 电子发烧友App
电子发烧友App


随着深度学习在欧几里得空间的成功应用,例如CNN,RNN等极大的提高了图像分类,序列预测等任务的效果,近期来图神经网路也开始蓬勃发展。图神经网络分为谱域和空域两大种类,谱域通过拉普拉斯算子对于图进行类微分处理,而空域通过信息传递的方式更新节点的embedding,均可以大幅度提高节点预测,链接预测,不规则图形分类等问题的效果。
在大规模图数据上训练图神经网络是一个大问题,计算代价过大,内存消耗过高均是制约图神经网络在大图训练的因素。而近期来,加速图训练、优化内存的论文不断出现。以GraphSage,FastGCN,VR-GCN,GraphSaint,Cluster-GCN,L-GCN,L2-GCN等系列模型被提出,并且得到了令人瞩目的结果。美中不足的是,他们仍然没有做到亿级别数据的训练,最大的数据集不过是百万节点,如果在亿级别数据上进行训练,时间和空间复杂度都会是一个极大的考验。
SGC-Simplifying graph convolutional network 成为了最合适的替代品,在当今大图计算仍然没有一个最优且快的model的时候,在效果上退而求其次是不可避免的。SGC在训练效果上和原始GCN持平,但是在速度上有这不可比拟的优势,而且空间复杂度极小,具有在大图上训练的潜力。
本文使用了飞桨图学习框架PGL,同时调用了多个Paddle API,包括全连接层和数据读入以及优化函数。Paddle的优化函数具有出色的性能,加快了训练速度,使得训练效果有了良好的表现。首先非常推荐在AI Studio上面直接进行复现,AI Studio是一个很出色的平台,同时对于优质作者有很强的算力支持,笔者是直接在AI Studio上面编辑复现的。当然,PGL也可以部署到本地,有意向在本地运行PGL的可以查询PGL在github上的官网,从而实现本地部署。PGL的两个特点在于高速性和模块性,你可以很快的调动许多已有的module,而不需要底层实现,就可以完成一些论文的复现。
复现实现的难点往往在于特征的预处理,对于没有预处理的特征,直接上模型可能效果非常的差,甚至不如多层感知机,但是在预处理之后,往往能够达到论文的精确度和速度,笔者在复现的时候尝试过直接把存入的data输入至模型,但是效果非常差,大概只有50%左右的ACC,不如多层感知机。但是在经过一系列预处理后,可以直接复现论文水平。
本模型的特点在于模型简单,速度快,但精确度只是略好于多层感知机,稍逊于其他模型。但是在工业应用上,已经拥有了极高的价值。这里我们其实并没有调用PGL的库函数,例如GCN等。因为我们的模型很简单,并不需要调用已有模型,同时已有模型由于兼容性等原因会降低速度,所以我主要应用的是Paddle里面的nn.fc和decay_adam优化器,前者是全连接层,后者是有衰减值的adam优化器。笔者认为这两个函数,尤其是后者大大加速了训练。其次我们还使用了PGL的图训练框架来加速训练,也达到了很好的效果。笔者认为,上面三个函数是PGL+Paddle模型远远快于Pytorch的原因。
论文模型理解
在原始GCN上被分为多步完成的图卷积操作SGC通过一步就完成,同时得到了相同的效果,可以看出其优势。
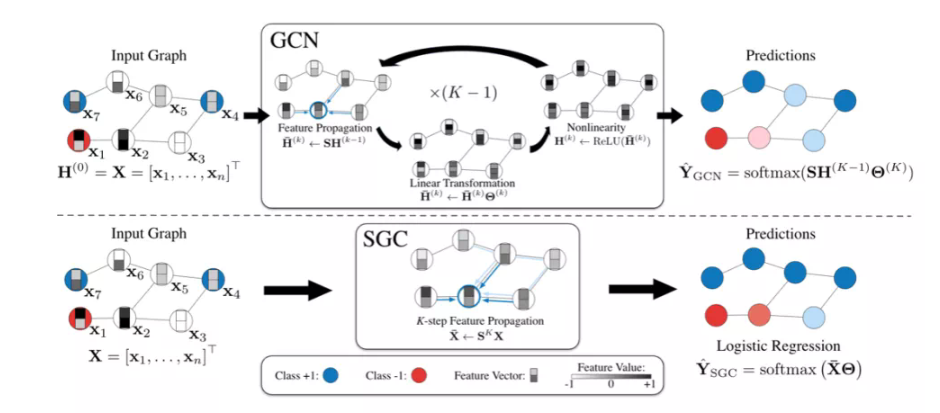
SGC最大的创新在于省去了激活函数,从而使得多个参数合成一个,减小了时间复杂度和空间复杂度。

论文模型复现过程
首先在AI Studio上安装PGL库函数和cython:
!pip install pgl
!pip install cython
这里对feature和adj矩阵都准备进行预处理,feature对行上进行归一化处理,adj通过degree准备进行normalization:
import scipy.sparse as sp
degree=dataset.graph.indegree()
norm = np.zeros_like(degree, dtype=“float32”)
norm[degree 》 0] = np.power(degree[degree 》 0],-1.0)
dataset.graph.node_feat[“norm”] = np.expand_dims(norm, -1)
def row_normalize(mx):
“”“Row-normalize sparse matrix”“”
rowsum = np.array(mx.sum(1))
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def aug_normalized_adjacency(adj):
adj = adj + sp.eye(adj.shape[0])
adj = sp.coo_matrix(adj)
row_sum = np.array(adj.sum(1))
d_inv_sqrt = np.power(row_sum, -0.5).flatten()
d_inv_sqrt[np.isinf(d_inv_sqrt)] = 0.
d_mat_inv_sqrt = sp.diags(d_inv_sqrt)
return d_mat_inv_sqrt.dot(adj).dot(d_mat_inv_sqrt).tocoo()
通过之前的到的信息,对于feature和adj进行归一化处理:
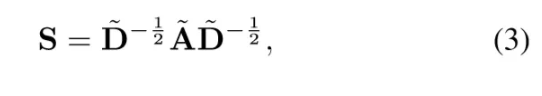
邻接矩阵的归一化方程:
def pre_sgc(dataset,feature,norm=None):
“”“
Implementation of Simplifying graph convolutional networks (SGC)
This is an implementation of the paper SEMI-SUPERVISED CLASSIFICATION
WITH Simplifying graph convolutional networks (https://arxiv.org/abs/1902.07153)。
Args:
gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
feature: A tensor with shape (num_nodes, feature_size)。
output: The output size for sgc.
activation: The activation for the output
name: Gcn layer names.
norm: If :code:`norm` is not None, then the feature will be normalized. Norm must
be tensor with shape (num_nodes,) and dtype float32.
Return:
A tensor with shape (num_nodes, hidden_size)
”“”
num_nodes=np.shape(feature)[0]
adj=np.zeros((num_nodes,num_nodes))
#print(np.shape(dataset.graph.edges))
for u in range(len(dataset.graph.edges)):
adj[dataset.graph.edges[u][0],dataset.graph.edges[u][1]]=adj[dataset.graph.edges[u][1],dataset.graph.edges[u][0]]=1
feature=dataset.graph.node_feat[‘words’]
feature=row_normalize(feature)
if norm==True:
adj=aug_normalized_adjacency(adj)
for i in range(args.degree):
feature=adj.dot(feature)
return feature
得到预处理的图算子:
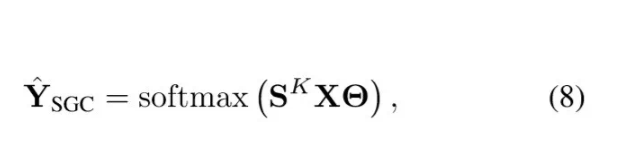
这里的K我们在args中设置,degree为2。进行训练并且得到结果,红色是train而绿色是validation:
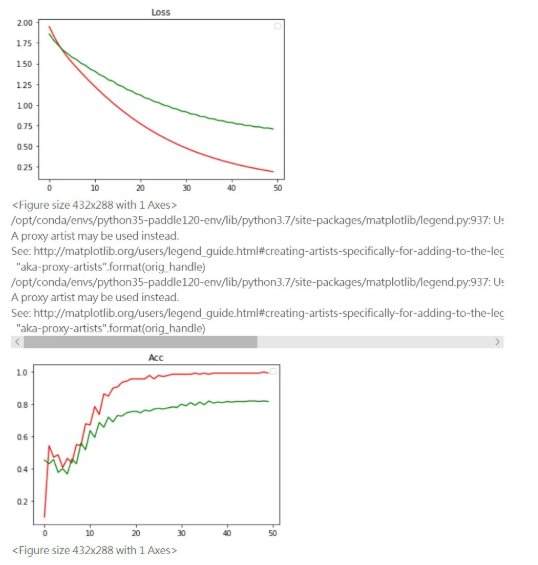
我们对比Pytorch的官方复现,要达到同样的效果,Pytorch需要100-150轮训练,我们利用PGL和Paddle可以在50轮甚至30轮达到收敛,速度极快!
正如之前开头所说的那样,我们需要的其实是工业应用图神经网络,而时间复杂度和空间复杂度往往是我们重点考虑的,Paddle在速度上的高效是其作为深度学习平台的优点,同时他的接口也是简单易懂,所以才可以迅速并简单的复现一篇论文。
编辑:hfy













 工商网监
工商网监
评论