 电子发烧友App
电子发烧友App


本质上,深度学习是一个新兴的时髦名称,衍生于一个已经存在了相当长一段时间的主题——神经网络。
从20世纪40年代开始,深度学习发展迅速,直到现在。该领域取得了巨大的成功,深度学习广泛运用于智能手机、汽车和许多其他设备。
那么,什么是神经网络,它可以做什么?
现在,一起来关注计算机科学的经典方法:
程序员们准确地设计函数f(x)的所有逻辑:
y = f(x)
其中x和y分别是输入数据和输出数据
但是,有时设计 f(x) 可能并不那么容易。例如,假设x是面部图像,y是通信员的名字。对于大脑来说,这项任务非常容易,而计算机算法却难以完成!
这就是深度学习和神经网络大显神通的地方。
基本原则是:放弃 f() 算法,试着模仿大脑。
那么,大脑是如何表现的?
大脑使用几个无限对 (x,y) 样本(训练集)不断训练,在这个过程中,f(x) 函数会自动形成。它不是由任何人设计的,而是从无休止的试错法提炼机制中形成的。
想想一个孩子每天看着周围熟悉的人:数十亿个快照,取自不同的位置、视角、光线条件,每次识别都要进行关联,每次都要修正和锐化自然神经网络。
人工神经网络是由大脑中的神经元和突触组成的自然神经网络模型。
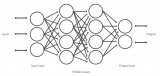
典型的神经网络结构
为了保持简单,并且利用当今机器的数学和计算能力,可以将神经网络设计为一组层,每层包含节点(大脑神经元的人工对应物),其中层中的每个节点连接到下一层中的节点。
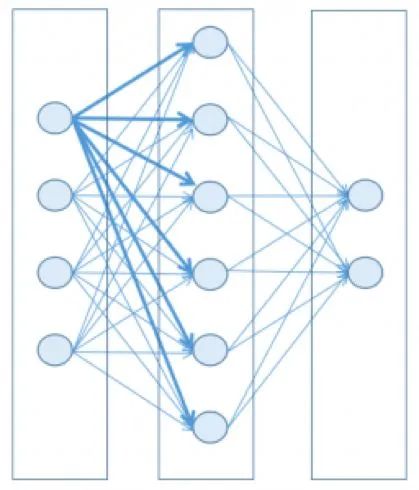
每个节点都有一个状态,通过浮点数表示,其取值范围通常介于0到1。该状态接近其最小值时,该节点被认为是非活动的(关闭),而它接近最大值时,该节点被认为是活动的(打开)。可以把它想象成一个灯泡;不严格依赖于二进制状态,但位于取值范围内的某个中间值。
每个连接都有一个权重,因此前一层中的活动节点或多或少地会影响到下一层中节点的活动(兴奋性连结),而非活动节点不会产生任何影响。
连接的权重也可以是负的,这意味着前一层中的节点(或多或少地)对下一层中的节点的不活动性(抑制性连结)产生影响。
简单来说,现在假设一个网络的子集,其中前一层中的三个节点与下一层中的节点相连结。简而言之,假设前一层中的前两个节点处于其最大激活值(1),而第三个节点处于其最小值(0)。
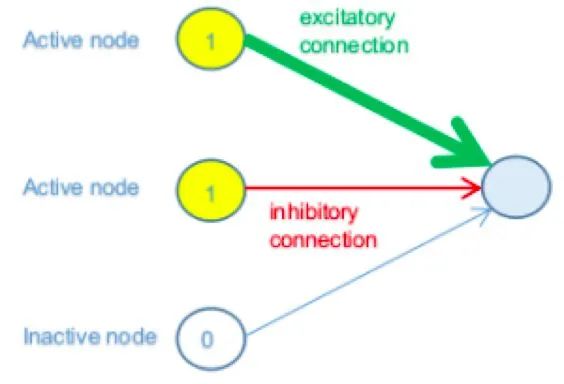
在上图中,前一层中的前两个节点是活动的(开),因此,它们对下一层中节点的状态有所贡献,而第三个节点是非活动的(关),因此它不会以任何方式产生影响(独立于其连结权重)。
第一个节点具有强(厚)正(绿色)连接权重,这意味着它对激活的贡献很大。第二个具有弱(薄)负(红色)连接权重;因此,它有助于抑制连接节点。
最后,得到了来自前一层的传入连接节点的所有贡献值的加权和。
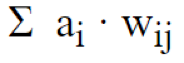
其中i是节点 i 的激活状态,w ij是连接节点 i 和节点 j 的连接权重。
那么,给定加权和,如何判断下一层中的节点是否会被激活?规则真的像“总和为正即被激活,结果为负则不会”?有可能,但一般来说,这取决于你为这个节点选择哪个激活函数及阈值)。
想一想。这个最终数字可以是实数范围内的任何数字,我们需要使用它来设置更有限范围内的节点状态(假设从0到1)。然后将第一个范围映射到第二个范围,以便将任意(负数或正数)数字压缩到0到1的范围内。
sigmoid 函数是执行此任务的一个常见激活函数。
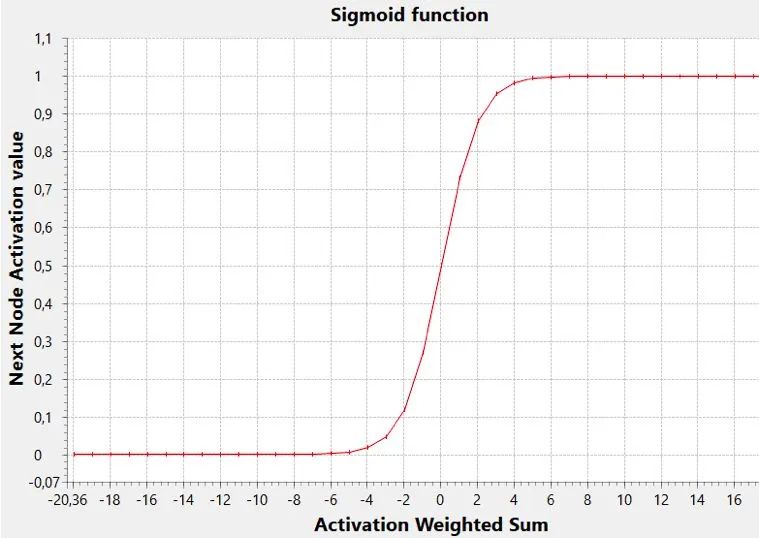
在该图中,阈值(y 值达到范围中间的 x 值,即0.5)为零,但一般来讲,它可以是任何值(负数或正数,其变化影响sigmoid向左或向右移动)。
低阈值允许使用较低的加权和激活节点,而高阈值将仅使用该和的高值确定激活。
该阈值可以通过考虑前一层中的附加虚节点来实现,其激活值恒定为 1。在这种情况下,该虚节点的连接权重可以用作阈值,并且上文提到的和公式可以被认为包括阈值本身。
最终,网络的状态由其所有权重的一组值来表示(从广义上讲,包括阈值)。
给定状态或一组权重值可能会产生不良结果或大错误,而另一个状态可能会产生良好结果,换句话说,就是小错误。
因此,在N维状态空间中移动会造成小错误或大错误。损失函数能将权重域映射到错误值的函数。在n+1空间里,人们的大脑很难想象这样的函数。但是,对于N = 2是个特殊情况。
训练神经网络包括找到最小的损失函数。为什么是最佳最小值而不是全局最小值?其实是因为这个函数通常是不可微分的,所以只能借助一些 梯度下降技术在权重域中游荡,并避免以下情况:
做出太大的改变,可能你还没意识到就错过最佳最小值
做出太小的改变,你可能会卡在一个不太好的局部最小值
不容易,对吧?这就是深度学习的主要问题,也解释了为什么训练阶段可能要花数小时、数天甚至数周。
这就是为什么硬件对于此任务至关重要,同时也解释了为什么经常需要暂停,考虑不同的方法和配置参数来重新开始。
现在回到网络的一般结构,这是一堆层。第一层是输入数据 (x),而最后一层是输出数据 (y)。
中间的层可以是零个、一个或多个。它们被称为隐藏层,深度学习中的“深度”一词恰好指的是网络可以有许多隐藏层,因此可能在训练期间找到更多关联输入和输出的特征。
提示:在20世纪90年代,你会听说过多层网络而不是深度网络,但这是一回事。现在,越来越清楚的是,筛选层离输入层越远(深),就能越好地捕捉抽象特征。
学习过程
在学习过程开始时,权重是随机设置的,因此第一层中的给定输入集将传送并生成随机(计算)输出数据。将实际输出数据与期望输出数据进行比较;其差异就是网络误差(损失函数)的度量。
然后,此错误用于调整生成它的连接权重,此过程从输出层开始,逐步向后移动到第一层。
调整的量可以很小,也可以很大,并且通常在称为学习率的因素中定义。
这种算法称为反向传播,并在Rumelhart,Hinton和Williams研究之后,于1986年开始流行。
记住这个名字:杰弗里·辛顿 (Geoffrey Hinton),他被誉为“深度学习的教父”,是一位孜孜不倦的科学家,为他人指引前进方向。例如,他现在正在研究一种名为胶囊神经网络 (Capsule Neural Networks) 的新范式,听起来像是该领域的另一场伟大革命!
反向传播旨在通过对训练每次集中迭代的权重进行适当的校正,来逐渐减少网络的整体误差。另外,减少误差这个步骤很困难,因为不能保证权重调整总是朝着正确的方向进行最小化。
简而言之,你戴着眼罩走来走去时,在一个n维曲面上找到一个最小值:你可以找到一个局部最小值,但永远不知道是否可以找到更小的。
如果学习率太低,则该过程可能过于缓慢,并且网络也可能停滞在局部极小值。另一方面,较高的学习率可能导致跳过全局最小值并使算法发散。
事实上,训练阶段的问题在于,错误只多不少!
现状
为什么这个领域现在取得如此巨大的成功?
主要是因为以下两个原因:
训练所需的大量数据(来自智能手机、设备、物联网传感器和互联网)的可用性
现代计算机的计算能力可以大大缩短训练阶段(训练阶段只有几周甚至几天的情况很常见)
想了解更多?这里有几本好书推荐:
亚当•吉布森(Adam Gibson)和 乔希·帕特森(Josh Patterson)所著的《深度学习》,O’Reilly媒体出版社。
莫希特·赛瓦克(Mohit Sewark)、默罕默德·礼萨·卡里姆(Md Rezaul Karim)和普拉蒂普·普贾里(Pradeep Pujari)所著的《实用卷积神经网络》, Packt出版社。
审核编辑 :李倩















 工商网监
工商网监
评论