 电子发烧友App
电子发烧友App



据思科统计数据,互联网视频流在网络带宽中占有很大份额,到2022年将增长到消费互联网流量的82%以上。视频服务已经成为人们生活中不可或缺的一部分。
为了克服网络抖动带来不必要的播放卡顿,自适应多码率被公认为最有效的手段之一,例如MPEG-DASH、Apple的HLS、快手的LAS等。ABR算法自适应多码率方案的核心,依据网络状态、播放状态等信息,动态调整请求视频流的清晰度(码率),从而在流畅度、清晰度和平滑性上取得平衡,最大化用户体验。
ABR算法可以分为两大类,一类是基于启发式的策略,通过建立各种模型或规则来控制码率的选择,然而这些算法通常需要仔细调参以适应多变的网络环境。另一类则是采用机器学习的方式,让播放器通过与现实中的网络交互,“自主地”学习出一个适应当前网络状态的ABR算法。
任何算法在落地前都需要经历漫长从理论到实践的调试与优化,特别是解决各种各样“实验室中认为不重要但是在落地阶段非常重要”的问题。
鉴此,快手音视频技术部联合清华大学孙立峰教授团队对基于学习的ABR算法在两方面进行了研究和改进,并分别发表在国际顶级会议IEEE INFOCOM 2020与国际顶级期刊IEEE JSAC。
论文地址:https://ieeexplore.ieee.org/abstract/document/9109427
自适应多码率
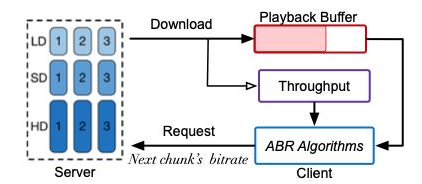
图1 码率自适应传输架构图
自适应多码率的传输架构分为基于分片(MPEFG-DASH、HLS)和基于流式(LAS)两类,本文以基于分片为例,如图1所示:视频在发布前,会先进行切片和转码,得到不同码率和清晰的分片,在客户端,每次当当前切片下载完成时,客户端上的ABR算法将综合考虑带宽、缓冲情况以及用户信息等信息,选择下一个切片的码率,从而实现自适应,提升用户的体验(QoE)。用户的QoE通常由以下指标组成(如公式1所示)。
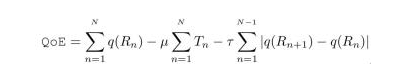
公式1 自适应码率传输中的QoE定义
其中代表视频的码率,代表视频的卡顿时长,最后一项为平滑项:即不希望视频码率频繁切换。μ和τ为惩罚系数。对ABR算法来说,该优化是一种长时优化(long-term optimization)。例如在某个时刻ABR算法“贪心地”选择了高码率,然而网络在之后变差了,导致之后几个时刻ABR算法都只能“被迫”选择较低的码率或造成卡顿,那么综合来说,这次选择就是不合适的。
基于学习的ABR
机器学习是否能解决这个问题呢?答案是肯定的。例如Pensieve(SIGCOMM‘17)将码率自适应过程建模为了一个马尔可夫决策过程(MDP),并使用深度强化学习算法(Deep Reinforcement Learning, DRL) 从零开始训练,最终学习到的策略在QoE指标上超越了过去最优算法18%。然而,尽管Pensieve在“性能”上获得了巨大的突破,但是该算法由于诸多限制很难在现实中部署:
开销:为了减少客户端上的开销,Pensieve将整个模型推理放在了服务器上,并作为服务运行。然而在实际部署中,大多数的ABR算法部署在客户端上以避免额外的消耗,例如端到端延迟,服务器上作为服务的消耗等。故如何进一步从机理上降低模型的开销将成为其部署的一大挑战。
效率:Pensieve使用强化学习算法进行训练,通常需要至少8小时才能训练收敛一个策略。如何改善训练效率,使其始终能适应当前网络状态是ABR任务的另一大挑战。
1、结合领域知识,降低整体开销
面对第一个挑战,我们提出了“结合领域知识”这一概念。基本动机是:虽然AlphaZero等突破性的算法在摒弃了人类领域知识后获得了更高的水准。但是考虑到ABR算法是一个“状态,动作空间较小,物理意义明确”的任务,是否过去优秀的ABR算法已经挖掘出足够的“领域特征了”?
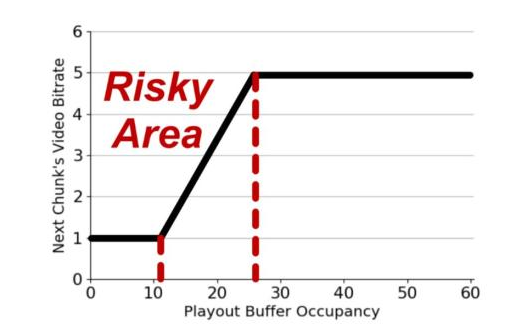
图2 BBA算法原理介绍
BBA(Buffer-Based Approach,SIGCOMM’14)是优秀的代表之一,其原理如图2所示。BBA算法内部有两个阈值(RESEVIOR和CUSHION)。在当前缓冲小于阈值RESEVIOR时(偏左的红色虚线),BBA算法恒选择最小的视频码率;当缓冲区储存的视频时长大于RESEVIOR+CUSHION(偏右的红色虚线)时,BBA会选择最大的视频码率;在缓冲区处于其他状态下时,BBA算法会使用线性拟合的方式,根据当前的缓冲选择一个适合的视频码率。由此可知,BBA算法的性能非常依赖RESEVIOR和CUSHION这两个值的取值。在本文中,我们尝试是否可以将BBA算法和基于学习的算法可以有机地结合在一起,即,我们能通过深度学习方法增强BBA算法,与此同时,BBA算法又能给学习算法带来更多的领域知识,从而降低模型开销。
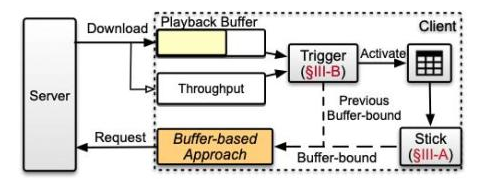
图3 Stick系统架构图
我们提出了Stick,一种融合了传统基于缓冲区方法和基于学习的方法的自适应码率方案。该方案的系统框架图如图3所示,模块主要由两大部分组成,分别是:1) 基本Stick模块。该模块主要利用一个线下训练完的神经网络,根据当前客户端接收的状态输出连续值,该值用于控制传统的BBA算法的阈值。2) Trigger模块。Trigger模块是一个轻量级的神经网络,部署在Stick启动之前,用于决策是否开启基本Stick模块,从而进一步降低Stick神经网络的整体开销。
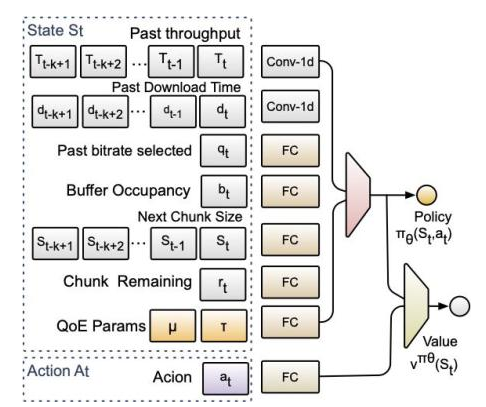
图4 Stick神经网络结构
Stick模块:采用连续值下的深度强化学习算法DDPG来训练神经网络,将过去的码率决策,过去一段时间的带宽大小,下载时长,未来视频大小,剩余时长,当前缓冲区大小等输入神经网络,并输出一个单值,代表允许下最大码率的缓冲值。随后我们采用经典的BBA方案,该值将被扩展为一个缓冲表,用于决策每一个缓冲下的对应下载码率。之后的实验表明,运用领域知识可以大幅度降低神经网络的开销,最高可将模型大小缩减88%。
Trigger模块:在使用领域知识缩减了模型大小后,我们进一步通过实验挖掘出BBA的潜力:由于Stick使用缓冲表去选择码率,很明显,它比一般的输出携带了更多的信息,所以在大多数网络情况下,只有30%到40%的情形需要去开启Stick神经网络去推端新的阈值,在其他时候,只需要沿用上一个阈值即可。故我们可以在Stick神经网络之前再部署一个非常轻量级的小型神经网络,使用简单的结构决定是否需要更新当前阈值参数。在此我们使用的模仿学习,即在训练时实时求解最优解并引导神经网络渐渐“靠近”最优策略。
实验结果:我们比较了Stick与经典的buffer-based算法(包括BBA和BOLA)的性能,结果表明Stick分别提升了44.26%和25.93%的QoE。随后在进一步和过去多个算法的比较中,Stick也表现出了更好的性能,总体提升了3.5%-25.86%的QoE。于此同时,与Pensieve相比,Stick减少了88%的模型开销。
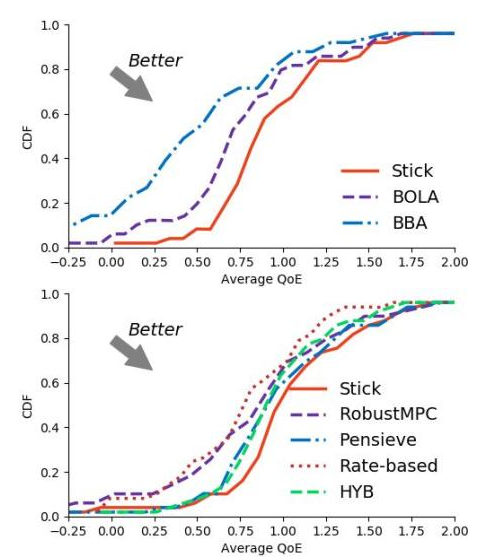
图5 Stick实验结果
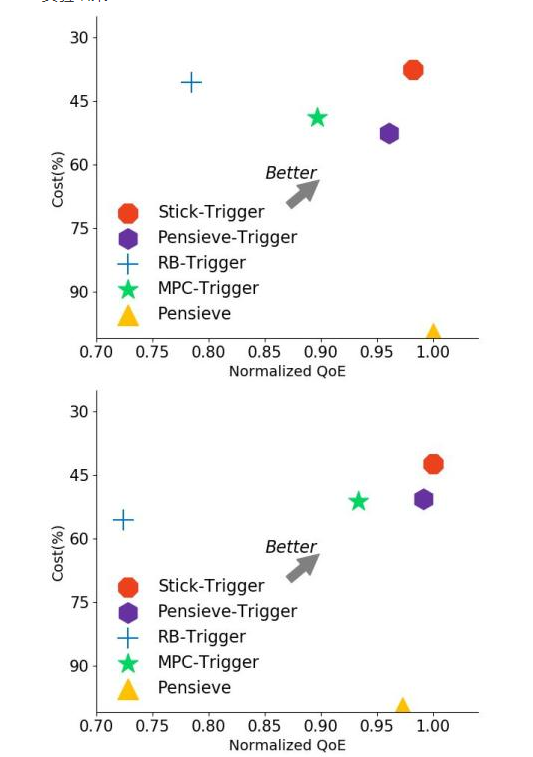
图6 Trigger实验结果
我们随后对Trigger三个不同的数据集上进行了实验测试。结果表明Trigger会明显减少Stick的综合开销,总体节省幅度在39%-61%。此外我们可以看到Trigger甚至帮助过去的一些经典算法提升了性能,包括Rate-based和经过改进的Pensieve。
更详细的内容请参考我们的IEEE INFOCOM2020的论文《Stick: A Harmonious Fusion of Buffer-based and Learning-based Approach for Adaptive Streaming》。
2、改善训练效率,在线终身学习
第二个挑战来自强化学习的低训练效率。在强化学习方案中,智能体通过与环境交互获得{状态,动作,回报}集合,随后通过学习增大每次动作获得的回报。然而,在学习过程中,智能体无法获取在当前状态下的最优动作,因此不能为神经网络提供准确的梯度方向更新,基于强化学习的ABR算法也遭受着这个缺点。
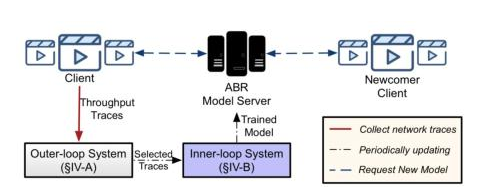
图7 LifeLong-Comyco系统架构
针对这些问题,我们提出了Lifelong-Comyco,一种终身模仿学习的ABR算法。Lifelong-Comyco的系统架构如图7所示。该系统由外循环系统(Outer-loop)和内循环(Inner-loop)系统两部分组成。其中内循环系统使用模仿学习方法更快更有效地从专家序列中学到策略;外循环系统则给予了系统持续更新能力,采用终身学习的方式自主“查缺补漏”,学习有必要的数据。该系统的系统流程为:在视频开始之前,位于客户端的视频播放器从ABR模型服务器下载最新的神经网络模型。每次当视频在客户端上播放完成后,播放器将通过过去的下载块大小和下载时间生成带宽数据。随后,收集到的带宽数据将被提交到位于服务器端的外循环系统。外环系统将即时估计当前策略与最优策略之间的差距。根据该差距,我们可以确定该网络带宽数据是否需要加入训练集中。随后在每个时间段(例如1小时),在内循环系统将被调用并通过终身模仿学习有效地更新神经网络。最后,每隔一段时间,我们会将训练好的模型冻结并提交给ABR模型服务器。
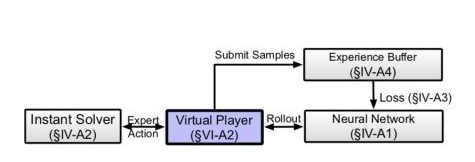
图8 内循环系统架构
内循环系统:在内循环系统中,我们充分利用了自适应码率任务的特点,即可以通过线下模拟器,在给定的网络和视频的条件下准确地判断出当前的最优或者接近最优的解。在获取到最优解后,我们便可以使用传统的监督学习方法高效地对神经网络进行更新。大致方法如下:首先,我们使用蒙特卡洛采样,即从相同的状态开始,将过程推演到N步之后。随后我们选择得到地QoE得分最高地那条轨迹中地第一个选择作为未来地码率选择。之后,我们将{状态,最优选择}保存入经验池中。最后,每次训练开启,我们需要训练的智能体就会从经验池中随机选出数据进行训练。这里我们可以注意到,与强化学习不同,模仿学习做到了采样和训练解耦,从而更能提升并行效率,达到高效训练。
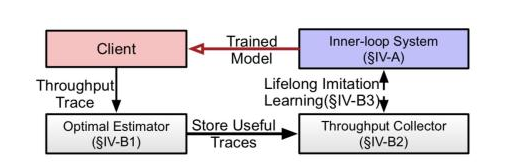
图9 外循环系统架构
外循环系统:外循环子系统的核心思想是进一步减少训练时所需地训练集。我们会先对客户端上报的带宽数据进行整理,核算线下最优解。随后我们查看当前线上策略与线下最优解所取得的QoE的差距,当差距超过某个值时,我们会将当前带宽数据放入要训练的数据集中。最后,我们会采用终身学习的训练方法训练神经网络,这是一种经典的主动学习(Active Learning)方案,可以在不忘记过去表现良好的带宽数据的情况下,记住表现不好的带宽数据。
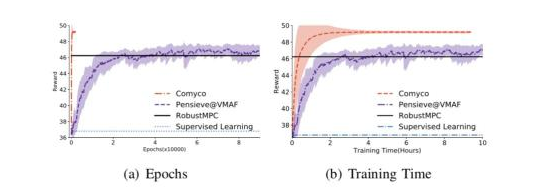
图13 内循环系统训练曲线
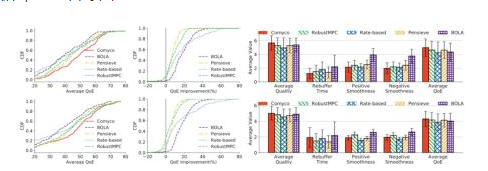
图14 内循环系统实验结果。算法在FCC和HSDPA数据集上进行了细致地测试
实验结果:首先我们测试了内循环系统训练出的神经网络的性能。如图10 所示,我们看到了模仿学习有效并快速的学习到了更好的策略:整体训练步数相较于强化学习的训练步数减少了1700倍,同时,整体训练时长减少了16倍。于此同时算法的整体性能还有提升。在HSDPA数据集上,我们测得模仿学习训练处的策略比过去的方法高出了7.5%-17.99%的QoE。
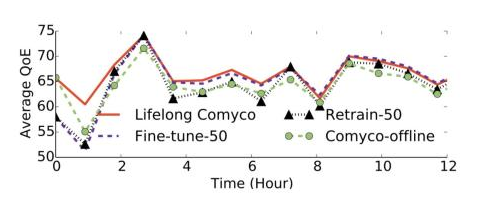
图15 外循环系统实验结果
随后我们对外循环系统进行了测试。测试数据是我们搜集12小时带宽序列数据。我们会在整点对神经网络进行更新,并在其他时候记录需要使用的带宽数据集。实验结果表示,使用终身学习算法将有效避免灾难性遗忘问题,并且能够跟随网络分布的变化实时更新自己的策略,使其性能用于处于较好的状态。反观其他算法,包括实时fine-tune,重新训练,与只是用内循环系统,都不能很好地做到这一点。实验表明,使用外循环系统更新能比只使用内循环系统的方案再高出1.07%到9.81%的性能。
更详细的内容请参考我们的JSAC的论文《Quality-aware Neural Adaptive Video Streaming with Lifelong Imitation Learning》。
结语
基于机器学习的ABR算法在落地上还有很多的内容需要被探索,包括可解释性,鲁棒性,以及更小巧的模型等。快手有完善的数据集、AB测试平台、优秀的算法团队,非常欢迎各位同行、学者和我们一起研究、探讨、合作,做落地有效的算法,提升用户体验。








 工商网监
工商网监
评论