 电子发烧友App
电子发烧友App



作者:周苏,支雪磊,刘懂,宁皓,蒋连新,石繁槐
PVANet(performance vs accuracy network)卷积神经网络用于小目标检测的检测能力较弱。针对这一瓶颈问题, 采用对PVANet网络的浅层特征提取层、深层特征提取层和HyperNet层(多层特征信息融合层)进行改进的措施, 提出了一种适用于小目标物体检测的改进PVANet卷积神经网络模型, 并在TT100K(Tsinghua-Tencent 100K)数据集上进行了交通标志检测算法验证实验。结果表明, 所构建的卷积神经网络具有优秀的小目标物体检测能力, 相应的交通标志检测算法可以实现较高的准确率。
计算机目标检测是指计算机根据视频、图像信息对目标物体的类别与位置的检测, 是计算机视觉研究领域的基本内容。随着硬件和软件技术的发展, 尤其是基于卷积神经网络目标检测算法的普及应用, 计算机目标检测的准确率及速度都有了很大提高[1]。而且, 异于传统的人工设计特征提取器, 卷积神经网络目标物体检测可自主学习视频、图像信息中的特征, 从而检测到更多类别以及更细分类的物体[2]。小目标检测主要是对图像或视频中的标志、行人或车辆等显示尺寸较小的目标进行检测, 在民用、军事和安防等领域具有十分重要的作用[1]。
近年来卷积神经网络结构及目标检测算法被广泛应用, 如用于手写数字识别的LeNet(lecun network)[3]、用于图像分类的VGGNet(visual geometry group network)、GoogLeNet(Google network)及ResNet(residual network)等[4], 用于目标检测的Faster R-CNN(faster region-based convolutional neural network)、R-FCN(region-based fully convolutional network)、YOLO(you-only-look-once)和SSD(single shot detector)等[5-7]。但是, 当检测图像中目标物体很小时, 主流卷积神经网络的检测能力仍然较弱, 这是其在目标检测应用方面的主要瓶颈问题之一。吴双忱等[8]基于SEnet(Squeeze-and-Excitation network)提出了一种解决红外小目标检测问题的深度卷积网络。赵庆北等[9]对Faster R-CNN网络进行改进, 引入候选区域方案提高了公司徽标的检测性能。彭小飞等[10]对原始FPN(feature pyramid network)网络进行改进, 利用浅层网络丰富的位置信息, 进行小目标的全图搜索检测。梁华等[11]针对航拍小目标识别率低、定位差的问题, 基于VGG16网络进行改进, 提高其实时性和精度性能.PVANet网络具有训练效率高、对不同尺度目标的适应性强等适合于复杂多变交通场景的优势。本研究工作对PVANet(performance vs accuracy network)网络进行改进, 解决其交通标志小目标检测能力不足的问题。
1 相关工作
各国交通标志都有其规定的颜色、形状、图案等特征, 采用传统的手工设计特征提取器, 可以从图像中提取特征信息进行交通标志检测.Ritter等[12]采用图像颜色组合检测交通标志, 在红、绿和蓝色(RGB)中引入查表法(LUT)消除不需要的颜色.Priese等[13]设计了用于颜色分割的颜色结构代码(CSC), 并且生成CSC数据库。研究结果表明, 道路标志颜色的RGB分量差异虽可用于目标分割和检测, 但不便于直接描述光照变化。因此, 人们开始研究由色调、饱和度和强度(HSI)或者色调、饱和度等组成的颜色特征空间下的交通标志检测[14]。其中, HSI因其模拟人类感知的能力优于RGB, 其交通标志检测应用效果更好。 Zaklouta等[15]结合HOG(histogram of oriented gradients)描述符和线性SVM(support vector machine)算法在处理实时性要求和性能之间取得了良好的折衷。
手工设计特征提取方法对图像特征的提取能力有限, 交通标志检测应用效果很大程度上取决于设计者经验, 因此不适用于大规模交通标志检测。神经网络具有学习非线性、复杂关系的能力[16], 尤其是卷积神经网络可自主学习图像特征, 越来越多地被用于交通标志检测.Sermanet等[17]用卷积网络从GTSRB数据集(德国交通标志检测数据集)的彩色图像中提取并学习交通标志的特征信息, 检测准确率高达98.97%.Aghdam等[18]提出一种新的ReLU(rectified linear unit)作为激活函数的CNN(convolutional neural network)架构, 实现了更佳的精确度和检测时间。
2 PVANet网络结构与改进
2.1 PVANet网络简介
PVANet[19]是Intel公司Kim等人在2016年提出的一种用于实时物体检测的卷积神经网络结构。在VOC(visual object classes)[20-21]数据集物体检测比赛项目上PVANet取得了第2名的成绩, 其平均准确率(mAP)为82.5%.
PVANet采用基于C.ReLU(concatenated rectified linear unit)激活函数的浅层特征提取方法, 改善参数冗余问题, 减小了网络参数量, 提高了训练效率.PVANet还借鉴Inception(谷歌基础神经元结构思想), 将输入分别通过4个不同的卷积核进行卷积和池化操作后串联合并在一起, 增加了网络对不同尺度目标的适应性。另外, PVANet将conv3中原图的1/8、1/16和1/32特征图连接起来, 增强了最终特征图中的多尺度信息。
2.2 PVANet网络结构的改进
PVANet网络进行目标检测时, 虽然其准确率和实时性较好, 但针对小目标物体的检测能力仍有很大的提升空间。对此, 本文提出了更适用于小目标物体检测的改进网络结构, 对浅层特征提取层、深层特征提取层和HyperNet层进行了改进。图 1是改进前PVANet网络结构(图 1a)与改进后结构(图 1b)的对比, 其中虚线边框模块为本文提出的改进模块。详细的改进后PVANet网络信息见表 1.
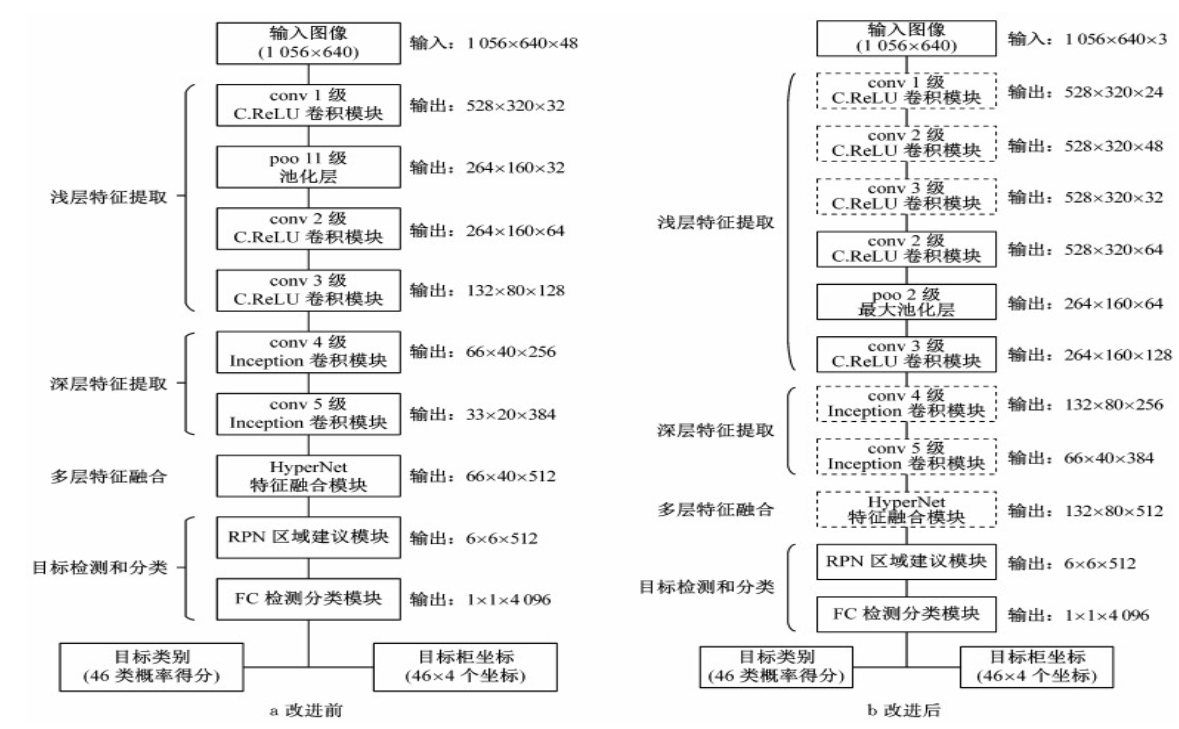
注: conv i—第i级卷积; pool—池化; RPN—region proposal network; FC— fully connected layer
图 1 PVANet网络改进前后结构图
Fig.1 Structure of PVANet before and after improvement
2.2.1 浅层特征提取
PVANet网络的第1层卷积层通常采用7×7或更大维度的卷积核(步长为2)进行卷积, 同时在本层即采用了C.ReLU型激活函数, 这样可以避免浅层卷积滤波器的参数冗余问题。
与单个的7×7或更大维度的卷积核相比, 采用多个3×3卷积核的组合, 可以减少参数量并加快检测速度, 同时增强网络的非线性表达能力。另外, C.ReLU激活函数虽然具有提高参数效率、避免浅层卷积滤波器参数冗余的优点, 但是特征图经过C.ReLU处理后输出维度会增加一倍。因此, 目前PVANet使用C.ReLU时通常对输入特征图的维度加以限制, 如设定conv1卷积模块的输出期望维度为32, 第1层卷积层的输出维度必须限定为16.对于较大图片来说, 这样的设计会限制浅层网络提取特征的能力, 致使图像的细粒度和小目标特征信息部分丢失。
鉴于上述原因, 本文提出将PVANet第1层卷积层中7×7维度的卷积核拆解成3层3×3维度的卷积层。其中, 第1层卷积层使用普通的ReLU激活函数, 将其输出维度提高至24;第2层卷积开始使用C.ReLU激活函数, 输出维度增加至48;第3层卷积层输出维度减小至32.这样的结构改进(图 2)旨在增加浅层卷积滤波器的细粒度和小目标图像特征的提取能力。此外, 为增强改进效果, 将conv 2和conv 3卷积模块中每个子模块中第1层卷积层的输出维度增大至48和72, 如表 1所示。
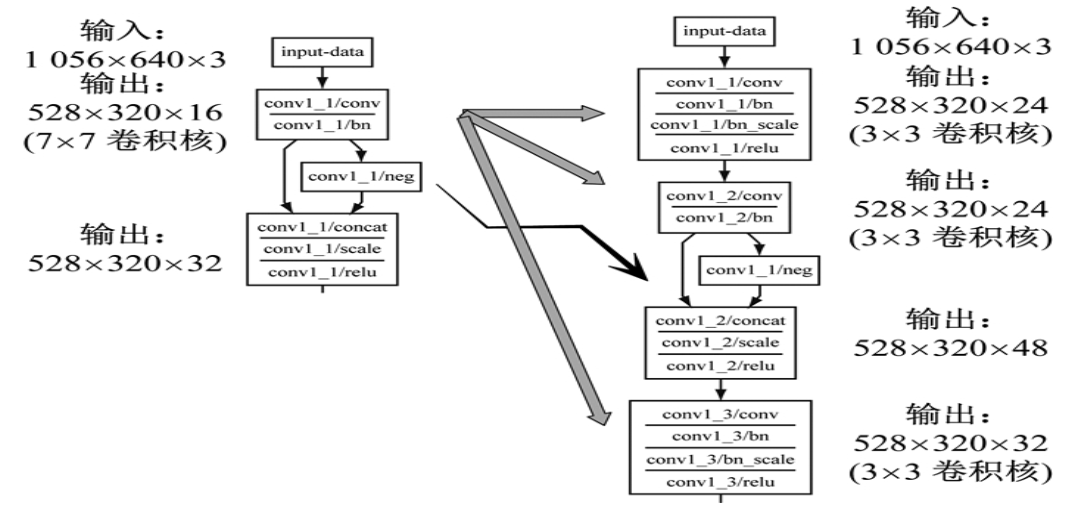
图 2 浅层特征提取卷积层改进示意图
Fig.2 Improvement of shallow feature extraction
2.2.2 深层特征提取
PVANet网络通常采用Inception v1模块进行深层特征提取。在该模块中, 将5×5的卷积核分解为两个3×3维度的卷积核, 可以减小网络模型的参数量, 但是会发生一定程度的精度损失。为了克服这一不足, 在进行上述卷积核分解的同时, 本文将3×3卷积核进一步非对称地分解成两个1×3和3×1维度的卷积核。这样的非对称分解(图 3)不仅进一步减少了网络的参数量, 而且通过层数增加有望进一步提高网络的非线性表达能力。
图 3 非对称1×3和3×1维度卷积核的卷积过程
Fig.3 Convolution process of asymmetric 1×3 and 3×1 dimensional convolution kernels
2.2.3 多层特征信息融合
在原版PVANet网络中, conv 3_4浅层卷积层输出的132×80像素特征图的下采样处理是通过3×3池化层进行的, 最后的conv5_4深层卷积层输出的33×20特征图的上采样处理则通过4×4像素卷积核进行。两者得到的特征图大小相同(66×40像素), 合并之后作为目标检测和分类的依据。但是, 相比输入图片, 这一系列66×40像素特征图已经缩小了16倍。如果输入图片中存在一个32×32像素描述的小目标, 映射到最后的特征图上就只有2×2个像素点信息。原版PVANet网络的多层特征信息融合方式使得小目标的特征表征能力受到限制, 难以准确识别图像中的小目标。
因此, 本文提出减少1次池化和相应的卷积特征提取, 使网络能融合更浅层卷积层输出的特征图信息, 并在更大的132×80特征图上进行目标检测和分类(即只缩小8倍), 使其对小目标有更强的检测能力。
3 实验
3.1 实验条件与方法
采用TT100K[22]交通标志数据集作为改进网络训练和测试用的基准数据集, 其中训练集包括10 380张图片, 测试集包括5 229张图片。两个子集覆盖了所有需要检测的标志类别, 并且图像数据互不包含。
训练所用的求解器为SGD(stochastic gradient descent), Batch Size为1, 起始学习率设置为0.01, 之后根据数据集的大小和Batch Size采用每40 000步减小0.1倍的方法, momentum和weight decay分别设置为0.9和0.000 2.
研究中所有深度学习算法的训练和测试全部使用了Caffe深度学习框架, 并且在一台配备了Intel i7-5930K CPU和NVIDIA Titan X GPU的工作站上进行, 操作界面采用Python软件实现。
3.2 实验结果与分析
在实验过程中, 分别使用原版PVANet网络模型结构及加入本文所述各改进算法的PVANet网络模型结构, 在TT100K测试集上进行交通标志检测, 以准确率、单帧检测时间和PR(precision-recall)曲线作为评价指标。实验结果见表 2和图 4.
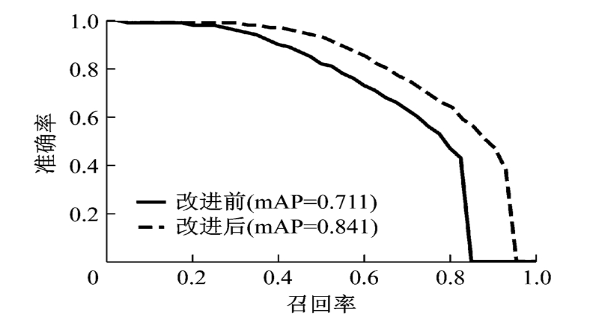
图 4 算法改进前后PR曲线对比图
Fig.4 Comparison of PR curve
由表 2可以看出, 与PVANet 9.1在数据集上的检测结果相比, 采用2.2.1节改进算法可以将交通标志检测的mAP提升约4.2%.可知, 提高浅层神经网络的通道数, 可以提高网络对交通标志小目标的检测能力。此外, 由于将大的7×7卷积核分解为多个小的3×3卷积核, 以减少计算量, 改进后网络模型的检测时间无明显增加。采用2.2.1、2.2.2节所述的改进算法, 即再将深层网络中的5×5卷积替换为两个1×3和3×1卷积, 也会使网络模型的检测速度变快, 同时能够保持较高的mAP.最后, 采用2.2节中的改进算法, 再减小1次池化计算, 将神经网络的输出特征图增大一倍, 使得网络对交通标志检测的mAP大幅提高约9%, 网络的检测时间虽然增加约0.02 s, 但是仍然具有很好的实时性, 满足交通标志检测要求。由图 4可知, 改进后算法的准确率和召回率都有所提升。综上所述, 输出更大的特征图虽然使计算量有所增加, 但可增强网络的特征表达能力, 大幅增加网络的目标检测准确率。
图 5是算法对小目标交通标志检测的效果图, 其中存在一个超小且被遮挡的交通标志(图 5b标注所示)。图 5a为原版PVANet网络模型检测结果, 图 5b为改进后PVANet网络模型检测结果。可见, 改进后PVANet网络对于交通标志小目标物体有着很好的检测能力, 且对于目标物体的被遮挡问题有着一定的鲁棒性。
图 5 改进前后PAVNet检测效果对比图
Fig.5 Comparison of detection before and after improvement
图 6是图 5场景经算法模型卷积计算得到的中间层特征图。可以看出, 浅层特征图侧重图像宏观特征的提取, 因此与原图风格相近, 而深层特征图侧重对细节像素的计算判断, 对交通标志的准确检测更为关键。对比算法改进前后的效果可以看到, 改进后算法在正确的交通标志区域呈现出代表敏感性的更亮色, 具有更好的检测效果。
图 6 改进前后浅层和深层卷积层特征对比图
Fig.6 Comparison of shallow and deep convolutional layers
图 7是改进算法对于有更多超小目标交通标志图像的更复杂交通场景的检测效果, 其中图 7a是原图, 图 7b和图 7c分别是改进前和改进后算法检测结果的局部放大图。该场景共有5个交通标志, 原版PVANet只检测到3个交通标志, 改进后算法可检测到所有5个交通标志。由此可见, 改进算法具有更好的检测效果。
图 7 检测效果对比图
Fig.7 Comparison of experimental results
TT100K数据集中的部分交通标志属于小目标物体, 通过本研究中基于此数据集的实验, 验证了所提出的改进算法对于交通标志小目标具有优秀的检测能力。分析其原因, 由于浅层神经网络感知野(perception field)较小, 主要负责网络的细节特征提取, 增加浅层网络通道数, 能够使网络提取更多细节信息, 这对交通标志小目标的检测是有利的。而减小一次池化计算, 不仅增大网络输出的特征图大小, 也使网络模型中HyperNet模块融合的浅层特征图更“浅”, 这样神经网络就能够提取图片中更多的细节特征信息, 提高网络的小目标检测能力。虽然经过多步改进后, 所提出改进算法的检测时间有一定增加, 但总时间仍控制在0.09 s内, 具有很高的实时性。
4 结论
PVANet网络具有训练效率高、对不同尺度目标的适应性强等适合于复杂多变交通场景应用的优势。本文对其浅层特征提取、深层特征提取和HyperNet多层特征融合模块分别进行改进, 提出了一种改进的PVANet卷积神经网络模型, 克服了小目标交通标志识别的瓶颈难点。基于TT100K交通标志数据集, 对改进算法进行了实验验证。结果表明, 所提出的改进网络模型与原网络模型相比, 交通标志小目标检测的mAP有大幅提升, 证明了其对小目标物体优秀的检测能力; 虽然检测时间小幅上升, 但仍具有较好的实时性。
参考文献[1]刘晓楠, 王正平, 贺云涛, 等。 基于深度学习的小目标检测研究综述[J]。 战术导弹技术, 2019(1): 100
LIU Xiaonan, WANG Zhengping, HE Yuntao, et al. Research on small target detection based on deep learning[J]。 Tactical Missile Technology, 2019(1): 100
[2]郭之先。基于卷积神经网络的小目标检测[D]。南昌: 南昌航空大学, 2018.
GUO Zhixian. Small object detection algorithm based on deep convolution neural network[D]。 Nanchang: Nanchang Hangkong University, 2018.
[3]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]。 Proceedings of the IEEE, 1998, 86(11): 2278 DOI:10.1109/5.726791
[4]HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
[5]REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]。 IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137
[6]LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21-37.
[7]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[8]吴双忱, 左峥嵘。 基于深度卷积神经网络的红外小目标检测[J]。 红外与毫米波学报, 2019, 38(3): 371
WU Shuangchen, ZUO Zhengrong. Small target detection in infrared images using deep convolution neural networks[J]。 Journal Infrared Millimeter Waves, 2019, 38(3): 371
[9]赵庆北, 元昌安, 覃晓。 改进Faster R-CNN的小目标检测[J]。 广西师范学院学报(自然科学版), 2018, 35(2): 68
ZHAO Qingbei, YUAN Chang‘an, QIN Xiao. Improved faster R-CNN for small object detection[J]。 Journal of Guangxi Teachers Education University (Natural Science Edition), 2018, 35(2): 68
[10]彭小飞, 方志军。 复杂条件下小目标检测算法研究[J]。 智能计算机与应用, 2019, 9(3): 171
PENG Xiaofei, FANG Zhijun. Research on small target detection algorithm under complex conditions[J]。 Intelligent Computer and Applications, 2019, 9(3): 171 DOI:10.3969/j.issn.2095-2163.2019.03.040
[11]梁华, 宋玉龙, 钱锋, 等。 基于深度学习的航空对地小目标检测[J]。 液晶与显示, 2018, 33(9): 793
LIANG Hua, SONG Yulong, QIAN Feng, et al. Detection of small target in aerial photography based on deep learning[J]。 Chinese Journal of Liquid Crystals and Displays, 2018, 33(9): 793
[12]RITTER W, STEIN F, JANSSEN R. Traffic sign recognition using color information[J]。 Math Compute Model, 1995, 22(4/5/6/7): 149
[13]PRIESE L, KLIEBER J, LAKMANN R, et al. New results on traffic sign recognition[C]//Proceedings of the Intelligent Vehicles’94 Symposium. Paris: IEEE, 1994: 249-254.
[14]MOGELMOSE A, TRIVEDI M M, MOESLUND T B. Vision-based traffic sign detection and analysis for intelligent driver assistance systems: perspectives and survey[J]。 IEEE Transactions on Intelligent Transportation Systems, 2012, 13(4): 1484 DOI:10.1109/TITS.2012.2209421
[15]ZAKLOUTA F, STANCIULESCU B. Real-time traffic sign recognition in three stages[J]。 Robotics and Autonomous Systems, 2014, 62(1): 16
[16]SABBEH A, AI-DUNAINAWI Y, AI-RAWESHIDY H S, et al. Performance prediction of software defined network using an artificial neural network[C]//2016 SAI Computing Conference (SAI)。 London: IEEE, 2016: 80-84.
[17]SERMANET P, LECUN Y, Traffic sign recognition with multiscale convolutional networks[C]//The 2011 International Joint Conference on Neural Networks. San Jose: IEEE, 2011: 2809-2813.
[18]AGHDAM H H, HERAVI E J, PUIG D. A practical approach for detection and classification of traffic signs using convolutional neural networks[J]。 Robotics and Autonomous Systems, 2016, 84: 97 DOI:10.1016/j.robot.2016.07.003
[19]KIM K H, CHEON Y, HONG S, et al. PVANet: deep but lightweight neural networks for real-time object detection[J]。 arXiv, 2016(8): 1
[20]EVERINGHAM M, ESLAMI S M A, GOOL L V, et al. The pascal, visual object classes challenge: a retrospective[J]。 International Journal of Computer Vision, 2015, 111(1): 98 DOI:10.1007/s11263-014-0733-5
[21]RUSSAKOVSKY O, DENG Jia, SU Hao, et al. ImageNet large scale visual recognition challenge[J]。 International Journal of Computer Vision, 2015, 115(3): 211 DOI:10.1007/s11263-015-0816-y
[22]ZHU Zhe, LIANG Dun, ZHANG Songhai, et al. Traffic-sign detection and classification in the wild[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2110-2118.
编辑:hfy









 工商网监
工商网监
评论