 电子发烧友App
电子发烧友App


近期,ChatGPT以百科全书般的功能引发了业界关注,作为下一个探索热点,AIGC也激发了大量的行业需求。AIGC将如何重塑内容生态?算力作为AIGC应用背后的关键,AIGC对算力有哪些需求?2月10日,摩尔学院院长李丰做客网易科技《迈向AIGC大淘金时代》直播连线,并带来《全功能GPU是AIGC的算力底座》为主题的分享。
以下是经过整理的访谈实录:
主持人:大家在接触ChatGPT之后,会有一种被震撼的感觉。其实AIGC对于目前的内容创作,更多是一种辅助,之后是和人类合作,最后它到达自主的原创阶段。其中每一个阶段,需要在算法或者数据训练方面做出哪些突破,距离AIGC真正高度取代人类又有多远的距离?
李丰:首先,现在ChatGPT也好,AIGC也好,已经可以在某种程度上替代一些人的工作了。以ChatGPT来说,目前它天然的模型是有一些缺陷的。比如,如果你去使用真的ChatGPT,它经常会一本正经的“胡说八道”,这个现象是很普遍的。
我们都知道作为人类,一个人对信息的判别和过滤,很多人连网络上各种虚假信息都不具备真假的辨别能力,我们跟AI对话当中得到的信息,我们怎么知道它是真是假,这是目前的一个很大的问题。而这个问题至少在目前的ChatGPT技术架构上是无法解决的。同时,因为它现在整个模型的知识,官方说截至2021年。假设实时的新产生的知识它不知道的时候,必然有一些时效性的知识它是有可能“胡说八道”的。所以,当AIGC产生的大量内容和人类产生大量的内容,融合在一起的时候,在很大程度上,你是很难很快去区分的,不管是文字还是图片。
第二,我们可以在产品上,把一些实时的结果跟ChatGPT的对话结果融合在一起。就像谷歌前几天的发布会,虽然它的Bard在发布的时候回答错了一些问题。但是实际上,如果说我们真的去用ChatGPT就知道,ChatGPT回答错的问题更是多了去了,所以我不认为谷歌的技术就比不上OpenAI,做不出类似的东西。反而是因为它的搜索覆盖的用户群过于巨大,它在产品上做一个小的修改,很有可能会引起数以亿计的用户习惯的改变,以及影响到它数十亿美金的收入。所以它和OpenAI的地位是不太一样的,它必然就会束手束脚,这是一个很重要的原因。
总的来说,AIGC实际上已经进入生产,已经可以满足我们低阶的需求,但是要看你怎么用。实际上我知道的一些团队,包括我所在的团队,都已经把AIGC的内容导入了工作流,做某个方面的优化。我相信很多的AIGC的产品,它现在在辅助人类的工作,以及替代人类的局部工作,这个现象已经在产生,而历史的车轮是不可阻挡的。
但也正如前面我提到,ChatGPT现在产生的很多内容,对于精准性、正确性来说,是有很大的缺陷的,这个影响如果说贯穿到很多的行业里,也可能带来对社会的一些负面影响,所以很多技术,在使用过程当中,我们既要拥抱它的变化,既要善于使用工具,同时也要能够控制工具,这是我的观点。
主持人:像AIGC应用,包括ChatGPT,目前需要的算力并不低,如何平衡算力成本和商业变现之间的关系?对于AIGC而言,如何打造一个长期的商业模式或价值?
李丰:首先算力这个问题,在某种程度上,随着时间的推移,成本肯定会下降。因为我们都知道,GPU一直是号称超越摩尔定律算力的发展,因此,我觉得某种程度上,算力的成本会随着时间的推移、半导体技术的发展,这是一个降低的维度。另外一个维度是说算法的改进,效率的提升,包括一些压缩模型的提出和使用,也会使得成本有一个降低的维度。
商业模式这一点,我认为芯片厂商,可能是吃到AIGC这一波大红利的厂商。因为他们是基础设施的提供者,几乎所有的AIGC算力,现在都是GPU在提供,尤其是在训练方面。另外一类,比如说云厂商,同样作为基础设施提供者,会推出大量的GPU云,以降低GPU部署的门槛。我认为这两类厂商,相对来说,商业模式比较清楚,它的盈利的点,包括商业模式的建立比较清晰,可以得到保障。
同时,现在产生出一种新的模式,有的把它叫做MaaS,也就是说模型即服务。有很多的厂商把自己预训练好的大模型开源出来,这些大模型如果你本机用还可以,但是要把它作为一个服务提供出去的时候,就需要算力托管。所以如果说把大模型加上算力托管做成中间件,提供很多标准的、可调度、可管理的API对外提供,我相信这又是另外一种商业模式,会有不少厂商在这一层上做。
但是因为算力的产生,算力由中间件到应用开发商,最后到用户付费这个管道,因为不同用户付费的意愿和付费的能力是不一样的,假设你开发的只是一个玩具,写写古诗词,你可能用户量很大,但是大部分人不会付费,最多有的人会愿意付你几块钱的订阅费,这要覆盖算力成本几乎不可能。但如果把AIGC很多成果和生产力对接,能够解决很多具体的问题,很多行业里的垂直用户是愿意为这些具体的问题付出高昂费用的。所以目前看起来,我看应用级别,已经产生了比较大收入的,因此这也是一类商业模式。
还有一类是用AIGC文本生成,去做产品评测的文档,大规模的发出去引流,然后把流量拿来变现,这一类厂商有一些收入也不错。从另外一个角度来说,一大堆AI产生的内容,在互联网上作为引流信息,可能人也不怎么看,实际上在互联网上本身也是一个商业模式,所以这个商业模式也是一类。
总而言之,我认为基础设施、中间件、算力托管、云服务厂商,这些相对来说随着时间的推移,盈利模式会比较容易,但是应用开发商还有很长的路要走,至少目前世界上最火的ChatGPT,现阶段肯定是严重亏损的,所以什么时候能够达到真正的盈利这一点,有待观察。
主持人:AIGC如果要大规模应用,它成功的必备因素有哪些?目前国内AIGC的发展现状如何?与ChatGPT的差距在哪里?
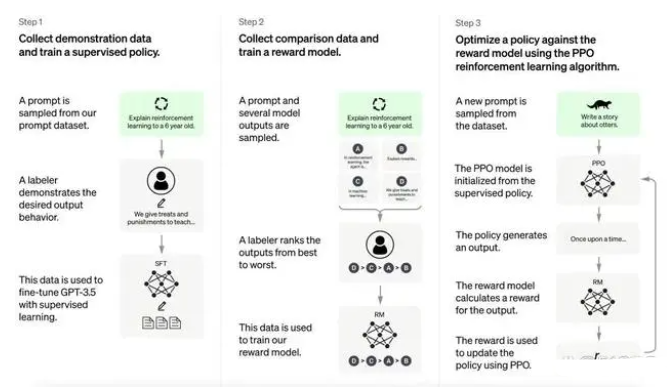
李丰:任何技术从诞生到成熟,到真正的得到应用,它是有一个很长的时间周期的。ChatGPT今天有这样的成果,并不是突然冒出来的,因为OpenAI经历了很长一个过程,它作为一个非营利性组织,到相对商业化运作,这个时间是非常长的。而且ChatGPT本身也是经过了GPT1、GPT2、GPT3,包括它是在GPT3.5上加入了很多人类反馈的微调才产生的,它的整个诞生过程是相当漫长的。所以,任何在这个领域里想深耕的企业,它是需要有很长的技术积淀的。
目前,从我个人观察来看,国内网络上,以ChatGPT为名的,各种各样的微信机器人、网络的应用,相当大一部分和ChatGPT没有什么关系。很多行业做的事情只要能沾点边,就拼命往ChatGPT上去靠。在我看来,并不是说今天有一家公司说,ChatGPT很热,马上要做就可以成功。
第一个因素是资金。虽然说ChatGPT没有公布GPT3.5的参数,但是GPT3的参数量高达1750亿,数据量也达到了45TB,从一些数据来看,它动用的GPU训练算力是世界上最高端的GPU芯片,而且是成千上万张来进行训练,所以训练一次的成本相当昂贵。所以很多小型团队如果说没有足够的资金,这件事情至少目前无法实现。
第二因素是原创性。我们必须得承认,在人工智能方面很多的原创模型和原创算法,目前很多还是来自于硅谷的团队,其实ChatGPT也不是从零开始的,它的很多模型也是来自于其他,比如说它使用了谷歌的Transformer,所以说ChatGPT也是站在全世界很多个科学家以及很多企业,包括很多的开源贡献者的肩膀上才出现的。目前,国内很多企业也运用了开源,比如GPT2是开源的,BERT是开源的,在一些开源模型上,做一些调整,产生出一些应用,不是说这个方法不好,但是实际上,我们还是在前人很多的技术基础上来进行修改,我们并没有诞生出在AIGC方面原创性的成果,我们必须要承认这个差距是在的。
当然,国内近期有一些大的企业,比如说百度、阿里等厂商,已宣布将发布类似于ChatGPT的产品战略或者是产品的体验。我相信这些国内的大厂,因为有很长时间的技术积淀,也有大量的数据积淀,也有足够雄厚的资金和足够多的工程师,所以,我很期待国内AIGC在接下来的时间里陆续亮相。
主持人:算力是AIGC应用背后的关键,AIGC对算力有哪些需求?企业若想大力发展AIGC,在算力方面方面应该做哪些部署?
李丰:我们今天做一个AI应用的部署,实际上就像造车一样,我们不是从种一棵橡胶树开始的,而是基于很多前人的技术成果上来搭建我们自己的应用。我们必须基于很多开源生态当中的成果来做,所以就不得不使用同样算力平台来做这件事情。
我们也看见有一些AI专用芯片在某些专门算法上优于GPU,但是AI模型和算法迭代的速度非常快,而针对专用算法优化的特定芯片,如果说现在部署,很可能到用上那一天,这个算法已经落后了,所以为了兼顾灵活度和应用开发的算力,目前来看全功能GPU更适合。或许将来,在推理尤其是边缘端的推理上,可能会有一些专用的SoC可以用于在推理方面的很多应用。事实上,包括现在,在边缘推理上,其实已经有一些专门的SoC在图像识别等领域得到了应用。
因此,我个人认为,将来的生态,基本上会以GPU为主,辅以其他种类芯片的生态。所以,假设今天要部署算力集群,首先要有一个明确的目标,我到底要做什么?我需要跟OpenAI去PK大语言吗?这时候就要先评估自己的资金有多少亿打底,如果有看OpenAI发表的一些文章和访谈就知道,有很大一笔费用,他们用于购买GPU。而且买来了GPU,还要有运维、管理、算力部署,需要一个团队来运营,所以要做什么,决定了你要投入多少在算力部署上。
同时,我认为现在,尤其对于很多小型团队,肯定要想清楚自己要做什么,因为AIGC是一个工具,最终要解决人类的某些问题,所以我更认为,为你要解决的某些问题来做算力的部署规划,然后同时有一部分自己本地的小型算力部署,结合一些GPU算力云的算力调用,有可能随着用户的多少或者是计算任务种类的变化,你需要一个弹性可变的算力,所以需要一种混合部署的方法,包括很多企业在做AIGC时,基本上也是采用这样的方式。此外,对于个人而言,也有一些模型是可以在本地计算机上部署的,当然这些模型部署下来,需要的也是本地GPU。因此,在算力部署这个话题上,无论你从哪一个角度去看,都绕不开GPU。
主持人:ChatGPT可以说是AIGC当中的一个爆款,摩尔线程也有自己的AIGC平台,咱们在开发的过程中遇到最大的困难和挑战是什么?从ChatGPT的发展上是否得到什么启示?未来希望怎么落地?
李丰:首先,摩尔线程部署自己的AIGC平台,这件事情很久以前就在做了。我们跟很多其他厂商不同,我们在推出服务的时候,要必须让所有的应用都部署在自己的GPU上,要把现在丰富多样的模型以及生态,在我们GPU上运行起来,这背后还涉及了很多技术问题。总的来说,摩尔线程作为一个算力提供者,我们希望能够帮助应用开发商拥有一个从端到端的硬件到软件栈的一套整体解决方案,包括我们也推出了算力底座MCCX元计算一体机,专为元宇宙应用构建的MTVERSE元宇宙平台,可以把上层SDK工具提供给开发者,实现AIGC内容生成等一系列功能,进一步简化应用和解决方案的开发周期和难度。
所以,我们做AIGC平台,不是简单做一个应用开发,把应用开放出来给消费者使用就可以了,我们要兼顾要做的事情,远比单纯的应用开发商更复杂,而且做GPU最难的是生态的建立,我们要兼顾很多的生态兼容性,比如全功能GPU做多模态生成,对于各种视频格式的编解码,作为科学计算的使用,包括AI训练和推理,包括要展现出图形的三维的、二维的各种渲染。实际上,我们希望自己的AIGC平台,运行在自己的GPU上,能够展示出摩尔线程研发了一个真正的全功能GPU,能够在AIGC领域对很多类型的内容生成都进行良好的支持。
除此之外,我们开发的AIGC平台,也在去年11月发布会首次亮相,它叫摩尔线程“马良”,我们内部已经内测了很长一段时间,现在还在不断迭代和增加功能过程当中。今年之内,我们陆续会有一些AIGC的成果给大家展现。
此外,摩尔学院院长李丰还带来《全功能GPU是AIGC的算力底座》的主题分享,以下是经过整理的现场实录:
最近大热的话题ChatGPT在AIGC(AI Generated Content)的C当中,属于自然语言的本文生成,包括前一段时间流行的文本生成图像,这些类别我们都统称为AIGC,实际上就是用人工智能来生成各种类型的内容,包括文本、图像、音乐、视频、三维模型等,而且还会涵盖面越来越广。
其实不管是ChatGPT,还是基于文本的图像生成,它们都有一个底层逻辑,所有这一切都是计算能力产生的内容,而这个算力是现在几乎AIGC都采用的算力——GPU。那么,为什么最终的内容生成都依赖GPU?
首先,GPU为现代科技当中需要算力的地方提供了重要支撑,比如大家熟悉的图像识别、自动驾驶的训练、包括推荐算法等领域,以及科学计算、高清视频编解码,这些很多需要算力的领域。今天,全世界和中国主要增长算力的来源都是来自于GPU,而AIGC是通过人工智能的模型,通过一些算法来产生出内容,这些内容的种类多种多样,其产生的机理,大多数先要历经一个训练过程,这个过程中需要大量的数据,这些数据需要在非常庞大的GPU集群上进行训练,训练完成之后,又部署到GPU的集群上,然后大家在使用当中,它是一个推理的过程。
所以,今天所有的AIGC都绕不开的一个话题,它们的算力底座都来自于全功能GPU,而且我们都知道,ChatGPT主要是文本生成,还有很多人用ChatGPT生成的文本也去生成图像。这个过程不管是生成图像、视频还是三维模型,又需要另外一种计算方法,比如生成高清视频,需要视频编解码;生成音乐,需要音频的编解码;三维模型需要三维的渲染,所以所有的这一切,就使得GPU成了这个浪潮当中基础设施的提供者。
我们都知道,所有的人工智能算法是在不断进步和迭代的,GPU兼顾了灵活度以及计算能力,它是属于芯片行业的“圣杯”。摩尔线程作为一家以全功能GPU芯片设计为主的创新型企业,我们也有在AIGC方面的布局。实际上,我们已经在内部测试,一个完全部署在摩尔线程全功能GPU上的AIGC平台,不久就会跟大家见面,它包括了图像生成、自然语言生成等一系列的多模态内容生成平台。
当然,我们也希望随着技术的进步,GPU可以为接下来的AIGC带来很大的助力。所以总的来看,GPU作为AIGC的核心发动机,以及算力的提供者和算力服务的支撑者,摩尔线程可能跟目前市场上做AIGC的一些企业定位不同,我们相当于属于整个产业的基础设施的提供商,也希望为中国AIGC发展及相关算力应用提供强大且易用、坚实的算力底座。
编辑:黄飞































 工商网监
工商网监
评论