电子发烧友网报道(文/李弯弯)在深度学习中,经常听到一个词“模型训练”,但是模型是什么?又是怎么训练的?在人工智能中,面对大量的数据,要在杂乱无章的内容中,准确、容易地识别,输出需要的图像/语音
2022-10-23 00:19:00 24277
24277 分布式深度学习框架中,包括数据/模型切分、本地单机优化算法训练、通信机制、和数据/模型聚合等模块。现有的算法一般采用随机置乱切分的数据分配方式,随机优化算法(例如随机梯度法)的本地训练算法,同步或者异步通信机制,以及参数平均的模型聚合方式。
2018-07-09 08:48:2213609 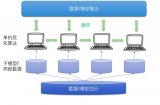
随着预训练语言模型(PLMs)的不断发展,各种NLP任务设置上都取得了不俗的性能。尽管PLMs可以从大量语料库中学习一定的知识,但仍旧存在很多问题,如知识量有限、受训练数据长尾分布影响鲁棒性不好
2022-04-02 17:21:438765 为什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 几种并行方式,分别在模型的层内、模型的层间、训练数据三个维度上对 GPU 进行划分。三个并行度乘起来,就是这个训练任务总的 GPU 数量。
2023-09-15 11:16:2112112 
Hello大家好,今天给大家分享一下如何基于YOLOv8姿态评估模型,实现在自定义数据集上,完成自定义姿态评估模型的训练与推理。
2023-12-25 11:29:01968 
训练好的ai模型导入cubemx不成功咋办,试了好几个模型压缩了也不行,ram占用过大,有无解决方案?
2023-08-04 09:16:28
就Edge Impulse的三大模型之一的分类模型进行浅析。针对于图像的分类识别模型,读者可参考OpenMv或树莓派等主流图像识别单片机系统的现有历程,容易上手,简单可靠。单击此处转到——星瞳科技OpenMv 所以接下来的分析主要是针对数据进行识别的分类模型。...
2021-12-20 06:51:26
),其中y取值1或-1(代表二分类的类别标签),这也是GBDT可以用来解决分类问题的原因。模型训练代码地址 https://github.com/qianshuang/ml-expdef train
2019-01-23 14:38:58
设备的不断增多,并发模型显得举足轻重,本期我们将为大家带来方舟编译器对传统Actor并发模型的轻量级优化。
一、什么是并发模型?在操作系统中,并发是任务在不影响最终执行结果的情况下无序或者按部分顺序
2022-07-18 12:00:53
会得到添加了高斯噪声的新图像。高斯噪声也称为白噪声,是一种服从正态分布的随机噪声。 在深度学习中,训练时往往会在输入数据中加入高斯噪声,以提高模型的鲁棒性和泛化能力。 这称为数据扩充。 通过向输入数据添加
2023-02-16 14:04:10
及优化器,从而给大家带来清晰的机器学习结构。通过本教程,希望能够给大家带来一个清晰的模型训练结构。当模型训练遇到问题时,需要通过可视化工具对数据、模型、损失等内容进行观察,分析并定位问题出在数据部分
2018-12-21 09:18:02
tf.lite.TFLiteConverter.from_concrete_functions(): # 由具体函数转化
2 TFLite格式分析
例如我们已经训练得到了一个tflite模型
2023-08-18 07:01:53
1、YOLOv6中的用Channel-wise Distillation进行的量化感知训练来自哪里 知识蒸馏 (KD)已被证明是一种用于训练紧凑密集预测模型的简单有效的工具。轻量级学生网络通过
2022-10-09 16:25:51
能否直接调用训练好的模型文件?
2021-06-22 14:51:03
:这种方法是在预训练模型的基础上,修改最后一层或几层,并且对整个网络进行微调训练。这种方法适用于新数据集和原数据集相似度较高,且新数据集规模较大的情况。
特征提取:这种方法是将预训练模型看作一个
2023-10-16 15:03:16
准备开始为家猫做模型训练检测,要去官网https://maix.sipeed.com/home 注册帐号,文章尾部的视频是官方的,与目前网站略有出路,说明训练网站的功能更新得很快。其实整个的过程
2022-06-26 21:19:40
多种形式和任务。这个阶段是从语言模型向对话模型转变的关键,其核心难点在于如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系及训练数据的规模。
奖励建模阶段的目标是构建一个文本
2024-03-11 15:16:39
OpenVINO安装完成后,需要提供项目的模型文件,才能进行参数调优和深度学习推理。所以需要进行数据收集,数据标注,进行模型训练。训练的模型很多,有Tensorflow、Caffee等,我选用
2020-07-15 23:29:12
用于训练模型,如下图所示:我选择的方式为上传本地图片的方式,选项选择如下:上传图片后,我们需要对图片进行标记,操作则需要点击下图所示的 查看与标注第四步:在创建数据集完成后,就是模型训练,我们进入模型
2021-03-23 14:32:35
(三)使用YOLOv3训练BDD100K数据集之开始训练
2020-05-12 13:38:55
我正在尝试使用自己的数据集训练人脸检测模型。此错误发生在训练开始期间。如何解决这一问题?
2023-04-17 08:04:49
医疗模型人训练系统是为满足广大医学生的需要而设计的。我国现代医疗模拟技术的发展处于刚刚起步阶段,大部分仿真系统产品都源于国外,虽然对于模拟人仿真已经出现一些产品,但那些产品只是就模拟人的某一部分,某一个功能实现的仿真,没有一个完整的系统综合其所有功能。
2019-08-19 08:32:45
问题最近在Ubuntu上使用Nvidia GPU训练模型的时候,没有问题,过一会再训练出现非常卡顿,使用nvidia-smi查看发现,显示GPU的风扇和电源报错:解决方案自动风扇控制在nvidia
2022-01-03 08:24:09
CV:基于Keras利用训练好的hdf5模型进行目标检测实现输出模型中的脸部表情或性别的gradcam(可视化)
2018-12-27 16:48:28
。
使用TensorFlow对经过训练的神经网络模型进行优化,步骤如下:
1.确定图中输入和输出节点的名称以及输入数据的维度。
2.使用TensorFlow的transform_graph工具生成优化的32位模型。
3.
2023-08-02 06:43:57
我正在尝试使用 eIQ 门户训练人脸检测模型。我正在尝试从 tensorflow 数据集 (tfds) 导入数据集,特别是 coco/2017 数据集。但是,我只想导入 wider_face。但是,当我尝试这样做时,会出现导入程序错误,如下图所示。任何帮助都可以。
2023-04-06 08:45:14
个人做数据可视化就算了,但凡上升到部门级的、企业级的,都少不了搭建数据分析模型,但数据分析模型不是那么好搭建的,经验不足、考虑不周都将影响到后续的数据可视化分析。有些企业用户就是在搭建分析模型时没做
2022-05-17 10:03:14
PyTorch Hub 加载预训练的 YOLOv5s 模型,model并传递图像进行推理。'yolov5s'是最轻最快的 YOLOv5 型号。有关所有可用模型的详细信息,请参阅自述文件。详细示例此示例
2022-07-22 16:02:42
怎样去开发一种Echarts消防训练成绩大数据可视化综合分析系统?如何去编写其代码?
2021-08-31 07:06:59
问题:如何用单个GPU在不到24小时的时间内从零开始训练ViT模型。作者认为,由于多种原因,这一方向的进展可能会对计算机视觉研究和应用的未来产生重大影响。1 加快模型开发。ML中的新模型通常通过运行和分析
2022-11-24 14:56:31
深度融合模型的特点,背景深度学习模型在训练完成之后,部署并应用在生产环境的这一步至关重要,毕竟训练出来的模型不能只接受一些公开数据集和榜单的检验,还需要在真正的业务场景下创造价值,不能只是为了PR而
2021-07-16 06:08:20
tensorflow模型部署系列的一部分,用于tflite实现通用模型的部署。本文主要使用pb格式的模型文件,其它格式的模型文件请先进行格式转换,参考tensorflow模型部署系列————预训练模型导出。从...
2021-12-22 06:51:18
),其中y取值1或-1(代表二分类的类别标签),这也是GBDT可以用来解决分类问题的原因。模型训练代码地址 https://github.com/qianshuang/ml-expdef train
2019-01-25 15:02:15
目前官方的线上模型训练只支持K210,请问K510什么时候可以支持
2023-09-13 06:12:13
我在matlab中训练好了一个神经网络模型,想在labview中调用,请问应该怎么做呢?或者labview有自己的神经网络工具包吗?
2018-07-05 17:32:32
个领先的 NLP 模型。它通过分析去掉一个单词的句子(或“屏蔽词”),并猜测屏蔽词是什么,来进行推断。例如,如果你要使用一个预先训练好的 RoBERTa 模型来猜测一个句子中的下一个单词,你要使
2022-11-01 15:25:02
一、前言前面结合神经网络简要介绍TensorFlow相关概念,并给出了MNIST手写数字识别的简单示例,可以得出结论是,构建的神经网络目的就是利用已有的样本数据训练网络的权重和偏置,使神经网络最终
2020-11-04 07:49:09
通过一个基于操作规程的虚拟训练系统研究了系统仿真流程,分析了有限状态机(FSM)的原理,结合虚拟仿真训练的特点,设计出了操作过程模型,并通过Windows 消息机制编程实
2009-12-07 14:23:01 14
14 ,需尽可能选择与目标项目更相似的数据用于模型的训练。利用PROMISE提供的34个公开数据集,从训练数据选择方面,分析了四种典型的相似性度量方法对跨项目预测结果的影响以及各种方法之间的差异。研究结果表明:使用不同的相似性度量
2017-12-09 11:39:530 深度学习模型和数据集的规模增长速度已经让 GPU 算力也开始捉襟见肘,如果你的 GPU 连一个样本都容不下,你要如何训练大批量模型?通过本文介绍的方法,我们可以在训练批量甚至单个训练样本大于 GPU
2018-12-03 17:24:01668 正如我们在本文中所述,ULMFiT使用新颖的NLP技术取得了令人瞩目的成果。该方法对预训练语言模型进行微调,将其在WikiText-103数据集(维基百科的长期依赖语言建模数据集Wikitext之一)上训练,从而得到新数据集,通过这种方式使其不会忘记之前学过的内容。
2019-04-04 11:26:2623192 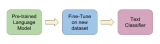
除此模型之外,本研究还尝试了几种其他的模型结构,一是移除教师 - 学生模型并使用自训练模型,二是在进行模型微调时使用推断出的标签作为训练数据。在实验分析部分,作者讨论了几个影响模型性能的敏感因素
2019-05-08 09:47:453377 自然图像领域中存在着许多海量数据集,如ImageNet,MSCOCO。基于这些数据集产生的预训练模型推动了分类、检测、分割等应用的进步。
2019-08-20 15:03:161871 生成的数据生成准确的预测。这些新数据示例可能是用户交互、应用处理或其他软件系统的请求生成的——这取决于模型需要解决的问题。在理想情况下,我们会希望自己的模型在生产环境中进行预测时,能够像使用训练过程中使用
2020-04-10 08:00:000 成功训练计算机视觉任务的深层卷积神经网络需要大量数据。这是因为这些神经网络具有多个隐藏的处理层,并且随着层数的增加,需要学习的样本数也随之增加。如果没有足够的训练数据,则该模型往往会很好地学习训练数据,这称为过度拟合。如果模型过拟合,则其泛化能力很差,因此对未见的数据的表现很差。
2020-05-04 08:59:002727 在这篇文章中,我会介绍一篇最新的预训练语言模型的论文,出自MASS的同一作者。这篇文章的亮点是:将两种经典的预训练语言模型(MaskedLanguage Model, Permuted
2020-11-02 15:09:362334 训练方法不仅能够在BERT上有提高,而且在RoBERTa这种已经预训练好的模型上也能有所提高,说明对抗训练的确可以帮助模型纠正易错点。 方法:ALUM(大型神经语言模型的对抗
2020-11-02 15:26:491802 
导读:预训练模型在NLP大放异彩,并开启了预训练-微调的NLP范式时代。由于工业领域相关业务的复杂性,以及工业应用对推理性能的要求,大规模预训练模型往往不能简单直接地被应用于NLP业务中。本文将为
2020-12-31 10:17:112217 
。这些大模型的出现让普通研究者越发绝望:没有「钞能力」、没有一大堆 GPU 就做不了 AI 研究了吗? 在此背景下,部分研究者开始思考:如何让这些大模型的训练变得更加接地气?也就是说,怎么用更少的卡训练更大的模型? 为了解决这个问题,来自微软、加州大学默塞德分校的研究
2021-02-11 09:04:002167 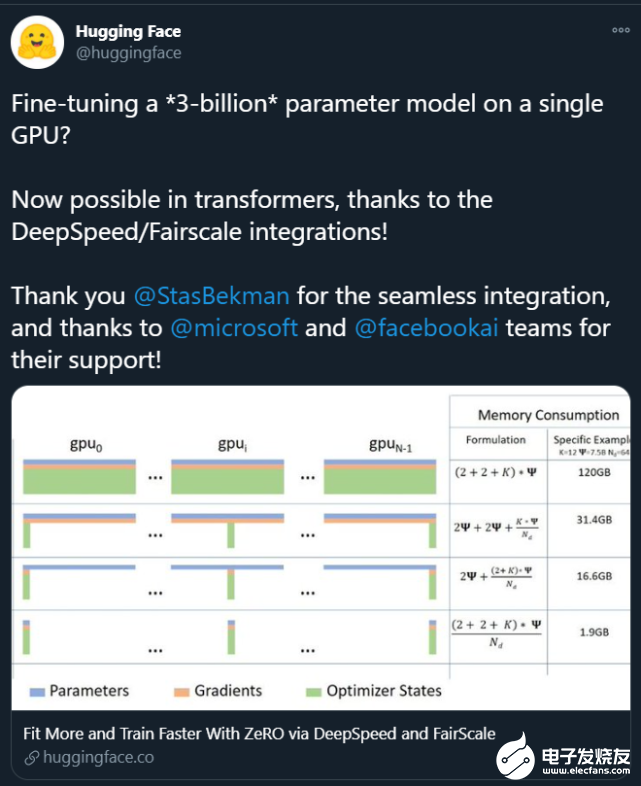
Pre-training of Knowledge Graph and Language Understanding)。该论文提出了知识图谱和文本的联合训练框架,通过将RoBERTa作为语言模型将上下文编码信息传递给知识
2021-03-29 17:06:103778 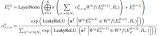
为提高卷积神经网络目标检测模型精度并增强检测器对小目标的检测能力,提出一种脱离预训练的多尺度目标检测网络模型。采用脱离预训练检测网络使其达到甚至超过预训练模型的精度,针对小目标特点
2021-04-02 11:35:5026 作为模型的初始化词向量。但是,随机词向量存在不具备语乂和语法信息的缺点;预训练词向量存在¨一词-乂”的缺点,无法为模型提供具备上下文依赖的词向量。针对该问题,提岀了一种基于预训练模型BERT和长短期记忆网络的深度学习
2021-04-20 14:29:0619 本文关注于向大规模预训练语言模型(如RoBERTa、BERT等)中融入知识。
2021-06-23 15:07:313468 
做企业级数据分析的,没个分析模型可不行,因此很多企业在做数据分析时都要投入大量的成本去搭建数据分析模型,但由于没有经验累积往往要走很多的弯路,付出大量试错成本。难道就没有别的办法降低风险和成本?有,那就是选择有现成数据分析模型的数据可视化软件。
2021-09-30 16:57:22378 在某一方面的智能程度。具体来说是,领域专家人工构造标准数据集,然后在其上训练及评价相关模型及方法。但由于相关技术的限制,要想获得效果更好、能力更强的模型,往往需要在大量的有标注的数据上进行训练。 近期预训练模型的
2021-09-06 10:06:533351 
大模型的预训练计算。 大模型是大势所趋 近年来,NLP 模型的发展十分迅速,模型的大小每年以1-2个数量级的速度在提升,背后的推动力当然是大模型可以带来更强大更精准的语言语义理解和推理能力。 截止到去年,OpenAI发布的GPT-3模型达到了175B的大小,相比2018年94M的ELMo模型,三年的时间整整增大了
2021-10-11 16:46:052226 
NVIDIA Megatron 是一个基于 PyTorch 的框架,用于训练基于 Transformer 架构的巨型语言模型。本系列文章将详细介绍Megatron的设计和实践,探索这一框架如何助力
2021-10-20 09:25:432078 2021 OPPO开发者大会:NLP预训练大模型 2021 OPPO开发者大会上介绍了融合知识的NLP预训练大模型。 责任编辑:haq
2021-10-27 14:18:411492 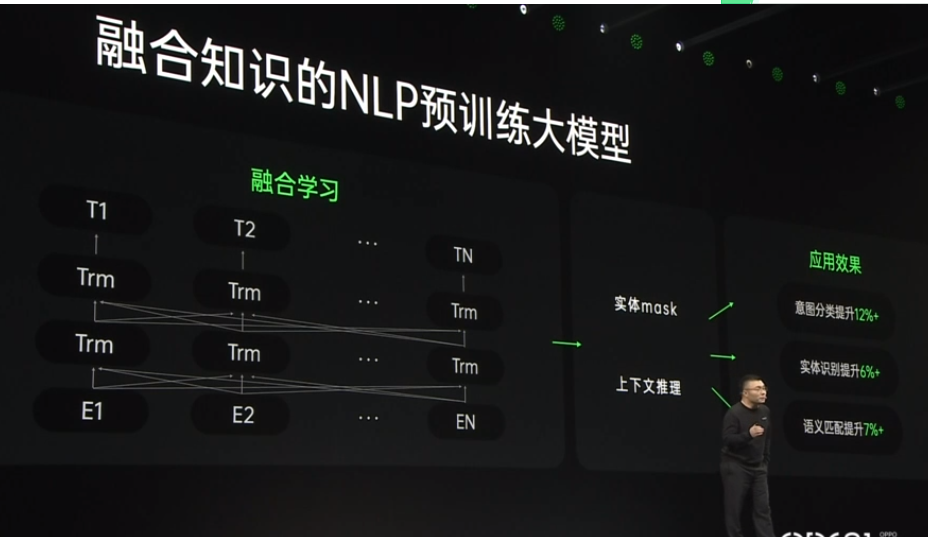
NLP中,预训练大模型Finetune是一种非常常见的解决问题的范式。利用在海量文本上预训练得到的Bert、GPT等模型,在下游不同任务上分别进行finetune,得到下游任务的模型。然而,这种方式
2022-03-21 15:33:301843 “强悍的织女模型在京东探索研究院建设的全国首个基于 DGX SuperPOD 架构的超大规模计算集群 “天琴α” 上完成训练,该集群具有全球领先的大规模分布式并行训练技术,其近似线性加速比的数据、模型、流水线并行技术持续助力织女模型的高效训练。”
2022-04-13 15:13:11783 今天给大家介绍的,就是这样一套不仅拥有上述能力,还直接提供目标检测、属性分析、关键点检测、行为识别、ReID等产业级预训练模型的实时行人分析工具PP-Human,方便开发者灵活取用及更改!
2022-04-20 10:16:481691 由于乱序语言模型不使用[MASK]标记,减轻了预训练任务与微调任务之间的gap,并由于预测空间大小为输入序列长度,使得计算效率高于掩码语言模型。PERT模型结构与BERT模型一致,因此在下游预训练时,不需要修改原始BERT模型的任何代码与脚本。
2022-05-10 15:01:271173 为了减轻上述问题,提出了NoisyTune方法,即,在finetune前加入给预训练模型的参数增加少量噪音,给原始模型增加一些扰动,从而提高预训练语言模型在下游任务的效果,如下图所示,
2022-06-07 09:57:321972 本文对任务低维本征子空间的探索是基于 prompt tuning, 而不是fine-tuning。原因是预训练模型的参数实在是太多了,很难找到这么多参数的低维本征子空间。作者基于之前的工作提出
2022-07-08 11:28:24935 在中国图象图形大会的华为昇思MindSpore技术论坛上,中国科学院空天信息创新研究院(以下简称“空天院”)发布了首个面向跨模态遥感数据的生成式预训练大模型“空天.灵眸”(RingMo,Remote Sensing Foundation Model)。
2022-08-23 09:38:141251 电子发烧友网报道(文/李弯弯)在深度学习中,经常听到一个词“模型训练”,但是模型是什么?又是怎么训练的?在人工智能中,面对大量的数据,要在杂乱无章的内容中,准确、容易地识别,输出需要的图像/语音
2022-10-23 00:20:037253 这些模型针对特定数据集进行了训练,并经过准确性和处理速度的验证。在部署之前,开发人员需要评估 ML 模型,并确保其满足特定的阈值并按预期运行。有很多实验可以提高模型性能,在设计和训练模型时,可视化
2022-10-24 15:53:14471 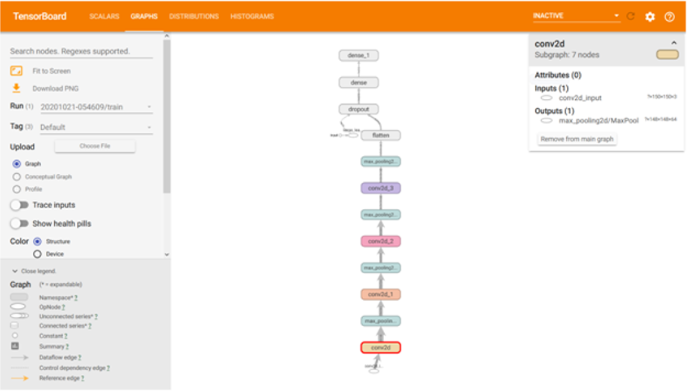
随着BERT、GPT等预训练模型取得成功,预训-微调范式已经被运用在自然语言处理、计算机视觉、多模态语言模型等多种场景,越来越多的预训练模型取得了优异的效果。
2022-11-08 09:57:193714 这些模型针对特定数据集进行了训练,并经过了准确性和处理速度的证明。开发人员需要评估 ML 模型,并确保它在部署之前满足预期的特定阈值和功能。有很多实验可以提高模型性能,在设计和训练模型时,可视化
2022-11-22 16:30:51334 可以访问预训练模型的完整源代码和模型权重。 该工具套件能够高效训练视觉和对话式 AI 模型。由于简化了复杂的 AI 模型和深度学习框架,即便是不具备 AI 专业知识的开发者也可以使用该工具套件来构建 AI 模型。通过迁移学习,开发者可以使用自己的数据对 NVIDIA 预训练模型进行微调,
2022-12-15 19:40:06722 在应用程序开发周期中,第一步是准备和预处理可用数据以创建训练和验证/测试数据集。除了通常的数据预处理外,在MAX78000上运行模型还需要考虑几个硬件限制。
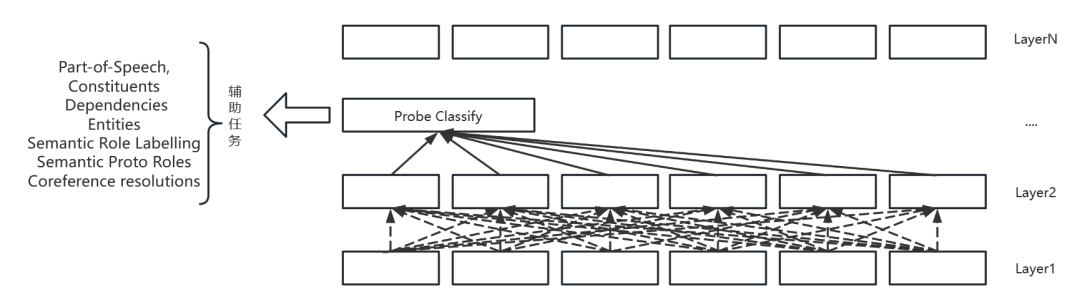
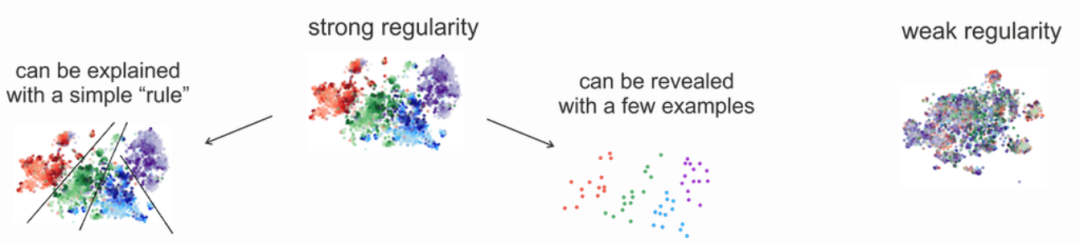
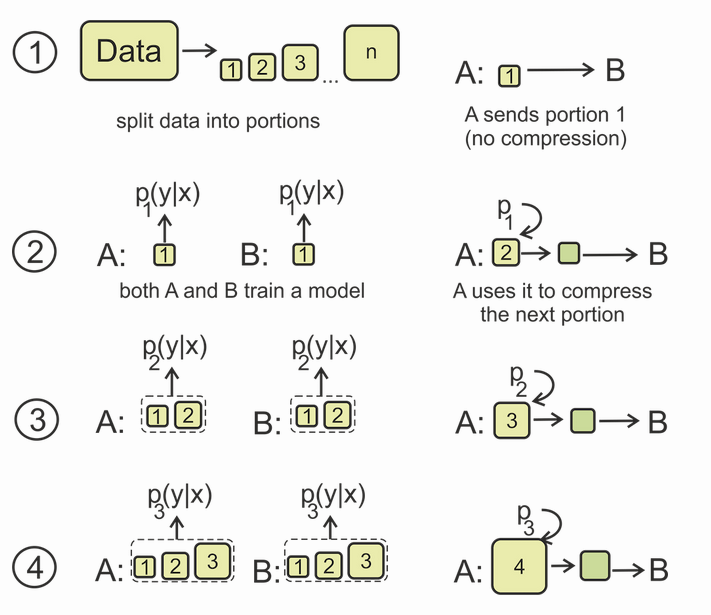
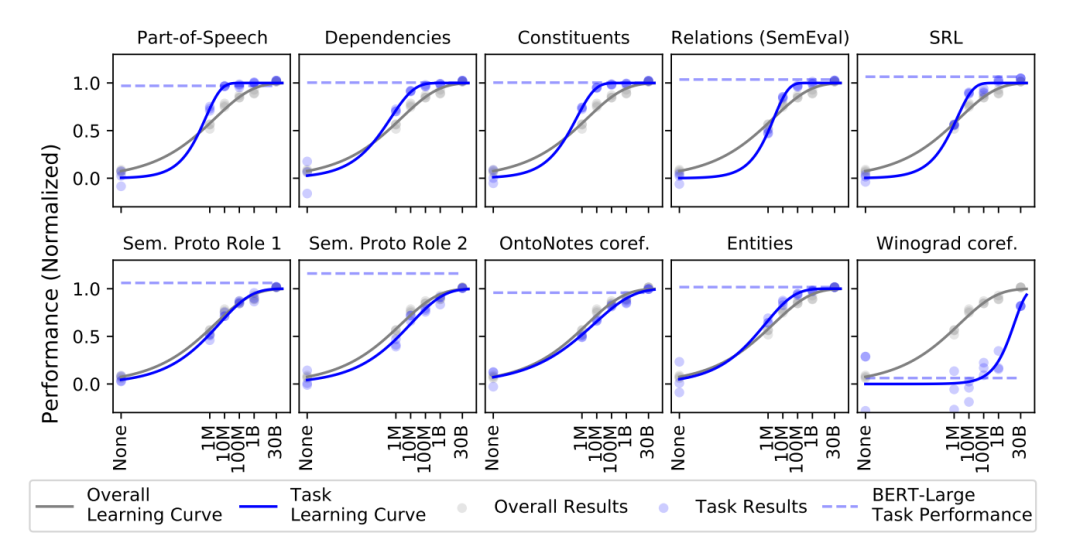
2023-02-21 12:11:44903 BERT类模型的工作模式简单,但取得的效果也是极佳的,其在各项任务上的良好表现主要得益于其在大量无监督文本上学习到的文本表征能力。那么如何从语言学的特征角度来衡量一个预训练模型的究竟学习到了什么样的语言学文本知识呢?
2023-03-03 11:20:00911 你想知道的,都在这里!本文是神策数据「十问十答」科普系列文章的第一期,围绕数据分析模型展开。 1 Q:常用的数据分析模型有哪些? A:神策数据总结了企业常用的数据分析模型,包括:事件分析、漏斗分析
2023-03-17 11:35:21343 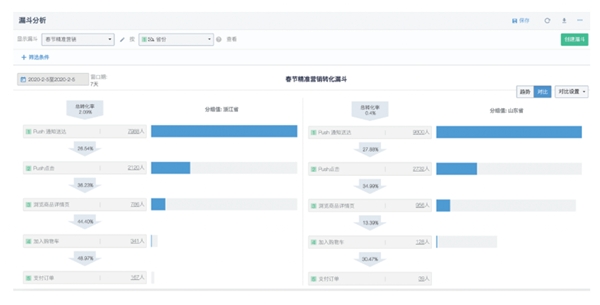
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。 如果要教一个刚学会走路的孩子什么是独角兽,那么我们首先应
2023-04-04 01:45:021025 作为深度学习领域的 “github”,HuggingFace 已经共享了超过 100,000 个预训练模型
2023-05-19 15:57:43494 
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。
2023-05-25 17:10:09595 vivo AI 团队与 NVIDIA 团队合作,通过算子优化,提升 vivo 文本预训练大模型的训练速度。在实际应用中, 训练提速 60% ,满足了下游业务应用对模型训练速度的要求。通过
2023-05-26 07:15:03422 
实验室在 SageMaker Studio Lab 中打开笔记本
为了预训练第 15.8 节中实现的 BERT 模型,我们需要以理想的格式生成数据集,以促进两项预训练任务:掩码语言建模和下一句预测
2023-06-05 15:44:40442 前文说过,用Megatron做分布式训练的开源大模型有很多,我们选用的是THUDM开源的CodeGeeX(代码生成式大模型,类比于openAI Codex)。选用它的原因是“完全开源”与“清晰的模型架构和预训练配置图”,能帮助我们高效阅读源码。我们再来回顾下这两张图。
2023-06-07 15:08:242186 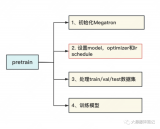
在一些非自然图像中要比传统模型表现更好 CoOp 增加一些 prompt 会让模型能力进一步提升 怎么让能力更好?可以引入其他知识,即其他的预训练模型,包括大语言模型、多模态模型 也包括
2023-06-15 16:36:11277 
,一定要经历以下几个步骤: 模型选择(Model Selection) :选择适合任务和数据的模型结构和类型。 数据收集和准备(Data Collection and Preparation) :收集并准备用于训练和评估的数据集,确保其适用于所选模型。 无监督预训练(Pretraining) :
2023-06-21 19:55:02313 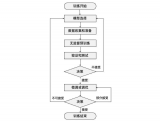
大型语言模型如 ChatGPT 的成功彰显了海量数据在捕捉语言模式和知识方面的巨大潜力,这也推动了基于大量数据的视觉模型研究。在计算视觉领域,标注数据通常难以获取,自监督学习成为预训练的主流方法
2023-07-24 16:55:03272 
模型训练是将模型结构和模型参数相结合,通过样本数据的学习训练模型,使得模型可以对新的样本数据进行准确的预测和分类。本文将详细介绍 CNN 模型训练的步骤。 CNN 模型结构 卷积神经网络的输入
2023-08-21 16:42:00885 数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次(Batch)维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。
2023-08-24 15:17:28537 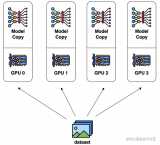
生成式AI和大语言模型(LLM)正在以难以置信的方式吸引全世界的目光,本文简要介绍了大语言模型,训练这些模型带来的硬件挑战,以及GPU和网络行业如何针对训练的工作负载不断优化硬件。
2023-09-01 17:14:561046 
model 训练完成后,使用 instruction 以及其他高质量的私域数据集来提升 LLM 在特定领域的性能;而 rlhf 是 openAI 用来让model 对齐人类价值观的一种强大技术;pre-training dataset 是大模型在训练时真正喂给 model 的数据,从很多 paper 能看到一些观
2023-09-19 10:00:06506 
NVIDIA Megatron 是一个基于 PyTorch 的分布式训练框架,用来训练超大Transformer语言模型,其通过综合应用了数据并行,Tensor并行和Pipeline并行来复现 GPT3,值得我们深入分析其背后机理。
2023-10-23 11:01:33826 
如果我们使用的 数据集较大 ,且 网络较深 ,则会造成 训练较慢 ,此时我们要 想加速训练 可以使用 Pytorch的AMP ( autocast与Gradscaler );本文便是依据此写出
2023-11-03 10:00:191054 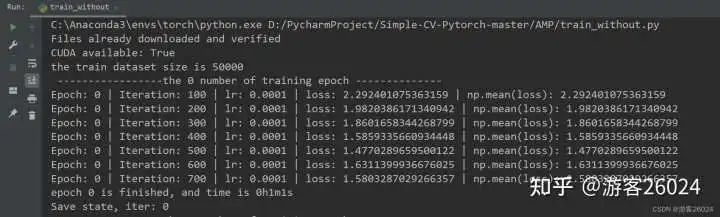
算法工程、数据派THU深度学习在近年来得到了广泛的应用,从图像识别、语音识别到自然语言处理等领域都有了卓越的表现。但是,要训练出一个高效准确的深度学习模型并不容易。不仅需要有高质量的数据、合适的模型
2023-12-07 12:38:24547 
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个自定义的圆检测与圆心定位预测模型
2023-12-21 10:50:05529 
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个工件切割分离点预测模型
2023-12-22 11:07:46259 
谷歌模型训练软件主要是指ELECTRA,这是一种新的预训练方法,源自谷歌AI。ELECTRA不仅拥有BERT的优势,而且在效率上更胜一筹。
2024-02-29 17:37:39337 谷歌在模型训练方面提供了一些强大的软件工具和平台。以下是几个常用的谷歌模型训练软件及其特点。
2024-03-01 16:24:01184 在近日举办的百度智能云千帆产品发布会上,三款全新的轻量级大模型——ERNIE Speed、ERNIE Lite以及ERNIE Tiny,引起了业界的广泛关注。相较于传统的千亿级别参数大模型,这些轻量级大模型在参数量上有了显著减少,为客户提供了更加灵活和经济高效的解决方案。
2024-03-22 10:28:3497
正在加载...
 电子发烧友App
电子发烧友App


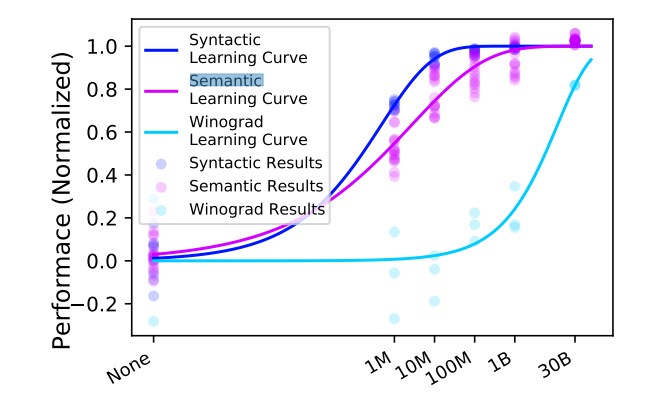
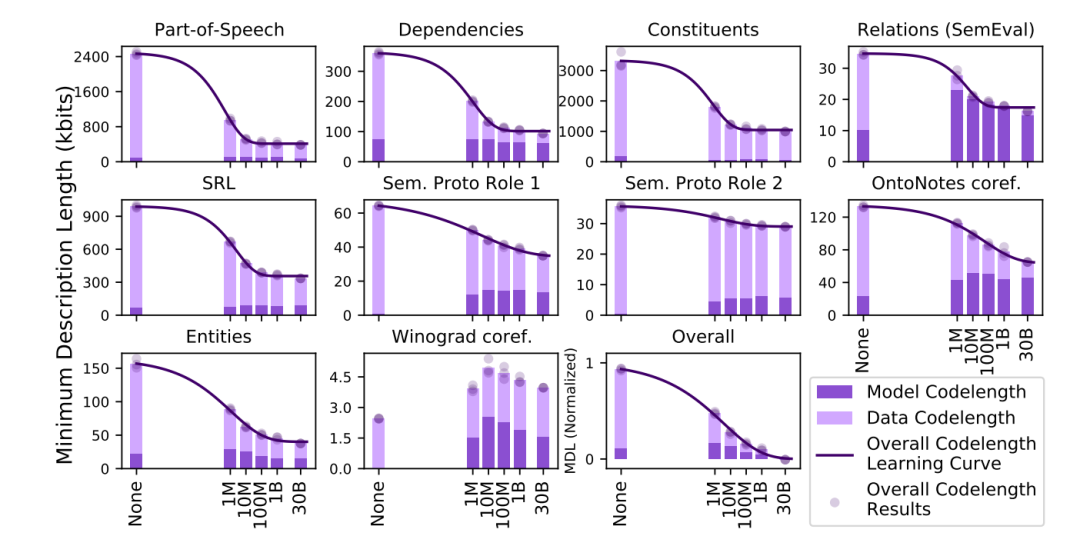
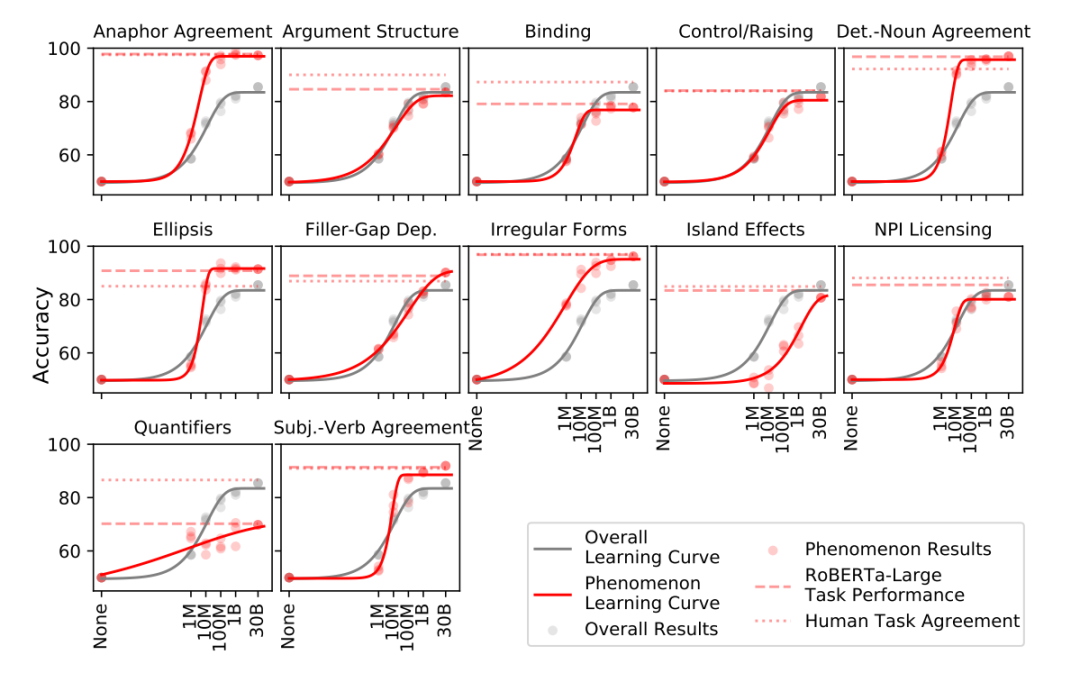
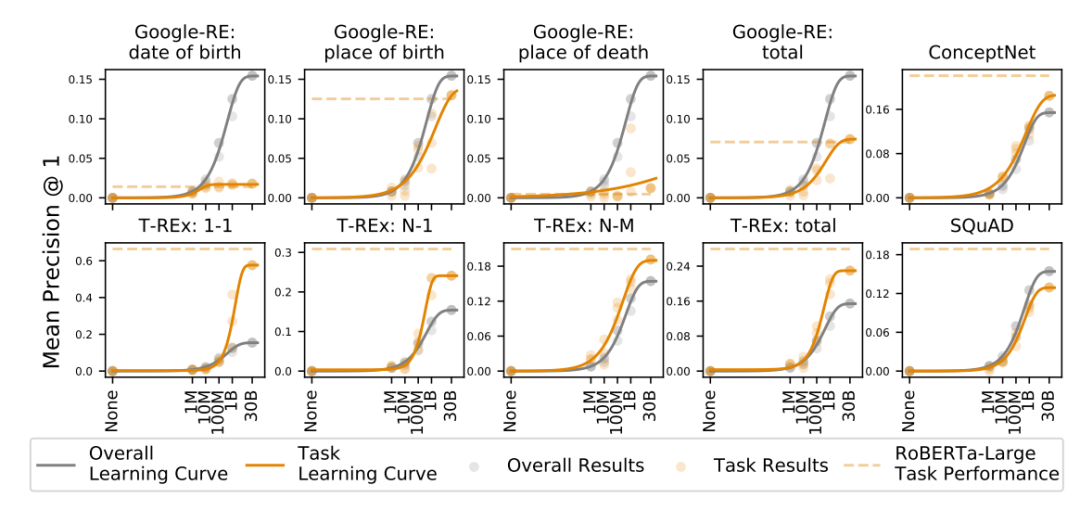







 工商网监
工商网监
评论