 电子发烧友App
电子发烧友App


本文为大家介绍了机器学习中常用的决策树算法以及相关术语,并基于天气数据集进行决策树算法(ID3、CART算法)实现过程的手动推导。
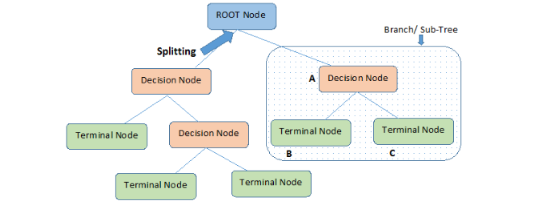
决策树是最重要的机器学习算法之一,其可被用于分类和回归问题。本文中,我们将介绍分类部分。
什么是决策树?
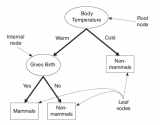
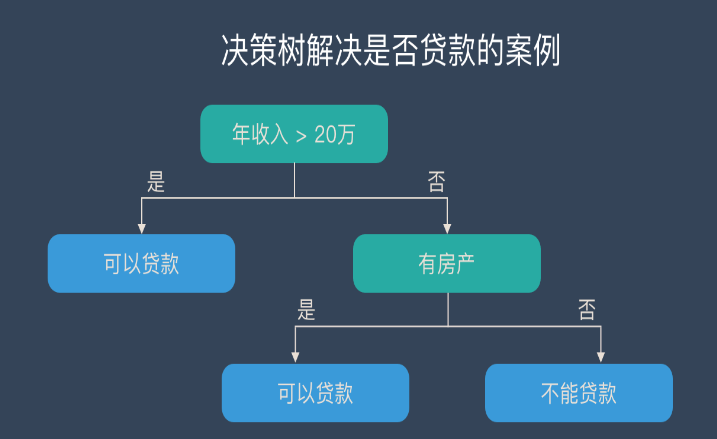
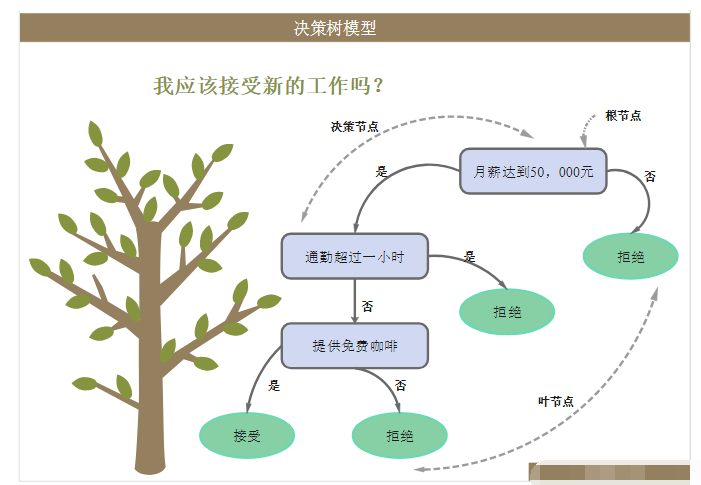
决策树(Decision Tree)是一个具有树形结构的分类和预测工具,其中的每个内部节点表示对属性的测试,每个分支代表测试的结果,并且每个叶子节点(终端节点)都有一个类别标签。
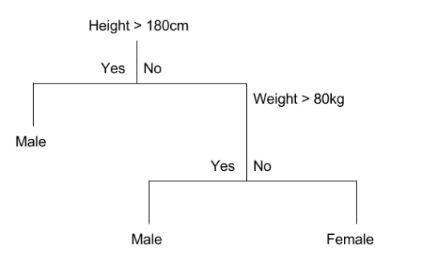
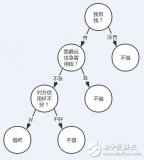
上图是一个小型决策树。决策树的一个重要优势在于其高度的可解释性。在上图中,如果身高大于180厘米或身高小于180厘米且体重大于 80公斤为男性,否则为女性。你是否思考过我们如何得到类似于上图的决策树,下面我将使用天气数据集对此进行解释。
在此之前,我将解释一下相关的术语。
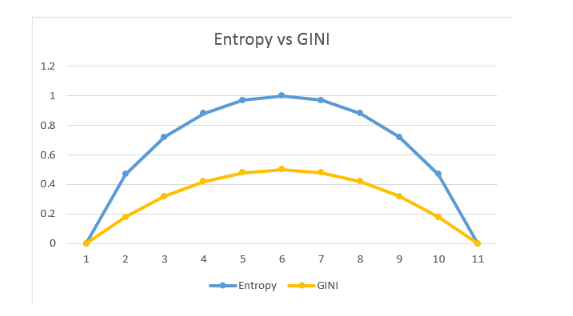
熵(Entropy)
在机器学习中,熵是对正在处理的信息中随机性的一种度量。熵越高,从该信息得出结论就越难。
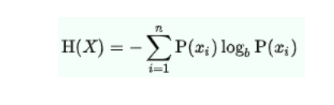
信息增益可以定义为随机变量或信号通过观察另一个随机变量所获得的信息量,其可以被视为父节点的熵与子节点的加权平均熵的差。
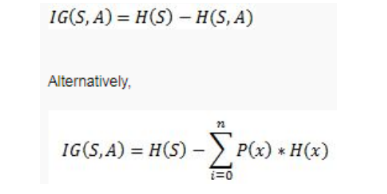
基尼不纯度(Gini Impurity)
基尼不纯度是一种度量方法,如果数据是根据子集中标签的分布被随机标记的,则基尼不纯度用来度量从集合中随机选择的数据被不正确标记的频率。
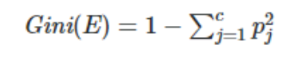
基尼不纯度的下界为0,如果数据集仅包含一个类别,那么基尼不纯度则为0。
有很多算法可以构建决策树。它们分别是:
1. CART(Classification and Regression Trees):使用基尼不纯度作为度量标准;
2. ID3(Iterative Dichotomiser 3):使用熵和信息增益作为度量标准。
本文将介绍ID3算法。一旦理解ID3后,就可以轻松地使用CART实现相同的功能。
使用ID3算法进行分类
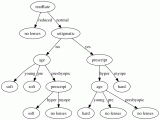
下面,我们基于天气数据集来确定是否踢足球。
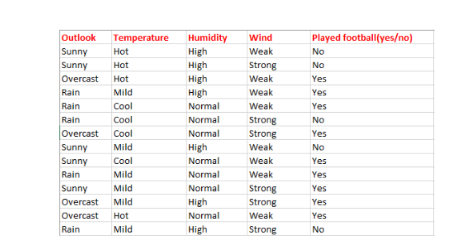
这里,自变量将决定因变量。其中,自变量是天气预报(outlook),温度(Temperature),湿度(Humidity)和风力(Wind),因变量是是否踢足球(Played football(yes/no))。
第一步,我们必须为决策树找到父节点。为此,有以下步骤:
1. 计算类别变量(即因变量)的熵。
E(S) = -[(9/14)log(9/14) + (5/14)log(5/14)] = 0.94
注意:这里通常将对数的底数设置为2。这里共有14个“yes/no”。其中有9个是“y
es”,5个“no”。在此基础上,我们计算出了上面的概率。
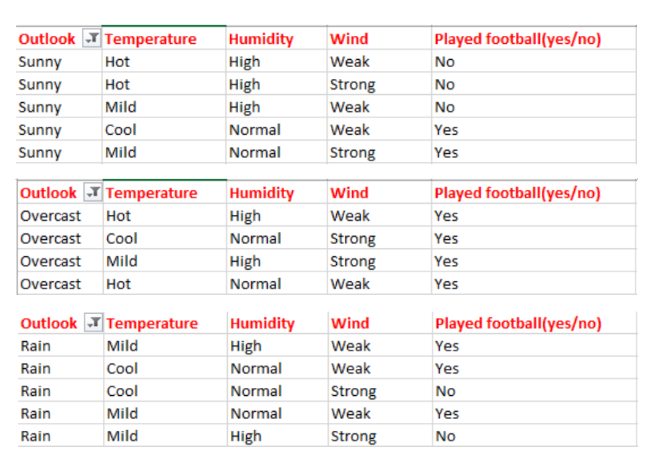
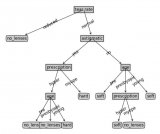
从上面天气预报(outlook)的数据中,我们可以轻松得到下表:
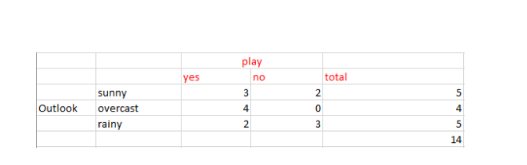
2. 现在我们需要计算加权平均熵,即我们已经计算出的每个特征的权重总和乘以概率。
E(S, outlook) = (5/14)*E(3,2) + (4/14)*E(4,0) + (5/14)*E(2,3) = (5/14)(-(3/5)log(3/5)-(2/5)log(2/5))+ (4/14)(0) + (5/14)((2/5)log(2/5)-(3/5)log(3/5)) = 0.693
下一步是计算信息增益,它是上面我们计算的父节点的熵与加权平均熵之间的差。
IG(S, outlook) = 0.94 - 0.693 = 0.247
类似地,计算温度(Temperature)、湿度(Humidity)和风力(Wind)的信息增益。
IG(S, Temperature) = 0.940 - 0.911 = 0.029
IG(S, Humidity) = 0.940 - 0.788 = 0.152
IG(S, Windy) = 0.940 - 0.8932 = 0.048
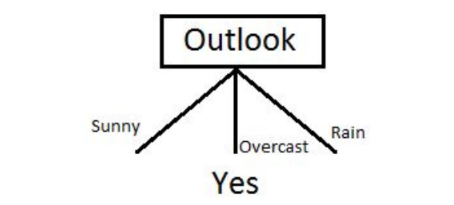
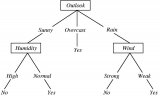
现在选择具有最大熵增益的特征。天气预报(outlook)特征是有最大熵增益的特征,因此它构成了决策树的第一个节点(根节点)。
现在我们的数据如下所示:
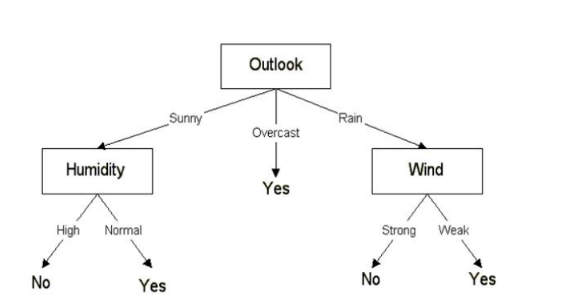
由于在天气预报(Outlook)特征为多云(overcast)时,因变量的结果仅仅有“Yes”这一种类别,因此我们可以将其设置为“Yes”。这意味着如果天气预报(outlook)特征为多云(overcast),我们就可以踢足球。现在我们的决策树如下所示。
接下来是在决策树中找到下一个节点。我们在晴天(sunny)下找一个节点。我们需确定在温度(Temperature)、湿度(Humidity)或风力(Wind)中谁有更高的信息增益。
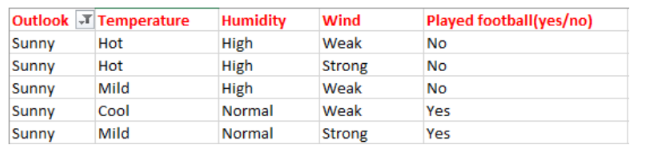
计算父节点晴天(sunny)的熵E(sunny):
E(sunny) = (-(3/5)log(3/5)-(2/5)log(2/5)) = 0.971
计算温度(Temperature)的信息增益IG(sunny, Temperature):
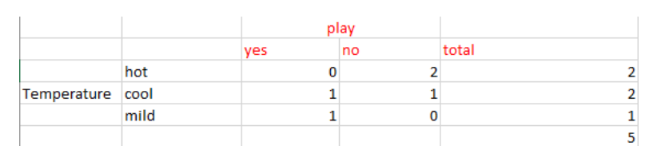
E(sunny, Temperature) = (2/5)*E(0,2) + (2/5)*E(1,1) + (1/5)*E(1,0)=2/5=0.4
现在计算信息增益:
IG(sunny, Temperature) = 0.971–0.4 =0.571
类似地,我们可以得到:
IG(sunny, Humidity) = 0.971
IG(sunny, Windy) = 0.020
这里的IG(sunny, Humidity)是最大值。因此,湿度(Humidity)是晴天(sunny)的子节点。
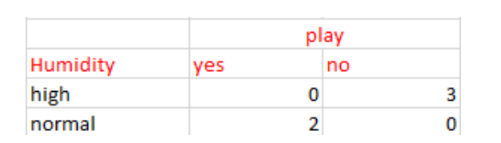
对于上表中的湿度(Humidity),如果湿度正常(normal),则因变量为“Yes”;如果湿度高(high),则因变量为“No”。与上面方法类似,我们可以找到下雨(Rain)的子节点。
注意:熵大于0的分支需要进一步拆分。
最终,我们可以得到如下的决策树:
使用CART算法进行分类
使用CART进行分类的过程与ID3算法类似,但是其使用基尼不纯度来替代熵作为度量标准。
1. 第一步我们需找到决策树的根节点,为此需计算因变量的基尼不纯度。
Gini(S) = 1 - [(9/14)² + (5/14)²] = 0.4591
2. 下一步,我们将计算基尼增益(Gini Gain)。
首先,我们要找到天气预报(Outlook)、温度(Temperature)、湿度(Humidity)和风力(Wind)的加权平均基尼不纯度。
首先考虑天气预报(Outlook):
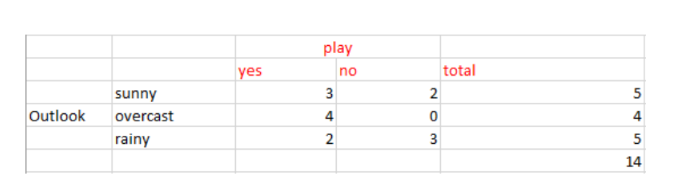
Gini(S, outlook) = (5/14)gini(3,2) + (4/14)*gini(4,0)+ (5/14)*gini(2,3) = (5/14)(1 - (3/5)² - (2/5)²) + (4/14)*0 + (5/14)(1 - (2/5)² - (3/5)²)= 0.171+0+0.171 = 0.342
Gini gain (S, outlook) = 0.459 - 0.342 = 0.117
Gini gain (S, Temperature) = 0.459 - 0.4405 = 0.0185
Gini gain (S, Humidity) = 0.459 - 0.3674 = 0.0916
Gini gain(S, windy) = 0.459 - 0.4286 = 0.0304
我们需要选择一个具有最高基尼增益的特征,天气预报(outlook)的基尼增益最高,因此我们可以选择它作为我们的根节点。
现在,你应该知道了如何进行接下来的操作,即重复我们在ID3算法中的相同步骤。
决策树的优缺点
优点:
决策树具有高度可解释性;
需要很少的数据预处理;
适用于低延迟应用。
缺点:
很可能对噪声数据产生过拟合。决策树越深,由噪声产生过拟合的可能性就越大。一种解决方案是对决策树进行剪枝。
编辑:hfy






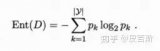




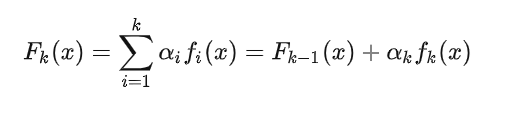







 工商网监
工商网监
评论