 电子发烧友App
电子发烧友App


来源:
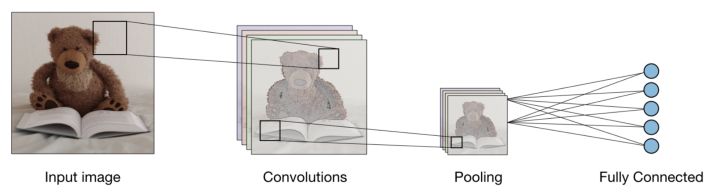
在当今时代,机器在理解和识别图像中的特征和目标方面已经成功实现了99%的精度。我们每天都会看到这种情况-智能手机可以识别相机中的面部;使用Google图片搜索特定照片的能力;从条形码或书籍中扫描文本。借助卷积神经网络(CNN),这一切都是可能的,卷积神经网络是一种特定类型的神经网络,也称为卷积网络。
如果您是一名深度学习爱好者,那么您可能已经听说过卷积神经网络,也许您甚至自己开发了一些图像分类器。像Tensorflow和PyTorch这样的现代深度学习框架使向机器学习图像变得容易,但是,仍然存在一些问题:数据如何通过神经网络的人工层传递?计算机如何从中学习?更好地解释卷积神经网络的一种方法是使用PyTorch。因此,让我们通过可视化每个图层的图像来深入研究CNN。
卷积神经网络的解释 什么是卷积神经网络?
卷积神经网络(CNN)是一种特殊类型的神经网络,在图像上表现特别出色。卷积神经网络由Yan LeCun在1998年提出,可以识别给定输入图像中存在的数字。
在开始使用卷积神经网络之前,了解神经网络的工作原理很重要。神经网络模仿人脑如何解决复杂的问题并在给定的数据集中找到模式。在过去的几年中,神经网络席卷了许多机器学习和计算机视觉算法。
神经网络的基本模型由组织在不同层中的神经元组成。每个神经网络都有一个输入层和一个输出层,并根据问题的复杂性增加了许多隐藏层。一旦数据通过这些层,神经元就会学习并识别模式。神经网络的这种表示称为模型。训练完模型后,我们要求网络根据测试数据进行预测。如果您不熟悉神经网络,那么这篇有关使用Python进行深度学习的文章就是一个很好的起点。 另一方面,CNN是一种特殊的神经网络,在图像上表现特别出色。卷积神经网络由Yan LeCun在1998年提出,可以识别给定输入图像中存在的数字。使用CNN的其他应用程序包括语音识别,图像分割和文本处理。在卷积神经网络之前,多层感知器(MLP)用于构建图像分类器。
图像分类是指从多波段光栅图像中提取信息类别的任务。多层感知器需要更多的时间和空间来在图片中查找信息,因为每个输入功能都需要与下一层的每个神经元相连。CNN通过使用称为本地连接的概念取代了MLP,该概念涉及将每个神经元仅连接到输入体积的本地区域。通过允许网络的不同部分专门处理高级功能(如纹理或重复图案),可以最大程度地减少参数数量。感到困惑?别担心。让我们比较一下图像如何通过多层感知器和卷积神经网络进行传递的,以更好地理解。
比较MLPS和CNNS 考虑到MNIST数据集,由于输入图像的大小为28x28 = 784,多层感知器输入层的总数将为784。 网络应该能够预测给定输入图像中的数量,这意味着输出可能属于以下范围中的任何一个,范围从0到9(1、2、3、4、5、6、7、8、9 )。 在输出层中,我们返回类别分数,例如,如果给定的输入是具有数字“ 3”的图像,则在输出层中,对应的神经元“ 3”比其他神经元具有更高的类别分数。 我们需要包含多少个隐藏层,每个层中应该包含多少个神经元?这是一个编码MLP的示例:
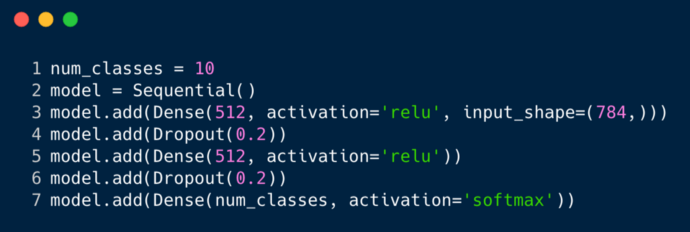
上面的代码段是使用称为Keras的框架实现的(暂时忽略语法)。它告诉我们在第一个隐藏层中有512个神经元,它们连接到形状为784的输入层。该隐藏层之后是一个随机失活层,该层克服了过拟合的问题。0.2表示在第一个隐藏层之后不考虑神经元的可能性为20%。再次,我们在第二个隐藏层中添加了与第一个隐藏层中相同数量的神经元(512),然后添加了另一个随机失活。最后,我们用包含10个类的输出层结束这组层。具有最高值的此类将是模型预测结果。
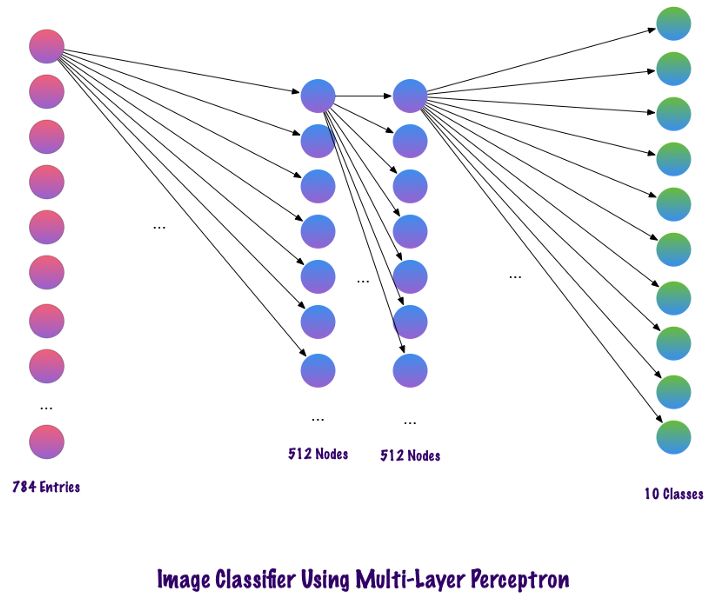
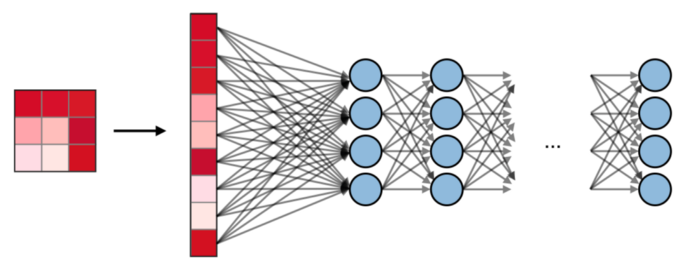
这是定义所有层之后的网络多层外观。这种多层感知器的一个缺点是全连接的以供网络学习,这需要更多的时间和空间。MLP仅接受向量作为输入。
卷积层不使用全连接层,而是使用稀疏连接层,也就是说,它们接受矩阵作为输入,这比MLP更具优势。输入特征连接到本地编码节点。在MLP中,每个节点负责获得对整个画面的理解。在CNN中,我们将图像分解为区域(像素的局部区域)。每个隐藏节点都必须输出层报告,在输出层,输出层将接收到的数据组合起来以找到模式。下图显示了各层如何本地连接。
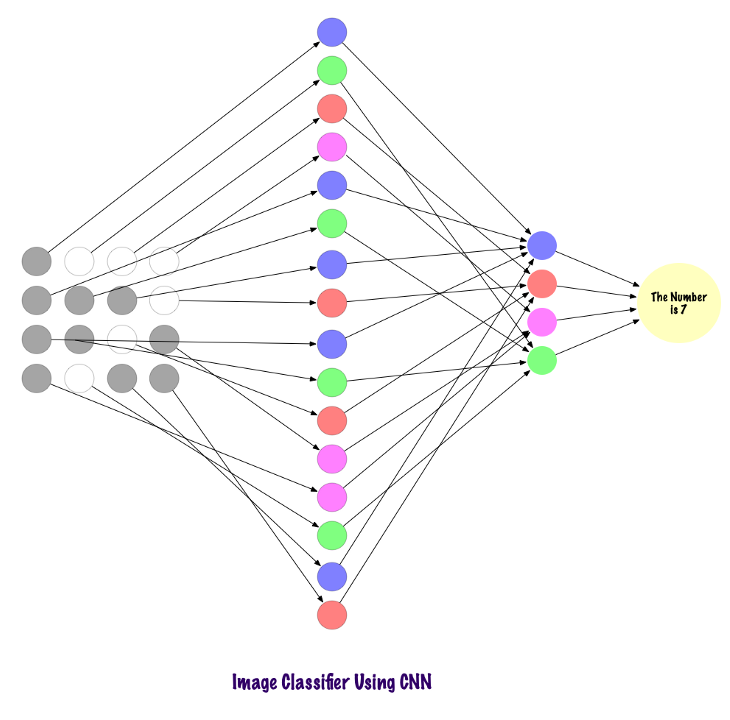
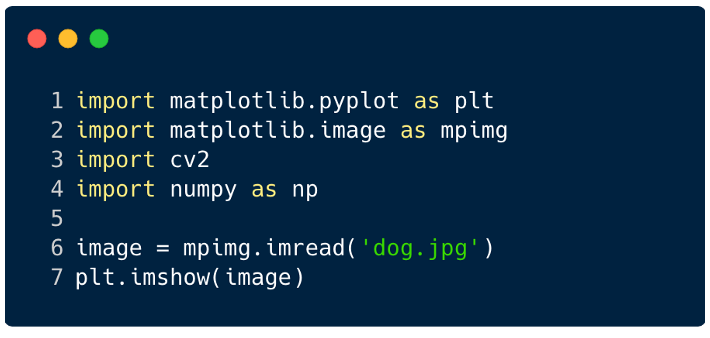
在我们了解CNN如何在图片中找到信息之前,我们需要了解如何提取特征。卷积神经网络使用不同的图层,每一层将保存图像中的特征。例如,考虑一张狗的照片。每当网络需要对狗进行分类时,它都应该识别所有特征-眼睛,耳朵,舌头,腿等。使用过滤器和核,这些特征被分解并在网络的局部层中识别出来。
计算机如何看图像?
与人类通过用眼睛了解图像的计算机不同,计算机使用一组介于0到255之间的像素值来了解图片。计算机查看这些像素值并理解它们。乍一看,它不知道物体或颜色,只识别像素值,这就是图像用于计算机的全部。
在分析像素值之后,计算机会慢慢开始了解图像是灰度还是彩色。它知道差异,因为灰度图像只有一个通道,因为每个像素代表一种颜色的强度。零表示黑色,255表示白色,黑色和白色的其他变化形式,即介于两者之间的灰色。另一方面,彩色图像具有三个通道-红色,绿色和蓝色。它们代表三种颜色(3D矩阵)的强度,并且当值同时变化时,它会产生大量的颜色!确定颜色属性后,计算机会识别图像中对象的曲线和轮廓。
可以使用PyTorch在卷积神经网络中探索此过程,以加载数据集并将滤波器应用于图像。下面是代码片段。(在GitHub上可找到此代码)
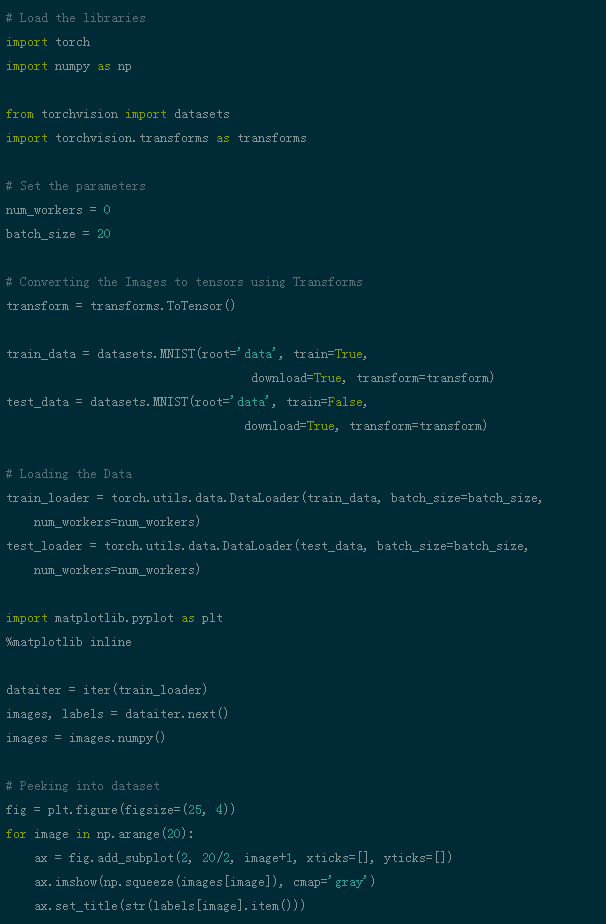

现在,让我们看看如何将单个图像输入神经网络。
(在GitHub上可找到此代码)
img = np.squeeze(images[7])fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111)ax.imshow(img, cmap='gray')width, height = img.shapethresh = img.max()/2.5for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]
这就是将数字“ 3”分解为像素的方式。从一组手写数字中,随机选择“ 3”,其中显示像素值。在这里,ToTensor()归一化实际像素值(0–255)并将其限制为0到1。为什么?因为,这使得以后的部分中的计算更加容易,无论是在解释图像还是找到图像中存在的通用模式。
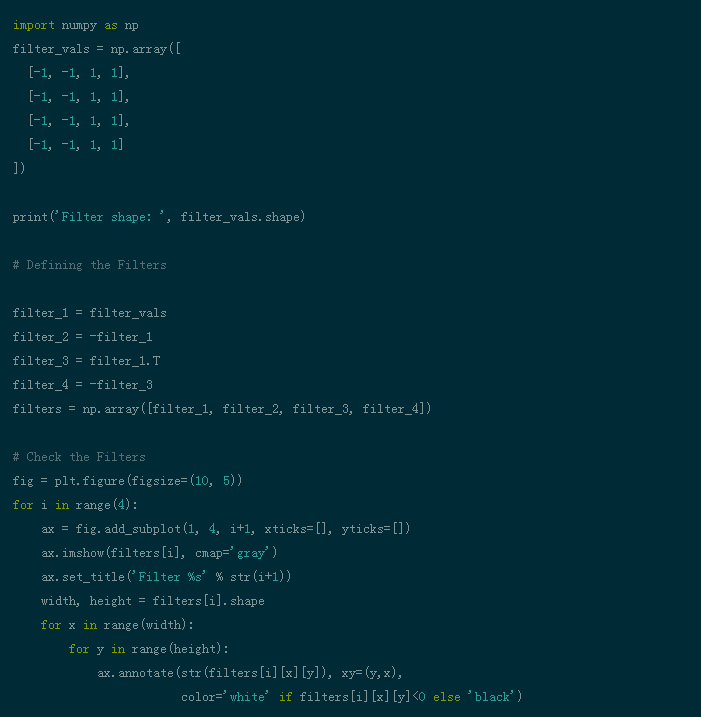
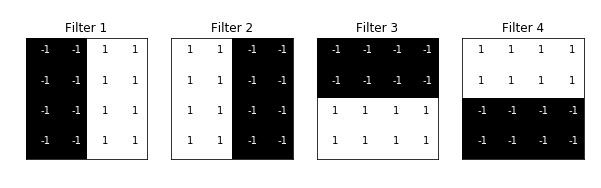
建立自己的滤波器 在卷积神经网络中,图像中的像素信息被过滤。为什么我们完全需要滤波器?就像孩子一样,计算机需要经历了解图像的学习过程。值得庆幸的是,这不需要几年的时间!计算机通过从头开始学习,然后逐步进行到整体来完成此任务。因此,网络必须首先知道图像中的所有原始部分,例如边缘,轮廓和其他低层特征。一旦检测到这些,计算机便可以处理更复杂的功能。简而言之,必须先提取低级功能,然后再提取中级功能,然后再提取高级功能。滤波器提供了一种提取信息的方法。 可以使用特定的滤波器提取低级特征,该滤波器也是类似于图像的一组像素值。可以理解为连接CNN中各层的权重。将这些权重或滤波器与输入相乘,得出中间图像,中间图像表示计算机对图像的部分理解。然后,这些副产品再与更多的滤波器相乘以扩展视图。该过程以及对功能的检测一直持续到计算机了解其外观为止。 您可以根据自己的需要使用很多滤波器。您可能需要模糊,锐化,加深,进行边缘检测等-都是滤波器。 让我们看一些代码片段,以了解滤波器的功能。
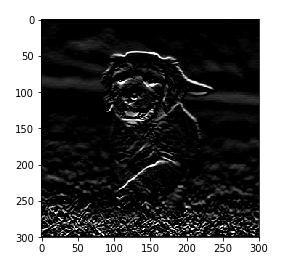
这是应用滤波器后图像的外观。在这种情况下,我们使用了Sobel 滤波器 。
完整的卷积神经网络(CNNS)
我们已经知道滤波器是如何从图像中提出特征了,但是为了完成整个卷积神经网络我们需要理解用来设计CNN的各层。
卷积神经网络中的各层分别叫做:
卷积层
池化层
全连接层
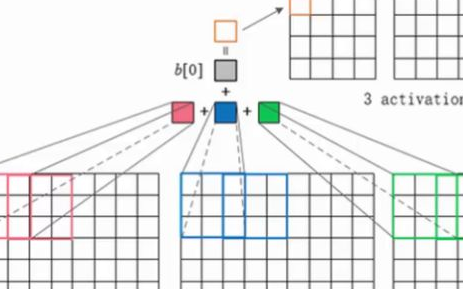
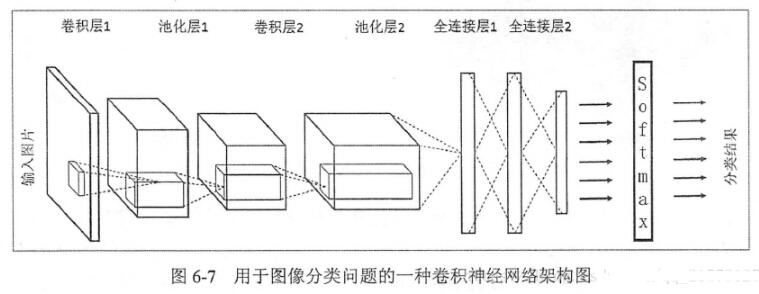
使用这3层,可以构造类似这样的图像分类器:
CNN各层的作用
现在让我们一起来看看各层是用来干什么的
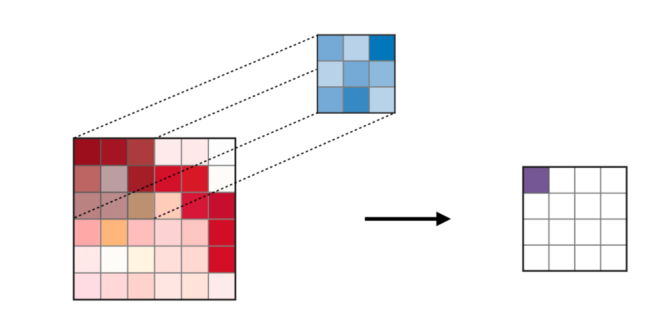
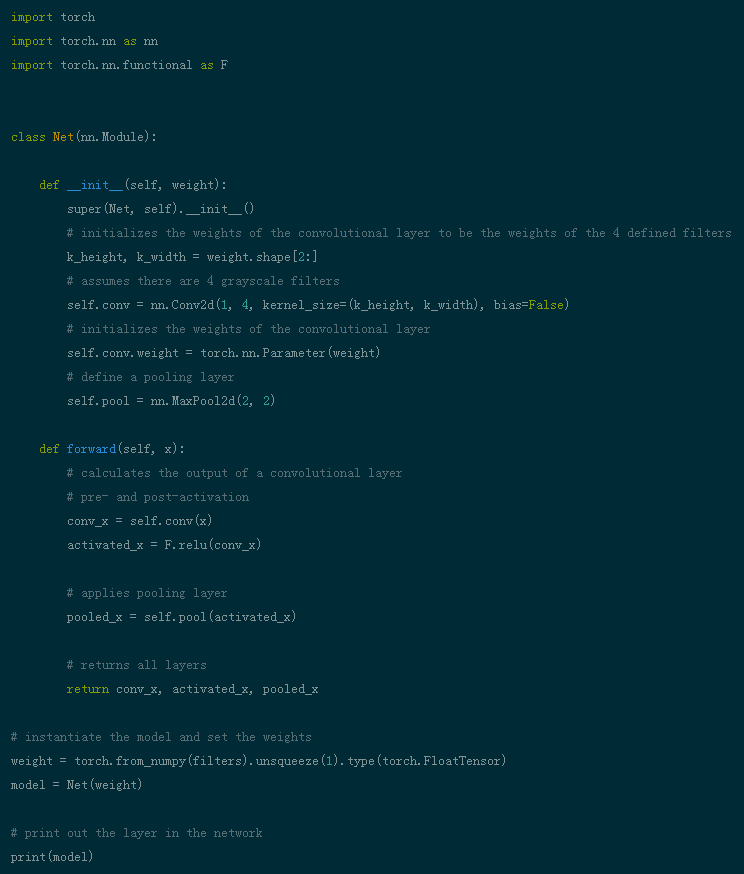
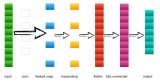
卷积层——卷积层(CONV)使用过滤器执行卷积操作,同时扫描输入图像的尺寸。它的超参数包括滤波器尺寸,通常设置为2x2,3x3,4x4,5x5(但并不仅限于这些尺寸),步长(S)。输出结果(O)被称为特征图或激活图,包含了输入层和滤波器计算出的所有特性。下图描述了应用卷积时产生的特征图:
卷积操作
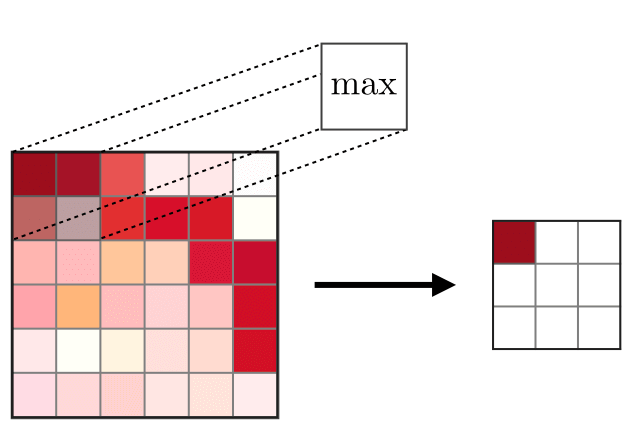
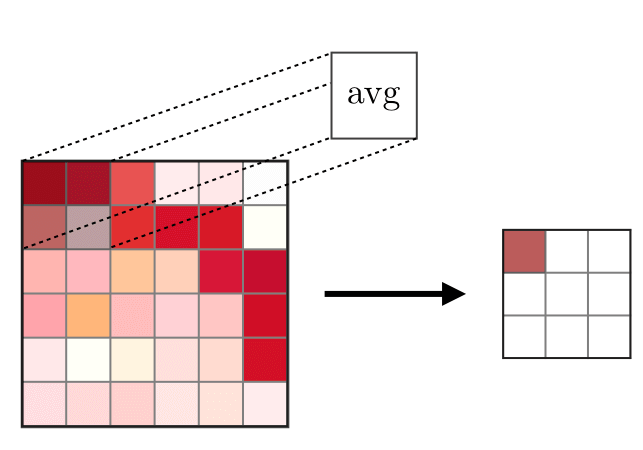
池化层——池化层(POOL)用于特征的降采样,通常在卷积层之后应用 。常见的两种池化操作为最大池化和平均池化,分别求取特征的最大值和平均值。下图描述了池化的基本原理:
最大池化
平均池化
全连接层——全连接层(FC)作用于一个扁平的输入,其中每个输入都连接到所有的神经元 。全连接层通常用于网络的末端,将隐藏层连接到输出层,这有助于优化类分数。
全连接层
在Pytorch可视化CNN
我们对CNN的函数有了更好的了解,现在让我们使用Facebook的PyTorch框架来实现它。
步骤1:加载输入图像。我们将使用Numpy和OpenCV。(在GitHub上可找到代码)
步骤2:可视化滤波器,以更好地了解我们将使用的滤波器。(在GitHub上可找到代码)
步骤3:定义卷积神经网络。该CNN具有卷积层和最大池化层,并且权重使用上述滤波器进行初始化:(在GitHub上可找到代码)
步骤4:可视化滤波器。快速浏览一下正在使用的滤波器。(在GitHub上可找到代码)
def viz_layer(layer, n_filters= 4): fig = plt.figure(figsize=(20, 20)) for i in range(n_filters): ax = fig.add_subplot(1, n_filters, i+1) ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray') ax.set_title('Output %s' % str(i+1))fig = plt.figure(figsize=(12, 6))fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05)for i in range(4): ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[]) ax.imshow(filters[i], cmap='gray') ax.set_title('Filter %s' % str(i+1)) gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)滤波器:
步骤5:跨层滤波器输出。 在CONV和POOL层中输出的图像如下所示。
viz_layer(activated_layer)viz_layer(pooled_layer)卷积层池化层
参考:CS230 CNNs(https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks).
可以在这里查看代码:https://github.com/vihar/visualising-cnns



















 工商网监
工商网监
评论