 电子发烧友App
电子发烧友App


近年来,深度学习在很多机器学习领域都有着非常出色的表现,在图像识别、语音识别、自然语言处理、机器人、网络广告投放、医学自动诊断和金融等领域有着广泛应用。面对繁多的应用场景,深度学习框架有助于建模者节省大量而繁琐的外围工作,更聚焦业务场景和模型设计本身。
使用深度学习框架完成模型构建有如下两个优势:
节省编写大量底层代码的精力:屏蔽底层实现,用户只需关注模型的逻辑结构。同时,深度学习工具简化了计算,降低了深度学习入门门槛。
省去了部署和适配环境的烦恼:具备灵活的移植性,可将代码部署到CPU/GPU/移动端上,选择具有分布式性能的深度学习工具会使模型训练更高效。
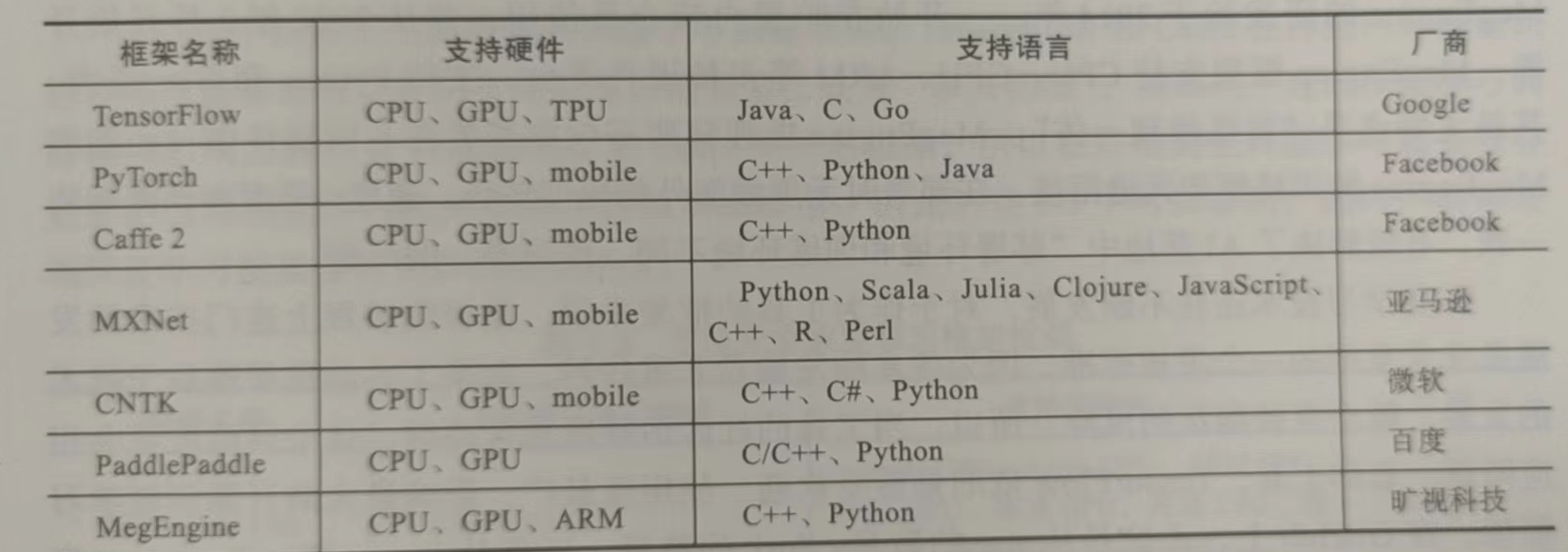
因此,在开始深度学习项目之前,选择一个合适的框架是非常重要的。目前,全世界最为流行的深度学习框架有PaddlePaddle、Tensorflow、Caffe、Theano、MXNet、Torch和PyTorch等。下面我们就来介绍一下目前主流的、以及一些刚开源但表现非常优秀的深度学习框架的各自特点,希望能够帮助大家在学习工作时作出合适的选择。
Theano
作为深度学习框架的祖师爷,Theano 的诞生为人类叩开了新时代人工智能的大门。Theano 的开发始于 2007 年的蒙特利尔大学,早期雏形由两位传奇人物 Yoshua Bengio 和 Ian Goodfellow 共同打造,并于开源社区中逐渐壮大。
Theano 基于 Python,是一个擅长处理多维数组的库,十分适合与其它深度学习库结合起来进行数据探索。它设计的初衷是为了执行深度学习中大规模神经网络算法的运算。其实,Theano 可以被更好地理解为一个数学表达式的编译器:用符号式语言定义你想要的结果,该框架会对你的程序进行编译,在 GPU 或 CPU 中高效运行。
Theano 的出现为人工智能在新时代的发展打下了强大的基础,在过去的很长一段时间内,Theano 都是深度学习开发与研究的行业标准。往后也有大量基于 Theano 的开源深度学习库被开发出来,包括 Keras、Lasagne 和 Blocks,甚至后来火遍全球的 TensorFlow 也有很多与 Theano 类似的功能。
随着更多优秀的深度学习开源框架陆续涌现,Theano 逐渐淡出了人们的视野。2013 年,Theano 创始者之一 Ian Goodfellow 加入 Google 开发 TensorFlow,标志着 Theano 正式退出历史舞台。目前仅有部分研究领域的学者会使用 Theano 进行一些学术研究。
Caffe&Caffe2
Caffe 是一个优先考虑表达、速度和模块化来设计的框架,它由贾扬清和伯克利人工智能实验室研究开发。支持 C、C++、Python等接口以及命令行接口。它以速度和可转性以及在卷积神经网络建模中的适用性而闻名。Caffe可以每天处理超过六千万张图像,只需单个NVIDIA K40 GPU,其中 1毫秒/图像用于推理,4毫秒/图像用于学习。
使用Caffe库的好处是从深度网络存储库“Caffe 模型Zoo”访问可用网络,这些网络经过预先培训,可以立即使用。通过Caffe Model Zoo框架可访问用于解决深度学习问题的预训练网络、模型和权重。这些模型可完成简单的递归、大规模视觉分类、用于图像相似性的SiameSE网络、语音和机器人应用等。
不过,Caffe 不支持精细粒度网络层,给定体系结构,对循环网络和语言建模的总体支持相当差,必须用低级语言建立复杂的层类型,使用门槛很高。Caffe2是由Facebook组织开发的深度学习模型,虽然使用门槛不像Caffe那样高,但仍然让不那么看重性能的开发者望而却步。另外,Caffe2继承了Caffe的优点,在速度上令人印象深刻。Facebook 人工智能实验室与应用机器学习团队合作,利用Caffe2大幅加速机器视觉任务的模型训练过程,仅需 1 小时就训练完ImageNet 这样超大规模的数据集。2018 年 3 月底,Facebook 将 Caffe2 并入 PyTorch,一度引起轰动。
Tensorflow
TensorFlow 是 Google 于 2015 年开源的深度学习框架。TensorFlow前身是谷歌的神经网络算法库 DistBelief,由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括 TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud 在内的多个项目以及各类应用程序接口。
TensorFlow 让用户可以快速设计深度学习网络,将底层细节进行抽象,而不用耗费大量时间编写底层 CUDA 或 C++ 代码。TensorFlow 在很多方面拥有优异的表现,比如设计神经网络结构的代码的简洁度,分布式深度学习算法的执行效率,还有部署的便利性(能够全面地支持各种硬件和操作系统)。
TensorFlow在很大程度上可以看作是Theano的后继者,不仅因为它们有很大一批共同的开发者,而且它们还拥有相近的设计理念,都是基于计算图实现自动微分系统。TensorFlow 使用数据流图进行数值计算,图中的节点代表数学运算,而图中的边则代表在这些节点之间传递的多维数组(张量)。
TensorFlow编程接口支持Python、C++、Java、Go、R和Haskell API的alpha版本。此外,TensorFlow还可在GoogleCloud和AWS中运行。TensorFlow还支持 Windows 7、Windows 10和Windows Server 2016。由于TensorFlow使用C++ Eigen库,所以库可在ARM架构上编译和优化。这也就意味着用户可以在各种服务器和移动设备上部署自己的训练模型,无须执行单独的模型解码器或者加载Python解释器。
TensorFlow构建了活跃的社区,完善的文档体系,大大降低了我们的学习成本,不过社区和文档主要以英文为主,中文支持有待加强。另外,TensorFlow有很直观的计算图可视化呈现。模型能够快速的部署在各种硬件机器上,从高性能的计算机到移动设备,再到更小的更轻量的智能终端。
不过,对于深度学习的初学者而言,TensorFlow的学习曲线太过陡峭,需要不断练习、探索社区并继续阅读文章来掌握TensorFlow的诀窍。
Keras
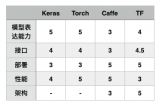
Keras用Python编写,可以在TensorFlow(以及CNTK和Theano)之上运行。TensorFlow的接口具备挑战性,因为它是一个低级库,新用户可能会很难理解某些实现。而Keras是一个高层的API,它为快速实验而开发。因此,如果希望获得快速结果,Keras会自动处理核心任务并生成输出。Keras支持卷积神经网络和递归神经网络,可以在CPU和GPU上无缝运行。
深度学习的初学者经常会抱怨:无法正确理解复杂的模型。如果你是这样的用户,Keras便是你的正确选择。它的目标是最小化用户操作,并使其模型真正容易理解。Keras的出现大大降低了深度学习应用的门槛,通过Keras的API可以通过数行代码就构建一个网络模型,曾几何时,Keras+Theano,Keras+CNTK的模式深得开发者喜爱。目前Keras整套架构已经封装进了TensorFlow,在TF.keras上可以完成Keras的所有事情。
如果你熟悉Python,并且没有进行一些高级研究或开发某种特殊的神经网络,那么Keras适合你。Keras的重点更多地放在取得成果上,而不是被模型的复杂之处所困扰。因此,如果有一个与图像分类或序列模型相关的项目,可以从Keras开始,很快便可以构建出一个工作模型。Keras也集成在TensorFlow中,因此也可以使用Tf.keras构建模型。
Pytorch
2017年1月,Facebook人工智能研究院(FAIR)团队在GitHub上开源了PyTorch,并迅速占领GitHub热度榜榜首。PyTorch的历史可追溯到2002年就诞生于纽约大学的Torch。Torch使用了一种不是很大众的语言Lua作为接口。Lua简洁高效,但由于其过于小众,用的人不是很多。在2017年,Torch的幕后团队推出了PyTorch。PyTorch不是简单地封装Lua Torch提供Python接口,而是对Tensor之上的所有模块进行了重构,并新增了最先进的自动求导系统,成为当下最流行的动态图框架。
Pytorch官网的标题语简明地描述了Pytorch的特点以及将要发力的方向。Pytorch在学术界优势很大,关于用到深度学习模型的文章,除了Google的,其他大部分都是通过Pytorch进行实验的,究其原因,一是Pytorch库足够简单,跟NumPy,SciPy等可以无缝连接,而且基于tensor的GPU加速非常给力,二是训练网络迭代的核心——梯度的计算,Autograd架构(借鉴于Chainer),基于Pytorch,我们可以动态地设计网络,而无需笨拙地定义静态网络图,才能去进行计算,想要对网络有任务修改,都要从头开始构建静态图。基于简单,灵活的设计,Pytorch快速成为了学术界的主流深度学习框架。
Pytorch的缺点则是前期缺乏对移动端的支持,因此在商用领域的普及度不及 TensorFlow 。在 2019 年,Facebook 推出 PyTorch Mobile 框架,弥补了 PyTorch 在移动端的不足,使得其在商用领域的发展有望赶超 TensorFlow 。不过现在,如果稍微深入了解TensorFlow和Pytorch,就会发现他们越来越像,TF加入了动态图架构,Pytorch致力于其在工业界更加易用。打开各自的官网,你也会发现文档风格也越发的相似。
PyTorch Lightning
PyTorch非常易于使用,可以构建复杂的AI模型。但是一旦研究变得复杂,并且将诸如多GPU训练,16位精度和TPU训练之类的东西混在一起,用户很可能会引入错误。PyTorch Lightning就可以完全解决这个问题。Lightning会构建你的PyTorch代码,以便可以抽象出训练的细节。这使得AI研究可扩展且可快速迭代。这个项目在GitHub上斩获了6.6k星。
Lightning将DL/ML代码分为三种类型:研究代码、工程代码、非必要代码。使用Lightning就只需要专注于研究代码,不需要写一大堆的 .cuda() 和 .to(device),Lightning会帮你自动处理。如果要新建一个tensor,可以使用type_as来使得新tensor处于相同的处理器上。此外,它会将工程代码参数化,减少这部分代码会使得研究代码更加清晰,整体也更加简洁。
PyTorch Lightning 的创建者WilliamFalcon,现在在纽约大学的人工智能专业攻读博士学位,并在《福布斯》担任AI特约作者。他表示,PyTorch Lightning是为从事AI研究的专业研究人员和博士生创建的。该框架被设计为具有极强的可扩展性,同时又使最先进的AI研究技术(例如TPU训练)变得微不足道。
PaddlePaddle
PaddlePaddle 的前身是百度于 2013 年自主研发的深度学习平台Paddle,且一直为百度内部工程师研发使用。PaddlePaddle 在深度学习框架方面,覆盖了搜索、图像识别、语音语义识别理解、情感分析、机器翻译、用户画像推荐等多领域的业务和技术。在 2016 年的百度世界大会上,前百度首席科学家 Andrew Ng首次宣布将百度深度学习平台对外开放,命名 PaddlePaddle,中文译名“飞桨”。
PaddlePaddle同时支持稠密参数和稀疏参数场景的超大规模深度学习并行训练,支持千亿规模参数、数百个几点的高效并行训练,也是最早提供如此强大的深度学习并行技术的深度学习框架。PaddlePaddle拥有强大的多端部署能力,支持服务器端、移动端等多种异构硬件设备的高速推理,预测性能有显著优势。PaddlePaddle已经实现了API的稳定和向后兼容,具有完善的中英双语使用文档,形成了易学易用、简洁高效的技术特色。
2019 年,百度还推出了多平台高性能深度学习引擎Paddle Lite(Paddle Mobile 的升级版),为 PaddlePaddle 生态完善了移动端的支持。
Deeplearning4j
DL4J 是由来自旧金山和东京的一群开源贡献者协作开发的。2014 年末,他们将其发布为 Apache 2.0 许可证下的开源框架。主要是作为一种平台来使用,通过这种平台来部署商用深度学习算法。创立于 2014 年的 Skymind 是 DL4J 的商业支持机构。2017 年 10 月,Skymind 加入了 Eclipse 基金会,并且将 DL4J 贡献给开源 Java Enterprise Edition 库生态系统。
DL4J是为java和jvm编写的开源深度学习库,支持各种深度学习模型。它具有为 Java 和 Scala 语言编写的分布式深度学习库,并且内置集成了 Apache Hadoop 和 Spark。Deeplearning4j 有助于弥合使用Python 语言的数据科学家和使用 Java 语言的企业开发人员之间的鸿沟,从而简化了在企业大数据应用程序中部署深度学习的过程。
DL4J主要有三大优势:
1. Python 可与 Java、Scala、Clojure 和 Kotlin 实现互操作性。Python为数据科学家所广泛采用,而大数据编程人员则在 Hadoop 和 Spark 上使用 Java 或 Scala 来开展工作。DL4J 填补了之间的鸿沟,开发人员因而能够在 Python 与 JVM 语言(例如,Java、Scala、Clojure 和 Kotlin)之间迁移。通过使用 Keras API,DL4J 支持从其他框架(例如,TensorFlow、Caffe、Theano 和 CNTK)迁移深度学习模型。甚至有人建议将 DL4J 作为 Keras 官方贡献的后端之一。
2. 分布式处理。DL4J 可在最新分布式计算平台(例如,Hadoop 和 Spark)上运行,并且可使用分布式 CPU 或 GPU 实现加速。通过使用多个 GPU,DL4J 可以实现与 Caffe 相媲美的性能。DL4J 也可以在许多云计算平台上运行。
3. 并行处理。DL4J 包含单线程选项和分布式多线程选项。这种减少迭代次数的方法可在集群中并行训练多个神经网络。因此,DL4J 非常适合使用微服务架构来设计应用程序。
CNTK
2015年8月,微软公司在CodePlex上宣布由微软研究院开发的计算网络工具集CNTK将开源。5个月后,2016年1月25日,微软公司在他们的GitHub仓库上正式开源了CNTK。早在2014年,在微软公司内部,黄学东博士和他的团队正在对计算机能够理解语音的能力进行改进,但当时使用的工具显然拖慢了他们的进度。于是,一组由志愿者组成的开发团队构想设计了他们自己的解决方案,最终诞生了CNTK。
根据微软开发者的描述,CNTK的性能比Caffe、Theano、TensoFlow等主流工具都要强。CNTK支持CPU和GPU模式,和TensorFlow/Theano一样,它把神经网络描述成一个计算图的结构,叶子节点代表输入或者网络参数,其他节点代表计算步骤。CNTK 是一个非常强大的命令行系统,可以创建神经网络预测系统。
CNTK 最初是出于在 Microsoft 内部使用的目的而开发的,一开始甚至没有Python接口,而是使用了一种几乎没什么人用的语言开发的,而且文档有些晦涩难懂,推广不是很给力,导致现在用户比较少。但就框架本身的质量而言,CNTK表现得比较均衡,没有明显的短板,并且在语音领域效果比较突出。
MindSpore
MindSpore是华为在今年3月召开的开发者大会上正式开源,MindSpore是一款支持端边云全场景的深度学习训练推理框架,当前主要应用于计算机视觉、自然语言处理等AI领域,旨在为数据科学家和算法工程师提供设计友好、运行高效的开发体验,提供昇腾AI处理器原生支持及软硬件协同优化。
MindSpore的特性是可以显著减少训练时间和成本(开发态)、以较少的资源和最高能效比运行(运行态),同时适应包括端、边缘与云的全场景(部署态),强调了软硬件协调及全场景部署的能力。因此,使用MindSpore的优势可以总结为四点:
简单的开发体验。帮助开发者实现网络自动切分,只需串行表达就能实现并行训练,降低门槛,简化开发流程;
灵活的调试模式。具备训练过程静态执行和动态调试能力,开发者通过变更一行代码即可切换模式,快速在线定位问题;
充分发挥硬件潜能。最佳匹配昇腾处理器,最大程度地发挥硬件能力,帮助开发者缩短训练时间,提升推理性能;
全场景快速部署。支持云、边缘和手机上的快速部署,实现更好的资源利用和隐私保护,让开发者专注于AI应用的创造。
MegEngine(天元)
MegEngine(天元)是今年3月正式开源的工业级深度学习框架,旷世也成为国内第一家开源AI框架的AI企业。天元可帮助开发者用户借助友好的编程接口,进行大规模深度学习模型训练和部署。架构上天元具体分为计算接口、图表示、优化与编译、运行时管理和计算内核五层,可极大简化算法开发流程,实现了模型训练速度和精度的无损迁移,支持动静态的混合编程和模型导入,内置高性能计算机视觉算子,尤其适用于大模型算法训练。
若说谷歌TensorFlow采用利于部署的静态图更适用于工业界,而Facebook PyTorch采用灵活且方便调试的动态图更适合学术科研。那么旷视的天元则在兼具了双方特性的过程中,找到了一个的平衡点。天元是一个训练和推理在同一个框架、同一个体系内完整支持的设计。基于这些创新性的框架设计,天元深度学习框架拥有推理训练一体化、动静合一、兼容并包和灵活高效四大优势:
训练推理:一体化天元既能够支持开发者进行算法训练,同时其训练得到的模型,还可以直接用于产品的推理和封装,无需进行多余的模型转换。这极大地简化了算法开发流程,实现速度和精度的无损迁移。与此同时,天元在模型部署时还能够自动优化模型,自动帮助开发者删除冗余代码。
动静合一:天元将动态图的简单灵活,与静态图的高性能优势进行整合,能在充分利用动态图模型训练优势的同时,通过动静态一键转换功能,以静态图的形式完成生产和部署。此外,天元还支持动静态的混合编程,进一步提高其灵活性。
兼容并包:天元部署了Pythonic的API和PyTorchModule功能,支持模型直接导入,进一步降低框架迁移的入门门槛和学习成本。同时,它内置高性能计算机视觉算子和算法,能够深度优化计算机视觉相关模型训练和应用。
灵活高效:在部署方面,天元拥有多平台多设备适应能力,其内置算子能够在推理或生产环境中充分利用多核优势,灵活调用设备算力,十分适用于大模型算法训练。
3月,旷视推出的天元是Alpha版本,其中包括旷视前期整理的代码和关键步骤。今年6月旷视推出了Beta版本,添加对ARM系列CPU的支持,以及更多加速芯片的支持。而天元的正式版本将于今年9月发布,除了添加对主流计算设备的支持外,还将升级其动态计算能力,进一步优化训练推理全流程的使用体验。与此同时,旷视天元已在GitHub和国内新一代人工智能开源开放社区OpenI上同步开源。
Jittor(计图)
Jittor 出自清华大学,开发团队来自清华大学计算机系图形学实验室,牵头者是清华大学计算机系胡事民教授。Jittor 是国内第一个由高校开源的深度学习框架,同时也是继 Theano、Caffe 之后,又一个由高校主导的框架。
与主流的深度学习框架TensorFlow、Pytorch不同,Jittor是一个完全基于动态编译(Just-in-time)、使用元算子和统一计算图的深度学习框架。Jittor 前端语言为 Python,使用了模块化的设计,类似于 PyTorch、Keras;后端则使用高性能语言编写,如 CUDA、C++。元算子和 Numpy 一样易于使用,而统一计算图则是融合了静态计算图和动态计算图的诸多优点,在易于使用的同时,提供高性能的优化。基于元算子开发的深度学习模型,可以被计图实时地自动优化并且运行在指定的硬件上,如 CPU、GPU。
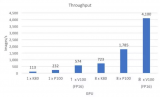
Jittor开发团队提供了实验数据。在ImageNet数据集上,使用Resnet50模型,GPU图像分类任务性能比PyTorch相比,提升32%;CPU图像分类任务提升11%。在CelebA数据集上,使用LSGAN模型,使用GPU处理图像生成任务,Jittor比PyTorch性能提升达51%。
此外,为了方便更多人上手Jittor,开发团队采用了和PyTorch较为相似的模块化接口,并提供辅助转换脚本,可以将PyTorch的模型自动转换成Jittor的模型。他们介绍称,在参数保存和数据传输上,Jittor使用和PyTorch一样的 Numpy+pickle 协议,所以Jittor和PyTorch的模型可以相互加载和调用。
当然, Jittor作为一个新兴深度学习框架,在一些功能上,仍旧需要持续迭代完善。比如生态的建设,以及更大范围的推广,仍旧需要很多的努力。Jittor开发团队介绍称,就目前来看,Jittor框架的模型支持还待完善,分布式功能待完善。这也是他们下一阶段研发的重点。
总的来说,各家的深度学习框架各有千秋,重要的是找到适合自己团队的,能够快速匹配团队的技术栈,快速试验以期发挥深度学习技术应用落地的商业价值。
编辑:hfy



















 工商网监
工商网监
评论