 电子发烧友App
电子发烧友App


今年4月底,中国工程院院士徐匡迪等多位院士的发声,直击我国在算法这一核心技术上的缺失,引发业界共鸣,被称为“徐匡迪之问”。
由此,“依靠开源代码和算法是否足够支撑人工智能产业发展?”、“为什么要有自己的底层框架和核心算法?”等一系列问题,成为行业热议的话题。
事实上,除了核心算法之外,对底层框架的忽视,也成为影响我国人工智能发展的重要因素,甚至比“缺芯少魂”、“卡脖子”问题更危险!
然而,想要理清其中的缘由,就需要从读懂机器学习开始。
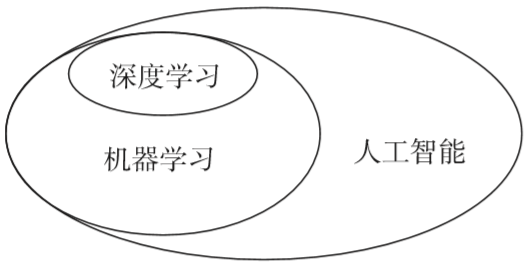
什么是机器学习?
众所周知,AI的根本目的就是让计算机模拟人类的行为和思维,以实现解放人力,提升效率,降低成本。其中,机器学习(Machine Learning)则是AI的智慧源泉。
从学术上来说,机器学习涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多领域交叉的课题和技术。
从广义上来说,机器学习就是赋予计算机学习能力,并实现模仿人类的一种方法。
从技术应用上来说,机器学习是利用大量数据,训练出专用的算法模型,然后通过该模型实现类似人的预测、推理,从而获取决策的方法。
从层级上来说,机器学习位于AI的技术层,与其他技术的相融合,构成了计算机视觉、智能语音、模式识别、数据挖掘、统计学习等AI核心技术,并在应用层得以体现。
从AI发展来看,几乎所有核心技术和应用场景的背后,都离不开机器学习所赋予的学习能力,也就是智能。
总之,机器学习既是人工智能的核心,也是计算机获得学习能力和智力的方法或途径。
而机器学习的核心则是算法。
深度学习算法与底层框架
作为AI大三元素(数据、算力、算法),目前主流的算法主要面向机器学习领域。因此,机器学习也可以理解为用于训练和推理的算法合集。
目前,机器学习算法可以分为传统算法和深度学习(Deep Learning)算法两大类。
深度学习是机器学习中一个新兴的研究方向,也是一个复杂的机器学习算法。深度学习的概念源于人工神经网络的研究,建立模拟人脑进行分析学习的神经网络,以模仿人脑的机制来解释数据,强调模型结构的深度和明确特征学习的重要性。
因此,深度学习使计算机实现模仿视听和思考等人类的活动,解决了大量复杂的模式识别难题,从而推动计算机视觉、智能语音等复杂AI基础技术的落地。
可以说,深度学习算法决定了未来AI的发展趋势,乃是兵家必争之地。
现在,全球AI领域,深度学习已经超越传统机器学习,成为主流算法。但是,机器学习仍未被取代,两者呈现互补的态势。随着深度学习与神经网络算法的结合,不仅降低了算法训练的门槛,更衍生出大量热门算法以及相应的底层构架。
与依赖于芯片的算力不同,算法由于开源代码、自动化工具等助力,门槛相对降低不少,因而成为初创公司不错的切入点。现在,大多AI企业基本都是围绕算法及相应的应用场景做文章,在国内尤为普遍。
然而,这些基于开源代码和自动化工具的算法往往过于通用和初级,仅仅依托国内海量数据储备和丰富的应用场景的优势,实现最基本的功能而已。真正核心和关键算法仍然掌握在国外大厂手中,核心竞争力明显不足。
而且,不仅是核心算法,深度学习的底层框架也同样来自于国外厂商。
底层框架,一般被称作为开源框架或算法训练平台。通俗来说,就是AI工具包,其作用就是用以训练算法模型的平台。
如果将算法比作“子弹”的话,底层框架就是“军工厂”,重要性不言而喻。
仅仅是算法的缺失,可以通过企业、开发者及整个行业的共同努力来弥补,但连工具都被“卡脖子”的话,显然将大大制约我国深度学习,乃至整个AI产业的发展。
外来的和尚好念经
目前,主流的深度学习底层框架虽然大多已经开源,但基本都来自于美国科技巨头及大学相关实验室,例如TensorFlow(谷歌)、PyTorch(Facebook)、MXNet(亚马逊)、CNTK(微软)、Deeplearning4j(美国AI初创公司Skymind)、Theano(蒙特利尔理工学院)、Caffe(加州大学伯克利/贾扬清开发)、Keras(谷歌工程师FrançoisChollet开发)等等。
其中, TensorFlow和PyTorch应用最为广泛,全球AI企业都将其视为重要的工具包。据TensorFlow网站显示,京东、中国移动、美团、搜狗等中国企业都在使用该框架,用于深度学习的应用和开发。
任何企业和开发者都可以将数据馈入其中,并开始训练自己的算法模型,无需重头开始自行开发底层框架和开发平台,所谓 “站在巨人的肩膀”。
谷歌、Facebook、亚马逊、微软也在不遗余力地投入,对这些底层框架进行维护、升级和推广,以确保其受到全球开发者的欢迎。根本目的就是建立统一的标准和规范,进而形成完整的生态。最简单的例子就是谷歌的安卓操作系统,虽为开源,但也形成了技术壁垒,让其他厂商难以逾越。
同时,大量企业和开发者也在为这些开源构架默默地做着贡献,从而推动其不断壮大。从另一个层面来说,尽管底层框架均为开源、免费,但获得全球开发者助力的同时,也省去了建立国际性开发团队的巨额成本。
其实,国内巨头已经意识到了这个问题。BAT、华为、商汤、旷视、360以及浪潮等厂商都已经推出了各自的机器学习底层框架。
尤其是百度飞桨(Paddle Paddle)自2016年开源起,一直在不断升级和推广,以吸引更多的企业和开发者的关注。2017年,腾讯Angel、360 Xlearning先后宣布开源。2018年年底,阿里x-deeplearning也正式开源。今年8月,华为推出了MindSpore深度学习框架,并将在2020年第一季度开源。此外,包括商汤、旷视、浪潮等厂商虽然已经拥有自己的底层构架,但遗憾的是并没有开源。
最近,小米宣布语音识别开源工具Kaldi 之父DanielPovey将出任语音首席科学家,很可能会加大相关底层构架的研发。
尽管中国厂商已经拥有了自研底层框架的实力,但在先入为主的国外开源构架面前,不仅用户量不足,而且缺乏贡献者,更有过于封闭的问题,因此底层构架的国产化可谓路漫漫。
如何突围?
随着国内自研AI芯片成为全新的风潮,让人看到了突破芯片“卡脖子”,实现“弯道超车”的可能。
即便如此,现在中国AI基础研究和基础设施仍然相当薄弱,包括硬件在内的大量核心技术掌控在美国手中,更随时面临“技术封锁”和“断供”的风险。
同样的情况也发生在深度学习领域,核心算法和底层构架的缺失,一旦风险爆发,将对中国AI发展带来致命影响。
从国外厂商在AI领域的布局来看,无论是云计算、芯片,还是算法和底层框架,均以构建自己的生态为根本目的,从而建立起牢不可破的“护城河”。
好在,阿里、百度、华为等国内巨头已经从各个角度开展布局,阿里平头哥“含光800”、华为麒麟系列芯片、鸿蒙操作系统以及百度飞桨等都是典型的代表。其中,今年7月,百度宣布飞桨与华为麒麟展开合作,芯片与底层构架的联手,无疑将共同推动中国深度学习和AI产业的落地和发展。相信这也是建立中国力量生态圈最好范例。
此外,建立和推动开源文化,也是摆在中国企业面前的老生常谈的问题。唯有拥抱开放、共享,才能真正推动中国核心技术,尤其是AI技术的快速进步和发展,从而突破“卡脖子”封锁。
目前,国内深度学习厂商主要分为云计算平台、AI初创企业、传统计算厂商以及大数据企业多个阵营。其中,云计算平台主要是BAT、华为、京东等互联网巨头为首;AI初创企业主要有第四范式、商汤、旷视、寒武纪等;浪潮、中科曙光等则发挥自身计算优势,占有一席之地;星环科技、美林数据、九章云极等大数据企业拥有数据挖掘的优势,也成为生态中不可获取的力量。
由此可知,除了AI本身之外,深度学习、机器学习与云、计算、数据等关键技术密不可分,这也恰恰证实了国内海量数据储备和互联网基础设施建设对AI行业起到的推动作用。然而,正如上文所述,唯有掌控核心算法和底层框架,拥有基础设施和核心技术的自研能力,才能真正主导深度学习及机器学习行业。
总之,就连机器学习、深度学习这样的AI工具包都一直掌控在美国手中,无疑比芯片、操作系统等核心技术的“卡脖子”问题更危险!














 工商网监
工商网监
评论