 电子发烧友App
电子发烧友App


Jetson Inference范例是NVIDIA 提供给Jetson系列的边缘装置进行视觉影像识别的范例,主要的特色在于这些范例都特别强调以NVIDIA Jetson系列边缘装置内的GPU进行运算,在实测上也的确发挥了很好的影像识别效果,尤其在对象侦测(Object Detection)所使用的Detectnet范例更有效率的辨识效能。
RealSense D435则是Intel推出的RealSense系列产品之一,这系列的产品主要是以输出影像深度信息(测距)的应用为主,RealSense D435透过光学测距的方式进行深度信息的探测,在应用上有着不错的探测效果。
影像对象侦测一直都是影像深度学习的重要应用之一,透过神经网络对于对象(Object)的种类进行辨识进而确认对象在影像中的直角坐标位置,在辨识上仅能确认对象的影像方位,这样的影像对象侦测由于缺少了对象与摄影机的相对距离,因此在更进一步的应用上便会受到一些局限,例如:透过影像信息控制机械手臂,自动夹取指定的物品、自驾车或无人飞行器精确的回避障碍物或跟踪控制。
因此本文将着重在对象与摄影机的相对距离应用在影像对象侦测的实作教学上,希望能够透过这样的实作教学让每个使用者可以进一步的针对影像对象侦测进行测量距离,这次采用的微电脑平台是NVIDIA Jetson Nano 4GB嵌入式系统,与Intel的影像深度摄影机Realsense D435两者进行整合,本文针对NVIDIA的GStreamer技术进行简介,主要是因为NVIDIA的Jetson Inference相关应用,都是透过GStreamer进行影像数据的交换传输,透过GStreamer可以有效提升图像处理的效能。
一、Jetson Inference应用程序操作环境的安装与设定
Jetson Inference程序操作环境的设定主要是会完成三个环境更新安装与设定,分别是:
1.Python程序的相依套件程序安装(如:Pytroch等)
2.Python程序的编译与路径参数设定
3.影像识别相关预训练神经模型的安装
/有关Jetson Inference程序的安装与设定,请参考之前的文章。--小编/
本文所采用的主要的是detectnet这个范例应用为主,因此若使用者对于安装空间有所斟酌的话,请优先完成这部分的安装,请注意,本文建议尽可能将detectnet所需要用到的预训练神经网络模型全部安装,这样可以避免未来在应用时产生补充安装模型的问题。此外这里的安装会需要从网络下载大量程序与档案,因此请务必确认网络传输环境在长时间运作下,能够正常传输。
Jetson Inference的范例程序运作,主要是透过CUDA连结GPU的方式进行Tensor-RT的运算,也由于是透过GPU进行运算,在操作影像识别的神经网络运算时有着较佳的运作效能。透过GStreamer进行影像串流的处理,可以有效提升影像传输的效能,在Jetson Inference的神经网络运算时,也都是以GStreamer的方式进行影像数据的传递。
透过上述这两方面的技术的整合,对于影像对象侦测是有非常重要的贡献,根据实测在进行detectnet程序运作的时候,整体约莫会有25FPS的操作效能,这归功于CUDA有效连结了GPU进行运算产生的效益。
二、intel Realsense D435深度影像应用程序操作环境的安装与设定
Realsense相关应用程序操作环境的安装与设定主要是针对以下三个事项进行设定,分别是:
1.Python相依套件的安装
2.Realsense应用程序的编译与路径设定
3.Realsense-viewer或Python程序的安装
/有关Realsense程序的安装与设定,请参考之前的文章进行安装即可。--小编/
Realsense的影像信息其格式必须经过numpy套件程序的转换处理才能呈现实时影像,这部分的介绍将会在后续的介绍当中,透过片段程序的进行重点说明,Realsense在运作的时候基本上会有两种不同内容的影像输出,一个是标准RGB的影像输出,另一个具有深度信息的影像输出,这两个影像在应用时必须要注意「影像信息对齐」,这主要的原因在于两种影像在撷取的时候可能会有两种不同的分辨率的设定。在实际的硬件规格当中亦可以看出这两种影像分辨率的极限的确有所不同。
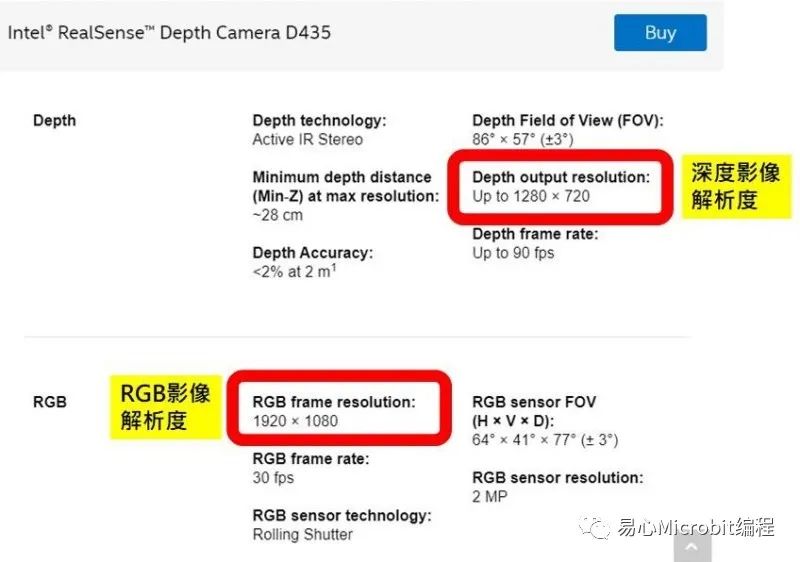
Intel Realsense D435原厂网站资料
https://www.intelrealsense.com/depth-camera-d435/
三、系统架构图
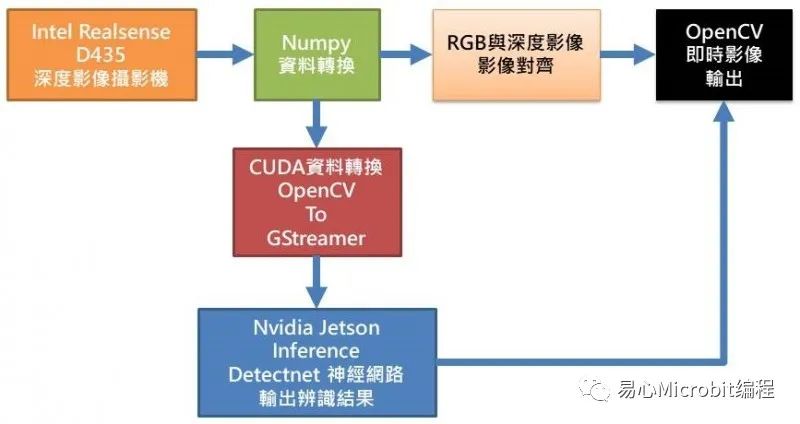
从上图可知,Realsense D435要透过Numpy套件程序才能将影像信息转换成OpenCV格式进行后续的图像处理,如:绘边界框、标注文字与实时影像显示等,而要进行Jetson Inference的detectnet运算之前,亦必须先透过CUDA转换数据将OpenCV格式转换成GStreamer格式才能进行detectnet神经网络运算,之后再将detectnet辨识后的结果,如:边界框位置信息、对象种类名称,加入至RGB影像讯息内容中,最后与深度影像信息进行对齐,如此便可以OpenCV进行整合后的影像呈现。
四、程序设计说明
<汇入相关套件>
1.JetsonInference 相关套件
主要有inference、jetson.utils
2.Realsense相关套件
主要是pyrealsense2
3.OpenCV相关套件
主要是cv2
4.Numpy数值运算相关套件
主要是numpy
#!/usr/bin/python3
#
#Copyright (c) 2021, Cavedu. All rights reserved.
#
importjetson.inference
importjetson.utils
importargparse
importsys
importos
importcv2
importre
importnumpy as np
importio
importtime
importjson
importrandom
importpyrealsense2 as rs1234567891011121314151617181920212223242526
<程序外部参数设定>
1.–network指定预训练神经网络模型
2.–threshold设定影像辨识阀值(多少以上才进行显示)
3.–width 设定影像宽度
4.–height设定影像高度
# parsethe command line
parser =argparse.ArgumentParser(description="Locate objects in a live camerastream using an object detection DNN.",
formatter_class=argparse.RawTextHelpFormatter,epilog=jetson.inference.detectNet.Usage() +
jetson.utils.logUsage())
parser.add_argument("--network",type=str, default="ssd-mobilenet-v2",
help="pre-trained modelto load (see below for options)")
parser.add_argument("--threshold",type=float, default=0.5,
help="minimum detectionthreshold to use")
parser.add_argument("--width",type=int, default=640,
help="set width forimage")
parser.add_argument("--height",type=int, default=480,
help="set height forimage")
opt =parser.parse_known_args()[0]12345678910111213141516171819
设定jetson.inference的神经网络运算为detectnet,并且透过opt.network的外部参数进行设定预训练神经网络模型。
# loadthe object detection network
net =jetson.inference.detectNet(opt.network, sys.argv, opt.threshold)123
设定Realsense套件的起始条件,并且启动Realsense套件程序。
#Configure depth and color streams
pipeline= rs.pipeline()
config =rs.config()
config.enable_stream(rs.stream.depth,opt.width, opt.height, rs.format.z16, 30)
config.enable_stream(rs.stream.color,opt.width, opt.height, rs.format.bgr8, 30)
# Startstreaming
pipeline.start(config)12345678910
由于启动本程序会进行大量运算,而使微电脑的核心产生高热,因此透过本行程序启动散热风扇进行降温。
os.system("sudosh -c 'echo 128 > /sys/devices/pwm-fan/target_pwm'")1
读取Realsense D435影像内容并且透过Numpy将数据转成OpenCV格式。
depth_image:深度影像信息
show_img:BGR影像信息
press_key= 0
while(press_key==0):
# Waitfor a coherent pair of frames: depth and color
frames = pipeline.wait_for_frames()
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
if not depth_frame or not color_frame:
continue
#Convert images to numpy arrays
depth_image =np.asanyarray(depth_frame.get_data())
show_img =np.asanyarray(color_frame.get_data())12345678910111213141516
透过CUDA进行OpenCV的BGR影像格式转换,并且将影像格式调整适用于神经网络运算的GStreamer格式(img)。
#convert to CUDA (cv2 images are numpy arrays, in BGR format)
bgr_img =jetson.utils.cudaFromNumpy(show_img, isBGR=True)
#convert from BGR -> RGB
img =jetson.utils.cudaAllocMapped(width=bgr_img.width,height=bgr_img.height,format='rgb8')
jetson.utils.cudaConvertColor(bgr_img,img)12345678910
将img影像信息传入神经网络进行运算,并将结果存在detections中。
# detectobjects in the image (with overlay)
detections = net.Detect(img)123
取得所有detections中所有已辨识出来的对象种类与位置信息。
box_XXXXX:边界框坐标
score:辨识信心分数
label_name:对象种类名称
for numin range(len(detections)) :
score =round(detections[num].Confidence,2)
box_top=int(detections[num].Top)
box_left=int(detections[num].Left)
box_bottom=int(detections[num].Bottom)
box_right=int(detections[num].Right)
box_center=detections[num].Center
label_name =net.GetClassDesc(detections[num].ClassID)12345678
透过OpenCV进行每个被辨识出来的对象其边界框绘制、中心准线绘制与标注辨识结果内容文字。
point_distance=0.0
for i inrange (10):
point_distance = point_distance +depth_frame.get_distance(int(box_center[0]),int(box_center[1]))
point_distance= np.round(point_distance / 10, 3)
distance_text= str(point_distance) + 'm'
cv2.rectangle(show_img,(box_left,box_top),(box_right,box_bottom),(255,0,0),2)
cv2.line(show_img,
(int(box_center[0])-10,int(box_center[1])),
(int(box_center[0]+10),int(box_center[1])),
(0, 255, 255), 3)
cv2.line(show_img,
(int(box_center[0]),int(box_center[1]-10)),
(int(box_center[0]),int(box_center[1]+10)),
(0, 255, 255), 3)
cv2.putText(show_img,
label_name + ' ' + distance_text,
(box_left+5,box_top+20),cv2.FONT_HERSHEY_SIMPLEX,0.4,
(0,255,255),1,cv2.LINE_AA)1234567891011121314151617181920212223
透过net.GetNetworkFPS撷取神经网络辨识的FPS值,并且透过OpenCV在实时影像画面中标注其FPS数值内容。
cv2.putText(show_img,
"{:.0f}FPS".format(net.GetNetworkFPS()),
(int(opt.width*0.8),int(opt.height*0.1)),
cv2.FONT_HERSHEY_SIMPLEX,1,
(0,255,255),2,cv2.LINE_AA)12345
透过OpenCV的resize函数进行显示画面的调整,并且进行实时影像的显示。
display= cv2.resize(show_img,(int(opt.width*1.5),int(opt.height*1.5)))
cv2.imshow('Detecting...',display)
keyValue=cv2.waitKey(1)
ifkeyValue & 0xFF == ord('q'):
press_key=11234567
关闭实时影像画面,并且结束Realsense的串流影像传送。
# 关闭所有 OpenCV 窗口
cv2.destroyAllWindows()
pipeline.stop()1234
五、程序执行方式
1.可透过MobaXterm以SSH方式联机进入JetsonNano操作系统操作终端机,或是直接以HDMI屏幕、USB键盘鼠标直接操作亦可。
2.操作本文测试程序之前,请务必要先将Jetson Inference (请参考连结)与Realsense(请参考链接),两个相关程序安装完成,缺一不可。
3.进入终端机指定文件夹中(本文为Realsense_Jetson_Inference)
cd ~
cdRealsense_Jetson_Inference12

4.请确定测试程序存于本文件夹中,并请执行以下指令(默认为ssd-mobilenet-v2模型):
python3detectnet_realsense.py1

执行结果如下:
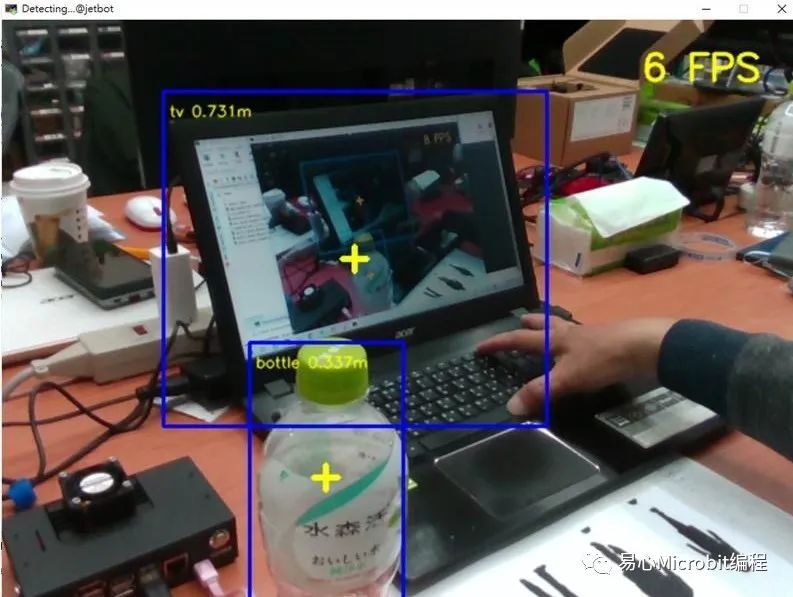
5.或指定其他预训练神经网络模型,请执行以下指令(本文例为pednet模型):
python3detectnet_realsense.py --network=pednet


编辑:黄飞






















 工商网监
工商网监
评论