 电子发烧友App
电子发烧友App


机器学习正在从云端转移到网络边缘,目的是进行实时处理、降低延迟、提高安全性、更高效地使用可用带宽以及降低整体功耗。而处于这些边缘节点上的物联网 (IoT) 设备只有有限的资源,因此开发人员需要弄清如何有效地添加这一全新的智能水平。
在边缘位置基于微控制器系统使用机器学习,为开发人员提供了几项新机会,可以彻底改变他们设计系统的方式。开发人员可以使用几种不同的架构和技术将智能添加到边缘节点。学习完本文后,我们将更加熟悉这些架构以及一些可用于加快该过程的技术。
边缘机器学习的作用
边缘机器学习对嵌入式系统工程师非常有用,原因有很多。首先,智能系统可以解决开发人员通常难以通过编码解决的问题。以简单的文本识别为例。识别文本是编程的噩梦,但如果使用机器学习,那么几乎就像用 C 语言编写“Hello World”应用程序一样简单。
其次,智能系统可以很轻松地针对新数据和情况进行扩展。例如,如果某个系统接受了识别基本文本的训练,然后突然采用新字体提供文本,这时并不需要推倒重来。相反,只需提供额外的训练图像,使该网络也能学习识别新字体便可。
最后,我们还可以了解到,边缘机器学习可以帮助开发人员降低某些应用类型的成本,例如:
第一次检查边缘机器学习时,使用应用处理器似乎是个不错的选择。包括 OpenCV 在内的几种开源工具专为计算机视觉而设计,我们可以从使用这些工具开始。不过,许多应用中仅使用应用处理器可能还不够,因为这些处理器不具备确定性的实时行为。
边缘机器学习架构
使用边缘机器学习时,有三种典型方法:
边缘节点获取数据,然后在云端完成机器学习
边缘节点获取数据,然后在芯片上完成机器学习
边缘节点获取数据,然后在边缘进行第一遍机器学习,最后在云端进行更深入的分析
前两个解决方案是目前业界探索最多的解决方案,在本文中,我们将会重点关注这两个解决方案。
使用边缘设备获取数据并使用基于云的机器学习系统来处理数据,这样的架构有几个优点。首先,边缘设备不需要运行机器学习算法所需的强大处理能力和资源。其次,边缘设备可以继续使用资源受限的低成本设备,就像许多嵌入式系统开发人员习惯创建的系统一样。唯一的区别是,边缘设备需要能够通过 HTTPS 连接到基于云的服务提供商,以便分析它们的数据。第三,基于云的机器学习正在以惊人的速度发展,将这些功能转移到片载解决方案将非常困难、耗时且成本高昂。
对于希望从基于云的机器学习开始的开发人员来说,他们可以使用 STMicroelectronics 公司的 STM32F779I-EVAL 板(图 1)这类开发板。该开发板基于 STMicroelectronics 公司的 STM32F769NIH6 微控制器,配备了 Arm® Cortex®-M7 内核、板载摄像头、用于与云进行高速通信的以太网端口,以及板载显示器。该开发板可与诸如 Express Logic 公司的 X-Ware IoT 平台等软件配合使用,轻松连接到任何机器学习云提供商,如 Amazon Web Services (AWS)、Microsoft Azure 和 Google Cloud。

图 1:STM32F779I-EVAL 板基于 Arm Cortex-M7 处理器,包含了进行片载或云端深度学习所需的一切资源。(图片来源:STMicroelectronics)
在云端进行机器学习对于开发团队来说可能意义非常重大,但有几个原因可以解释为什么机器学习开始从云端转向边缘。虽然这些原因具有很强的应用针对性,但确实也包括了一些重要因素,例如:
- 实时处理需求
- 带宽限制
- 延迟
- 安全要求
如果某个应用存在这方面的问题,那么将神经网络从云端转移到边缘是可以行得通的。这种情况下,开发人员必须对他们希望嵌入式处理器负责处理的内容做到心里有数,以便应用能够尽可能高效地执行。
选择用于机器学习的处理器
在嵌入式处理器上运行机器学习需要考虑几个重要因素。首先,处理器必须能够高效地执行 DSP 指令,因此浮点运算单元 (FPU) 非常有用。其次,需要具备可以在处理器上运行的机器学习库。学习库需要包括卷积、池化和激活。如果没有这些学习库,开发人员基本上需要从头开始编写深度学习算法,不但费时,而且成本高昂。
最后,开发人员需要确保微控制器上具有足够的 CPU 周期,以便可以完成神经网络执行以及分配给处理器的任何其他任务。
Arm Cortex-M 处理器现在配有 CMSIS-NN 扩展,这是一个神经网络库,其设计目的是在资源受限的环境中可以在微控制器上高效地运行机器学习,这一特性使其成为基于边缘的智能系统的绝佳选择。确切的处理器选择将取决于手头的应用,因此详细了解几款不同的开发板及其最适合的应用非常重要。
首先介绍 SparkFun Electronics 公司的 OpenMV 机器视觉开发板(图 2)。该模块采用基于 Cortex-M7 的 STM32F765VI 处理器,运行频率 216 MHz,支持 512 KB RAM 和 2 MB 闪存。

图 2:SparkFun 的 OpenMV 开发板是一个机器视觉平台,该平台使用 Arm CMSIS-NN 框架在 Cortex-M 上高效运行机器学习算法。(图片来源:SparkFun Electronics)
OpenMV 模块可用于:
- 通过帧差分检测运动
- 颜色跟踪
- 市场跟踪
- 人脸检测
- 眼动跟踪
- 线条和形状检测
- 模板匹配
由于该模块的软件基于 Arm CMSIS-NN 库,因此可以在处理器上尽可能高效地运行机器学习网络。
其次介绍 STM32F746ZG Nucleo 开发板,STMicroelectronics 公司基于 Arm Cortex-M7 的 STM32F746 处理器使用的就是这款开发板,运行频率为 216 MHz(图 3)。与 OpenMV 模块上的处理器相比,这款开发板上使用的处理器具有较少的内存和闪存,分别为 320 KB 和 1 MB。Arm 在许多机器学习白皮书中都使用了这款处理器,这些白皮书涵盖了诸如关键字识别之类的主题。

图 3:STM32F746ZG Nucleo 开发板是一款低成本开发板,适用于那些刚开始使用机器学习,不需要附加各种“花哨”功能的开发人员。(图片来源:STMicroelectronics)
这款开发板更大程度上提供的是一种开放平台,适用于原型开发以及使用大量 I/O 和外设的系统。它包括一个以太网端口、USB OTG、三个 LED、两个用户和重置按钮以及用于 ST Zio(包括 Arduino Uno V3)和 ST Morpho 的扩展板连接器。
最后介绍 NXP Semiconductors 公司的 IMXRT1050-EVKB 开发板,该公司的 i.MX RT 1050 处理器使用的就是这款开发板,运行频率高达 600 MHz(图 4)。该处理器仍然基于 Cortex-M7 架构,但却拥有很强的机器学习算法执行能力。因此,这是一个很棒的通用平台,开发人员可以使用它来试验和调整他们对机器学习的理解。该处理器内含 512 kB 紧耦合内存 (TCM),并且能够使用外部 NOR、NAND 或 eMMC 闪存。

图 4:NXP 的 i.MX RT1050 基于 Arm Cortex-M7 架构,但同时还融合了 NXP 的 Cortex-A i.MX 系列处理器的最佳功能。RT1050 是一款高端处理器,能够提供出色的机器学习体验。(图片来源:NXP Semiconductors)
了解 CMSIS-NN 的作用
即使机器学习从云端转移到网络边缘,在微控制器上运行机器学习框架也不切实际,认识到这一点非常重要。微控制器可以运行框架的输出,即经过训练的网络,但仅此而已。Arm-NN 能够将在高端机器上运行的经过训练的模型转换为可在微控制器上运行的低级代码。为 Arm-NN 提供 API 的低级库即是 CMSIS-NN。
如前所述,CMSIS-NN 包含用于常见机器学习活动的 API 和库函数,例如:
- 卷积
- 池化
- 激活
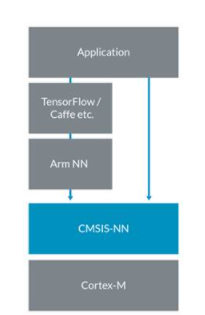
图 5:Arm-NN 利用 CMSIS-NN 库将高端机器上执行的经过训练的模型转换为可在 Cortex-M 处理器上运行的低级代码。(图片来源:Arm)
使用边缘机器学习的技巧和窍门
有很多技术可以帮助改进边缘机器学习。以下是一些技巧和窍门,可以帮助那些有兴趣架设和运行自己的机器学习系统的开发人员:
如果不考虑延迟,可以使用边缘收集数据,并使用云端通过机器学习网络来处理数据
将机器学习分流到云端时,除非您计划未来将机器学习转移到边缘设备,否则请不要过度选择边缘设备所需的处理能力
当实时性能至关重要时,请使用高性能的 Arm Cortex-M7 处理器来执行边缘机器学习网络
阅读 Ian Goodfellow、Yoshua Bengio、Aaron Courville 和 Francis Bach 编写的《深度学习》,了解机器学习背后的理论和数学知识
从云端或 PC 开始,然后按照自己的方式达成嵌入式目标
创建一个可以识别手写数字的“Hello World”应用程序
查看关于关键字识别和语音识别的 Arm 论文
购买开发套件并复制一个示例
结论
智能正在迅速从云端向边缘转移。从将机器学习完全分流到云端,到在边缘上运行经过训练的机器学习算法,目前有三种不同的方法可供开发人员选择。运行边缘机器学习需要具有高性能和 DSP 功能的微控制器。Arm Cortex-M7 处理器非常适合架设和运行边缘机器学











 工商网监
工商网监
评论