 电子发烧友App
电子发烧友App


近年来,神经网络模型规模呈指数级增长,从2018年拥有超1亿参数的Bert到2020年拥有1750亿个参数GPT-3,短短两年模型的参数量增加了3个数量级,而且这种增长还看不到尽头。 人们刚刚开始发掘神经网络的应用潜力,但传统的训练和推理方式已然无法跟上神经网络规模的飞速增长速度,无法满足大规模机器学习所需的内存和算力需求。为此,国内外诸多创业公司寻求对软硬件等进行实质性的底层技术革新来解决这一挑战。 作为业内备受关注的AI加速器创业公司,成立于2016年的Cerebras希望通过构建全新AI加速器方案解决AI计算问题,以实现数量级计算性能:首先,需要改进计算核心架构,而不只是一味地提升每秒浮点运算次数;其次,需要以超越摩尔定律的速度提高芯片集成度;最后,还要简化集群连接,大幅度提升集群计算效率。 为了实现上述目标,Cerebras设计了一种新的计算核心架构。它让单台设备运行超大规模模型成为可能,此外,它开发出只需简单数据并行的横向扩展和本地非结构化稀疏加速技术,使大模型的应用门槛大幅降低。

图1:近年来各SOTA神经网络模型的内存与算力需求 2021年,Cerebras曾推出全球最大AI芯片Wafer Scale Engine 2(WSE-2),面积是46225平方毫米,采用7nm工艺,拥有2.6万亿个晶体管和85万个AI优化核,还推出了世界上第一个人类大脑规模的AI解决方案CS-2 AI计算机,可支持超过120万亿参数规模的训练。今年6月,它又在基于单个WSE-2芯片的CS-2系统上训练了世界上最大的拥有200亿参数的NLP模型,显著降低了原本需要数千个GPU训练的成本。 在近期举办的Hot Chips大会上,Cerebras联合创始人&首席硬件架构师Sean Lie深入介绍了Cerebras硬件,展示了他们在核心架构、纵向扩展和横向扩展方面的创新方法。以下是他的演讲内容,由OneFlow社区编译。
01 Cerebras计算核心架构
计算核心(compute core)是所有计算机架构的“心脏”,而Cerebras针对神经网络的细粒度动态稀疏性重新设计了计算核心。
图2:Cerebras计算核心 图2是一款小型核心,它只有38,000平方微米,其中一半的硅面积用于48 KB内存,另一半是含110,000个标准单元(cell)的计算逻辑。整个计算核心以1.1 GHz的时钟频率高效运行,而峰值功率只有30毫瓦。 先从内存说起。GPU等传统架构使用共享中央DRAM,但DRAM存取速度较慢,位置也较远。即便使用中介层(interposer)和HBM等尖端技术,其内存带宽也远低于核心数据通路带宽。例如,数据通路带宽通常是内存带宽的100倍。 这意味着每一个来自内存的操作数(operand)至少要在数据通路中被使用100次,才能实现高利用率。要做到这一点,传统的方法是通过本地缓存和本地寄存器实现数据复用。 然而,有一种方法可以让数据通路以极致性能利用内存带宽,就是将内存完全分布在要使用内存的单元旁边。这样一来,内存带宽就等于核心数据通路的操作数带宽。 这是一个简单的物理原理:将比特数据从本地内存移动到数据通路,中间只有几十微米的距离,相比将它通过数据包移动到外部设备要容易得多。
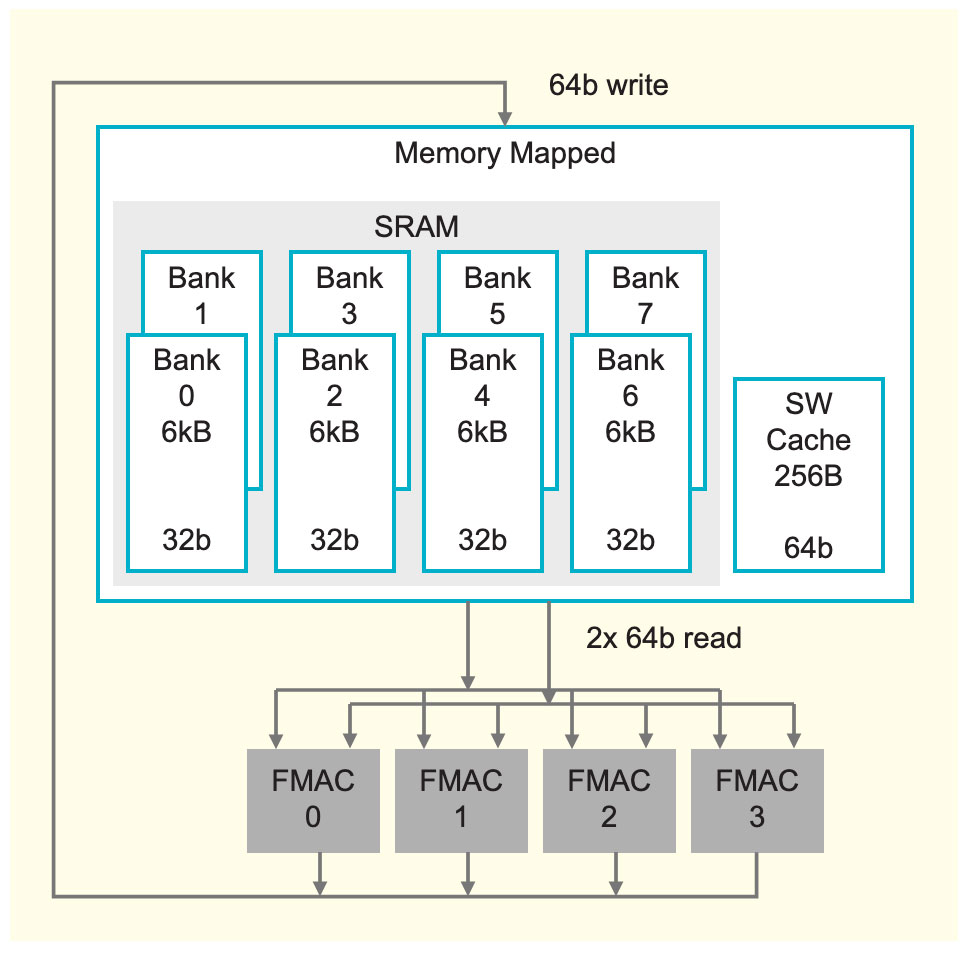
图3:Cerebras计算核心的内存设计:每个核心配有独立内存。 图3展示了Cerebras计算核心的内存设计,每个核心配有48 KB本地SRAM,8个32位宽的单端口bank使其具备高密度,同时可保证充分发挥极致性能,这种级别的bank可提供超出数据通路所需的内存带宽。 因此,我们可以从内存中提供极致数据通路性能,也就是每个循环只需2个64位读取,一个64位写入,因此它可以保证数据通路充分发挥性能。值得注意的是,每个核心的内存相互独立,没有传统意义上的共享内存。 除了高性能的SRAM以外,Cerebras计算核心还具备一个256字节的软件管理缓存,供频繁访问的数据结构使用,如累加器等。该缓存离数据通路非常紧凑,所以消耗的功率极低。上述分布式内存架构造就了惊人的内存带宽,相当于同等面积GPU内存带宽的200倍。
02 所有BLAS级别的极致性能
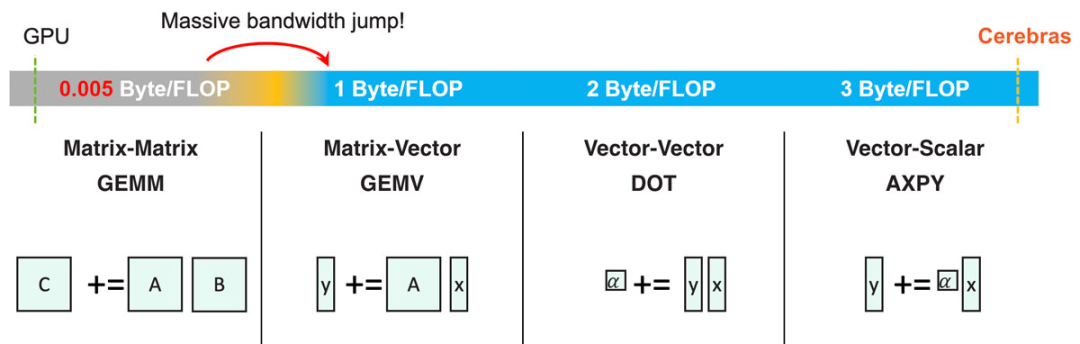
图4:稀疏GEMM即对每个非零权重执行一次AXPY操作。 有了极大的内存带宽,就可以实现许多卓越的功能。比如,可以充分发挥所有BLAS级别(基础线性代数程序集,BLAS levels)的极致性能。传统的CPU和GPU架构的片上内存带宽有限,因此只能实现GEMM(通用矩阵乘法)的极致性能,即矩阵-矩阵相乘。 从图4可见,在低于矩阵-矩阵相乘的任何BLAS级别都需要比内存带宽的大幅增加,这一点传统架构无法满足。 但有了足够的内存带宽后,就可以让GEMV(矩阵-向量相乘)、DOT(向量-向量相乘)和AXPY(向量-标量相乘)均实现极致性能。高内存带宽在神经网络计算中尤为重要,因为这可以实现非结构化稀疏的充分加速。一个稀疏GEMM操作可看作是多个AXPY操作的合集(对每个非零元素执行一次操作)。 Cerebras计算核心的基础是一个完全可编程的处理器,以适应不断变化的深度学习需求。与通用处理器一样,Cerebras核心处理器支持算术、逻辑、加载/储存、比较(compare)、分支等多种指令。这些指令和数据一样储存在每个核心的48 KB本地内存中,这意味着核心之间相互独立,也意味着整个芯片可以进行细粒度动态计算。通用指令在16个通用寄存器上运行,其运行在紧凑的6级流水线中。
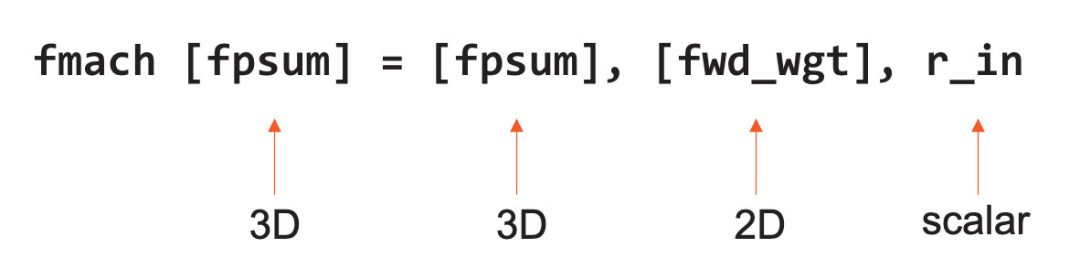
等式1,FMAC指令示例 除此之外,Cerebras核心还在硬件层面支持所有有关数据处理的张量指令。这些张量算子在64-位数据通路中执行,数据通路由4个FP16 FMAC(融合乘积累加运算)单元组成。 为了提升性能与灵活性,Cerebras的指令集架构(ISA)将张量视为与通用寄存器和内存一样的一等操作数(first-class operand)。上图等式1是一个FMAC指令的例子,它将3D和2D张量视为操作数直接运行。 之所以可以做到这一点,是因为Cerebras核心使用数据结构寄存器(DSR)作为指令的操作数。Cerebras核心有44个DSR,每个DSR包含一个描述符,里面有指针指向张量及其长度、形状、大小等信息。 有了DSR后,Cerebras核心的硬件架构更灵活,即可以在内存中支持内存中的4D张量,也可支持织构张量(fabric streaming tensors)、FIFO(先进先出算法)和环形缓冲器。此外,Cerebras核心还配有硬件状态机来管理整个张量在数据通路中的流动次序。
03 细粒度数据流调度
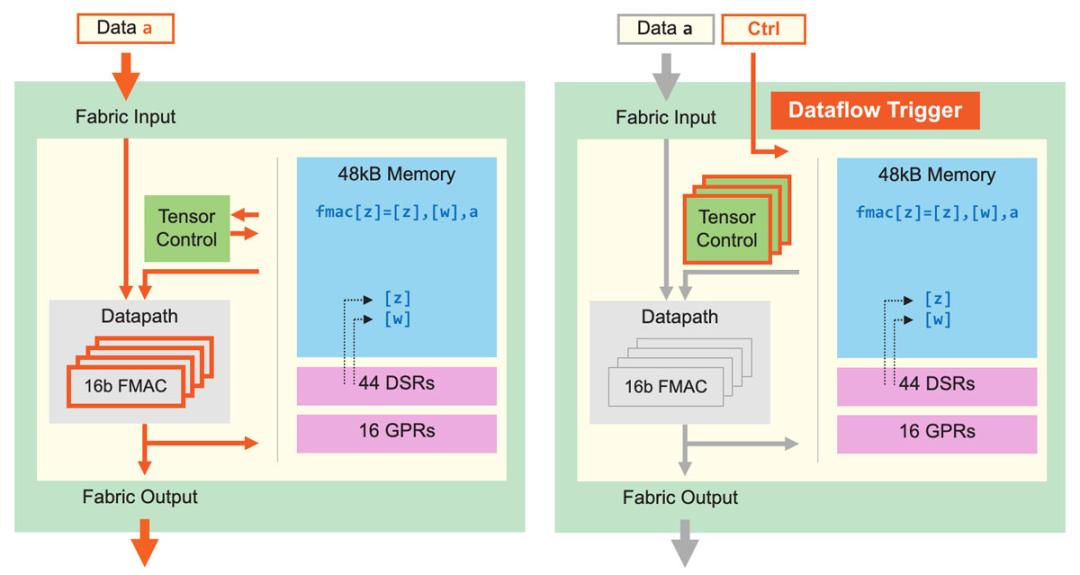
图5:核心数据通路及核心数据流调度。细粒度动态计算核心可提升计算性能,稀疏利用率为GPU的10倍。 除了改进张量应用,Cerebras核心还可执行细粒度数据流调度。如图5所示,所有计算都由数据触发。Fabric直接在硬件中传输数据和关联控件,一旦核心接收数据,就开始查找运行指令,查找工作完全基于接收到的数据。这一数据流机制使整个计算结构变成一个数据流引擎,可以支持稀疏加速——因为它只处理非零数据。发送器会过滤所有零值,因此接收器只会接收到非零值,而所有计算都由非零数据触发。 这样做不但可以节省功率,还可以省略不必要的计算,加快运算效率。操作由单个数据元素触发,使得Cerebras核心可以支持超细粒度、完全非结构化的稀疏性,同时不会造成性能损失。由于数据流具有动态性,所以Cerebras核心还支持8个张量操作同时运行,我们称之为“微线程(micro-threads)”。 微线程之间相互独立,每次循环时硬件可在其间切换。调度器持续为所有待处理张量监控输入和输出是否可用,还具有优先处理机制,保证关键任务得到优先处理。当不同任务间的切换产生大量动态行为时,微线程可以提升利用率,否则这些动态行为可能会导致流水线出现气泡。 上述细粒度、动态、小型核心架构等特点使我们的架构具备前所未有的高性能,其非结构化稀疏计算的利用率是GPU的至少10倍。可见,通过对计算核心架构的改进,Cerebras可将性能进行数量级提升。
04 纵向扩展:超越摩尔定律
要纵向扩展芯片,传统的方法都是从芯片制造方面入手,即提升芯片集成度。过去数十年,芯片行业的发展都符合摩尔定律,芯片集成度越来越高。如今,摩尔定律还在延续,但它的增量不够大,每一代制程只能将集成度提升约两倍,不足以满足神经网络的计算需求。所以,Cerebras希望可以超越摩尔定律,实现数量级的性能提升。 为此,我们尝试过传统的方法——扩大芯片面积,并在这方面做到了极致,成果就是WSE-2(Wafer-Scale Engine,晶圆级引擎)。如今,WSE-2的应用已非常广泛。它是全世界最大的芯片,尺寸超过46,000平方毫米,是目前最大的CPU的56倍。单块WSE-2有2.6万亿个晶体管,核心数达850,000个。庞大的芯片面积可以实现极大的片上内存和极高的性能。 为了让尺寸惊人的WSE-2也能在标准的数据中心环境中使用,我们还针对性地设计了Cerebras CS-2系统,做到了用单块芯片实现集群级计算。
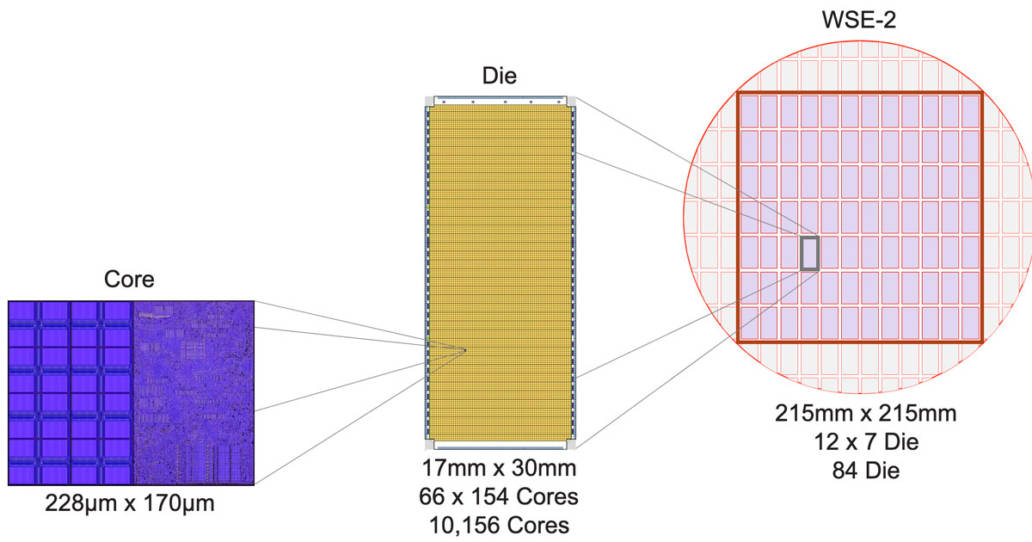
图6:从小型核心到大型晶圆级引擎 以下是我们从小型核心构建大型晶圆级引擎的过程:首先,我们在整片直径约300毫米的晶圆上做出一个个传统晶粒(Die),每个晶粒含有约10,000个核心;然后,不同于以往的是,我们不将单个晶粒切割出来做成传统芯片,而是在整片晶圆内切割出一个边长215毫米的方块,方块包含84个晶粒,共有850,000个计算核心(图6)。
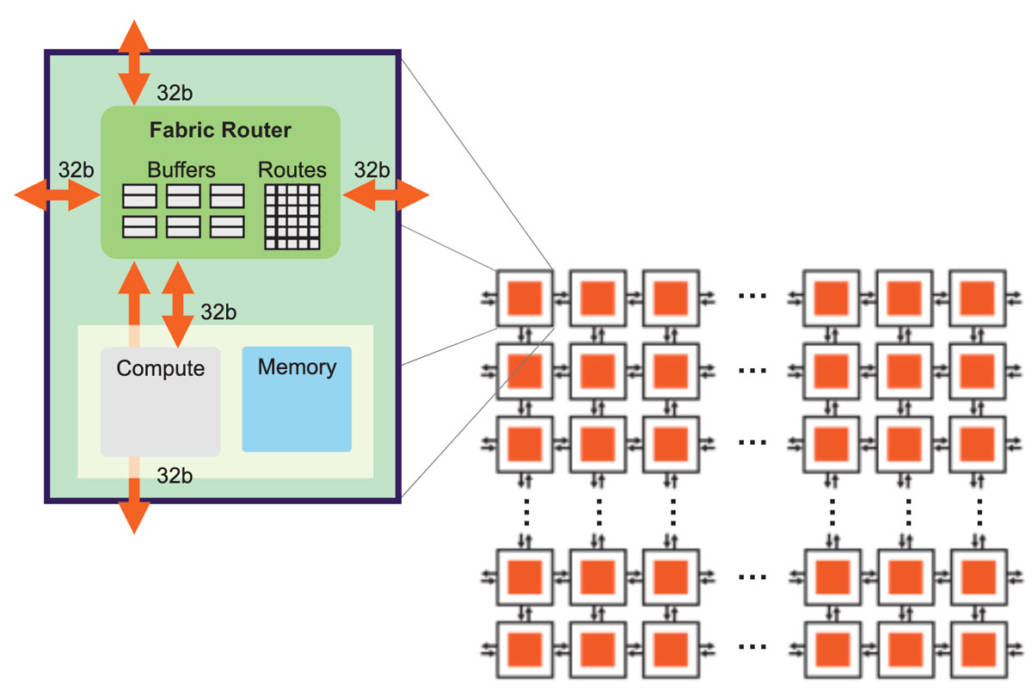
图7:高带宽、低延迟的芯片结构 实现这样的超大芯片尺寸,离不开底层架构的配合,底层架构必须能使数据在整片晶圆上高效、高性能地传输(图7)。Cerebras的芯片结构使用2D网格拓扑,这种结构非常适合扩展,而且只需消耗极低的开销。 网格拓扑将所有核心连接起来,每个核心在网状拓扑中有一个结构路由器(fabric router)。结构路由器有5个端口,4个方向各有1个,还有一个端口面向核心自身,各个端口都有32位的双向接口。端口数量较少的好处是可以将节点间延时保持在一个时钟周期以内,从而实现低成本、无损流控和非常低的缓冲。 芯片中的基本数据包是针对神经网络优化后的单个FP16数据元素,与之伴随的是16位的控制信息,它们共同组成32位的超细粒度数据包。 为了进一步优化芯片结构,我们使用了静态路由(static routing),效率高,开销低,而且可以充分利用神经网络的静态连接。为了让同一物理连接上可以有多条路由,我们提供24条相互独立的静态路由以供配置,路由之间无阻塞,且都可以通过时分复用(time-multiplexing)技术在同一物理连接上传输。 最后,由于神经网络传输需要高扇出(fan-out),因此Cerebras芯片的每个结构路由器都具有本地广播(native broadcast)和多播(multi-cast)能力。 有了上述基础后,我们就可以进行扩展。在单个晶粒内进行扩展比较简单,但现在需要将晶粒与晶粒连接起来。为了跨越晶粒间不到一毫米宽的划片槽(scribe line),我们使用了台积电工艺中的高级金属层。 我们将计算核心扩展为2D网格计算结构,然后又在整个晶圆上形成了完全同质的计算核心阵列。晶粒-晶粒接口是一种高效的源同步并行接口,但是,在如此大的晶圆规模上,总共有超过一百万条线路,所以我们的底层协议必须采用冗余度设计。我们通过训练和自动校正状态机来做到这一点。有了这些接口,即使在制造过程中存在瑕疵,整个晶圆的结构也能做到完全均质结构(uniform fabric)。
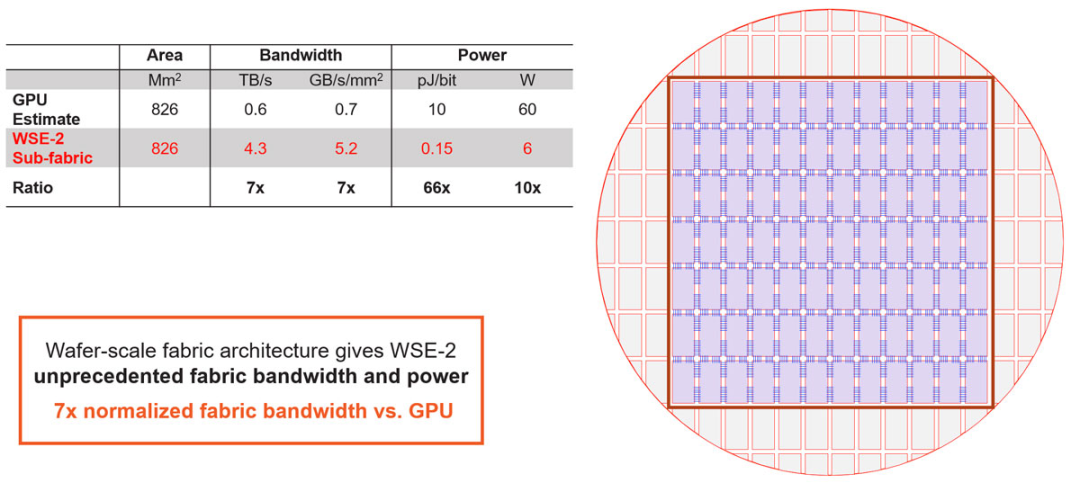
图8:整个晶圆上的均质结构(uniform fabric)。 芯片上看似简单的短线其实十分重要,它们在硅上的距离不到一毫米。这种线路设计与传统的SERDES方法很不一样。与前面提到的的内存设计相同,短线设计是出于简单的物理原理:在芯片上将比特数据传输不到1毫米的距离,比通过封装连接器、PCB或者线缆传输都更容易。 与传统IO相比,这种方法带来了数量级的改进。从图8数据可看出,WSE-2每单位面积的带宽比GPU多出约一个数量级,并且每比特的功率效率提高了近两个数量级。这些都表明整个晶圆结构具备了前所未有的高性能。 如果转化为同等的GPU面积,WSE-2的带宽是GPU的7倍,而功率仅约5瓦。正是这种级别的全局结构性能,使晶圆能够作为单个芯片运行。有了如此强大的单芯片,我们就可以解决一些极具挑战性的问题。
05 通过权重流式技术支持超大模型
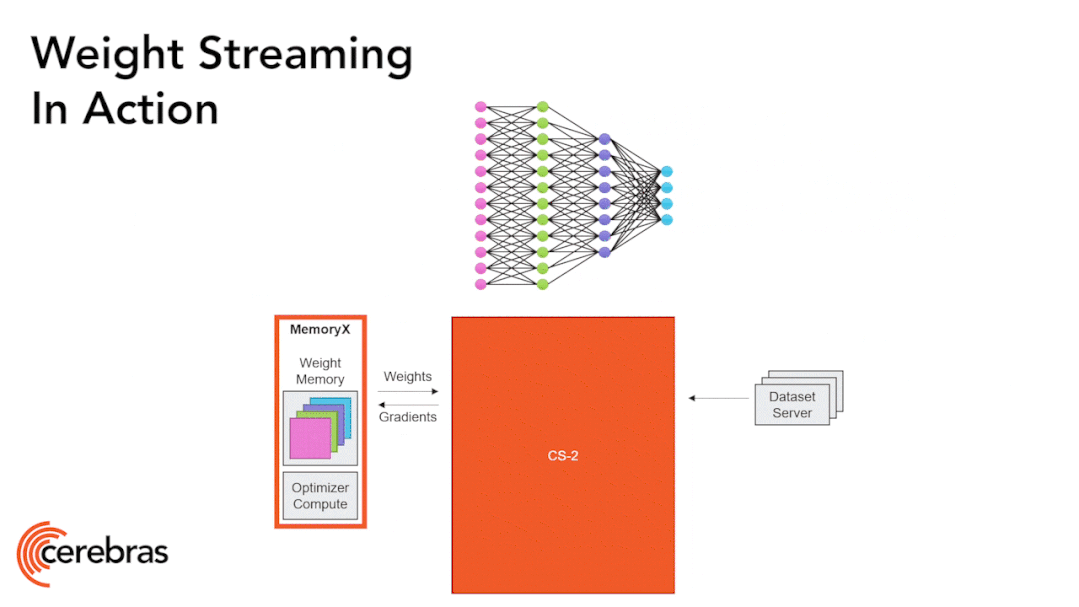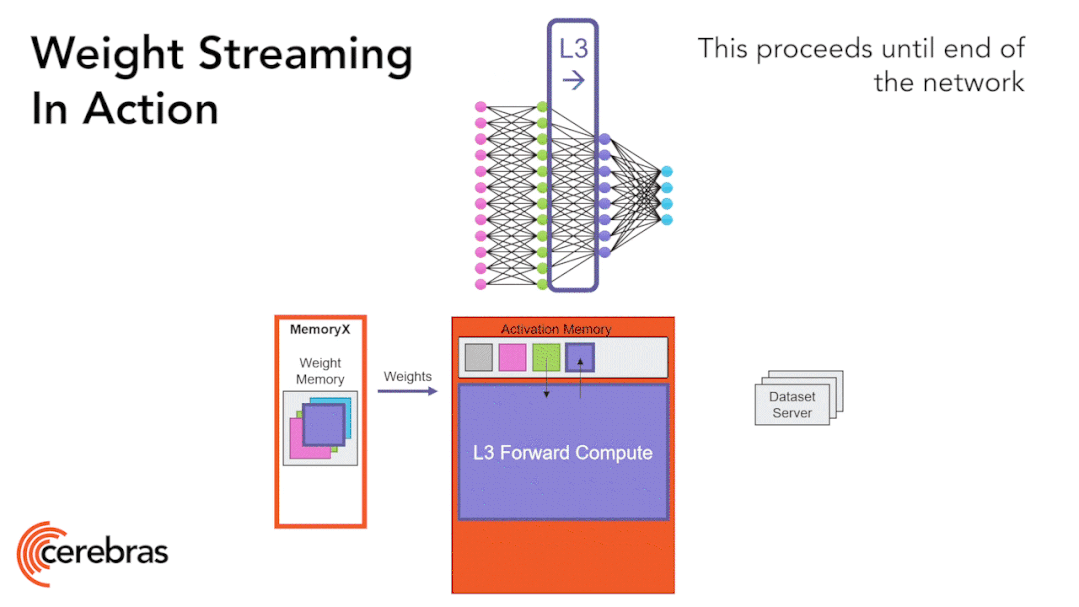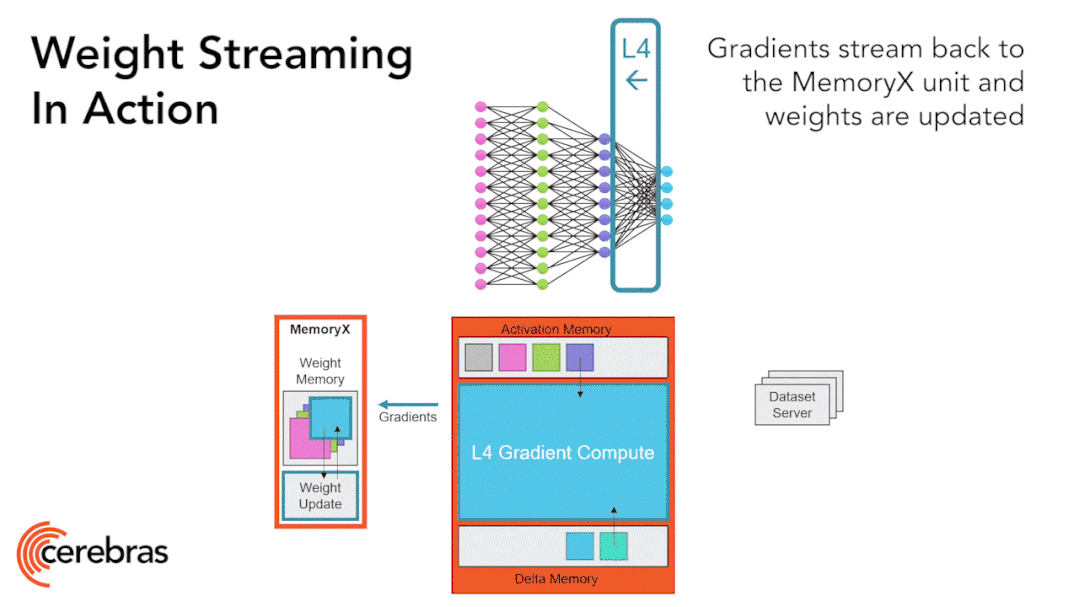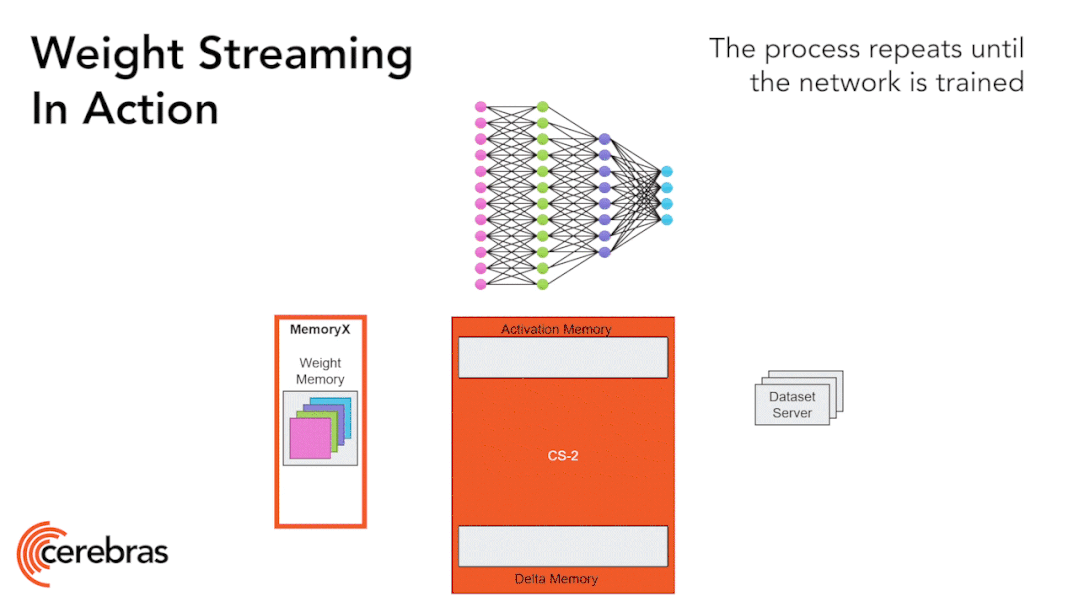
图9:通过权重流式(Weight Streaming)技术可在单个芯片上支持所有模型大小。 高性能的芯片结构可以让我们在单个芯片上运行大型神经网络。WSE-2具有足够高的性能和容量来运行如今最大的模型,且无需分区或复杂的分布式处理,这是通过分解神经网络模型、权重和计算来完成的。 我们将所有模型权重存储在名为MemoryX的外部设备中,并将这些权重流式传输到CS-2系统。权重会在神经网络各层的计算中用到,而且一次只计算一层。权重不会存储在CS-2系统上,哪怕是暂时储存。CS-2接收到权重后,使用核心中的底层数据流机制执行计算(图9)。 每个单独的权重都会作为单独的AXPY操作触发计算。完成计算后,该权重就会被丢弃,硬件将继续处理下一个元素。由于芯片不需要储存权重,所以芯片的内存容量不会影响芯片可处理的模型大小。在反向传播中,梯度以相反的方向流回到MemoryX单元,然后MemoryX单元进行权重更新。
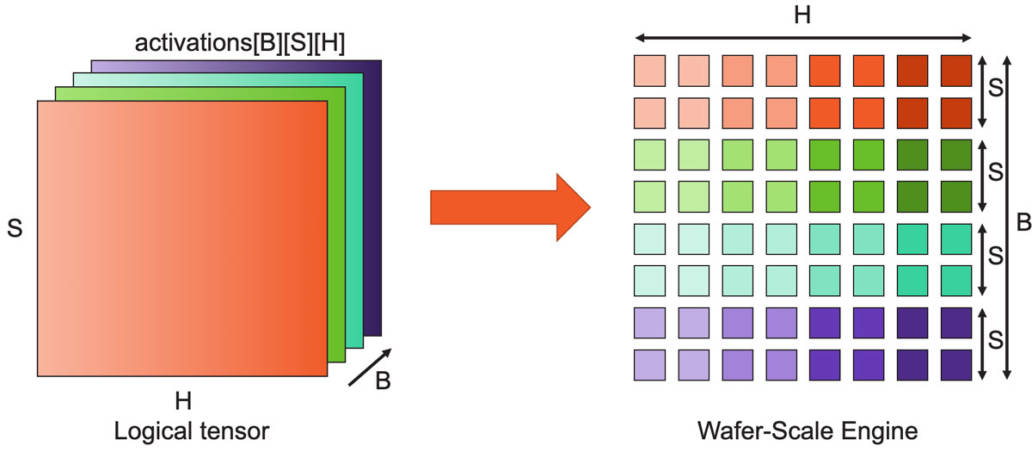
图10:完整的晶圆是MatMul阵列,可支持超大矩阵。 以下是芯片中执行计算的具体方法。神经网络各层的计算可归结为矩阵乘法,由于CS-2的规模较大,我们能够将晶圆的85万个核心用作单个巨型矩阵乘法器。 它是这样工作的:对于像GPT这样的Transformer模型,激活张量具有三个逻辑维度:批次(B)、序列(S)和隐藏(H)维度,我们将这些张量维度拆分到晶圆上的二维核心网格上。隐藏维度在芯片结构的x方向上划分(split),而批次和序列维度在y方向上划分。这样可以实现高效的权重广播以及序列和隐藏维度的高效归约。 激活函数存储在负责执行计算工作的核心上,下一步是触发这些激活函数的计算,这是通过使用片上广播结构来完成的。我们使用片上广播结构来向每一列发送权重、数据和命令的方法。 当然,在硬件数据流机制下,权重会直接触发FMAC操作。这些是AXPY操作。由于广播发生在列上,因此包含相同特征子集的所有核心接收相同的权重。此外,我们发送命令来触发其他计算,例如归约或非线性操作。
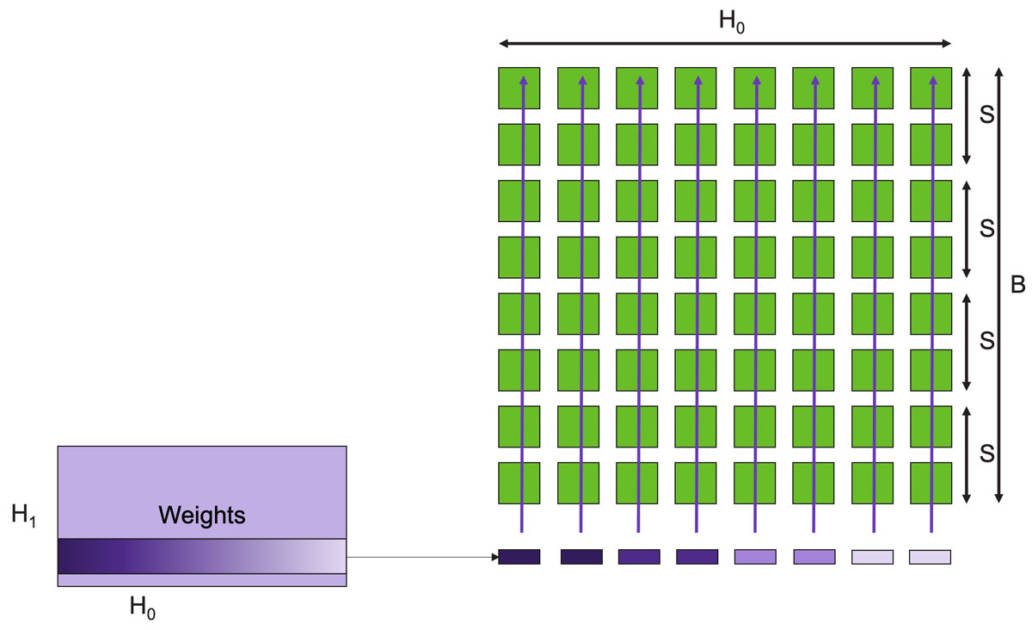
图11:数据流调度以低开销实现完全非结构化的稀疏MatMul运算。 举个例子,我们首先在整个晶圆上广播权重行(图11)。每行的每个元素都是标量,当然,在单行中,有多个权重映射到单个列上,当存在稀疏性时,只有非零权重才会被广播到列,触发FMAC计算。我们跳过所有的零权重,并输入下一个非零权重,这就是产生稀疏加速的原因。
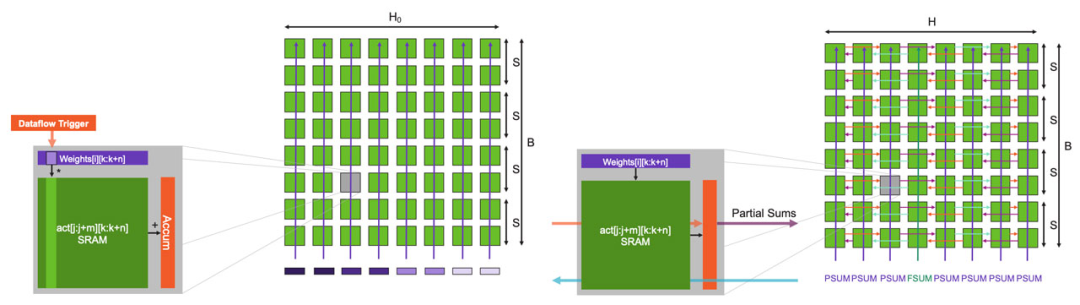
图12:稀疏输入的GEMM:乘法和partial sum归约。 如果我们现在放大一个核心,可以看到核心架构是如何进行此操作(图12)。在数据流机制下,权重抵达后,就会触发核心上的FMAC计算。权重值与每个激活函数输出相乘,然后累加到软件管理缓存中的本地累加器中。FMAC计算使用张量指令执行,将激活函数输出视为张量操作数。上述计算都不会对核心造成额外开销。 此外,权重也不会产生内存开销,因为一旦计算完成,核心就会转而计算下一个权重,不需要存储任何权重。若整行核心都接收到权重,每个核心就都会产生一个partial sum,然后该行核心的所有partial sum将进行归约。 归约计算由被广播到每列所有核心的命令包触发。同样,在数据流调度机制下,一旦核心接收到命令包,它就会触发partial sum归约计算。实际的归约计算本身是使用核心的张量指令完成,使用的是结构张量操作数。所有列都接收一个PSUM命令。但是其中一列会收到一个特殊的FSUM命令,它要求内核存储final sum。这样做是为了使用与输入特征相同的分布来存储输出特征,从而为下一层计算做好准备。 收到命令后,核心使用结构上的环形模式进行通信,该模式使用结构静态路由设置。使用微线程,所有归约都与下一个权重行的FMAC计算重叠,该种FMAC计算并行开始。当所有的权重行都处理完毕,完整的GEMM操作就完成了,同时所有的激活函数输出都已完备,可以进行下一层计算。 上述设计能让各种规模的神经网络都可以在单个芯片上高性能运行。独特的核心内存和芯片架构使芯片可以无需分块或分区即可支持超大矩阵,即使是具有多达100,000 x 100,000 MatMul层的超大模型也可以在不拆分矩阵的情况下运行。 若使用单个WSE-2芯片运行此模型,FP16稀疏性能可达75 PetaFLOPS(若稀疏性更高,性能还可更高),FP16密集性能可达7.5 PetaFLOPS。这就是我们应对机器学习硬件挑战的第二个方面,通过扩展进一步带来一个数量级的性能提升。
06 横向扩展:为什么这么难
最后一个方面:集群横向扩展。如今已经存在集群解决方案,但为什么横向扩展仍然如此困难?
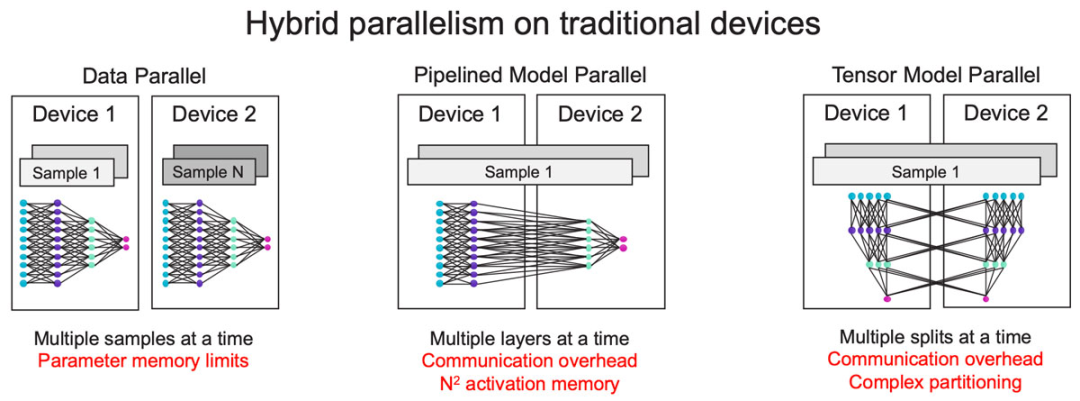
图13:分布复杂性随集群规模显著增加。 让我们看看现有的横向扩展技术(图13)。最常见的是数据并行,这也是最简单的方法,但它不适用于大型模型,因为它要求每个设备都有足够的容量容纳整个模型。 为了解决这个问题,常见的方法是采用模型并行,即划分模型,以流水线方式用不同的设备运行模型的不同层。但随着流水线变长,激活值内存(activation memory)以二次方的速度增长。 为了避免这种情况,另一种常见的模型并行方法是跨设备划分层,但这会造成很大的通信开销,而且划分单个层非常复杂。 由于上述种种限制,今天仍没有一种万能的方式来实现横向扩展。在大多数情况下,训练海量模型需要数据并行和模型并行混合的方法。现存的横向扩展解决方案仍有许多不足,根本原因很简单:在传统的横向扩展中,内存和计算是紧密联系的,如果在数千台设备上运行单个模型,扩展内存和计算就变成相互依赖的分布式约束问题。
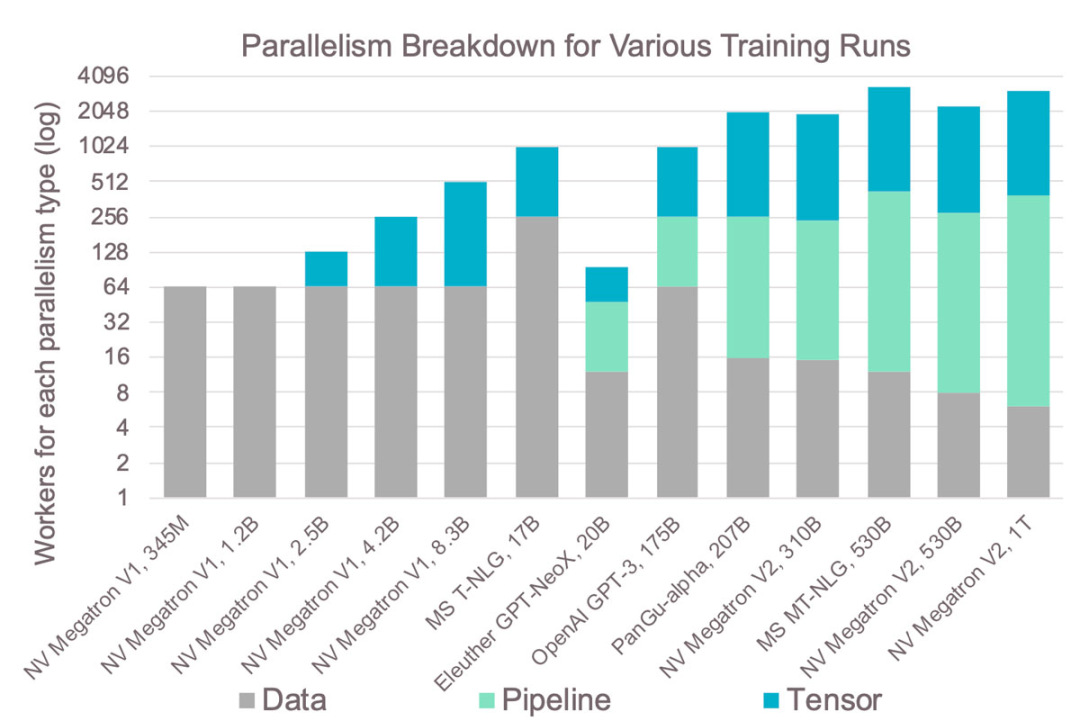
图14:GPU集群在实践中的复杂性。 这种复杂性导致的结果是:图14显示了过去几年在GPU上训练的最大模型及其使用的不同并行方法。从中可见,越大的模型需要的并行类型也越多,增加了复杂性。 例如,张量模型的并行级别始终限制为8,因为在单个服务器中通常只有8个GPU。因此,大型模型大多采用流水式模型并行,这是最复杂的方法,原因就是之前提到的内存问题。在GPU集群上训练模型需要解决这些分布式系统问题。这种复杂性导致需要更长的开发时间,并且往往无法实现最佳扩展。
07 Cerebras架构使扩展变得容易
Cerebras架构能够在单个芯片上运行所有模型,无需模型分割,因此扩展变得简单而自然,可以仅通过数据并行进行扩展,不需要任何复杂的模型并行分割。
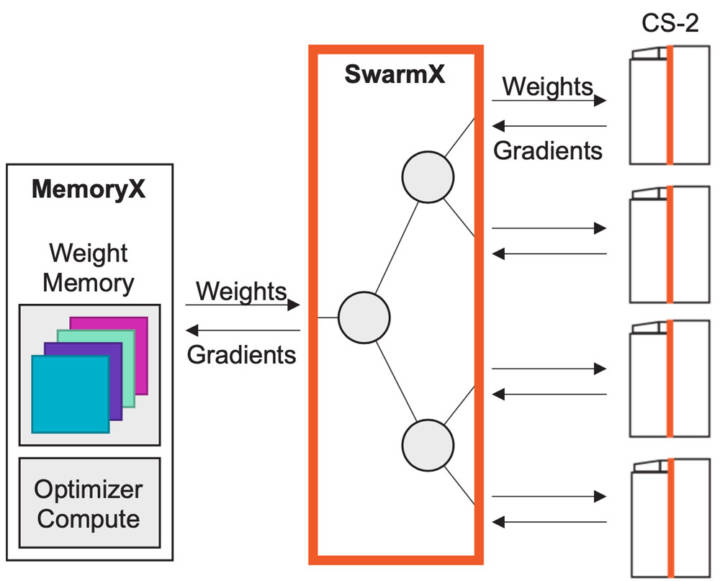
图15:使用MemoryX和SwarmX进行扩展,只需近线性的数据并行。 我们为数据并行专门设计了SwarmX(图15)互联技术。它位于储存权重的MemoryX单元和用于计算的CS-2系统之间,但又独立于两者。 SwarmX向所有CS-2系统广播权重,并减少所有CS-2的梯度,它不仅仅是一个互联,更是训练过程中的一个活跃组件,专为数据并行横向扩展而构建。 在内部,SwarmX使用树形拓扑来实现模块化和低开销扩展,因为它是模块化和可分解的,所以扩展到任意数量的具有与单个系统相同的执行模型的CS-2系统。要扩展到更多计算,只需在SwarmX拓扑中添加更多节点和更多CS-2系统。这就是我们应对机器学习硬件需求的最后一个方面:改进并大大简化横向扩展。
08 总结
在过去的几年里,机器学习工作负载的需求增加了三个数量级以上,而且没有放缓的迹象。预计几年后将增长到图16的箭头位置,我们问自己,可以满足这种需求吗?

图16:各种最先进的神经网络的内存和计算要求。横、纵坐标每一格代表一个数量级的提升。 Cerebras相信,我们可以,但不是通过传统技术做到这一点,而是通过非结构化稀疏加速、晶圆级芯片和集群横向扩展的结合将性能提升三个数量级。神经网络模型规模依然呈指数级增长,可以使用这些大模型的公司很少,而且未来只会更少。 然而,Cerebras架构支持用单个设备运行超大模型,同时支持只需数据并行的横向扩展,以及本地非结构化稀疏加速,将让更多人都能使用大模型。
编辑:黄飞









 工商网监
工商网监
评论