 电子发烧友App
电子发烧友App


背景
机器学习现在已经被广泛应用到计算机视觉、图像处理、语音处理、地球物理等领域。和其他技术,比如压缩感知等类似,在计算机和图像处理领域掀起热潮之后,机器学习开始在声学崭露头角。虽然起步不早,但是发展很快。在人类语言语音、动物发声、水下声源定位等声学子领域都有应用。
机器学习的定义想必大家或多或少都知道,可以被宽泛地定义为,无需明确指令的情况下,依赖数据中的模式和特征,通过电脑研究算法和统计模型,来完成特定任务的过程。机器学习大体分为三类:监督学习 (Supervised learning) ,无监督学习 (Unsupervised learning) 和强化学习 (Reinforcement learning)。这篇文章我们只关注前两类。
吴恩达教授给出的监督学习的定义:
In supervised learning, we are given a data set and already know what our correct output should look like, having the idea that there is a relationship between the input and the output。
无监督学习:
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don‘t necessarily know the effect of the variables.
简单说就是监督学习对于输出我们已经有了预期,知道他们长什么样;无监督学习是不知道输出应该是什么,最后用数据来判断。比如同样是分类,垃圾邮件分类是监督学习;把同质类的新闻分类就是无监督学习,因为我们并不知道要分成几类,也没有具体分类标准。
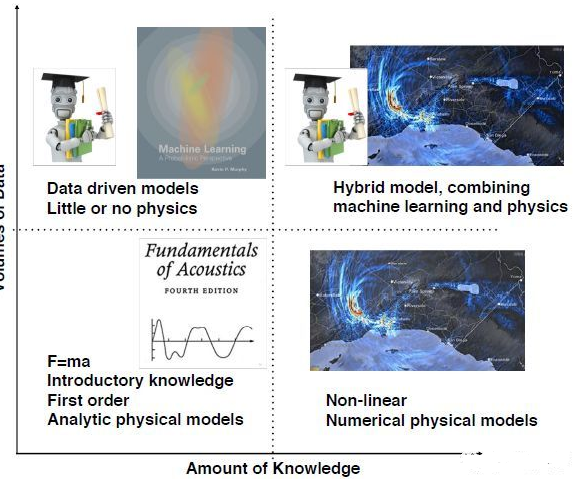
声学是物理学分支,人们几百年来一直致力于发展声学的物理模型,如下图的x轴所示;随着数据量的增大,以数据为驱动的方法也逐渐被运用,如图的y轴。右上角方向就是声学发展的方向:更先进完备的物理模型和大数据驱动的机器学习的结合。机器学习中,数据特征是关键。
机器学习的常见方法
机器学习有海量的学习资料,我一个外行就不再班门弄斧讲基础知识。在这里简单列几个比较常用的机器学习方法。
监督学习
1. 回归和分类
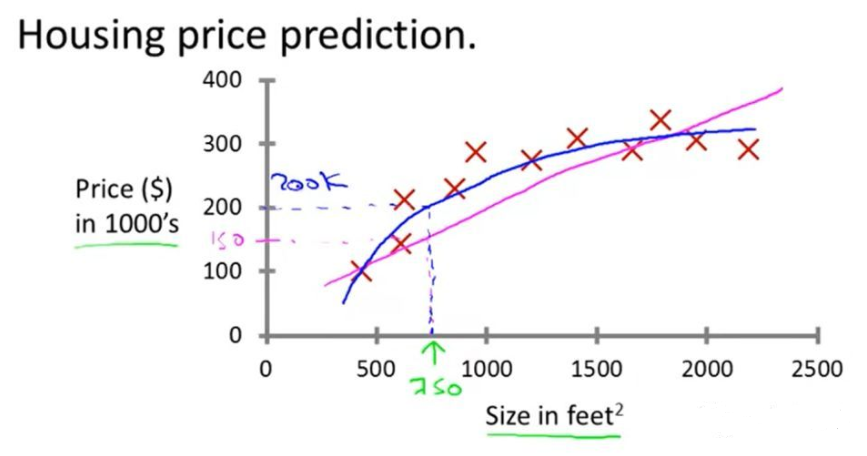
用吴恩达老师在Coursera的Machine Learning里面的一张图展示什么是回归。横坐标房子面积,纵坐标房价,我们可以用各种曲线来代表房价趋势,从而由面积预测房价。
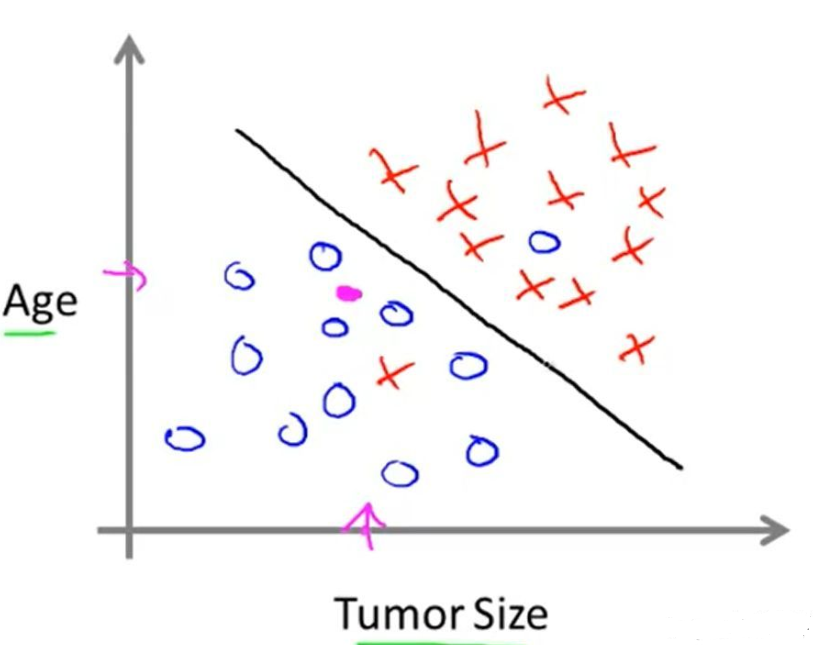
分类很好理解,一个简单的例子
其他的方法还有支持向量机SVM (Support Vector Machine)、神经网络等。其中支持向量机要比回归更灵活,而神经网络可以利用非线性模型进行预测或分类。
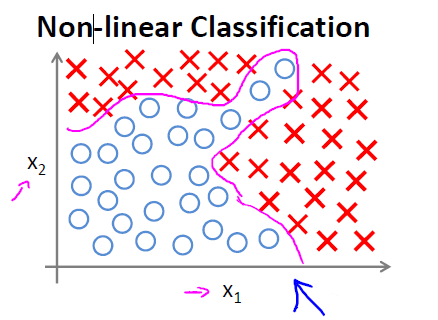
神经网络非线性分类
无监督学习
主要方法有:
1. 主成分分析 PCA (Principal components analysis)
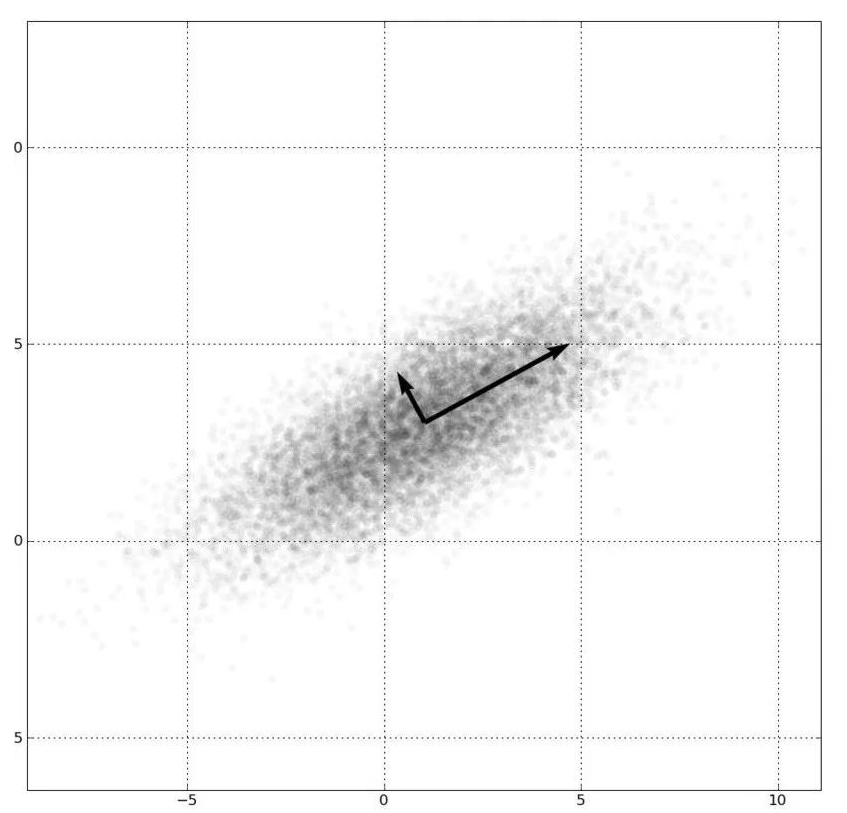
PCA: 通过正交变换把数据转化成线性无关的主成分,对数据进行降维打击,让特征更具代表意义
2. K-means
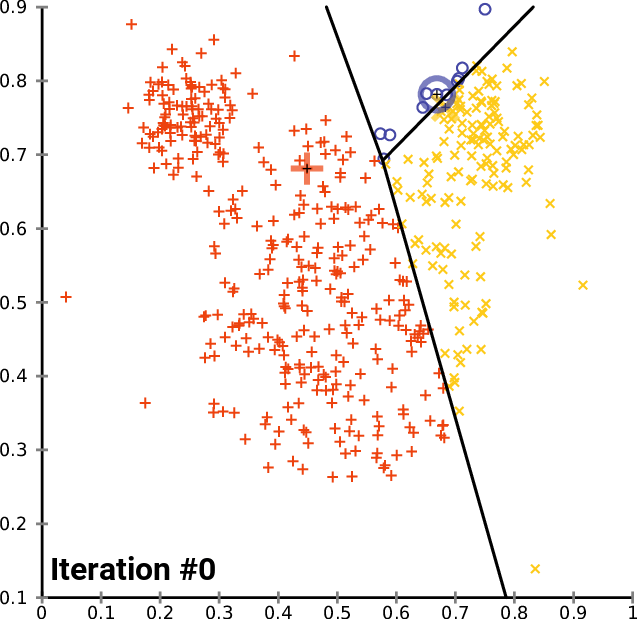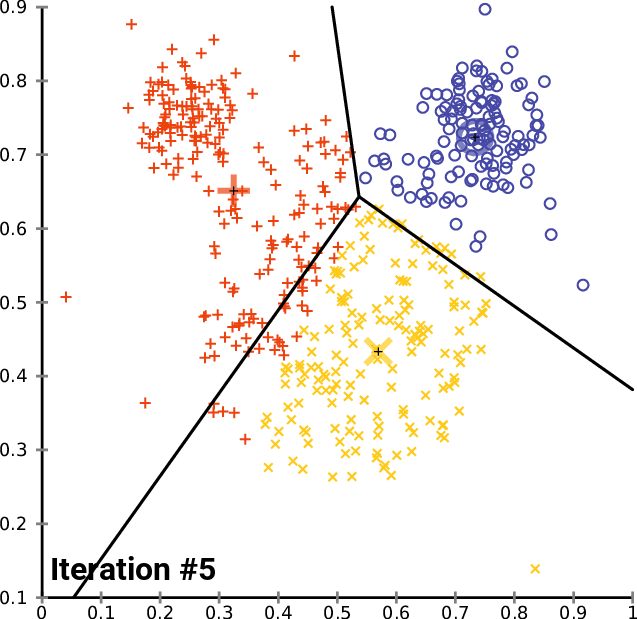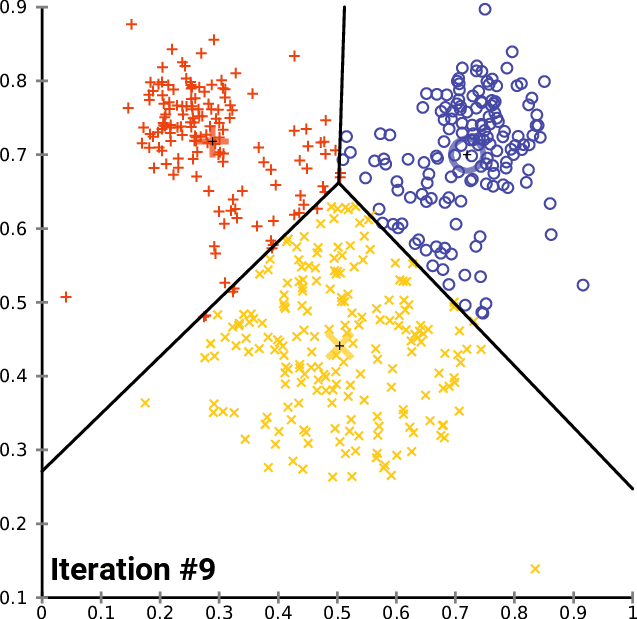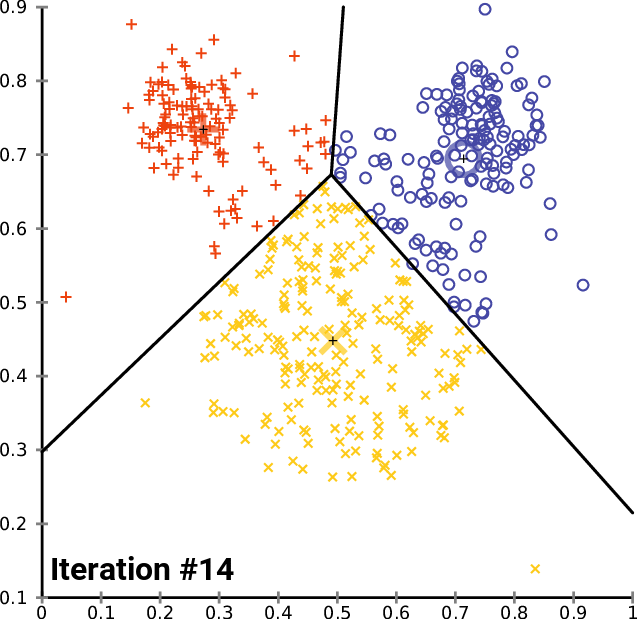
k-mean: 通过迭代找到不同类数据的中心点,从而对数据分类
3. GMM 和最大期望Expectation Maximization (EM)
和k-mean类似,也是一种聚类分析。通过混合几个不同的高斯分布,对特征分类。
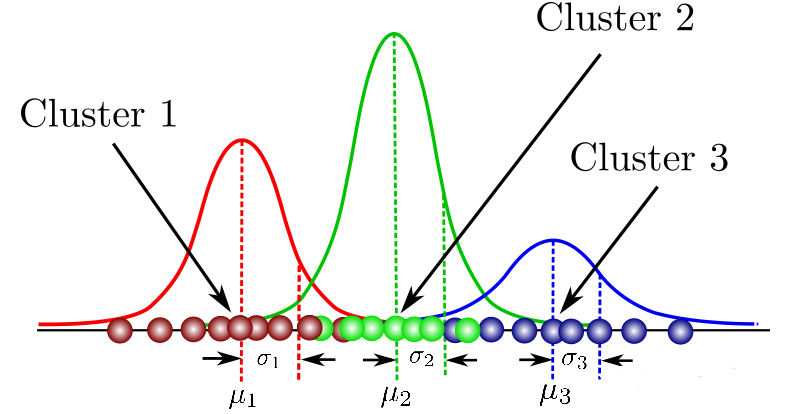
GMM
其他方法还有字典学习 Dictionary learning,Autoencoder network、深度学习(包括卷积神经网络)等。
机器学习在声学中的应用
1. 音频处理中的声源定位
在音频处理中,对声源或者发声者的语音增强是核心问题。机器学习和声学的结合,在手机、汽车、助听器和智能家居等领域都有广泛应用。虽然这个方向的发展非常迅猛,但是在高背景噪声和房间混响的环境下准确识别声源依然是最大的挑战。LOCATA项目最近发起了一项声源定位和追踪的挑战,建立了一个基于现实生活录音的数据库可以用来训练声源定位算法。现在国内外各大语音相关企业都在开展这方面的研究。
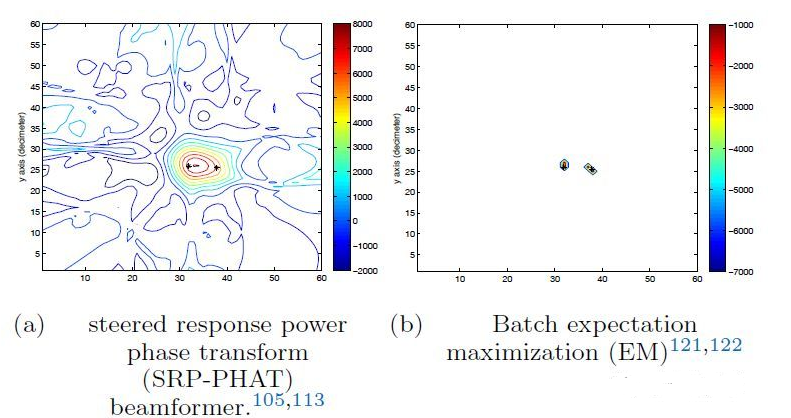
GMM结合EM提高定位精度
2. 海洋声学中的声源定位
海洋声源定位主要利用声呐系统结合Matched field processing (MFP)算法。由于空间中声源绝大多数为稀疏分布(不是空间里布满了声源),所以压缩感知 (Compressive sensing)在近十几年被引入声学。正如前述所说,声学一般都是滞后引入其他学科中的新技术,这似乎是声学学科的特点。
神经网络被用到过准确定位货轮位置[5]。对于浅海和倾斜的海洋环境,需要针对不同的海水深度训练time delay neural network (TDNN)模型从而避免mismatch [6]。今年又有学者成功利用单个水听器hydrophone结合deep residual CNN (Res-Net)预测声源范围和深度[7]。随着计算机能力的提升(比如量子计算机,虽然不知道还要多少年才能商用),结合机器学习和物理模型,有望实现更精准的实时海洋声源定位。
三个船不同时间的时频图
3. 生物声学
这个方向的应用比较有意思,主要研究自然界生物对各种声音的产生和感知,这里的声音不仅仅局限于语音。机器学习已经用于回答以下问题:为什么动物会发声?为什么会出现喊叫和歌声?这些声音之间有什么联系?这些方面有丰富的数据,可供机器学习使用。
通过采集动物叫声,来对他们的生物和生态方面的行为进行分类,从而鉴定某一个区域的动物分布密度,以及密度如何随时间变化,月亮圆缺如何影响动物觅食行为等。早在90年代就有人研究过海洋动物的特征 ,通过提取音频中特征对应的心理声学参数、时频特征等来训练机器学习模型。80年代就有人通过海豚的叫声来对海豚种类进行分类,后来GMM被用到了齿鲸叫声频谱参数数值变化的研究,用隐形马尔科夫模型HMM通过鸟叫来给鸟分类,用多层神经网络分类蝙蝠和鲸鱼,并识别出杀人虎鲸的叫声——方便及时跑路。还有用ensemble learning来给大黄蜂进行分类。无监督学习目前还没有被大面积用到生物声学领域。
几个有趣的生物声学数据库:
https://www.macaulaylibrary.org
Sharing bird sounds from around the world
MobySound.org
British Library - Sounds
https://www.ngdc.noaa.gov/mgg/pad/
在医学领域机器学习和声学也有结合,用来做疾病诊断。比如澳大利亚的Noisy Guts(http://www.noisyguts.net/)公司用声学信号结合机器学习,诊断肠道疾病。
还有对语音信号进行情感情绪分析,来预判危险行为的发声,提前介入防止暴力发生,可以用在幼儿园和监狱等场所。荷兰的一家公司就在做这方面的研究。
通过语音时频谱可以看出人的突然发生很大变化
4. 地质探测
对碳水化合物的地质探测主要通过收集发射的地震波的反射波,来分析地表下反射层是否存在不连续,从而探测地下是否存在碳水资源。这个领域传统方法是结合信号和图像处理,利用声学做地质探测也是近期的事情。
5. 混响和环境声
人类每天都在和复杂的声环境打交道,各种各样的声源包括语音、音乐、冲击、摩擦、流动、动物、机器等。每个声源发出的声音和其他声源以及周围环境发生交互,导致传到人耳里面的声音非常复杂,并不包含声源的原始声音。像之前提到的,去混响和反射、提取声源声音都是声学和机器学习结合面临的挑战,如何在混合信号中提取出声源声。比如,我们需要让助听器能够在背景噪声中分辨出人声,自动驾驶的汽车能在嘈杂的街道上听出警笛并让道(虽然这个功能在国内应该是鸡肋)。
在自然环境中,声源辨别面临以下几个问题:
声源种类繁多;
每种声源又有很大多样性;
自然环境中都是多个声音时间同时发生并互相干扰。
现在有好多的数据库来提供自然界的录音来训练classifier,比如DCASE challenges,ESC,TUT,Audio set,Urban Sound and scene classication (DCASE; TUT)。
通过声学结合先进的图像处理来进行声音场景和声源分类识别可以增强识别效果。还可以通过物理模型来模拟声音,用来方便产生更多数据来提取特征,训练模型。
通过物理模型合成大型对比声音数据库







 工商网监
工商网监
评论