 电子发烧友App
电子发烧友App


摘 要: 针对铝型材表面缺陷快速准确检测的需求,提出一种基于 YOLO 深度学习模型的铝型材表面缺陷识别方法。对铝型材数据集进行图像增广,解决原始数据集中图像数量少且缺陷数据不均衡问题。建立基于 YOLO 的铝型材表面缺陷识别模型,通过增加模型预测尺度,提高对微小缺陷的识别能力。对铝型材缺陷数据集的目标框重新进行聚类分析,改进 YOLO 算法的模型参数。通过多尺度训练方法,增强模型对不同尺度缺陷的适应性和识别精度。实验结果表明,本文方法识别效果较改进前有较明显提升,准确率均值 MAP 从 95.66% 提升至 97. 46% ,单幅图像平均识别时间约 45 ms,可有效实现铝型材表面缺陷的快速与准确识别。
铝型材作为建筑和机械工业领域中重要的应用材料,其全行业的产量和消费量在世界范围内逐年递增。铝型材在生产过程中,由于材料特性和加工工艺,不可避免存在表面缺陷,严重影响铝型材的可靠性、安全性和可加工性。在实际生产中,对铝型材表面缺陷进行准确快速识别,对保证铝型材的质量至关重要。传统的铝型材表面缺陷识别方法包括涡流检测法、超声导波检测及红外检测法等识别成本高、设备复杂,且不易实现缺陷识别过程的可视化。机器视觉检测作为一种非接触式在线自动检测技术,具有非接触、安全性高、识别效率高和工作时间长的特点,是实现表面缺陷准确与快速识别的有效手段。例如,胡继文等针对带有纹理的铝型材图像,提出基于 Gabor 滤波的纹理分析方法,实现铝型材喷涂表面图像快速分类,但该方法极易受到喷涂表面粗糙度的影响。刘泽等针对钢轨表面典型的缺陷图像设计动态阈值分割算法和缺陷区域提取算法,优先实现钢轨缺陷的检测。孙雪晨等设计了一种基于机器视觉的凸轮轴表面缺陷识别系统,能够有效识别与定位 1 mm 以上的缺陷。
以上识别方法多采用传统机器视觉算法,通过图像形态学处理与特征提取进行缺陷识别,往往需要根据不同形态的缺陷特征,设计不同的特征提取与识别算法。铝型材表面缺陷形态不规则、位置随机且大小不一,采用传统机器视觉缺陷识别方法进行铝型材缺陷识别,难以同时满足检测精度与效率的要求。
近些年,随着人工智能技术的发展,基于深度学习的目标识别方法在工业零件的缺陷识别中得到应用,并取得较好的效果。YOLO( You Only Look Once) 识别算法是目前深度学习领域执行速度较优算法,其将目标识别问题转化为回
归问题可以同时预测多个识别框的位置和类别,具备较高准确率和执行速度。在 YOLO 的基础上,又出现 YOLOv2、YOLOv3改进算法,在识别速度和准确率上有所提高。其中,YOLOv3 对不同大小的多尺度目标识别效果较好,在齿轮、玻璃外观等表面缺陷识别领域得到应用。深度学习的识别方法用于工业产品的缺陷识别,具有较好的泛化性和鲁棒性。目前,铝型材表面缺陷的识别方法多采用传统的缺陷识别技术,将 YOLO 深度学习模型用于铝型材识别,将有助于改善铝型材表面缺陷识别的准确率与速度,提高铝型材的产品质量与生产效率。针对铝型材表面缺陷快速准确识别的需求,本文提出一种基于 YOLO 深度学习模型的铝型材表面缺陷识别方法。首先,采用图像增广对原始图像进行扩充,解决原始数据集中图像数量少且缺陷数据不均衡问题,并构建 3 个不同分辨率的数据集,提高训练过程中对不同尺度图像的鲁棒性。然后,建立铝型材表面缺陷的 YOLO 识别模型,通过增加模型预测尺度,提高对微小缺陷的识别能力。最后,对铝型材缺陷数据集的目标框重新进行聚类分析,并利用多尺度训练的方法,在低分辨率数据集上进行预训练,再利用中高分辨率数据集微调识别模型,以增强模型的适应性和准确率。
1 数据集构建
如图 1 所示,铝型材常见的缺陷有 4 种,分别是擦花、漏底、碰凹、凸粉。本文的铝型材图像数据集来源于江苏省某铝材公司。原始的铝型材图像数据集一共包括 342 张铝型材缺陷图像,缺陷图像样本较少,且部分缺陷占整个数据集比例过小、缺陷数据不均衡。深度学习在进行训练时,如果数据集较少会导致模型出现过拟合的问题。为解决上述问题,本文对有缺陷的铝型材图像,采用图像增广来进行数据集扩充。图像增广技术是对原图像数据进行一系列随机对比度调整、旋转等处理,产生相似但不同的训练数据,以扩大训练图像集的规模,同时降低模型对某些特征的依赖,提高模型的泛化能力。

▲图 1 常见的 4 种铝型材缺陷
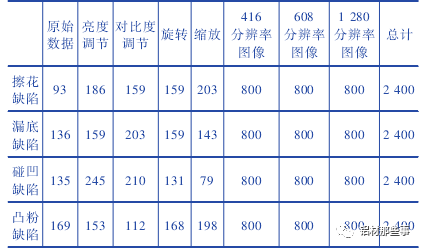
本文采用的图像增广方法包括调整对比度、亮度、旋转和缩放,每张增广后的图片为原图经过多种随机组合变换得到。图像增广后每种缺陷类别的图像的数量为 2 400 张,各缺陷比例为 1∶ 1∶ 1∶ 1。训练集的图像被转换为 PASCAL-VOC格式,其长度分别调整为 416、608、1 280,并调整宽度以保持原始纵横比。整个铝型材图像数据集的图片为 9 600 张,如表 1 所示。与一般的图像分类数据集不同,铝型材数据集在进行深度学习训练时,需提供图片缺陷区域的坐标位置。本文中通过 labellmg 软件来进行缺陷位置的标注。铝型材数据集中擦花、漏底、碰凹、凸粉四种缺陷分别标注,并保存其路径、标签和缺陷坐标信息。
表 1 铝型材缺陷数据集组成
2 识别方法
2. 1 铝型材表面缺陷的 YOLO 识别模型
YOLOv3 作为一种基于回归的目标识别算法,能够实现多目标的快速、准确识别。YOLOv3 对输入图像的全局区域进行训练,可加快训练速度且能更好地区分目标和背景。先利用 Darknet-53主干网络完成铝型材表面缺陷特征提取,再采用目标框直接预测目标类别和位置。铝型材表面缺陷形态不规则、位置随机且大小不一,直接应用 YOLOv3 模型进行识别难以保证微小缺陷的精密识别。本文在深入分析 YOLOv3 模型特性的基础上对其进行改进。将原有 3 尺度识别结构扩展为 4 尺度,提高对微小缺陷的识别能力; 通过重新聚类分析构建适合铝型材表面缺陷的初始目标框,改进 YOLO 算法的模型参数; 采用多尺度训练方式对训练流程进行优化,以增强模型对不同尺度缺陷的适应性和识别精度,解决铝型材表面缺陷识别困难、精度低等问题。
基于 YOLO 的铝型材多尺度识别模型架构如图 2 所示。在数据集构建后,以 Darknet-53 为主干网络进行特征提取,并融合多尺度识别,实现铝型材表面缺陷的有效识别。该网络从训练集和验证集中快速提取铝型材表面缺陷相应特征,并融合多尺度特征信息,同时得到缺陷预测框和类别,从而快速精确地识别出缺陷种类和位置。其中,训练集用于拟合识别网络,验证集用于调整识别网络的超参数以及对网络性能进行评估。
铝型材表面缺陷识别模型的工作流程如下: 首先,构建铝型材表面缺陷图像数据集,将缺陷图像输入识别模型进行训练; 再根据预测边界框及所属类别的概率对缺陷进行多尺度预测; 最后通过损失函数不断调整训练参数,以得到改进
后识别模型的参数。
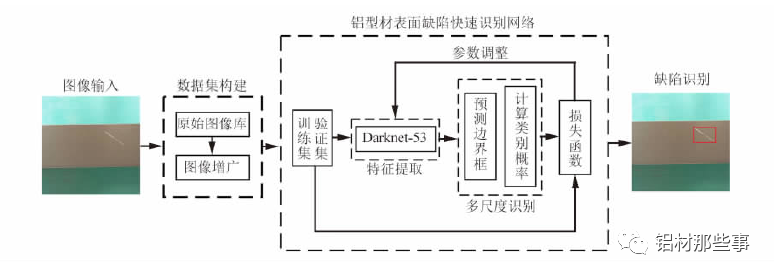
▲图 2 铝型材多尺度识别模型架构
2. 2 特征提取网络
采用 Darknet-53 网络作为图像特征提取的主干网络,其网络结构如图 3( a) 所示。整个网络采用完整的卷积层,没有池化层和固定输出的连接层。Darknet-53 网络结构借鉴残差神经网络 Res Net( ResidualNetwork),在其网络中加入 5 个残差块( residual) 。每个残差块中包含不同数量的残差单元,残差单元由特征提取层与两个 DBL( Darknetconv2d BN Leaky) 单元经过两层卷积所构成,如图 3( b) 所示。其中,残差单元中的 DBL 单元也是YOLOv3 的基本构成单元,由卷积( Conv) 、批归一化( BN) 和激活函数 Leaky Relu 共同构成,如图 3( c) 所示。Darknet-53网络中加入残差单元,可以保证主网络结构在不断加深的情况下不会造成梯度消失或爆炸,以加强主网络对图像特征的提取效果,进而提高模型识别的准确率。
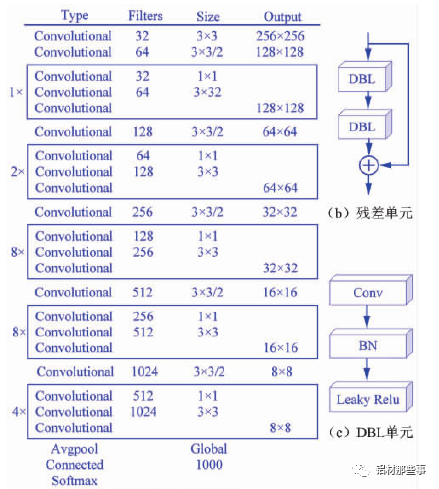
▲图 3 Darknet-53 网络结构
2. 3 多尺度识别的模型结构
对于大多数卷积神经网络,通过特征提取网络获取图像最终的特征图后,直接在该特征图上进行预测。这种方式仅能获取图像中单一尺度的语义信息,识别的尺度范围有限。在铝型材表面缺陷识别过程中,缺陷区域往往大小不一,且具有不同特征,因而需要利用不同尺度的识别网络来适应多尺度目标。YOLOv3 通过多尺度预测的方式对不同尺寸的目标来识别,其结构如图 4 所示。以本文的研究对象铝型材为例,输入的图像经过 Dark-net-53 主干网络时,共进行 5 次下采样。每进行一次下采样,铝型材的特征图就会变成原输入图像尺寸一半。经过 5 次即 32 倍下采样后,生成尺度 1 的铝型材特征图。该尺度特征图为 13 ×13 分辨率,通过卷积等操作后进行一次 2 倍上采样,生成 26 ×26 分辨率的特征图,将其与特征提取网络中16 倍下采样生成的 26 × 26 分辨率的特征图进行张量连接。通过张量连接融合两个图像的特征信息,生成一个双尺度融合的铝型材特征图( 尺度 2) 。以此类推,该尺度特征图再次通过 2 倍上采样,与 8 倍下采样生成的 52 × 52 分辨率的特征图进行张量连接,生成同为 52 × 52 分辨率且 3 尺度融合的铝型材特征图( 尺度 3) 。在铝型材缺陷识别中,存在微小的缺陷区域,使用原YOLOv3 中多尺度预测的方法难以满足微小缺陷精确识别的需求。针对该问题,本文对 YOLOv3 模型进行改进,将原有 3个尺度识别扩展为 4 个尺度,增加 104 × 104 分辨率的特征图,见图 4 新加结构。该尺度通过张量连接的方式,将 4 倍下采样生成的 104 ×104 分辨率的特征图与尺度 3 中 52 × 52分辨率的特征图融合。通过多尺度特征融合方式,将不同分辨率的特征图融合后单独输出且分别进行目标预测,以此提升小目标识别的精确度。融合后的尺度 4 包含之前各尺度信息的特征图,可改善铝型材表面微小缺陷的识别效果。

2. 4 目标框的聚类分析
目标框( anchor boxes) 是一组具有固定宽高比的数据集图像初始候选框,其设定对图像检测的精度和处理速度有着重要影响。YOLO 算法对目标框的宽高比维度进行 K-menas聚类分析,并对神经网络的训练过程进行优化,即事先确定一组宽高比维度固定的矩形框作为选取目标包围框时的参照物,通过预测目标框的偏移量取代直接预测坐标,以降低模型训练的复杂度。在 YOLOv3 原模型中,目标框通过 Pas-cal VOC、COCO 等图像标准数据集聚类得到,适用于自然场景中的目标。
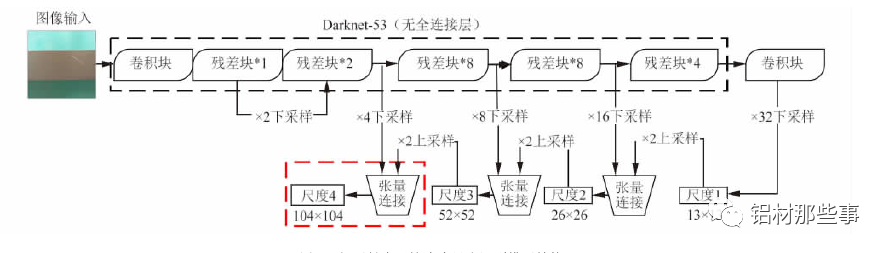
▲图 4 铝型材表面缺陷多尺度识别模型结构
本文要识别的目标为铝型材表面缺陷,这些缺陷的特征与上述数据集中的目标完全不同,因此直接使用原算法中聚类分析过的目标框并不合理。基于上述考虑,为得到精准的铝型材缺陷位置和类别信息,本文利用 K-menas 算法对数据集中目标框的宽高比维度重新进行聚类分析,得到适合铝型材数据集的目标框。通过聚类分析主要是获得更高的交并比 Io U( Averange intersection over union) 。Io U 代表预测的目标框与真实目标框的重叠率,其值越大表示聚类效果越好。因此,本文采用 Io U 取代 K-means 方法中的欧氏距离,用 Io U定义的距离 D 可表示为
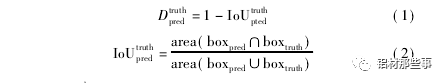
式中: Io Utruthpted为交并比,area( boxpred∩boxtruth表示预测目标框和真实目标框的交集部分面积,area( boxpred∪boxtruth表示预测目标框和真实目标框的并集部分面积。本文设定 K-means 聚类分析中簇的个数 K =1,2,…,20,聚类分析结果如图 5 所示。可以看出,随着 K 个数的增加,Io U 的数值不断增加,增长率不断减小。一般来说,最佳 K 值选取点为曲线斜率最大点之后的点。一方面,较少数量的 K值可以减少模型计算量,进一步加快损失函数的收敛。另一方面,也可以去除由较多目标框带来的识别误差。从图中可以看出,K =9 时为最优点,其对应的目标框分别为( 25,33) ,( 26,101) ,( 50,555) ,( 62,235) ,( 80,587) ,( 90,37) ,( 133,325) ,( 257,86) ,( 554,58) 。
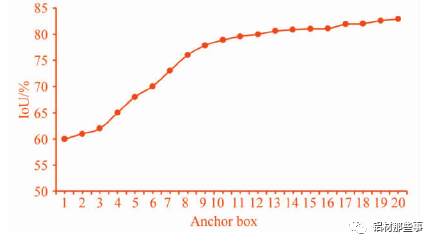
▲图 5 聚类分析曲线图
3 实验与分析
3. 1 模型训练
本文实验平台如表 2 所示。在模型训练前,基本参数设置如下: 动量( momentum) 设为 0. 9,衰减系数( decay) 设为0. 000 5,初始学习率( learning rate) 为 0. 000 1,学习率调整策略为 steps,最大迭代次数为 10 000 次。
表 2 实验平台

为提高铝型材缺陷识别的准确率,本文通过多尺度训练的方法,对其训练流程进行改进,使模型逐步适应不同分辨率的图像,以更好适应铝型材图像中不同尺度的缺陷特征。
具体流程如下:
1) 采用 312 × 312 分辨率的铝型材图像对模型进行预训练,获得初始的预训练权重;
2) 利用 416 × 416 分辨率的铝型 材图 像 对 模型 进 行 微调,使得模型能逐渐适应中等分辨率的缺陷特征;
3) 输入 608 × 608 分辨率的铝型材图像进行训练,自主调整每层权重来适应高分辨率图像输入,更好适应铝型材图像中不同尺度的缺陷特征,提高模型尺度不变性和鲁棒性。在训练过程中,损失函数 Loss 的定义为
Loss = lxyδ( x,y) + lwhδ( w,h) + lconfδ( conf) + lcδ( c) ( 3)
式中: δ( x,y) 为预测目标框中心坐标( x,y) 的误差函数,δ( w,h) 为预测目标框宽高比维度的误差函数。δ( conf) 为置信度 Confidence 的误差函数,δ( c) 为类别 c 的误差函数。lxy、lwh、lconf、lc分别为误差权重系数。
图 6 为本文模型在训练时的损失曲线图。本文模型随着迭代次数增加,误差损失经过震荡呈下降趋势,当训练迭代批次达 8 000 次后损失基本趋于平稳。
3. 2 缺陷识别效果
利用铝型材测试集图像对训练后的铝型材 YOLO 模型进行实验,以验证本文方法的有效性。评价模型有效性的相关指标包括平均准确率 AP、平均准确率均值 MAP和平均识别时间 t。AP 用于衡量模型在单个类别上的识别性能; MAP用于衡量模型在所有类别上的平均识别性能; 识别时间为模型平均处理每张图像所需时间,其单位为 ms。和 MAP用公式表示为
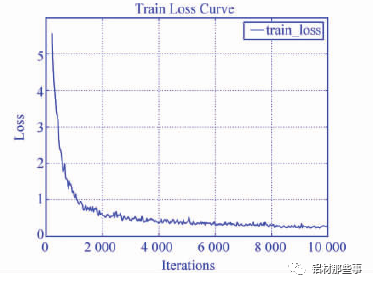
▲图 6 损失曲线图
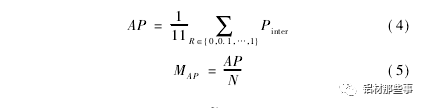
式中: PinterP( R) 为召回率满足 R~≥R 时的准确率的最大值,N为模型中待识别类别的个数。召回率表示正确识别的目标个数占总目标数百分比,准确率表示正确识别的目标个数占总识别目标个数百分比。召回率 R、准确率 P 和 PinterP( R) 可用公式表示为
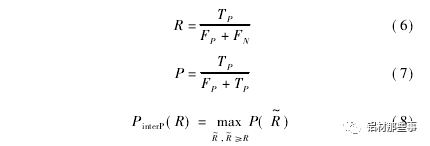
式中: TP为真正例,表示正样本被预测为正样本的数量; FP为假正例,表示负样本被预测为正样本的数量; FN为假负例,表示正样本被预测为负样本的数量; TN为真负例,表示负样本被预测为负样本的数量。为了定量分析本文方法实验效果,将本文方法与 YOLO、YOLOv2、YOLOv3、YOLOv3-tiny 及文献基于图像特征的传统机器视觉方法进行对比。表 3 所示为不同方法的实验结果。可以看出,采用 YOLO 系列原模型,对于擦花缺陷,仅YOLOv3 的 AP 值达 到 95. 25% ,其 他 方法的 AP 值 都 较 低,YOLO 的 AP 值则低于 70% 。在凸粉和漏底缺陷的测试结果中,本文方法的 AP 最高,分别达到 95. 75% 与 96. 86% 。碰凹缺陷因特征明显,其 AP 值在对比方法中都较高,尤其是本文方法 AP 达到 100% 。
表 3 不同方法性能对比
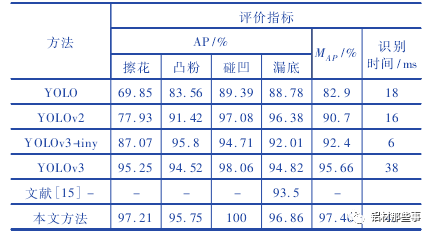
相较于 YOLOv3、YOLOv2,本文方法中的网络模型更复杂,使得平均识别时间分别增加 7 ms、29 ms,但 MAP值分别提升 1. 8% 、6. 76% 。YOLOv3-tiny 模型结构简单,检测速度虽较快,但检测精度明显降低,其 MAP比本文方法低 5. 06% 和 3. 24% 。本文方法的多项性能指标相较于改进前均有显著提升,尤其是 MAP达到 97. 46% 。与 YOLO 相比,本文方法 MAP提高14. 56% 。与文献基于图像特征处理的传统机器视觉方法相比,本文方法的 MAP提升 3. 96% 。图 7 所示为不同 YO-LO 系列方法及本文模型的缺陷识别效果图,图 7 ( a) - ( f)分别为原图、本文方法、YOLOv3、YOLOv3tiny、YOLOv2、YOLO的识别效果图。YOLOv3-tiny 模型结构较简单,对于漏底缺陷 AP 虽然较高,但仍存在漏检。YOLOv2 和 YOLO 在识别漏底和凸粉缺陷时也出现漏检情况,由于缺少多尺度检测结构,难以有效检测不明显的缺陷特征,从侧面验证了增加尺度预测结构对提高模型识别精度的重要性。相比之下,本文方法对测试图像中的 8 个擦花缺陷全部识别成功,优于其他方法的检测效果。在识别时间方面,本文方法相较于其他方法,单幅图片的识别时间略有增加,达到 45 ms,但仍能满足缺陷检测的实时性要求。可以看出,本文方法整体性能表现最佳,可以同时满足识别精度与速度的需求。

▲图 7 不同方法对 4 种缺陷的识别效果图
综上所述,本文方法通过增加模型识别尺度,可精确识别铝型材微小表面缺陷的类别和位置,提升识别精度和定位精度。通过聚类分析重新构建适合铝型材表面缺陷的初始目标框,利用多尺度训练优化模型参数,可更好适应铝型材图像中不同尺度的缺陷特征。本文方法对铝型材表面缺陷具有较好的识别效果,缺陷识别准确率达到 97. 46% ,平均耗时为 45 ms,可同时满足识别精度和速度要求。
4 结论
在铝型材缺陷识别中,缺陷形态特征的复杂多变会严重影响模型识别准确率和效果。针对铝型材缺陷快速准确识别问题,本文提出一种基于 YOLO 的铝型材表面缺陷识别方法。对铝型材数据集进行图像增广,解决原始数据集中图像数量少且缺陷特征不均衡问题。建立铝型材表面缺陷识别的 YOLO 模型,并通过增加模型预测尺度,提高对微小缺陷的识别能力。对铝型材数据集目标框重新进行聚类分析,并采用多尺度训练的方法,优化缺陷识别效果。本文方法的缺陷识别准确率达到 97. 46% ,优于其他 5 种对比算法。本文提出铝型材表面缺陷快速识别方法,缺陷识别准确率高、实时性好,可用于铝型材表面缺陷的快速准确识别,提高铝型材生产的自动化水平与检测效率。
编辑:黄飞

















 工商网监
工商网监
评论