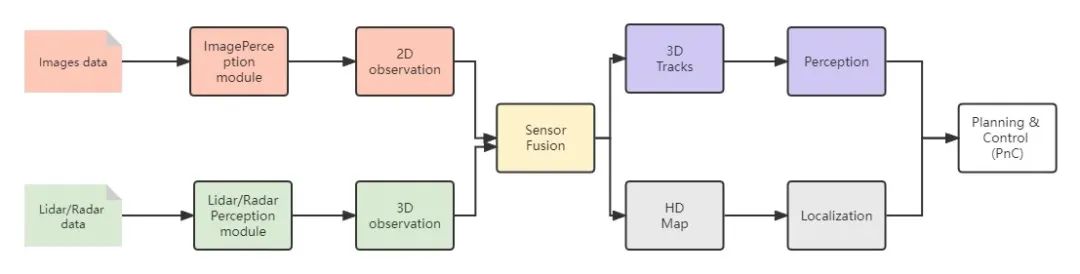
▲图2 SLAM+DL的自动驾驶技术框架
■2.2问题和挑战
但是,上述基于SLAM+DL的第一代自动驾驶技术暴露出越来越多的问题: 1)整个自动驾驶系统最上游的是感知模块,尤其当传感器的类型和数量变的越来越复杂,如何融合持续输入的多模态和不同视图数据,并实时输出下游所需的一系列任务结果,成为自动驾驶的核心挑战。 2)感知环节通常会消耗车辆的大部分算力。在感知过程中,系统需要融合不同视角摄像头的视觉数据以及毫米波雷达、激光雷达等传感器的数据,这给模型设计和工程实现带来了挑战。在传统的融合后处理方法中,每个传感器对应一个神经网络,无法充分发挥多传感器融合的优势,而且计算量大、耗时长。此外,如果多个任务简单地共享一个骨干网络,很容易导致每个任务难以同时获得优异的性能,如图3所示。
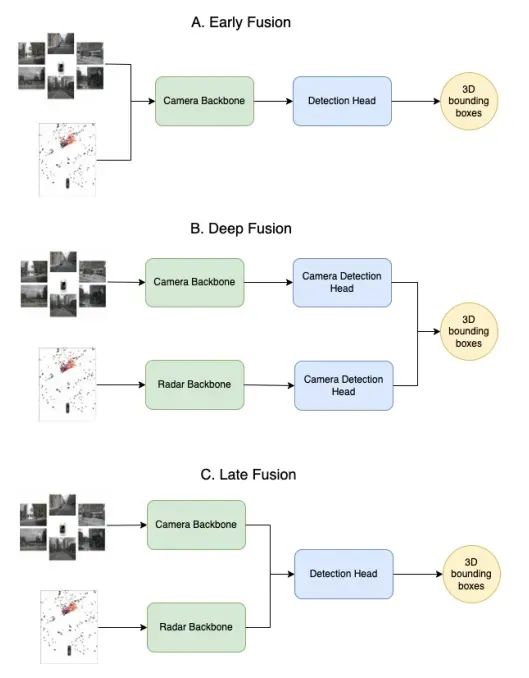
▲图3|一种多模态融合算法示意图
■3.1 BEV方案基本流程 ·简介 BEV(鸟瞰视图)模型
基于多个摄像头甚至不同传感器,可以被视为解决上述SLAM+DL第一代自动驾驶技术问题的潜在技术方案,本文将BEV+Transformer结合技术成为自动驾驶感知2.0时代。如图4所示,BEV以鸟瞰图视角呈现车辆信息,是自动驾驶系统中跨摄像头和多模态融合的体现。其核心思想是将传统的2D图像感知转为3D感知。对于BEV感知来说,关键在于将2D图像作为输入并输出3D感知帧,而如何在多摄像头视角下高效优雅地获得最佳特征表示仍是一个难题。
目前,基于多视角相机的BEV3D物体检测感知任务,受到越来越多的关注。如图5所示,在BEV视图下,统一和描述不同视角的信息是非常直观自然的,这为后续规划和控制模块的任务提供了便利。此外,BEV视图下的物体在2D视角下不存在遮挡和比例问题,有助于提高检测性能。BEV模型还有助于提高感知融合的性能,并通过统一的模型实现从纯视觉感知到多传感器融合解决方案的逻辑一致性,从而降低额外的开发成本。
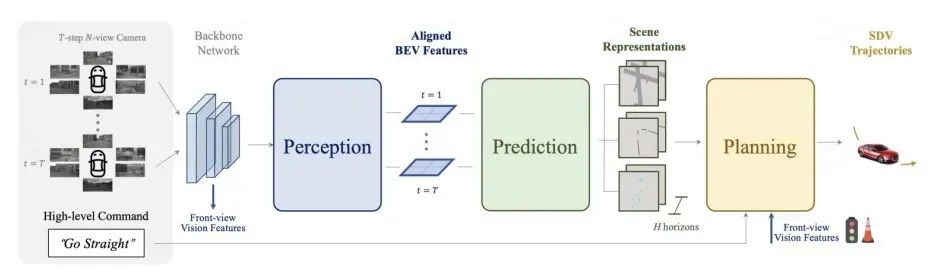
▲图5|纯视觉的端到端规划框架
· BEV技术方法 目前为止,BEV研究主要基于深度学习方法。根据BEV特征信息的组织方式,主流方法可分为不同架构的模式。
■3.2 自底向上 vs. 自顶向下
· 自底向上方法 自底向上法采用了从2D到3D的模式:
1)首先,在2D视图下估计每个像素的深度信息,然后基于相机内外参数将图像映射到BEV空间。
2)然后,通过融合多个视图生成BEV特征。
这种方法的早期代表方法是LSS(Lift、Splat、Shoot),如图6所示,它构建了一个简单而有效的处理过程:
1)将2D相机图像投射到3D场景中;
2)然后从上帝视角把得到的3D场景“压扁”,形成BEV视图。
平面场景符合人们对地图的直观感觉,虽然已经获得了三维场景数据,但并不是完整的三维数据,因为从 BEV 的角度来看,无法获得准确的三维高度信息,所以需要将其扁平化。自下而上法的核心步骤是:
1)拉升----在对每幅相机图像进行图像平面下采样后,准确估计特征点的深度分布,并获得包含图像特征的视锥(点云);
2)拍打----结合摄像机的内部和外部参数,将所有摄像机的视锥(点云)分布到 BEV 网格中,并对每个网格中的多个视锥点进行求和汇集计算,形成BEV 特征图;
3)拍摄----使用任务头处理 BEV 特征图,输出感知结果。
LSS 和 BEVDepth等算法基于 LSS 框架进行了优化,是 BEV 算法的经典之作。 · 自顶向下方法 自顶向下法采用了从3D到2D的模式:
1)这类方法首先初始化BEV空间中的特征;
2)然后通过一个多层的Transformer与每个图像特征进行交互,得到与之对应的BEV特征。
Transformer 是谷歌在 2017 年提出的一种基于注意力机制的神经网络模型。与传统的 RNN 和 CNN 不同,Transformer 通过注意力机制挖掘序列中不同元素之间的联系和关联,从而适应不同长度和结构的输入。Transformer 首先在自然语言处理(NLP)领域取得了巨大成功,随后被应用于计算机视觉(CV)任务,并取得了显著效果。 这种自顶向下的方法逆转了 BEV 的构建过程,利用 Transformer 的全局感知能力从多个透视图像的特征中查询相应信息,并将这些信息融合和更新到BEV 特征图中。特斯拉在其 FSD Beta 软件视觉感知模块中采用了这种自上而下的方法,并在特斯拉 AI-Day上展示了有关 BEVFormer的更多技术理念。
■3.3 纯视觉还是多传感器融合?
BEV 目前已经是自动驾驶领域一个庞大的算法家族,包括不同方向的算法选择。其中,以视觉感知为主的流派由特斯拉主导,核心算法建立在多个摄像头上。另一大流派是融合派,利用激光雷达、毫米波雷达和多个摄像头进行感知。许多自动驾驶公司都采用了融合式算法,谷歌的 Waymo 也是如此。从输入信号的角度来看,BEV 可分为视觉流派和激光雷达流派。
· BEV相机
BEV 相机指的是基于多个视角的图像序列,算法需要将这些视角转换为 BEV 特征并对其进行感知,例如输出物体的三维检测帧或在俯视图下进行语义分割。与激光雷达相比,视觉感知具有更丰富的语义信息,但缺乏精确的深度测量。此外,BEV 的 DNN 模型需要在训练阶段指出照片中的每个物体是什么,并在标注数据上标注各种物体。如果遇到训练集中没有的物体类型,或者模型表现不佳,就会出现问题。 为了解决这个问题,Occupancy Network改变了感知策略,不再强调分类,而是关注道路上是否有障碍物。这种障碍物可以用三维积木来表示,有些地方称之为体素(voxel)。这种方法更为贴切,无论障碍物的具体类型如何,都能保证不撞击障碍物。 特斯拉正在经历从 BEV 技术(鸟瞰图)到新技术--occupancy network(占用网络)的过渡,从二维到三维。无论是二维还是三维,它们都致力于描述车辆周围空间的占用情况,但使用的表示方法不同。在二维 BEV 中,我们使用类似棋盘的方法来表达环境中的占用情况;而在三维占用网络中,它们使用类似积木的体素来表达。 具体来说,在 BEV 技术中,深度学习模型(DNN)通过概率来衡量不同位置的占用率,通常将物体分为两类:
1)不经常变化的物体,如车辆可通过区域(Driveable)、路面(Road )、车道(Lane)、建筑物(Building)、植被(Foliage/Vegetation)、停车区域(Parking)、信号灯(TrafficLight)以及一些未分类的静态物体(Static),这些类别可以相互包含。
2)另一类是可变物体,即会移动的物体,如行人(Pedestrian)、汽车(Car)、卡车(Truck)、锥形交通标志/安全桶(TrafficCone)等。
这种分类的目的是帮助自动驾驶系统进行后续的驾驶规划和控制。在BEV的感知阶段,算法根据物体出现在网格上的概率进行打分,并通过Softmax函数对概率进行归一化处理,最后选择概率最高的物体类型对应的网格作为占据网格的预测结果。
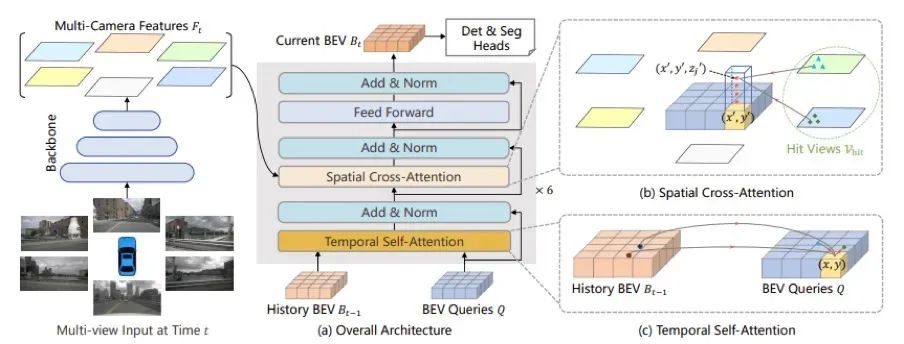
▲图7|BEVFormer流程
BEVFormer的详细流程如下:
1)使用基干和脖颈模块(使用 ResNet-101-DCN + FPN)从环视图像中提取多尺度特征。
2)编码器模块(包括时间自注意力模块和空间交叉注意力模块)使用本文提出的方法将环视图像特征转换为 BEV 特征。
3)与可变形 DETR 的解码器模块类似,它完成三维物体检测的分类和定位任务。
4)使用匈牙利匹配算法定义正负样本,并使用 Focal Loss + L1 Loss 作为总损失来优化网络参数。
5)计算损失时使用 Focal Loss 分类损失和 L1 Loss 回归损失,然后执行反向传播并更新网络模型参数。
在算法创新方面,BEVFormer 采用 Transformer 和时间结构来聚合时空信息。它利用预定义的网格状 BEV 查询与空间/时间特征进行交互,以查找和聚合时空信息。这种方法能有效捕捉三维场景中物体的时空关系,并生成更强大的表征。这些创新使 BEVFormer 能够更好地处理环境中的物体检测和场景理解任务。 · BEV融合
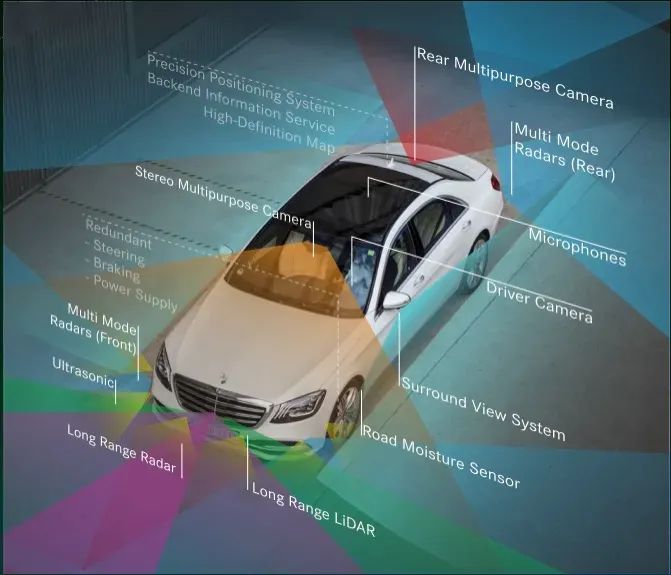
▲图8|奔驰智能驾驶配备的传感器套件
BEV 融合学派在自动驾驶领域的主要任务是融合各种传感器的数据,如图 8所示,包括摄像头、激光雷达、GNSS(全球导航卫星系统)、里程表、高精度地图(HD-Map)、CAN总线等。这种融合机制可以充分利用各个传感器的优势,提高自动驾驶系统对周围环境的感知和理解能力。 除了摄像头,融合学派还关注激光雷达的数据。与毫米波雷达相比,激光雷达的数据质量更高,因此毫米波雷达逐渐退出了主要用途,在一些车辆中继续充当停车雷达。
然而,毫米波雷达仍有其独特的价值,尤其是在自动驾驶领域技术日新月异的背景下。新算法可能会让毫米波雷达重新发挥作用。 激光雷达的优势在于可以直接测量物体的距离,其精度远高于视觉推测的场景深度。激光雷达通常将测量结果转化为深度数据或点云,这两种数据形式的应用历史悠久,成熟的算法可以直接借鉴,从而减少开发工作量。此外,激光雷达在夜间或恶劣天气条件下仍能正常工作,而相机在这种情况下可能会受到很大影响,导致无法准确感知周围环境。 总之,融合学派的目标是有效整合多传感器数据,使自动驾驶系统在各种复杂条件下获得更全面、更准确的环境感知,从而提高驾驶的安全性和可靠性。融合技术在自动驾驶领域发挥着关键作用。它融合了来自不同传感器的信息,使整个系统能更好地感知和理解周围环境,做出更准确的决策和计划。
■4.1 为什么是BEV感知?
首先,自动驾驶是一个 3D 或 BEV 感知问题。使用 BEV 视角可以提供更全面的场景信息,帮助车辆感知周围环境并做出准确决策。在传统的二维视角中,由于透视效应,物体可能会出现遮挡和比例问题,而 BEV 视角可以有效解决这些问题。 与以往自动驾驶领域基于正视图或透视图进行检测、分割、跟踪等任务的大多数模型相比,BEV 表示法能使模型更好地识别遮挡的车辆,有利于后续模块(如预测、规划控制)的开发和部署。同时,它还能将二维图像特征精确转换为三维特征,并能将提取的 BEV 特征应用于不同的探测头。 另一个重要原因是促进多模态融合。自动驾驶系统通常使用多种传感器,如摄像头、激光雷达、毫米波雷达等。BEV视角可以将不同传感器的数据统一表达在同一平面上,这使得传感器数据的融合和处理更加方便。在现有技术中,将单视角检测扩展到多视角检测是不可行的。 这是因为单视角检测器只能处理单个摄像头的图像数据,而在多视角的情况下,检测结果需要根据相应摄像头的内外部参数进行转换,才能完成多视角检测。然而,这种简单的后处理方法无法用于数据驱动训练,因为变换是单向的,无法反向区分不同特征的坐标系原点。这使得我们无法轻松地使用端到端训练模型来改进自动感知系统。为了解决这些问题,基于变换器的 BEV 感知技术应运而生。 总之,对于摄像头的感知而言,转向 BEV 将大有裨益:
1)直接在 BEV 中执行摄像头感知可直接与雷达或激光雷达等其他模式的感知结果相结合,因为它们已在 BEV中表示和使用。BEV 空间中的感知结果也很容易被预测和规划等下游组件使用。
2)纯粹通过手工创建的规则将 2D 观察结果提升到 3D 是不可扩展的。BEV 表示法有助于向早期融合管道过渡,使融合过程完全由数据驱动。
3)在没有雷达或激光雷达的纯视觉系统中,通过BEV 执行感知任务几乎是强制的,因为在传感器融合中没有其他三维线索可用于执行这种视图转换。之所以选择从 BEV 的角度进行感知,是为了提高感知的准确性和稳定性,并为多模态融合和端到端优化创造条件,从而推动自动驾驶技术的发展。
■4.2 为什么是BEV+Transformer?
为什么 "BEV+Transformer "会成为主流模式?其背后的关键在于 "第一原则",即智能驾驶应该越来越接近 "像人一样驾驶",而映射到感知模型本身,BEV 是一种更自然的表达方式,由于全局注意力机制,变形器更适合进行视图转换。目标域中的每个位置访问源域中任何位置的距离都是相同的,克服了 CNN 中卷积层感受野的局部局限性。此外,与传统的 CNN 相比,视觉转换器还有几个优势:更好的可解释性和更好的灵活性。随着产学研的推进,BEV+Transformer 最近已从普及走向量产,这在当前智能驾驶的商业颠覆背景下或许是一个难得的亮点。
1. 数据采集和预处理 BEV 透视需要进行大量的数据采集和预处理,这对场景感知的性能和效果有着重要影响。其中,需要解决多相机图像融合、数据对齐、畸变校正等问题。同时,变换器需要海量数据,如何获取高质量的海量数据也是一个重要的研究课题。 2. Transformer是暴力美学,模型体积惊人,其计算会消耗大量的存储和带宽空间。对于芯片而言,除了相应的运算器适配和底层软件优化外,还需要对缓存和带宽进行优化,要求也随之提高。与此同时,还需要对模型进行优化。
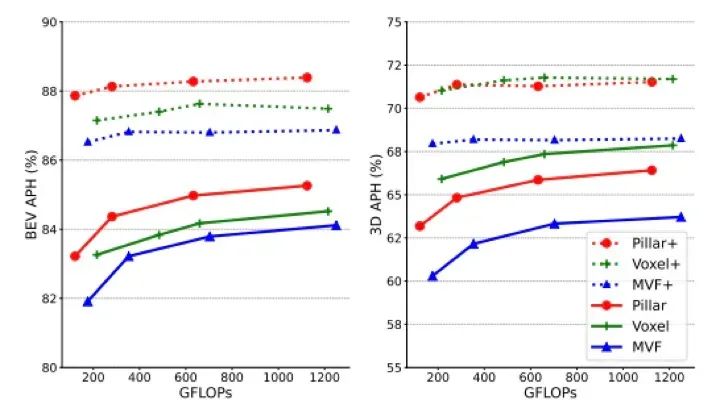
▲图9|模型优化性能对比图
3. 更多传感器融合: 目前,BEV 透视技术主要使用激光雷达和摄像头等传感器进行数据采集和处理,但仍需要更多传感器的融合,如图10所示的毫米波雷达、GPS等,以提高数据的准确性和全面性。
▲图10|更多的传感器数据融合
4. 稳健优化:BEV 在复杂环境中的应用面临诸多挑战,如天气变化、光照变化、目标遮挡、对抗性攻击等。未来有必要加强算法的鲁棒优化,以提高系统的稳定性和可靠性。
5. 应用场景更多:BEV 技术的应用场景非常广泛,包括自动驾驶、智能交通、物流配送、城市规划等领域,如图12中的机器人。自动驾驶与 BEV 的融合可以提供全方位的场景信息,有利于车辆准确感知周围的物体和环境,实现高效、安全的自动驾驶。BEV视角下的智能交通可以提供更直观、更全面的路况信息,有利于实现高效的路况监测和交通管理,提高城市交通的效率和安全性。物流配送与 BEV 的结合可以提供更准确、更全面的货物位置和空间信息,有利于实现高效的物流配送,提高物流效率和服务质量。未来,应用领域还可以进一步拓展,如农业、矿业等领域,满足不同领域的需求。
▲图12|BEV在机器人领域中的应用
总结
从行业发展趋势来看,BEV 模式及其应用或将成为主流趋势。这意味着从芯片开始,传感器芯片、摄像头、软件算法等都需要快速适应,快速实现解决方案。 综上所述,BEV 是继深度学习之后的又一新高度,它解决了以往多传感器变化和异构带来的各种融合感知算法的发展难题。从原理上讲,与传统的感知算法相比,BEV 的输入相同,都是多通道传感器信息,最后直接输出三维空间规划和控制所需的输出形式。BEV 基于二维数据,提供鸟瞰视角,与 SLAM 相辅相成,为自动驾驶的发展和实现带来了更多可能。随着技术的不断进步,感知模块也将不断发展,更高效、更精准的感知技术将推动自动驾驶技术走向更广阔的未来,为人类社会的进步贡献更多价值。
审核编辑:黄飞














 工商网监
工商网监
评论