,在实践操作中往往涉及多方人员,其结果对开源项目发展影响深远,因此,开源指南针的愿景是:通过开源指南针, 我们帮助需要对社区进行数据分析的人。包括但不限于 OSPOs、社区管理人员、学术研究人员、项目
2023-02-17 16:15:44
据英国《每日邮报》6月25日报道,研究人员发现,在面部数量达百万级的测试中,饱受争议的面部识别技术并不像声称地那么准确。 人工智能可以在数千张面孔中识别出你的面孔,准确率近乎百分之百,,但当其
2016-06-28 14:10:07
,和大津法,这一章介绍图像边界提取。这里我的算法是基于逐飞开源的灰度图算法写的,但也在上面改进了许多,使得边界的搜取不会出现丢边。一、灰度边界提取的原理 在我们获取摄像头的数据后,返回回来的是0-255的灰度值。...
2022-01-14 08:27:39
PID的智能车控制算法研究
2016-07-18 20:07:41
STM32 Foc开源算法,包括观测器和Foc method STM32F0系列FOC 源代码,有单电阻采样和三电阻采样两种代码。都是ST很经典算法,代码学习,无感算法观测器是开源代码,Foc method也是开源,不是库。...
2021-09-06 08:09:03
编译在Cortex-A9嵌入式平构建了强化信息安全嵌入式Linux家庭服务器;组建以ZigBee为基础的智能家居控制通信网络,采用MAC地址过滤技术的白名单设备入网机制、SMS4-CCM算法、入侵安全
2015-12-02 16:12:36
是实现人工智能的一个途径,即以机器学习为手段解决人工智能中的问题。1.在维基百科中,机器学习有下面几种定义:机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法
2017-06-23 13:51:15
多智能体系统深度强化学习:挑战、解决方案和应用的回顾摘要介绍背景:强化学习前提贝尔曼方程RL方法深度强化学习:单智能体深度Q网络DQN变体深度强化学习:多智能体挑战与解决方案MADRL应用结论和研究
2021-07-12 08:44:43
斯坦福大学与赛灵思研究实验室(Xilinx Research Labs)联手开发专门面向研究社群的第二代高速网络设计平台 NetFPGA-10G。该新型平台采用最先进的技术,能够帮助研究人员迅速构建
2019-08-27 08:30:57
关键字: 太阳能电池 玻璃纤维 光纤 来自日本的研究人员开发出一种“纤维状无TCO染料敏化太阳电池
2009-04-14 14:23:10
有没有搞机器学习、人工智能相关的算法研究的啊?自己一个人搞感觉挺难的,希望找到志同道合的朋友,相互探讨。
2016-02-26 09:56:00
如题,希望找到一些同样研究机器学习,人工智能算法研究的朋友,相互探讨,共同进步。自己一个人搞感觉挺难的,希望可以一起讨论,跟贴联系。
2016-02-26 09:58:54
通过使用基于光子的THz电路来桥接光纤和无线电的世界,以实现超高数据速率。但是,不管要实现什么样的系统,信号复用和解复用系统(复用器/解复用器)都是基本要求。研究人员使用两个平行的金属板的波导系统,把
2018-08-31 15:58:59
测试)三、主讲内容1:课程一、强化学习简介课程二、强化学习基础课程三、深度强化学习基础课程四、多智能体深度强化学习课程五、多任务深度强化学习课程六、强化学习应用课程七、仿真实验课程八、辅助课程四、主讲
2021-01-10 13:42:26
发现硅压阻式压力传感器系统设计和制造工艺缺陷是解决上述问题的根本。但是,MEMS器件可靠性标准的缺乏和研究人员对MEMS器件的可靠性研究不足, 限制了它的使用,以及可靠性的提高。因此, 为保证产品在
2018-11-05 15:37:57
据物理学家组织网报道,美国普渡大学和哈佛大学的研究人员推出了一项极为应景的新发明:一种外形如同一颗圣诞树一样的新型晶体管,其重要组件“门”(栅极)的长度缩减到了突破性的20纳米。这个被称为“4维
2013-02-03 20:30:28
数字图像处理原理是什么?简单Ferret算法原理是什么?改进的Ferret算法原理有哪些步骤?改进的Ferret算法和目前常用的测量算法有哪些不同?
2021-04-15 06:58:37
求:BP算法改进的matlab代码,改进算法思想:1、自适应调整学习率2、自适应调整动量因子3、自适应调整允许误差谢谢各位高手!
2013-05-20 17:19:23
职位描述:1. 负责计算机视觉&机器学习(包括深度学习)算法的开发与性能提升,负责下述研究课题中的一项或多项,包括但不限于:人脸识别、检测、活体、跟踪、分类、语义分割、深度估计、图像处理
2017-12-07 14:34:41
文中先对BP 算法进行了分析,然后针对标准BP 算法的不足进行了改进,通过对作用函数进行修正、自动调节学习率以及选择初始权值后得到了改进的BP 算法,并给出了在车牌识别
2010-01-22 16:06:28 0
0 人员闯入入侵徘徊识别算法系统借助智能视频分析技术和YOLO深度学习技术的支持,能够对现场监控摄像机获取的视频进行实时分析和处理。系统根据预先设定的禁止入内地区,通过现场监测摄像机可以准确地监测人员靠近或闯入禁止区域的情况。一旦发现异常情况,系统立即触发警报,并即时将相关信息通知给工地管理者。
2023-12-11 14:50:52
法国研究人员开发出新型智能晶体管
法国研究人员最新开发出一种新型智能晶体管,它能够模仿神经系统的运行模式,对图像进行识别,帮助电脑完成更加复
2010-01-27 10:43:27 442
442 本内容提出了音乐旋律匹配算法的改进研究,希望对大家学习上有所帮助
2011-05-26 15:56:1647 美国研究人员日前开发出一种新型“自旋极化”OLED技术,改进后的OLED与普通LED相比具有更多的优点。
2012-07-20 09:28:561046 改进的多电平SVPWM及其广义算法研究。
2016-04-15 18:06:157 基于非正交坐标系下的SVPWM改进算法研究
2016-04-19 14:10:447 基于改进蚁群算法的云计算任务调度研究_张海玉
2017-01-08 14:47:534 改进的PCA算法在人脸识别中的应用研究_周亦敏
2017-03-19 11:30:430 与监督机器学习不同,在强化学习中,研究人员通过让一个代理与环境交互来训练模型。当代理的行为产生期望的结果时,它得到正反馈。例如,代理人获得一个点数或赢得一场比赛的奖励。简单地说,研究人员加强了代理人的良好行为。
2018-07-13 09:33:0024321 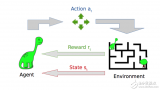
深度强化学习DRL自提出以来, 已在理论和应用方面均取得了显著的成果。尤其是谷歌DeepMind团队基于深度强化学习DRL研发的AlphaGo,将深度强化学习DRL成推上新的热点和高度,成为人工智能历史上一个新的里程碑。因此,深度强化学习DRL非常值得研究。
2018-06-29 18:36:0027596 在本篇论文中,研究人员使用流行的异步进化算法(asynchronous evolutionary algorithm)的正则化版本,并将其与非正则化的形式以及强化学习方法进行比较。
2018-02-09 14:47:413454 
巴西研究人员设计了一款微型光谱仪,可集成于无人机、智能手机及用于化学化合物探测和温室气体远程监控等设备
2018-05-18 11:53:001545 传统上,强化学习在人工智能领域占据着一个合适的地位。但强化学习在过去几年已开始在很多人工智能计划中发挥更大的作用。
2018-03-03 14:16:563924 强化学习是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大,强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价
2018-05-30 06:53:001234 为了达到人类学习的速率,斯坦福的研究人员们提出了一种基于目标的策略强化学习方法——SOORL,把重点放在对策略的探索和模型选择上。
2018-06-06 11:18:234988 
Q Learning算法是由Watkins于1989年在其博士论文中提出,是强化学习发展的里程碑,也是目前应用最为广泛的强化学习算法。
2018-07-05 14:10:003368 这些具有一定难度的任务 OpenAI 自己也在研究,他们认为这是深度强化学习发展到新时代之后可以作为新标杆的算法测试任务,而且也欢迎其它机构与学校的研究人员一同研究这些任务,把深度强化学习的表现推上新的台阶。
2018-08-03 14:27:264305 强化学习作为一种常用的训练智能体的方法,能够完成很多复杂的任务。在强化学习中,智能体的策略是通过将奖励函数最大化训练的。奖励在智能体之外,各个环境中的奖励各不相同。深度学习的成功大多是有密集并且有效的奖励函数,例如电子游戏中不断增加的“分数”。
2018-08-18 11:38:573363 物联网安全研究人员渗透进了某智能灯泡,获取到了Mesh网络内传输的WiFi信息(包括WiFi密码)。尽管在该案例中WiFi密码被加密,但是研究人员依然通过获取设备的底层固件,得到了加密算法和密钥信息
2018-08-21 10:57:541366 研究人员借助人工智能(AI)可以基本确定被观察对象是否属于神经质、友好、外向、认真和好奇等性格特征。
2018-08-23 17:39:132662 对于新的研究人员来说,能够根据既定方法快速对其想法进行基准测试非常重要。因此,我们为 Arcade 学习环境支持的 60 个游戏提供四个智能体的完整培训数据,可用作 Python pickle 文件
2018-08-31 10:55:304646 艾伦人工智能研究所和华盛顿大学的研究人员正在使用可以根据上下文来确定英文单词含义的神经网络。
2018-09-12 15:52:142014 按照以往的做法,如果研究人员要用强化学习算法对奖励进行剪枝,以此克服奖励范围各不相同的问题,他们首先会把大的奖励设为+1,小的奖励为-1,然后对预期奖励做归一化处理。虽然这种做法易于学习,但它也改变了智能体的目标。
2018-09-16 09:32:035336 日前,据外媒报道,Deezer的研究人员已经成功开发出能识别歌曲中情绪的人工智能。
2018-09-29 10:10:09880 在德国北极科考营地,研究人员试种西红柿、黄瓜、大头菜等多种蔬菜获得成功。
2018-10-04 08:43:002629 研究人员挑选出各个器官(包括脑、心脏、胰腺和胸腺等)的细胞,然后开展单细胞RNA测序,以获取每个细胞的转录组。研究人员指出,FACS方法和微流体方法在大量基因表达谱上基本一致。
2018-10-11 11:08:404528 之前接触的强化学习算法都是单个智能体的强化学习算法,但是也有很多重要的应用场景牵涉到多个智能体之间的交互。
2018-11-02 16:18:1521017 11月1日,Facebook开源了Horizon,一个由Facebook的AI研究人员、推荐系统专家和工程师共同搭建的强化学习平台,其框架的构建工作开始于两年半前,在过去一年中一直被Facebook内部使用。
2018-11-05 09:34:17722 OpenAI 近期发布了一个新的训练环境 CoinRun,它提供了一个度量智能体将其学习经验活学活用到新情况的能力指标,而且还可以解决一项长期存在于强化学习中的疑难问题——即使是广受赞誉的强化算法在训练过程中也总是没有运用监督学习的技术。
2019-01-01 09:22:002122 
研究中的研究人员使用增强现实技术来改变主动感知行为与其产生的感官反馈之间的联系,并更多地了解该过程的工作原理。
2018-12-29 15:11:312774 人工智能系统,使机器人具备了像人类一样灵巧地掌握和操纵物体的能力,现在,研究人员表示,他们已经开发出一种算法,通过这种算法,机器可能学会独立行走。来自加州大学伯克利分校和其中之一的谷歌人工智能研究
2019-01-03 10:08:52829 在谷歌最新的论文中,研究人员提出了“非政策强化学习”算法OPC,它是强化学习的一种变体,它能够评估哪种机器学习模型将产生最好的结果。
2019-06-22 11:16:292280 在谷歌最新的论文中,研究人员提出了“非政策强化学习”算法OPC,它是强化学习的一种变体,它能够评估哪种机器学习模型将产生最好的结果。数据显示,OPC比基线机器学习算法有着显著的提高,更加稳健可靠。
2019-06-22 11:17:083374 这一研究的目标是通过单张图像输入,对图像中的物体进行检测、获取不同物体的类别、掩膜和对应的三维网格,并对真实世界中的复杂模型进行有效处理。在2D深度网络的基础上,研究人员改进并提出了新的架构。
2019-08-02 15:51:223558 
研究人员创建了一个自动图像分析系统,旨在改善无法负担Pap测试和其他诊断工具的国家中子宫颈癌的筛查。
2019-10-23 09:31:58586 近日,滑铁卢大学研究人员开发了一种新的人工智能工具,该工具使用深度学习的AI算法来确定帖子中的故事是否得到同一主题的其他帖子故事的支持,这可以帮助社交媒体网络和新闻机构鉴别并清除虚假新闻。
2019-12-17 16:09:153063 惰性是人类的天性,然而惰性能让人类无需过于复杂的练习就能学习某项技能,对于人工智能而言,是否可有基于惰性的快速学习的方法?本文提出一种懒惰强化学习(Lazy reinforcement learning, LRL) 算法。
2020-01-16 17:40:00745 研究人员第一次使用了一种称为双梳光谱的先进分析技术来快速获取极其详细的高光谱图像。
2020-03-04 09:12:46909 现在,在研究人员开发出一种称为“黑暗仿真器”的人工智能工具后,可以在几秒钟内研究宇宙如何产生其空隙和细丝。
2020-03-06 10:16:21646 近年来随着强化学习的发展,使得智能体选择恰当行为以实现目标的能力得到迅速地提升。目前研究领域主要使用两种方法:一种是无模型(model-free)的强化学习方法,通过试错的方式来学习预测成功的行为
2020-03-26 11:41:121801 苏黎世联邦理工学院的研究人员最近推出了一种新的基于深度学习的策略,该策略可以在不需要大量真实数据的情况下在机器人中实现触觉传感。在arXiv上预先发表的一篇论文中概述了他们的方法,该方法需要完全在模拟数据上训练深度神经网络。
2020-03-26 15:47:562388 根据 Nature 杂志发表的一项研究,斯坦福大学研究人员开发了一种机器学习方法,能够实现早期肺癌患者的鉴别筛查。
2020-03-27 16:06:04674 来自剑桥大学和纽卡斯尔大学的研究人员设计了一种新的方法,通过向电池发送电脉冲并测量其响应来监测电池。然后,他们利用机器学习算法对测量数据进行处理,以预测电池的健康状况和使用寿命。
2020-04-09 11:18:221021 预计COVID-19研究人员将开始使用人工智能(AI)和机器学习来挖掘有关COVID-19的新线索和新见解。
2020-04-15 10:48:32684 强化学习(RL)是现代人工智能领域中最热门的研究主题之一,其普及度还在不断增长。 让我们看一下开始学习RL需要了解的5件事。
2020-05-04 18:14:003117 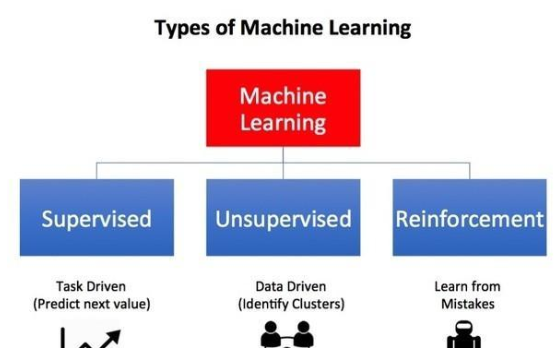
在过去的几年中,Microsoft深度学习研究人员在开发算法方面达到了人类同等的里程碑,该算法的性能与研究基准一样好,可以测试会话语音识别,阅读理解,新闻文章翻译和其他具有挑战性的语言理解能力任务。现在,这些AI研究突破的好处正逐渐渗透到从Azure到Bing的产品中。
2020-04-20 15:28:111697 Facebook在一篇博文中表示,卡耐基梅隆大学的研究人员“不会与Facebook分享个人调查反馈,Facebook也不会与研究人员分享关于你是谁的信息。”该公司还表示,将通过其疾病预防地图计划(Disease Prevention Maps program),为流行病学家提供新的类别的数据。
2020-04-22 10:58:393142 研究人员开发了一种机器学习模型,该模型可以使机器人安全地治疗与神经退行性疾病相关的手部震颤。
2020-04-29 17:29:23812 这个由来自哈佛医学院,克利夫兰诊所,梅奥诊所等众多研究人员的研究人员组成的多机构团队对来自3,052名参与者的数据进行了AI训练。其中,1,531例患有癌症,1,521例没有。
2020-05-21 10:17:501791 由剑桥大学领导的研究人员设计了一种用于药物发现的机器学习算法,该算法的效率是工业标准的两倍,可以加快开发新的疾病治疗方法的进程。
2020-05-28 09:04:51563 尽管AI系统已取得长足进步,但它们仍然无法应对混沌或不可预测性。现在,研究人员想教授AI物理学以解决此类问题。
2020-06-30 16:47:361838 该算法背后的研究人员在波特兰的俄勒冈健康与科学大学工作。《自然新陈代谢》正在免费全面运行他们的发现
2020-07-03 10:46:411471 许多现代的AI系统都在神经网络上运行,而我们仅了解其基础知识,因为算法本身很少提供解释方式。缺乏解释性通常被称为AI系统的“黑匣子”。研究人员将注意力集中在神经网络如何工作的细节上
2020-07-14 16:31:561708 为了简化此过程,MDC的研究人员开发了一种通用的编程工具,该工具可将各种基因组数据转换为所需的格式,以供深度学习模型进行分析。
2020-07-16 14:47:461837 正如研究人员在AlphaZero项目中发现的那样,设计精良的深度学习模型在遇到定义明确、但又不受人类固有规则束缚的问题时,往往能够快速开辟出前所未有的解决思路。
2020-07-17 15:15:313317 Viet Nguyen就是其中一个。这位来自德国的程序员表示自己只玩到了第9个关卡。因此,他决定利用强化学习AI算法来帮他完成未通关的遗憾。
2020-07-29 09:30:162429 这项工作发表在《NPJ计算材料》上,是南卡罗来纳大学工程与计算机学院的研究人员与贵州大学(位于中国贵阳的研究型大学)的研究人员之间的合作。
2020-09-10 11:45:062049 Arm和PragmatIC的研究人员最近使用低成本的柔性芯片制造了机器学习(ML)处理引擎,该引擎可用于构建具有先进数据处理能力的各种智能设备。
2020-09-11 11:28:471920 此外,研究人员还对无负极电池进行测试,以评估其安全性。他们根据研究结果设计出的电解质可以优化电池性能,并将其寿命延长至充放电循环次数可达200次。研究人员表示,他们将继续进行研究,使无负极电池达到实际应用水平。
2020-09-12 09:37:252152 传感器应用韩国科学技术高等研究院(KAIST)研究人员提供了一种深度学习供电的单应变电子皮肤传感器,可以从远处捕获人体运动。 韩国科学技术高等研究院(KAIST)研究人员提供了一种深度学习供电
2020-09-22 14:28:311814 医疗技术应当对所有人都有所帮助,为了应对这一挑战,改善糖尿病视网膜病变筛查,人们已经做出了很多努力。Google AI的研究人员们就利用机器学习和计算机视觉领域的最新进展,开发了一种能够通过眼部扫描图像判断患者的视网膜是否发生了病变的深度学习算法。
2020-11-16 09:15:291647 南加州大学(USC)的Victor Martinez是AI研究的首席研究员该软件将于本月在2020年自然语言处理经验方法会议论文集上首次亮相。其他研究人员USC克里希纳包括和Somandepalli纳拉亚南Shrikanth
2020-11-23 15:10:301725 据外媒报道,美国加州大学洛杉矶分校(UCLA)、加州理工学院(Caltech)和福特汽车公司的一组研究人员改进了燃料电池技术,而且让该技术在效率、稳定性和功率方面都超过了美国能源部(DOE)设定的目标,而且目前还没有其他燃料电池同时在此类方面达到同样的里程碑。
2020-11-30 10:09:101980 加州大学伯克利分校的研究人员创造了一种设备,使用可穿戴传感器和人工智能软件来识别一个人打算做出什么手势。传感器和人工智能能够根据前臂的电信号模式来判断一个人打算做出的手势。研究人员表示,该设备为改进假肢控制和与电子设备的互动铺平了道路。
2020-12-23 11:27:541594 苏黎世ETH的研究人员首次通过将流体力学与人工智能相结合,成功地使湍流建模自动化。他们的项目依赖于在CSCSS超级计算机Piz Daint上通过湍流模拟进行扩增强化学习算法。
2021-01-07 10:46:225032 一个国际研究人员团队开发了一种用于光子处理器的新方法和体系结构,可加快机器学习领域的复杂数学任务。
2021-01-08 14:00:081695 我们这些凡人在国际象棋上已经很久没有真正与人工智能竞争了。距人类在国际象棋比赛中征服计算机已有15年了。但是,近日,一组研究人员开发了一种AI国际象棋engine,它的出现并不是打算碾压我们这些弱小
2021-02-23 09:38:581355 近日,两个由 OpenAI 的研究人员开发的一模一样的机械臂爱丽丝和鲍勃,可以在模拟情景中通过对弈互相学习,而不需要人为输入文本。
2021-02-23 10:40:311595 强化学习( Reinforcement learning,RL)作为机器学习领域中与监督学习、无监督学习并列的第三种学习范式,通过与环境进行交互来学习,最终将累积收益最大化。常用的强化学习算法分为
2021-04-08 11:41:5811 强化学习是人工智能领域中的一个研究热点。在求解强化学习问题时,传统的最小二乘法作为一类特殊的函数逼近学习方法,具有收敛速度快、充分利用样本数据的优势。通过对最小二乘时序差分算法
2021-04-23 15:03:035 一种新型的多智能体深度强化学习算法
2021-06-23 10:42:4736 基于改进SIFT和RANSAC图像拼接算法研究_马强(怎样测监控电源电流)-基于改进SIFT和RANSAC图像拼接算法研究_马强这是一份非常不错的资料,欢迎下载,希望对您有帮助!
2021-07-26 12:53:1512 定标记训练数据的情况下获得正确的输出 无监督学习(UL):关注在没有预先存在的标签的情况下发现数据中的模式 强化学习(RL) : 关注智能体在环境中如何采取行动以最大化累积奖励 通俗地说,强化学习类似于婴儿学习和发现世界,如果有奖励(正强化),婴儿可能会执行一个行
2022-12-20 14:00:02828 作者:Siddhartha Pramanik 来源:DeepHub IMBA 目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。这些算法
2023-02-03 20:15:06747 强化学习(RL)是人工智能的一个子领域,专注于决策过程。与其他形式的机器学习相比,强化学习模型通过与环境交互并以奖励或惩罚的形式接收反馈来学习。
2023-06-09 09:23:23355 的情况下获得正确的输出无监督学习(UL):关注在没有预先存在的标签的情况下发现数据中的模式强化学习(RL):关注智能体在环境中如何采取行动以最大化累积奖励通俗地说,强
2023-01-05 14:54:05419 
作者:SiddharthaPramanik来源:DeepHubIMBA目前流行的强化学习算法包括Q-learning、SARSA、DDPG、A2C、PPO、DQN和TRPO。这些算法已被用于在游戏
2023-02-06 15:06:38665 电子发烧友网站提供《人工智能强化学习开源分享.zip》资料免费下载
2023-06-20 09:27:281 摘要:基于强化学习的目标检测算法在检测过程中通常采用预定义搜索行为,其产生的候选区域形状和尺寸变化单一,导致目标检测精确度较低。为此,在基于深度强化学习的视觉目标检测算法基础上,提出联合回归与深度
2023-07-19 14:35:020
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论