 电子发烧友App
电子发烧友App


自动驾驶系统依赖于人工智能深度神经网络(deep neural networks, DNN)算法来执行感知、决策和控制等复杂任务。
近年来,针对于自动驾的深度神经网络算法的精度有了显著提高。然而,汽车在行驶过程中,除了要保证自动驾驶系统的输出和决策是准确的之外,其时机也必须是确定性的,因为即使准确但过晚的输出可能导致汽车撞上障碍物从而发生事故。因此准确性和实时性都是安全系统中需要考虑的关键因素。
深入理解自动驾驶系统中的深度神经网络模型的工作负载的多样性和有效的端到端执行,为准确和实时的执行提供硬件和软件机制是保障自动驾驶安全和有效的基础。
考虑到自动驾驶系统当中有多深度神经网络模型需要同时运行,每个模型的工作负载的多样性以及特殊安全性需求等等挑战,如何能够设计一个高效可靠且能适配于神经网络处理器(Neural Network Processing unit, NPU)硬件架构的多深度神经网络DNN的调度机制越来越成为自动驾驶领域内各方关注重点和研究对象。
1. 理解多深度网络生成和执行的上下文
1. 1 深度神经网络工作负载的生成
深度神经网络DNN的可执行文件的生成通常包含以下几个步骤:
首先是在Pytorch、Tensorflow等AI框架下开发和训练得到的模型,也可以进一步将模型转换成ONNX格式。
通常模型在训练完之后,还会通过模型压缩工具进一步进行压缩和转换,这包括量化、稀疏以及剪枝等等,这些方法可以大大地提升模型运行的效率,并节约硬件中存储等资源,这一步骤是可选的。
被转换后的模型通过AI编译器进行编译,通常AI编译器至少分成前端和后端两个部分,前端将模型进行多层融合和算子对应并生成图形表达,后端则是负责将高阶的模型表达形式转换成低阶的张量或者算子层级的表达,并完成到硬件资源的映射和存储分配,生成机器代码,最终编译器将输出可执行文件,以支持在NPU硬件中执行。
有的编译器可以支持单个或者多个模型同时处理,并且将他们联合进行编译乘多种输出形式的二进制文件,包括单个模型在单个stream中,多个模型分成多个stream,以及多个模型混合在同一个stream当中。如下图中所示:
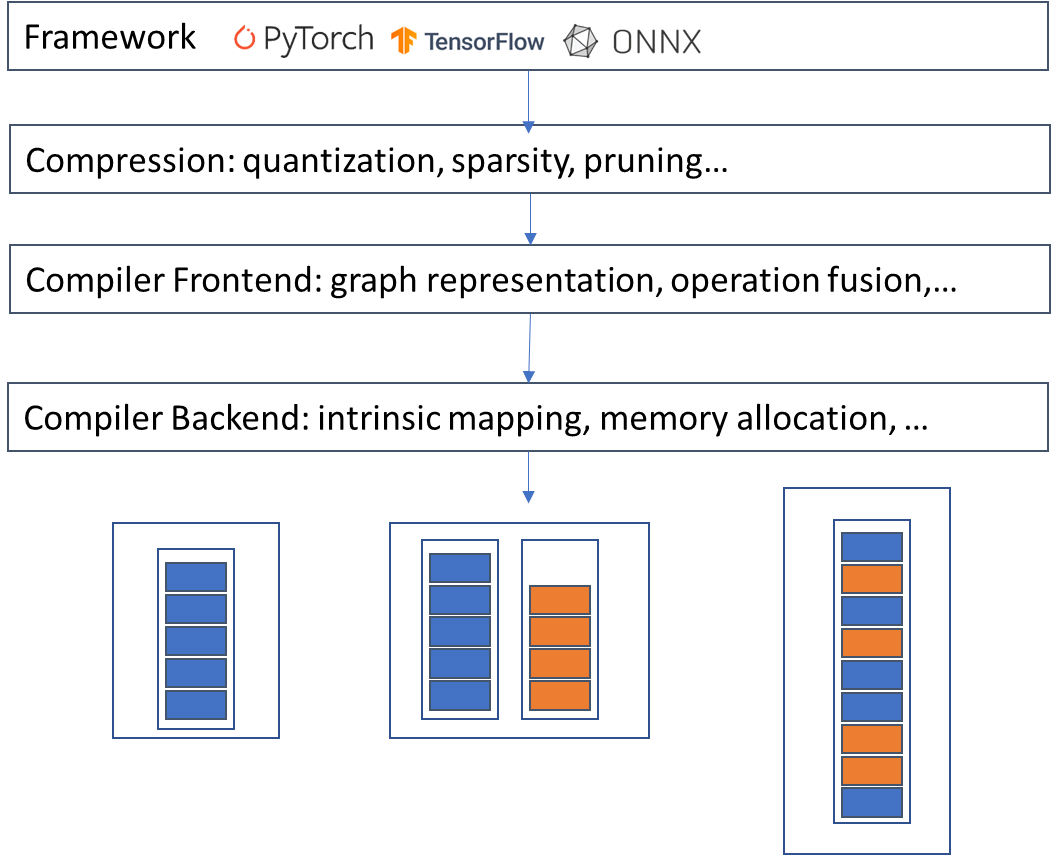
图 1 深度神经网络DNN工作负载的生成步骤
1.2 深度神经网络工作负载的执行
上一节介绍了深度神经网络DNN,接下来再理解下深度神经网络DNN是如何在硬件中执行的。
DNN的执行大体上也可以分为几个层级,最顶层的是应用层,正如之前提到的,编译器可以将多个神经网络模型分布单个或者多个stream当中,在中间层的调度负责将具体的任务负载从各个stream中提取出来放到调度队列当中,然后由底层驱动和运行时调度器将任务分配到NPU硬件中进行执行。
负责执行深度神经网络的硬件架构有多种形式,从单个计算核心到多个簇(Cluster)以及异构架构等等。一般来说计算核心是由调度器以及处理单元(Processing Element,PE)阵列组成,而cluster则有多个计算核心组成。在异构架构中除了有PE阵列单元负责卷积以及矩阵操作之外,还有支持向量运算的向量计算单元等等。
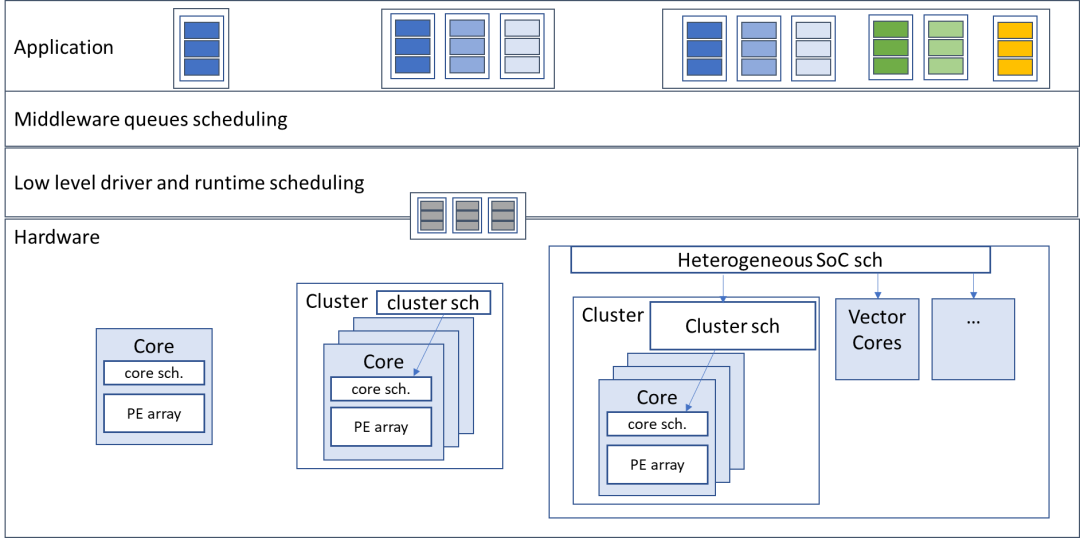
图 2深度神经网络DNN工作负载的执行分层
2. 深度神经网络DNN在NPU上调度的目标和挑战
2.1 深度神经网络DNN在NPU上调度的挑战
01
多深度神经网络DNNS的实时性要求
各个模型需要执行的开始时间不同,同时各个模型的任务截止时间也不相同。另外优先级高的模型任务需要得到优先调度,甚至有的时候需要抢占式来保证高优先级的任务模型立即执行。最后还要满足模型的服务质量(quality of service,QOS)的要求等等。
02
深度神经网络的负载多样性
深度神经网络由多个层级组成的结构,其负载实质上就是其中不同层级中的算子操作。这些算子的计算强度各不相同,计算强度是由计算量除以访存量就可以得到的,它表示此模型在计算过程中,每个字节内存交换到底用于进行多少次浮点运算,其单位是字节每秒浮点运算次数(FPLOPs)/字节(Byte),算子计算强度越大,其内存使用效率越高。根据计算强度我们可以把不同的算子其分为计算受限(computing-bound)以及存储受限(memory-bound)两种类型。
对于计算受限的算子,它们通常对相同的数据执行多个操作,因此可以充分利用加速器中的处理元素。但是,它们不需要经常从内存中获取数据,而不需要充分利用内存缓冲区和带宽。这是卷积算子的情况。
对于存储受限的算子,它们的数据可重用性很低。因此,他们需要非常频繁地获取数据,计算资源没有得到充分利用,等待更多的数据。池化(Pooling)、全连接层(full connection)、激活函数(activation function)等算子以及自注意力(self-attention)等算子都是受内存限制类型的。
正是由于计算受限和存储受限的算子对于资源的诉求不同,因为调度器需要根据将被执行的算子的特性进行不同的调度策略和资源分配才能达到实时性和高效率的要求。
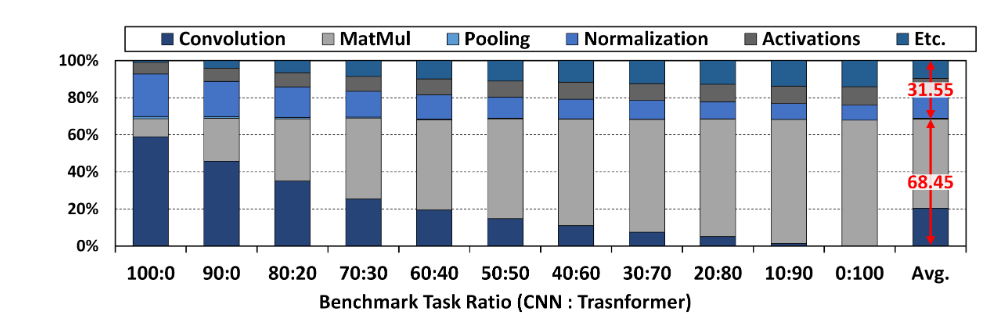
图 3深度神经网路DNN中不同算子的占比
(J.-H. Kim et al., 2022)
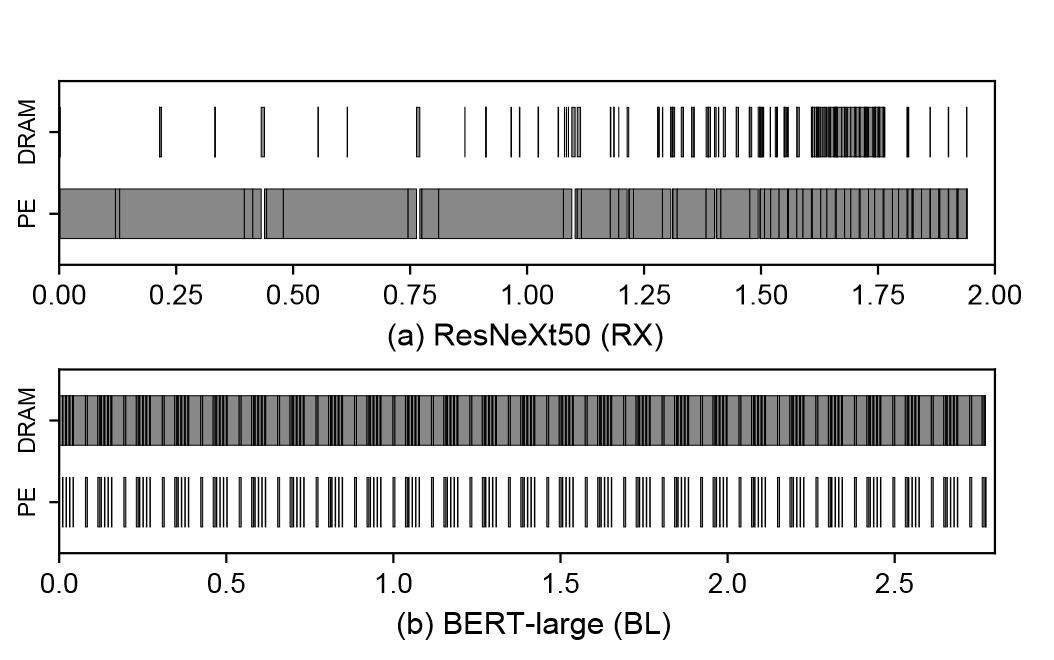
图 4 DNN中的计算受限和内存受限的工作负载
(Y. H. Oh et al,2021)
03
特殊安全和可靠性需求
一些负载由于要满足特殊安全性的需求,需要通过硬件资源与其他的负载进行分离以达到确保的安全性和实时性。
04
硬件灵活性带来的映射空间巨大
NPU的架构形式非常丰富,而不同的硬件架构形式又决定了NPU可以支持的调度的灵活性。
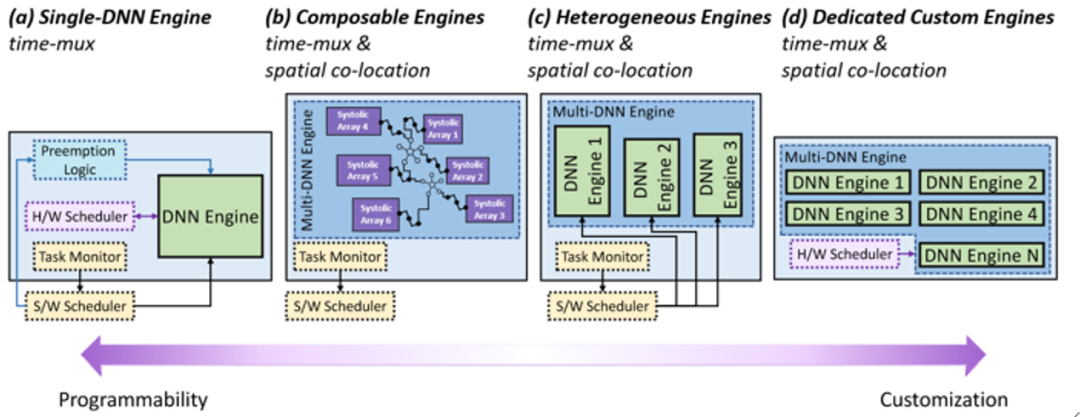
图 5 NPU的架构设计空间分类
(Stylianos I. Venieris et al., 2022))
硬件支持的调度灵活性通常可以分为四个维度:
T 即数据切块大小(Tile sizes):改变张量数据结构在多层次结构的缓冲区的每个级别中的数据切块的边界和宽高比。
O 即循环顺序(Loop order):改变每个数据切块的循环计算结构中循环执行顺序。
P 即循环并行化(Loop parallelization):改变每个数据切块的计算中从哪个张量维度(长、宽或者通道)进行并行化调度,这实际代表着数据的空间划分(例如跨多个PE划分)。
S 即数组形状(Array shape):改变加速器硬件资源即PE阵列的逻辑形状和集群方式。这决定了数据切块的数量和在PE阵列上映射的张量维度的最大切块尺寸。
每一种灵活性都会带来多余的硬件面积,因此绝大多数NPU硬件架构只能支持以上几个维度当中的一个或几个, 但是也会形成一个巨大的硬件映射空间,而针对于一个特定任务负载的每一个调度的决策在这个映射空间都是一个点,其结果都会得到不同的延时以及硬件利用率等性能。这些因素都给调度器和编译器带来了相当的复杂度。
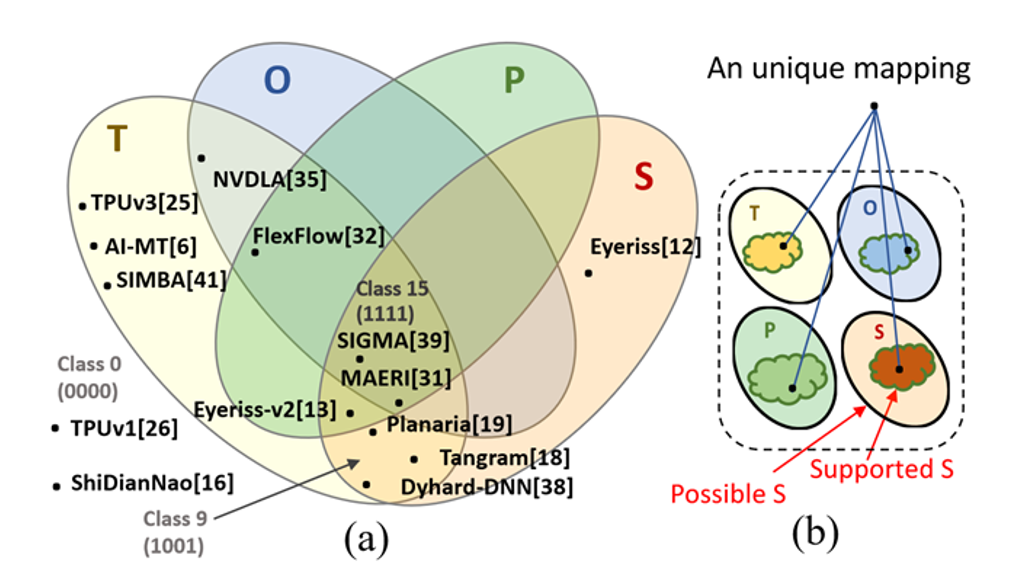
图 6 不同NPU架构支持的灵活性维度以及映射空间
(S.-C. Kao et al., 2022)
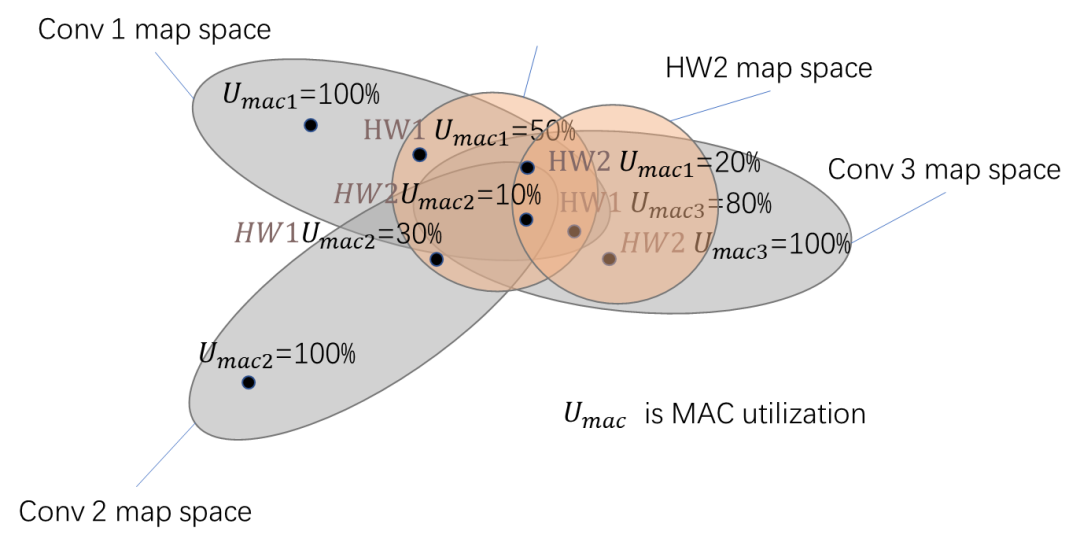
图 7 不同深度神经网络DNN工作负载
在不同的硬件的设计空间进行映射
2.2 多深度神经网络DNN调度的目标和指标
在多个DNN工作负载运行时,对于调度机制来说有多个而不是单一的优化目标,包括满足不同DNN网络的实时性要求,高效的硬件映射以及调度的开销/收益的平衡等等。
在评估调度方法时,常见具体使用性能指标以及计算公式如下公式所示:系统吞吐量(STP),度量在多程序执行下,每个任务的性能下降的程度:
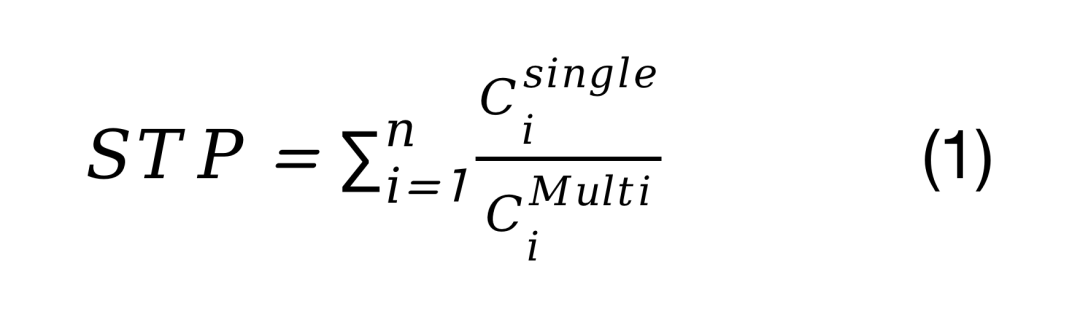
标准化周转时间(NTT),用来度量单一任务执行的时间是否比多个任务执行时放缓:
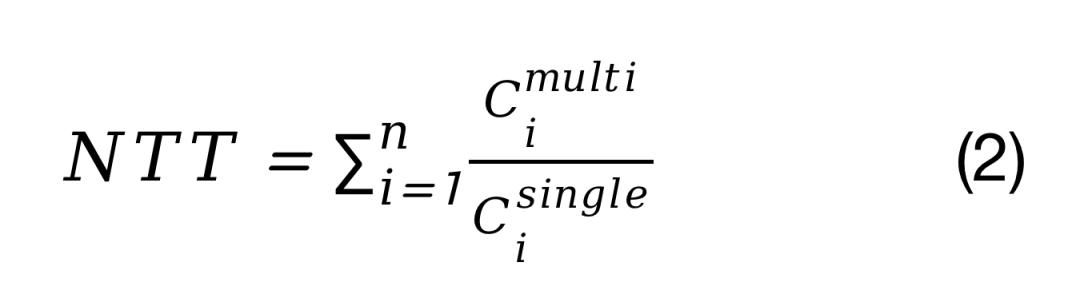
NTT的算术平均值(ANTT),即NTT的算数平均值:
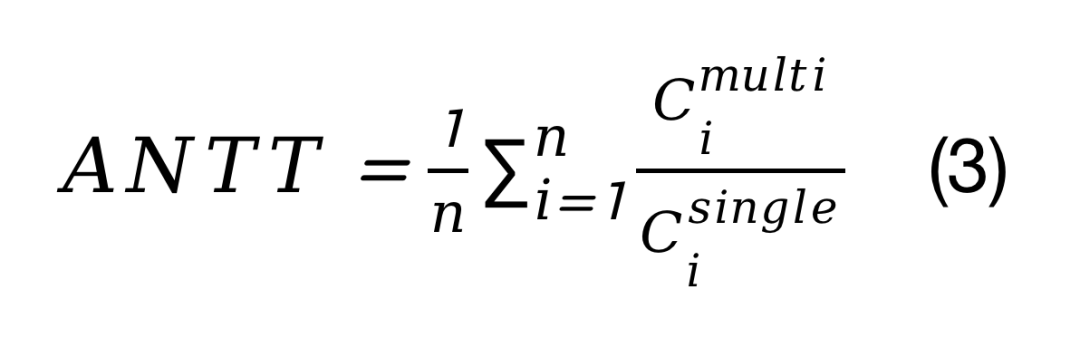
公平性(Fairness),在多任务环境下,相对于任务的孤立执行,衡量任务进度的平等程度:
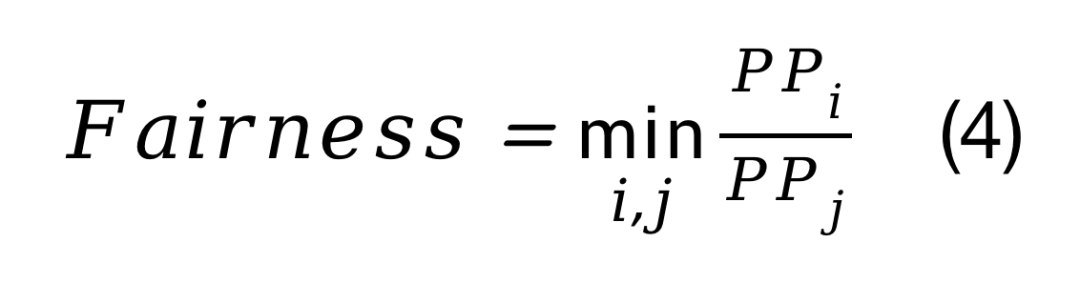
上述式子中,Cisingle表示仅有第i个深度神经网络DNN在NPU中执行所需的时间,Cimulti表示有n个深度神经网络DNN在NPU中执行时,第i个深度神经网络DNN执行所需要的时间,而PPi的表示如下式所示:
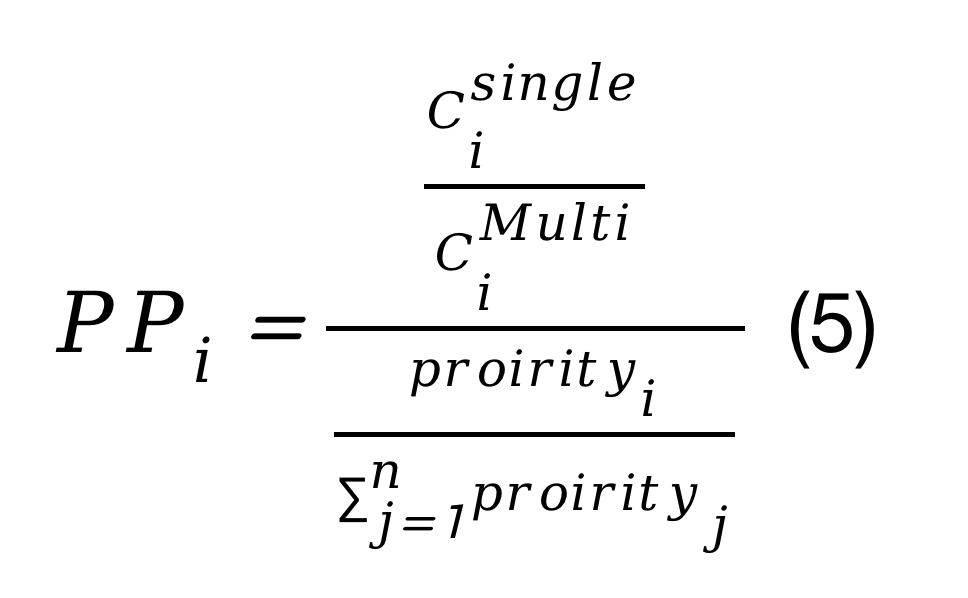
3. 多深度神经网络DNN在NPU上的调度优化策略
3.1 单个深度神经网络DNN调度优化方案
传统上优化DNN调度的问题主要就是关注在单个核心NPU或GPU中调度单个模型到达最低的时延和最高的硬件利用率。
在DNN的运行分层从上到下使用了几种优化技术,:
服务层级编排(orchestration):它发生在软件层级,当云服务接收数百万DNN任务并将其分发到多个服务器时。
图级并行化:在DNN编译器中通常使用有向无环图(Directed Acyclic Graph, DAG),其中节点表示深度神经网络中的算子,边表示张量。这一级别的优化旨在充分实现图中的并行性提高计算效率,因此通常是在软件的编译器中进行优化。
运行时级调度:旨在使用负载平衡和并发方式来优化算子之间的并行性上。在单一DNN模型推理中,这仅限于模型内的并行性, 而在多个DNN模型推理中,则可以是跨模型的并发。
算子级别:通过循环平铺和缓冲区管理等机制来加速算子执行,以达到充分利用NPU计算和内存资源。在GPU中,这通常是作为内核级的调优完成,而在NPU中,则是由编译器完成的。
3.2 多个深度神经网络DNN调度优化策略
01
时分复用(time multiplex)
时分复用是一种常用的多神经网路调度的策略是时分多路复用。
在这种策略中,单个DNN模型使用整个加速器,然后转换到另一个DNN网络模型。这通常是通过每个DNN在不同的stream中来进行管理的。
时分多路复用调度策略也可以采用多种多样的形式,例如可以是基于FIFO的、固定时间的、贪婪的或计算-存储平衡的等等策略。其中计算-内存平衡调度器的目标是提高硬件利用率并降低总体延迟,当内存资源被完全占用时,它们会调度计算受限(computing-bounding)的算子到硬件中执行,而当计算能力被充分利用时,则调度内存受限(memory-bounding)的算子到硬件资源中执行。
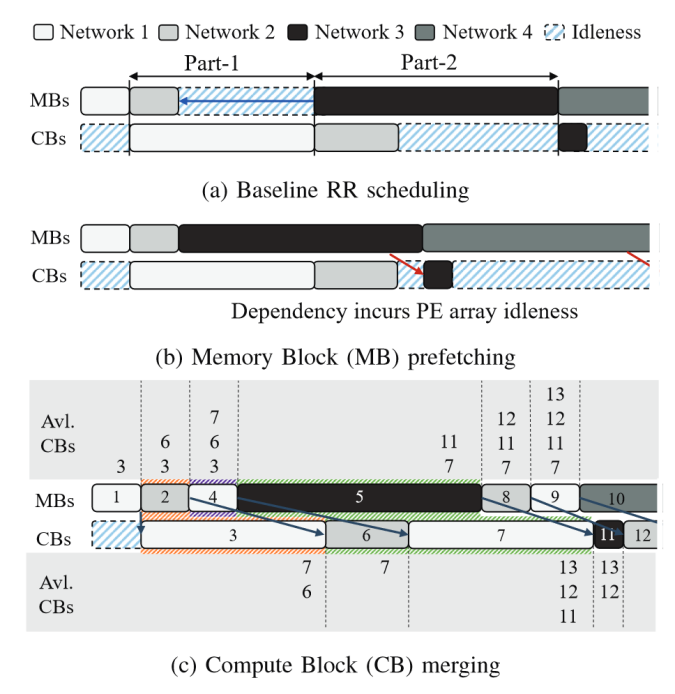
图 8 时分复用方式调度的例子示意
(E. Baek et al., 2020)
02
共部(co-location)
在多个同一类的网络模型共享使用同一个硬件资源的方式叫做共部(Co-location),这可以通过在硬件架构中使用不同处理器模块专用于多个同一类的网络模型来实现。
例如在FPGA模型开发研究中,通常每个网络或每种网络类型都有一个专门的处理器模块。但是共部(Co-location)不仅局限于FPGA上的专用处理器模块,在具有多核的NPU硬件架构中,也可以将每个核都分配一个网络模型。
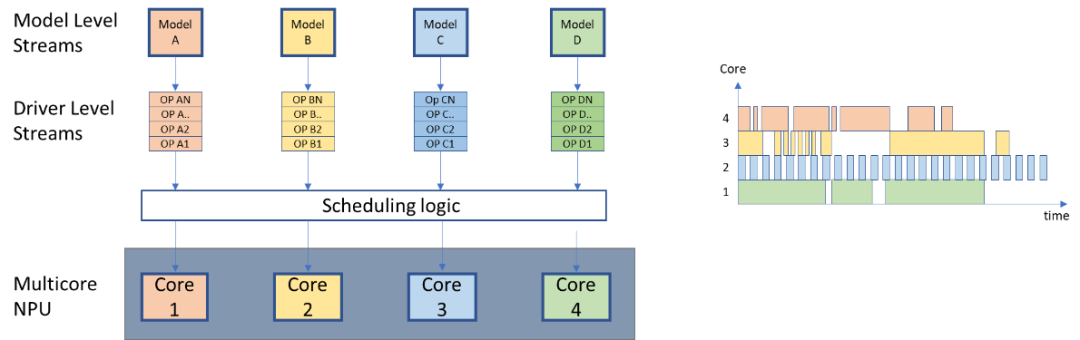
图 9每个模型都分配专用计算核心的
共部(co-location)调度策略
03
混合调度
共地址的调度方式也可以与时分多路复用方法相结合。如下图所示,在NPU架构中有4个计算核心,其中左边三个核心支持分时复用的调度策略,而最右侧的核心则实现了共部调度策略;在这种情况下,调度可以获得一些模型的时间复用优势,同时保持一个模型的专用核心。这可能是决定论或安全性所需要的。
不同的方法需要不同的硬件和软件来支持它们,这取决于不同的场景的需求,在设计中考虑运行时哪项指标是最重要的:吞吐量、延迟、公平性或确定性。
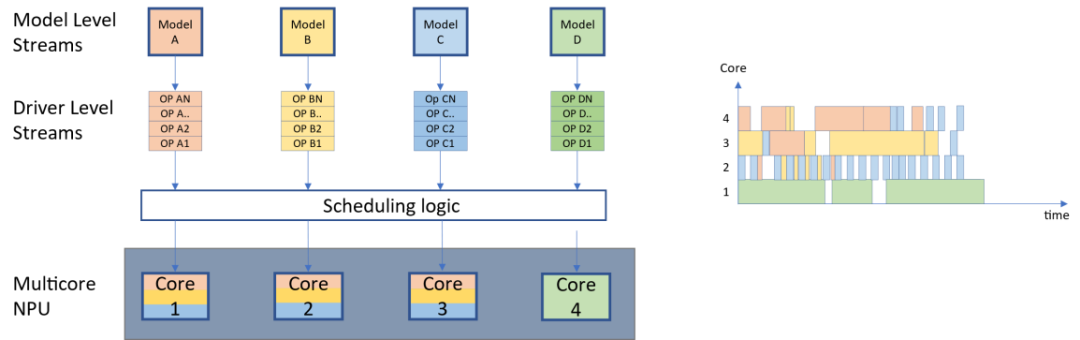
图 10共部以及时分复用混合的调度策略
3.3多核架构NPU的调度策略
多核架构NPU的调度策略主要有:
基于帧的分割: 同一个深度神经网络DNN模型推理时,可以并行处理多帧数据的推理,而不同帧则由不同的计算核心同时处理,模型参数可以在核心之间共享。
基于层的分割: 在运行深度神经网络DNN对某一帧数据进行推理的时候,将DNN模型按照层进行分割后在多个计算核并行处理。这种方法提高了吞吐量,但是需要一个很好的平衡策略使整个网络模型能够恰好地分割到所有核心,否则会出现部分计算核心处于空闲状态,从而降低了硬件领用率和推理时延。
共享输入特征的特征映射分区:在这种方法中,通过将深度神经网络DNN中的每一层的输入特征(input feature)划分到不同的核心并行运行。考虑到数据可以广播,因此带宽显著减少。由于每次只在每个核上处理输入特征的一部分,因此在最后要做一些后处理来考虑边缘对齐。
共享权重的特征映射分区:和前一种方式类似,只是划分的对象变成了权重而非输入特性。在深度神经网络DNN中的每一层通过在不同计算核心中划分权重来在多个计算核心中并行运行,同时带宽会显著减少。
总结
深度神经网络模型DNN正以令人眼花缭乱的速度演进发展,随着算法多样性和更高算力的需求推动着NPU的硬件架构朝着规模越来越大,核心的数量也越来越多,而硬件的设计和验证时间相比软件更费时费力,这使得处于模型算法和硬件之间的调度系统变得越来越重要。
如何在硬件加速器上高效地运行多个DNN模型的策略选择有很多,许多新的优化机会还在不断涌现中。
然而,这些优化是有代价的,目前看起来最有前景的调度策略都需要硬件支持,如抢占表、权重的内存直接访问(Direct Memory Access,DMA)、输入特征的DMA或硬件运行时调度模块。
因此在为未来的深度神经网络DNN设计调度机制时,最大挑战是需要协同软件和硬件在成本、性能和未来工作负载的灵活性之间保持良好的平衡。
参考文献:
[1] H. Kwon, P. Chatarasi, M. Pellauer, A. Parashar, V. Sarkar, and T. Krishna, ‘Understanding Reuse, Performance, and Hardware Cost of DNN Dataflows: A Data-Centric Approach Using MAESTRO’. arXiv, May 11, 2020. Accessed: Jul. 21, 2022. [Online]. Available: http://arxiv.org/abs/1805.02566
[2] L. Liu, Y. Wang, and W. Shi, ‘Understanding Time Variations of DNN Inference in Autonomous Driving’. arXiv, Sep. 12, 2022. doi: 10.48550/arXiv.2209.05487.
[3] F. Yu et al., ‘Automated Runtime-Aware Scheduling for Multi-Tenant DNN Inference on GPU’. arXiv, Nov. 28, 2021. doi: 10.48550/arXiv.2111.14255.
[4] Y. Choi and M. Rhu, ‘PREMA: A Predictive Multi-task Scheduling Algorithm For Preemptible Neural Processing Units’. arXiv, Sep. 06, 2019. Accessed: Jul. 19, 2022. [Online]. Available: http://arxiv.org/abs/1909.04548
[5] E. Baek, D. Kwon, and J. Kim, ‘A Multi-Neural Network Acceleration Architecture’, in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), May 2020, pp. 940–953. doi: 10.1109/ISCA45697.2020.00081.
[6] J.-H. Kim, S. Yoo, S. Moon, and J.-Y. Kim, ‘Exploration of Systolic-Vector Architecture with Resource Scheduling for Dynamic ML Workloads’. arXiv, Jun. 07, 2022. Accessed: Aug. 12, 2022. [Online]. Available: http://arxiv.org/abs/2206.03060
[7] S. I. Venieris and C.-S. Bouganis, ‘f-CNNx: A Toolflow for Mapping Multiple Convolutional Neural Networks on FPGAs’, in 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, Aug. 2018, pp. 381–3817. doi: 10.1109/FPL.2018.00072.
[8] Y. H. Oh et al., ‘Layerweaver: Maximizing Resource Utilization of Neural Processing Units via Layer-Wise Scheduling’, in 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Korea (South), Feb. 2021, pp. 584–597. doi: 10.1109/HPCA51647.2021.00056.
[9] F. Yu, D. Wang, L. Shangguan, M. Zhang, C. Liu, and X. Chen, ‘A Survey of Multi-Tenant Deep Learning Inference on GPU’. arXiv, May 24, 2022. Accessed: Dec. 15, 2022. [Online]. Available: http://arxiv.org/abs/2203.09040
[10] Stylianos I. Venieris, Chistos-Savvas Bouganis, Nicholas D. Lane, ‘Multi-DNN Accelerators for
Next-Generation AI Systems’. IEEE Computer Journal, 2022
[11] S.-C. Kao, H. Kwon, M. Pellauer, A. Parashar, and T. Krishna, ‘A Formalism of DNN Accelerator Flexibility’. arXiv, Jun. 06, 2022. Accessed: Aug. 17, 2022. [Online]. Available: http://arxiv.org/abs/2206.02987
作者简介
Carlos Nossa,复睿微电子英国研发中心软件架构师,常驻英国剑桥。曾在知名通信芯片公司参与多款物联网芯片相关的开发和研究工作,负责期平台软件架构设计,并通过安全认证,实现海量发货。
Shawn Ouyang,复睿微电子英国研发中心系统架构师,常驻英国剑桥。曾在某顶尖通信公司的海内外研究所从事近10年手机和物联网芯片相关的开发和研究工作。
编辑:黄飞





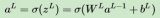
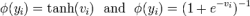







 工商网监
工商网监
评论