 电子发烧友App
电子发烧友App


一、GPT-4正式发布,多模态能力带来更多应用想象
1.1、OpenAI发布GPT-4,能力全面升级
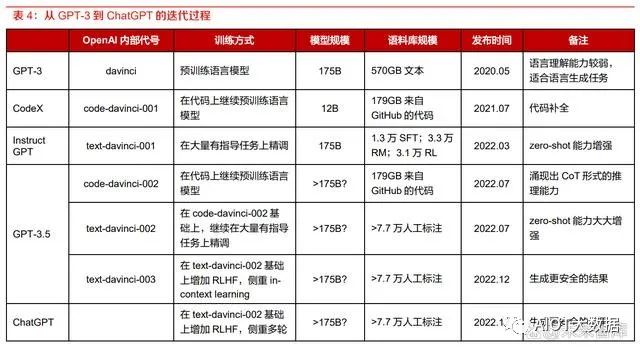
GPT-4 正式发布,性能全面升级。2023 年 3 月 15 日凌晨,OpenAI 正式发布了 GPT-4 预训练大 模型,相比于 GPT-3.5 模型进行了全方位的升级。实际上在半年前 OpenAI 就已经完成了 GPT-4 的模型,随后又采用对抗性测试对 GPT-4 进行了 6 个月的迭代调整,保证其在真实性、可操作性 和安全方面达到最好。GPT-4 仍为 Transformer 架构的预训练模型,与 ChatGPT 类似,同样采用 了基于人类反馈的强化学习(RLHF)方法,在一些专业和学术领域上已经达到了人类水平,是 OpenAI 在人工智能领域的又一里程碑。
GPT-4 相比 GPT-3.5 具有四方面的能力提升:1) GPT-4 具有一定的多模态能力,能够进行图文结合输入的分析。GPT-4 是一个多模态模型, 它能够接受图片和文本输入,并输出文本回复,相比 GPT-3.5 增加了对图像模态的分析推理 能力。与业界之前的预测不同,GPT-4 并不具备多模态的生成能力,即无法从文本输入中得 到图片(类似于 DALL-E),只能对图片的输入进行分析,并且图片输入目前仍处于研究预 览阶段,还未对公众开放。根据 OpenAI 显示,GPT-4 对图片的处理分析能力达到了很高的 水准,这相当于机器拥有了视觉并且能够进行思考,在应用层面有非常广的空间。比如,完 全可以成为视力障碍人群的眼睛,给出题目的图片能够直接进行解题步骤的输出等,在教育 领域有广泛的落地场景。
2) GPT-4 在复杂专业领域的性能表现大幅超过 GPT-3.5 和当下的 SOTA 大模型。据 OpenAI 显示,GPT-4 和 GPT-3.5 在一些普通的谈话测试中的性能区别不大,但是在处理较为复杂 和专业的任务上,GPT-4 相比 GPT-3.5 则表现更优。在美国律师资格考试测试中,GPT-4 的成绩可以达到前 10%,而 GPT-3.5 只能达到后 10%的水平。与 SOTA 模型(state-of-theart model,目前最好的模型)相比,GPT-4 也展现出了更好的性能。
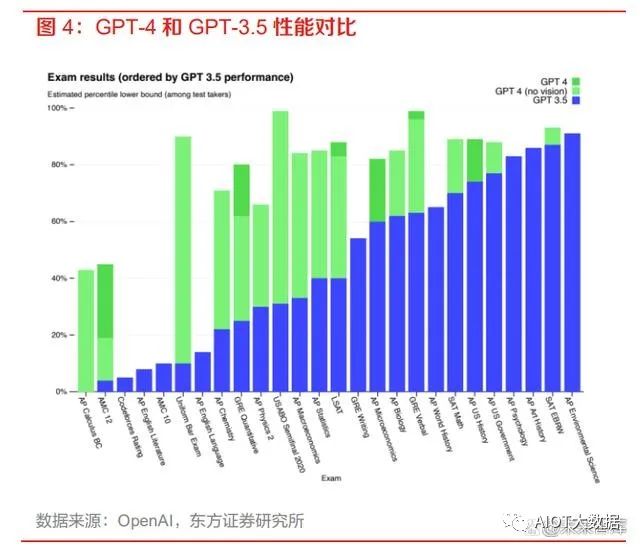
3) GPT-4 能够处理更长的文本,具有更好的创作能力和逻辑推理能力。ChatGPT 处理的文本 字数上限为 3000 字,而 GPT-4 可以处理超过 25000 字的长文本,支持内容创作、对话拓展 和文档分析等功能。在创造性方面,GPT-4 可以辅助用户进行生成、处理和迭代创意工作, 例如创作歌曲、编写剧本或学习用户的写作风格。与 ChatGPT 相比,GPT-4 的逻辑推理能 力更进一步,在复杂的推理问题中表现更佳。4) GPT-4 支持用户自定义 AI 的对话风格。在 OpenAI 的开发者直播中可以初步窥视 GPT-4 的 页面布局,用户可以左侧的 System 栏中输入命令来定义 GPT-4 的交互对话风格,而不是像 ChatGPT 一样只有一种风格。我们认为,自定义 AI 对话风格对于基于 GPT-4 的二次开发应 用来说是非常方便的,开发者可以轻松地创造出具有个人独特风格的 AI 应用。
GPT-4 已开放给 ChatGPT Plus 用户使用,并且开放了 GPT-4 API 使用申请,使用成本大幅提 升。据 OpenAI 显示,目前仅有 ChatGPT Plus 的订阅会员用户能够访问 GPT-4,但存在容量上 限,OpenAI 会对此进行持续扩展和优化,未来可能会推出免费的 GPT-4 试用版和更高级的订阅 版本以供用户获得更多的使用容量。OpenAI 同时开放了 GPT-4 API 的使用申请,开发者可以申 请进入 GPT-4 API 的等待列表,OpenAI 会逐步邀请开发人员开始试用 API。目前提供给开发者 的 API 只能进行文本的输入,分为 8k 和 32k token 两个版本,最便宜的 8k-prompt 版本的定价为 0.03 美元/1k tokens,相比于之前发布的 GPT-3.5-turbo 的 0.002 美元/1k tokens 要贵十倍以上。
1.2、GPT-4有望带来多场景智能化升级
GPT-4 已在多领域落地,微软官宣证实 New Bing 背后的大模型就是 GPT-4。伴随着 GPT-4 的 发布,OpenAI 也给出了 GPT-4 的 6 个应用实例,涵盖了教育、金融和政府领域。例如在 Duolingo 里加入 AI 与用户进行日常聊天,加速用户对语言的学习;摩根士丹利采用 GPT-4 来对 其知识库进行管理,帮助员工快速访问想要的内容。微软也在 GPT-4 发布后官宣,New Bing 背 后的模型就是 GPT-4,并且将随着 GPT-4 的更新持续迭代。我们在之前的报告中已多次提到,大 模型的能力将对产业智能化带来重大影响。随着 GPT-4 的发布以及性能飞跃,大模型在各领域有 望迎来进一步的落地应用。考虑到其对话交互的特性,我们看好 GPT-4 在如下几个领域的应用。
1) 教育场景:GPT-4的自定义AI风格能力与其连续对话交互能力与教育场景十分契合,对不 同性格的学生采用不同风格的AI作为虚拟导师,回答学生的问题、提供个性化的学习建议 和教育资源、分析学生的学习进展等,达成对学生进行个性化教育的目标,使得每个学生都 能以最大化的效率进行学习。此外GPT-4还能作为教师的辅助教学工具,帮助教师更好地 管理教学过程和学生。例如,教师可以使用 AI 来分析学生的学习数据,针对不同的学生制 定更加个性化的教学计划和评估学生的学习成果。GPT-4的图片分析能力还能够辅助教学过 程中的阅卷工作,实现对主观题的评分,减轻教师工作负担,提高阅卷的公正性与准确性。
2) 医疗场景:GPT-4 丰富的专业知识使其能够做好辅助诊断的工作,通过分析医疗记录、病历 资料、诊断报告等数据,提供有关疾病诊断、治疗方案和药物处方等方面的建议和指导,帮 助医生更加准确地诊断和治疗疾病,提高医疗质量和治疗效果。在医学影像领域,GPT-4 新 增的图片分析能力也可以用于CT等图像的诊断,智能标记出存在症状的图像区域。将GPT4 与可穿戴设备结合,可实现对重症患者的全天候健康监测,进行实时健康风险评估,帮助 患者做好健康管理等。
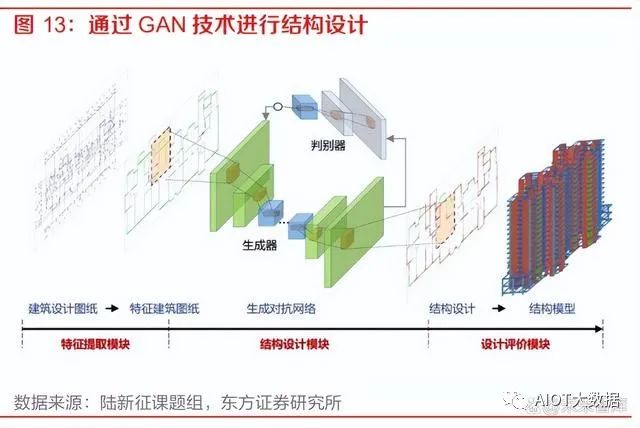
3) 企业经营管理办公场景:GPT-4 的对话交互特性与逻辑分析能力可以助力企业经营管理办公 全流程的效率提升。在企业的 OA 系统中,GPT-4 可以辅助员工快速智能地进行流程办理;在企业 ERP 系统中,GPT-4 可以通过数据分析来辅助企业进行经营决策;在办公环节, GPT-4 的长文本理解能力有望对会议、文档和邮箱场景带来效率提升。4) 工业设计场景:GPT-4 在复杂专业领域的性能以及其多模态分析能力可以成为良好的工业设 计辅助工具。例如在 CAD、CAE、EDA 等工业设计软件领域,GPT-4 可以作为其中的插件 来进行模型的辅助设计、图纸生成等。清华大学土木工程系的陆新征课题组已经将生成对抗 网络技术应用到了结构设计中,能够自动为剪力墙进行配筋,结果基本和普通的结构设计软 件给出的配筋结果一致。能力更强的大模型在这方面的应用更加值得期待。
二、百度发布会召开,文心生态圈持续扩大
2.1、“文心一言”正式发布,具备多模态能力
百度的对话式大模型“文心一言”正式发布。3 月 16 日下午,百度 CEO 李彦宏在发布会上正式 揭开了“文心一言”的面纱。“文心一言”是百度新一代知识增强大语言模型,它基于百度 ERNIE 及 PLATO 系列模型的基础进行研发,其大模型的训练数据包括万亿级网页数据、数十亿的搜索数据和图片数据、百亿级的语音日均调用数据,以及5500亿事实的知识图谱等。李彦宏表 示,虽然“文心一言”的实际能力还并不完美,但希望通过发布后的真实用户反馈来帮助大模型 快速迭代,加速模型能力的提升。
“文心一言”具备五大能力:1) 文学创作:发布会现场以《三体》为例,“文心一言”能够对《三体》进行续写,并能回答 事实相关问题,体现出了强大的总结分析与推理能力。2) 商业文案创作:“文心一言”能够为公司起名提供创意,并能直接进行商业新闻稿的创作, 展现了模型的理解表达与创作能力。3) 数理逻辑推算:“文心一言”能够看出题目本身存在的错误,并能给出正确题目的解题步骤, 具备较强的数理逻辑能力。4) 中文理解:“文心一言”基于大量中文语料进行训练,能够解释“洛阳纸贵”背后的经济学 原理,并能写出藏头诗,展现了对中文的强大理解能力。5) 多模态生成能力:“文心一言”可以输入文字生成图像、音频和视频,并支持多种方言生成。文字生成视频的能力现阶段还未对外开放,但百度旗下的百家号已经在使用这项技术。
“文心一言”的多模态生成能力亮眼,多模态是未来大模型的发展趋势。从“文心一言”现场演 示的几大功能来看,最为亮眼的当属其多模态的生成能力,能够支持图像、音频和视频多种模态 内容的生成,而 OpenAI 的 GPT-4 目前还没有多模态的生成能力,在应用领域将会有更广阔的的 空间。我们认为,多模态是未来 AI 大模型的发展趋势,随着百度多模态统一大模型的能力增强, “文心一言”的多模态生成能力也会不断提升。
“文心一言”是新一代知识增强大语言模型,具有六大核心基础模块。百度 CTO 王海峰提到, “文心一言”与别的大语言模型相比,除了有监督精调(Supervised Fine-Tune)、人类反馈的 强化学习(RLHF)、提示(Prompt)这三项大模型均会采用的基础训练模块外,增加了三项具 有百度特色的核心基础模块:知识增强、检索增强、对话增强,充分利用了百度旗下的百度知识 图谱和百度搜索引擎等产品的能力。
1) 知识增强:“文心一言”的知识增强主要是通过知识内化和知识外用两种方式。知识内化是 从大规模知识和无标注数据中,基于语义单元学习,利用知识构造训练数据,将知识学习到 模型参数中;知识外用,是引入外部多源异构知识,做知识推理、提示构建等等。2) 检索增强:“文心一言”的检索增强,来自以语义理解与语义匹配为核心技术的新一代搜索 架构。通过引入搜索结果,可以为大模型提供时效性强、准确率高的参考信息,更好地满足 用户需求。3) 对话增强:基于对话技术和应用积累,“文心一言”具备记忆机制、上下文理解和对话规划 能力,实现更好的对话连贯性、合理性和逻辑性。
2.2、文心生态圈持续扩大,大模型带来新的产业机会
“文心一言”生态圈已加入650家企业,落地场景涵盖各行各业。李彦宏在发布会上宣布,已有 650 家企业首批接入了“文心一言”,涵盖了互联网、媒体、金融、保险、汽车、企业软件等行 业,百度大模型在 B端的生态圈迅速扩大。我们认为,随着“文心一言”的首批生态企业应用逐 步落地,百度将建立起开发者及用户调用和模型迭代之间的飞轮,加速构建开放繁荣的技术生态, 在推动公司增长的同时,也对中国生成式 AI 的发展带来了巨大的促进作用。
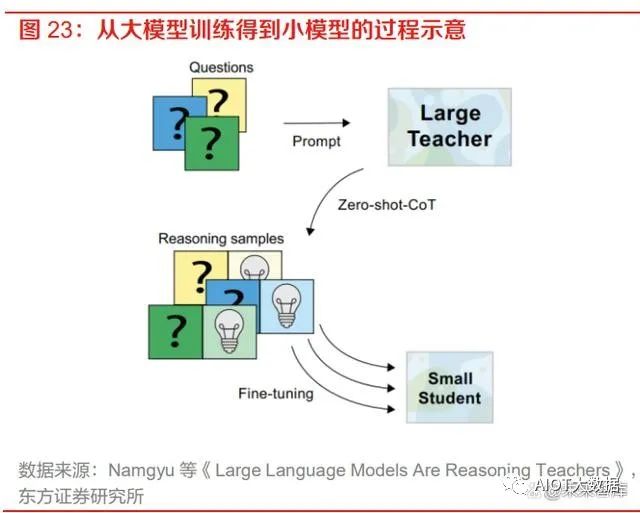
“文心一言”将在 3 月 27 日正式开放,大模型的发展将带来三大产业机会。“文心一言”目前 仍处于邀请制内测阶段,百度智能云官方宣布将于 3 月 27 日召开发布会,届时“文心一言”将正 式向大众开放。李彦宏在“文心一言”发布会上预测,大模型的发展有望带来三大产业机会:新型云计算、行业模型精调和应用开发。我们在之前的报告《文心一言发布在即,大模型有望引领 产业智能化变革》也有展望过,MaaS 未来将有望成为大模型落地的新形态,通过模型蒸馏技术 将大模型“瘦身”成为垂直行业模型,能够大大降低模型搭建的成本。我们认为,随着“文心一 言”的发布,基于大模型的垂直场景化模型以及基于垂直模型的应用开发将会快速增加,AI 市场 有望迎来需求的大幅增长。
百度具有人工智能全栈布局,长期的技术积累和生态优势助力百度成为国内对话式大模型先行者。基于搜索引擎这一天然的自然语言理解与处理的入口,百度从诞生开始就逐渐在NLP、语义理解方面进行持续的技术积累。过去数十年,百度深耕人工智能领域,目前已经拥有芯片、框架、模型和应用四层技术栈,文心大模型自2019年推出以来也历经了多次迭代,目前已经具备较强的泛化能力与性能。良好的技术储备与自身的生态优势使得百度成为了国内对话式大模型的先行者,我们也十分看好“文心一言”发布后在各个产业中的落地应用。
三、微软和英伟达相继召开发布会,AI应用广泛落地
3.1、微软推出Microsoft 365 Copilot,办公场景根本性变革
微软宣布 Microsoft 365 服务全面接入 AI 驱动工具 Copilot。3 月 16 日晚,微软在“The Future Work with AI”发布会上宣布将人工智能大语言模型技术(LLM)引入 Office 应用程序,推出了 AI 助手——Microsoft 365 Copilot,帮助用户提高办公生产力。该 AI 助手由 OpenAI 的 GPT-4 技术 驱动,出现在 Microsoft 365 应用的侧边栏,可以作为一个聊天机器人随时召唤,带来更智能、更 高效的办公体验。微软 CEO 表示,Copilot 的核心特点是通过自然语言理解用户的需求提供更加 个性化的服务,基于自然语言技术将大模型、用户数据和应用结合起来。
Copilot 打通微软办公产品线,数据在各个产品中自由流通。Microsoft 365 Copilot 将大语言模型 的能力与储存在 Microsoft Graph 中的数据如邮件、文档、会议、日程、聊天等以及 Word、Excel、 PowerPoint、Teams、Outlook 等办公产品全部联系到一起,通过四个步骤将用户的文本命令输 入转化为应用层的执行。Copilot 以迭代的方式来处理和编排这一系列流程服务,形成了集合大模 型、用户数据和应用的 Copilot System,实现了多种令人惊叹的功能。
1) 第一步:用户在办公产品端通过文本输入 prompt,Copilot 接收用户的 prompt,并通过 Grounding 技术对 prompt 进行预处理,其核心是调用 Microsoft Graph 来检索与此 prompt 相关的业务内容背景信息,并基于这些信息对 Prompt 进行修改;2) 第二步:Copilot 将修改后的 prompt 发送给大语言模型 LLM;3) 第三步:Copilot 获取到 LLM 对 prompt 产生的回应,并再次通过 Grounding 技术对回应进行 后处理,包括额外的图形调用、对 AI 生成结果的安全性、合规性检查等,并生成对应用的 调用命令;4) 第四步:Copilot 向用户发送最终回复和对应用程序的调用命令。
Copilot 与 Microsoft 365 应用紧密集成。微软将 AI 助手 Copilot 与 Word、Excel、PowerPoint、 Outlook、Teams 等产品紧密结合,成为高效的生产力工具。用户可以用 Copilot 实现在 Word 中 生成文稿,为 PPT 增加图片和动画效果,在 Excel 里分析用户输入的数据并将结果生成可视化图 表,帮助 Outlook 进行邮件管理和智能生成回复,在 Teams 里进行会议实时总结和会议纪要生成 等功能,甚至可以在不同的产品应用间进行格式转换,例如要求其根据给定的 Word 文档创建 PPT,极大地提高了用户在办公场景的效率。
Business Chat 功能将数据转化为知识,大幅提升办公效率。Copilot 提供了 Business Chat 功能, 横跨了所有的数据和应用,用 Microsoft Graph 将来自文档、PPT、电子邮件、日历、便笺和联系 人等的数据汇集在一起。比如可以直接通过与客户的聊天、邮件、日历等信息进行总结,按照 A 文件的格式编写包含 B 计划的时间表并给相关联系人发送邮件等。同时,团队中的每个人都可以 在同一个Chat页面上共同进行业务的推进,比如在员工 A 创建了文档后,员工B可以直接命令Copilot对文档进行修改,实现了协同办公效率的大幅提升。
Copilot 作为流程编排引擎驱动流程自动化与业务应用开发的 AI 变革。微软将 Copilot 也接入到 了旗下的低代码开发平台 Power Platform 中,用户可以在 Power Apps、Power Virtual Agents 和 Power Automate 中用自然语言描述他们想要的应用、功能和流程,Copilot 可以在几秒钟内完成 应用和流程的创建,并提供改进的建议。在 2022 年 10 月上线的预览版 Power Automate 中,采 用了 AI 驱动的流程自动化创建能够节省约 50%的时间,大幅提高了业务工作效率。
3.2、英伟达GTC 2023召开,展现AI多领域应用
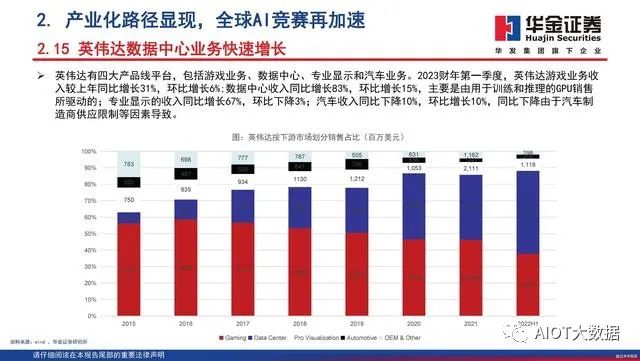
英伟达 GTC 2023 正式召开,展现 AI、加速计算及其他领域的突破性进展。北京时间 3 月 21 日 晚,英伟达 CEO 黄仁勋为 GTC 2023 进行了主题演讲,对英伟达在 AI 应用、加速计算等软硬件 领域取得的新进展进行了介绍。经过几十年的经营,英伟达不仅成为了全球领先的 AI 算力提供商, 也构建了一套围绕着实际产业运转的 AI 应用生态,在自然科学、化学制药、视觉解析、数据处理、 机器学习和大模型领域成为不可或缺的一环。
AI 产业迎来“iPhone”时刻,英伟达联手云厂商推出 DGX 云服务。黄仁勋在演讲中多次表示, AI 产业正处于“iPhone”时刻,生成式 AI 技术的快速进步引发了全球企业对 AI 战略制定的紧迫 感。为了方便企业客户更快地访问英伟达 AI 算力与应用库,黄仁勋在演讲中宣布英伟达将与微软 Azure、谷歌云、Oracle OCI 合作,推出英伟达 DGX 云服务。这一合作将英伟达的生态系统引入 了云服务厂商,极大地扩展了英伟达的触及范围。这意味着当下性能最佳的 DGX AI 超级计算机 将成为能够提供多租户的云服务设施,一众试图训练自营大语言模型、图片模型的企业,将能直 接通过云服务快速实现自己的愿景。目前已有 50 余家企业客户已经开始使用 DGX 云服务,涵盖 了医疗、媒体、金融等多个行业领域。
生成式 AI 将重塑几乎所有行业,行业模型有望成为未来大趋势。生成式 AI 是一种新型的计算平 台,与 PC、互联网、移动设备和云诞生的时代类似,先行者们已经在利用生成式 AI 打造新的应 用,利用其智能自动化和协同创作能力来改变传统的行业运行模式。对于某些具有较高专业性的 领域比如医疗、药物等行业,可能需要用专属的行业数据来构建定制化的行业模型,以满足该行 业的特定要求。我们在之前的报告《文心一言发布在即,大模型有望引领产业智能化变革》也有 展望过,通过模型蒸馏技术将大模型“瘦身”成为垂直行业模型,能够大大降低模型搭建的成本, MaaS 在未来将有望成为大模型落地的新形态。
英伟达推出 AI Foundations 云服务,提供从建立模型到上线运营的全套服务。对想要建立独有 的垂直领域行业模型的客户,英伟达推出了 AI Foundations 一站式云服务,从模型的构建到生成 应用上线,英伟达就类似于芯片行业的台积电,成为了生成式 AI 领域的代工厂,协助客户快速构 建、优化和运营大模型,把制造大模型的能力传递到每一个用户。英伟达 AI Foundations 由三个 部分组成:
1) NEMO:NEMO 是用于自然语言文本的生成式模型,提供 80 亿、430 亿、5300 亿参数的 GPT 模型,客户也可以引入自己想要的模型。Nemo 会定期更新额外的训练数据,可以帮助 企业为客服、企业搜索、文档处理、市场分析等场景定制生产生成式 AI 模型。2) PICASSO:PICASSO 是一项视觉语言模型的制作服务,可以用于训练能够生成图像、视频 和 3D 素材的模型。客户可以基于英伟达提供的 Edify 大模型或是自建定制模型来进行训练 和优化,得到自己想要的生成式 AI 模型。Shtterstock 目前正在与英伟达合作开发一款以其 专业的图像、3D 和视频素材库进行训练的 Edify-3D 生成式模型,用于简化创意制作、数字 孪生和虚拟协作中 3D 素材的创建过程。Adobe 也与英伟达合作,发布了 Adobe Firefly 这一 生成式 AI 工具,将生成式 AI 融入了营销人员和创意工作者的日常工作流中。
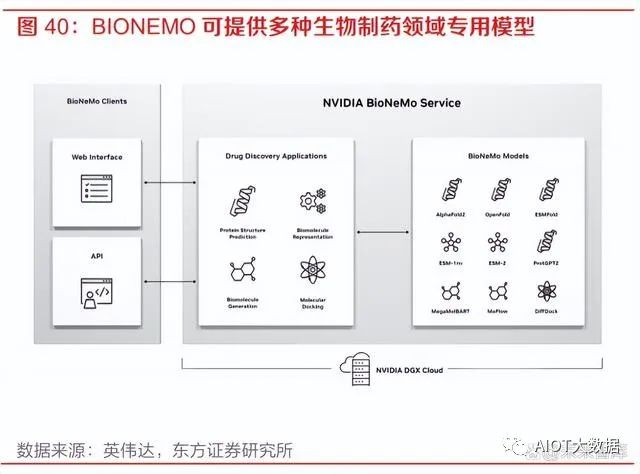
3) BIONEMO:BIONEMO 是针对于生物制药领域的 AI 模型服务。生物制药行业目前正在转向 利用生成式 AI 来发现疾病靶因、设计新型分子或蛋白质类药物、以及预测药物对机体的作 用等。BIONEMO 可以为用户提供创建、微调、提供自定义模型的平台,包括 AlphaFold、 ESMFold、OpenFold 等蛋白质预测模型。生成式 AI 模型可以在给出氨基酸序列的条件下快 速准确地预测目标蛋白质结构,预测蛋白质和分子的相互作用等,极大地提升了最佳候选药 物研发的效率。
工业软件领域与 AI 大模型能力的结合值得期待。本次英伟达 CEO 的主题演讲中,AI 与专业的创 意设计、工业设计、模拟仿真类软件结合方式为 AI 大模型的落地带来了新的场景,在驾驶仿真、 粒子特效运算、动画制作、材质表面生成、物理效果等领域都有良好的应用。我们认为,随着 AI 能力的持续进步和业界对 AI 应用方式的不断探索,像 CAD、EDA、BIM 等工业软件也有较大成 长的机会,其模型设计、图纸生成等功能都与大模型能力十分契合。未来随着国外头部厂商进行 大模型方向的创新应用,国内的相关工业软件企业也会有较大发展空间。
四、生成与通用领域双线发展,人工智能迈入“双G时代”
大语言模型的诞生带来了新的知识表示和调用方式的变迁。自计算机诞生以来,知识表示和调用 方式历经了两次大的变迁。在互联网诞生之前,最为常见的知识表示方式是关系型数据库,通过 SQL 语句进行调用,精确度高但调用的方式较为复杂,代表的公司比如 Oracle 等数据库的巨头公 司。随着互联网的诞生与搜索引擎的诞生,知识的调用方式变化为了关键词搜索,方便程度提高了,但是对于知识调用的精确度却有所降低。而大模型的诞生进一步提高了知识调用方式的自然 度,仅需通过自然语言交互即可访问想要的知识。
当下人工智能在生成和通用两条主线上不断发展,迈入“双 G 时代”。目前人工智能最火热的两 个赛道分别是生成(Generation)和通用(General),这两条赛道相互交织并行,AI 领域也进 入了“双 G 时代”。在生成领域,以 DALLE-2、Stable Diffusion 等引领的生成式 AI 技术与 AIGC 概念如火如荼;在通用领域,AI 研究者们现在都在朝着通用人工智能(Artificial General Intelligence, AGI)的方向不断努力,大模型不断增强的多模态感知能力就是迈向 AGI 的重要途径。这两条赛道是密不可分的,像百度的“文心一言”大模型就既具有多模态的生成能力,又能够回 答大部分的通用问题,具有一定的通用人工智能能力。
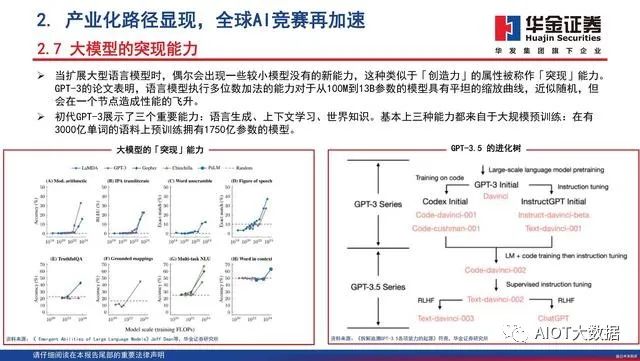
OpenAI 及其 GPT 系列模型是当前人工智能赛道上的领跑者,超大规模模型带来的知识涌现能力 是 ChatGPT 出圈的关键。OpenAI 和 GPT-4 毫无疑问是当下人工智能领域最为耀眼的明珠,回 顾 GPT 系列模型的发展历程,2018 年 OpenAI 发布 GPT-1 模型,仅有 1.17 亿参数,性能也落后 于谷歌随后发布的 BERT 模型,BERT 也成为当时 NLP 领域最常用的模型。OpenAI 持续在 GPT 模型上发力,陆续推出规模更大的迭代版本 GPT-2 和 GPT-3,在 OpenAI 的研究中,发现了当模 型参数到达一定规模时,模型会开始涌现出 In-context learning(上下文学习)、Chain ofThoughts(思维链)、Zero-shot(能够处理未见任务)等能力,而这样的能力成为了 ChatGPT 能够“更像人”的关键。
“文心一言”已达“能用”标准,我国在人工智能赛道上将持续追赶。从近期的“文心一言”相 关测试来看,距离 GPT-4 还有很大差距,但是其能力展现已有 GPT-3 的水平,达到了“能用” 标准,在 B 端、垂直行业端等都有应用的空间。我们认为,我国的人工智能技术起步晚,经验积累不足,但是发展速度较快。随着我国相关科技公司大力投入生成式 AI、大语言模型的研究,我 国在 AI 的“双 G 时代”中将持续扮演追赶者的角色,争取和国际领先水平缩小差距。
服务器产业链如何受益于AI大模型
(报告出品方:华泰证券)
产业链公司梳理
以 ChatGPT 为代表的 AI 应用掀起 AI 落地千行百业的浪潮,驱动算力需求增长。我们认为 服务器产业链将深度受益于 AI 算力需求,产业链公司包括:1)服务器品牌及整机:联想、 浪潮、工业富联、中兴通讯、紫光股份;2)PCB&CCL&ABF 载板:沪电股份、深南电路、 生益电子、兴森科技、胜宏科技、生益科技、华正新材等;3)主机板:环旭电子;4)半 导体:寒武纪、海光信息、龙芯中科、澜起科技、杰华特、东微半导、华润微、闻泰科技 等;5)光模块及光芯片:中际旭创、新易盛、天孚通信、华工科技、源杰科技等;5)光 纤光缆:长飞光纤光缆、亨通光电、中天科技等;6)热管理:英维克、申菱环境。
AI 大模型如何推动服务器产业链需求
为了满足 AI 市场的需求,英伟达今年 GTC2023 上不仅发布了 L4 Tensor Core GPU、L40 GPU、H100 NVL GPU 和 Grace Hopper 等芯片,还进一步推出 NVIDIA DGX 超级计算机, 成为大语言模型实现突破背后的引擎。英伟达在 GTC2023 中表示,《财富》100 强企业中 有一半安装了 DGX AI 超级计算机,DGX 已成为 AI 领域的必备工具。DGX 配有 8 个 H100 GPU 模组,H100 配有 Transformer 引擎,旨在支持类似 ChatGPT 的大模型。这 8 个 H100 模组通过 NVLINK Switch 彼此相连,以实现全面无阻塞通信。8 个 H100 协同工作,形成一个巨型 GPU。通过 400 Gbps 超低延迟的 NVIDIA Quantum InfiniBand 进行网络内计算,将成千上万个 DGX 节点连接成一台 AI 超级计算机,并不断扩 展应用范围,成为全球客户构建 AI 基础设施的蓝图。
服务器厂商如何把握 AI 大模型机会
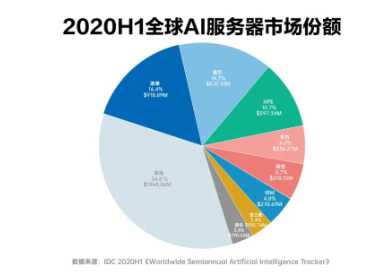
AI 大模型训练和推理催生 GPU 需求上涨,AI 服务器采用异构式架构,NVIDIA DGX A100 服务器 8 个 GPU+2 个 CPU 的配置远高于普通服务器 1~2 个 CPU 的配置,能够满足 AI 大模型需求。在单芯片计算训练性能不断提升的基础上,服务器整体能效的提升同样受到 关注。IDC 预计,全球 AI 服务器市场规模稳健增长,2021-2026E CAGR 预计达 17%。我 们认为,AI 大模型将带动算力需求增长,催生对 AI 服务器的需求。工业富联、联想、中兴 通讯、紫光股份等公司有望把握住AI大模型带来的机会,受益于AI服务器需求的持续提升。
全球 AI 服务器市场规模稳健增长,2021-2026E CAGR 预计达 17%
根据 IDC 数据,2014-2021 年,全球服务器厂商销售总额总体呈上升趋势,2021 年全球服 务器市场规模达到 USD99bn。其中,戴尔、HPE、联想、浪潮市场份额排名前列,合计占 比超过 40%。IDC 认为 2021-2026E 全球 AI 服务器厂商市场规模将稳健增长,2026 年市 场规模有望达 USD35mn,预计 2021-2026E CAGR 达到 17%。1H21 全球 AI 服务器厂商 竞争格局相对集中,其中浪潮信息占比最高(20.2%),其次是戴尔、HPE、联想。
AI 服务器采用异构式架构,GPU 数量远高于普通服务器
AI 大模型训练和推理催生 GPU 需求上涨。目前 AI 训练主要采用:1)英伟达在 AI 训练 GPGPU:包括 V100/A100/H100(22 年下半年开始量产出货)以及美国限制出口后英伟达 推出的裁剪版 A800。2)AMD 推出的 AI 训练芯片包括 MI 250/250X/300。在推理芯片的选用方面,相较于训练更多关注模型大小而言,推理更依赖于任务本质,以 此决定所需芯片种类。当需要大量内容/图像 AI 生成式时,需要 GPU 进行推理计算(如英 伟达主流的 T4 芯片);而对于较简单的推理过程(语音识别等),CPU 有时也会成为较好 的推理引擎。AI 服务器采用异构式架构,GPU 数量远高于普通服务器。随着多模态大模型 AI 服务器和 普通服务器的主要区别在于:1)架构不同。AI 服务器采用 CPU+GPU/FPGA/ASIC 等异构 式架构,而普通服务器一般是 CPU 架构;2)GPU 数量差异显著。比较 NVIDIA DGX A100 和浪潮英信服务器 NF5280M6 构造,NVIDIA DGX A100 包括 8 个 A100 GPU 和 2 个 AMD Rome CPU,而浪潮英信服务器 NF5280M6 仅配置 1-2 个英特尔第三代 Xeon 处理器。仅 在 GPU 方面,一台 AI 服务器就能够带来约 10 万美元的价值量提升。

在单芯片计算训练性能提升的基础上,服务器整体能效的提升同样受到关注
英伟达在此次 GTC 大会上推出 DGX H100 服务器,配有 8 个 H100 GPU 模组,配有 Transformer 引擎以支持处理类似 ChatGPT 的生成式训练模型,FP8 精度在大型语言模型 相较上一代 A00 的训练和推理能力分别提升 9/30 倍。8 个 H100 模组通过 NVLINK Switch 相连,确保 GPU 之间的合作和通信。我们认为,AI 服务器整体能效的提升驱动服务器各零部件升级需求,包括且不限于:1)AI 训练和推理对网络带宽提出更高要求,有望催生光模块速率进一步升级需求,其中 800G 光模块有望加速放量;2)PCB:AI 服务器用 PCB 一般是 20-28 层,传统服务器最多 16 层,每提升一层,PCB 价值量提升 1000 元左右,因此单台 AI 服务器的 PCB 价值量约为 单台传统服务器的 3-4 倍;3)服务器半导体:GPU 方面,一台 AI 服务器就能够带来约 10 万美元的价值量提升,而大功率供电需求也驱动多相电源用量增长,进一步提升价值量。
服务器厂商有望借助“AI 算力革命”机遇再创高峰
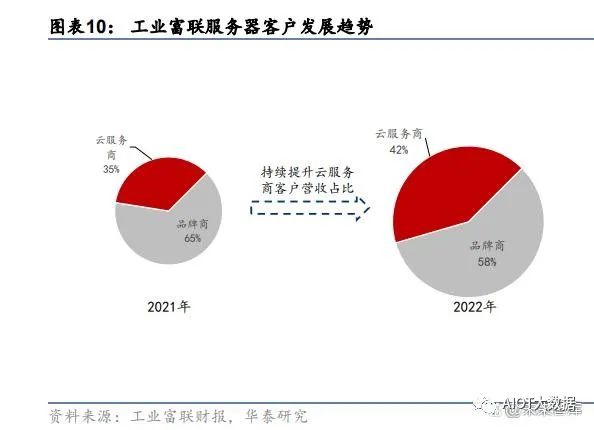
工业富联作为提供服务器代工服务的龙头厂商,将深度受益于 AI 服务器市场扩容带来的机 会,有望凭借高性能的 AI 服务器迎来营收增长。客户方面,相较于 2021 年,2022 年工业 富联服务器营收中云服务商比重由 35%上升至 42%,来自云服务商客户的营收占比持续提 升;产品方面,伴随着 AI 硬件市场迅速成长,公司相关产品 2022 年出货加倍,AI 服务器 及 HPC 出货增长迅速,在 2022 年云服务商产品中占比增至约 20%。算力时代的开启为高 效 AI 服务器提供了更广阔的发展空间,据公司 2022 年报,相关新产品将在 2023 年陆续研 发推出。2022 年,工业富联云服务设备占总营收比例超过 40%,考虑到收入增速超平均 的 CSP 业务占公司云设备业务比重上升,我们预测工业富联服务器 23/24/25 年的收入增 幅为 8.6%/8.2%/8.2%,高于行业平均。
环旭电子:服务器和高速交换机主机板供应商,协助客户推出边缘 AI 计算服务器
环旭为客户提供 ODM/JDM/EMS 伺服器、存储、NAS 和 SSD 产品以及制造服务,并提供 L10 系统设计服务,包括主机板、固件 BIOS 和 BMC、子卡(背板、附加卡等)、外壳和散 热设计以及系统集成。Al 服务器方面,环旭提供设计制造(JDM)服务,协助品牌客户推出 边缘 Al 计算服务器。根据环旭电子 2022 年业绩快报,云端及存储类业务营收达 69.89 亿 元,同比增长 41.1%,占公司营收比例由 2021 年的 8.7%增长至 2022 年的 10.2%。我们 认为,受益于 AI 带来的云端及边缘计算新需求,公司云端及存储类产品营收有望实现长期 稳健增长。
PCB 厂商如何把握 AI 大模型机会
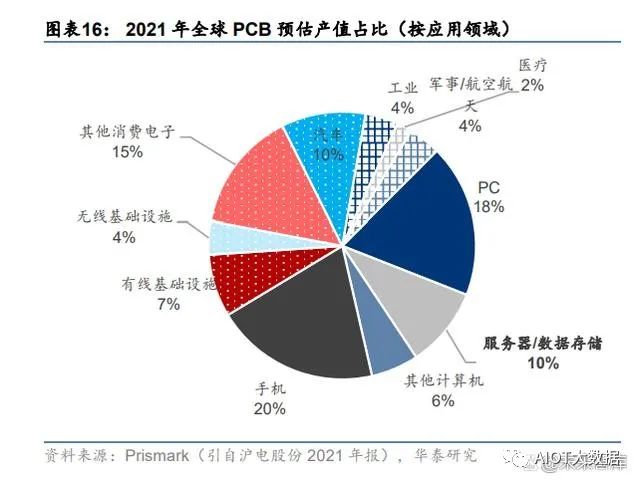
从下游应用来看,服务器/数据存储是 PCB 重要的下游应用领域之一。根据 Prismark 数据, 预估 2021 年服务器/数据存储占全球 PCB 产值的 10%,并预测其 2021-2026 年产值复合 增速在 PCB 下游细分领域中排名第一。
PCB 在服务器中主要用于:1)主板:服务器标配,且使用的 PCB 价值量最高;2)电源 背板:单独设置或与主板集成;3)功能性配板:网卡、硬盘、内存、CPU 等。服务器用 PCB 的特点主要体现在高层数、高纵横比、高密度及高传输速率,以高多层板、封装基板 为主。
AIGC 大模型的训练和推理需要大量的高性能计算算力支持,对 AI 服务器需求提升,同时 将进一步加速服务器平台升级。整体来看,AI 大模型的发展对 PCB 的核心影响在于价值量 提升,包括:1)服务器平台升级;2)AI 服务器对 PCB 的高要求。
服务器平台升级对 PCB 的影响关键在于总线标准升级
价#1:服务器平台升级对 PCB 的影响关键在于总线标准升级。其价增逻辑在于,服务器平 台升级→PCIe 总线标准升级→传输速率提升→走线密度增加→PCB 层数、材料等级、工艺 (如背钻)要求更高、更严格→PCB 价值量提升。以 Intel 服务器平台为例,从 Purley 到 Whitley 再到即将量产的 Eagle Stream,对应的 PCIe 接口级别依次提升,分别为 PCIe 3.0、 4.0 和 5.0,PCB 层数从 12 层以下增加至 16 层以上,CCL 材料等级从 Mid Loss 升级至 Ultra Low Loss,对背钻等技术的管控更严格。根据产业调研,从 Whitley 到 Engle Stream, PCB 层数虽仅增加 2-4 层,但价格差不多翻倍。以 ChatGPT 大模型引领的新一轮 AI 技术革命,将加速新一代服务器平台渗透率提升及下 一代服务器平台研发。从主流厂商规划来看,AMD 的 Zen4 平台和 Intel 的 Engle Stream 预计将在今年 Q3-Q4 开始上量,有望开启新一轮服务器 PCB 上行周期。
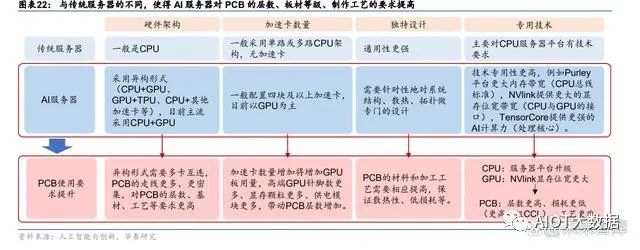
相比传统服务器,AI 服务器的 PCB 层数更高,单台 PCB 价值量大幅提升
价#2:相比传统服务器,AI 服务器的 PCB 层数更高,单台 PCB 价值量大幅提升。AI 服务 器与传统服务器的区别主要在于:1)硬件架构更复杂:多采用“CPU+其他加速卡”的异 构形式,且目前 CPU+GPU 为主流;2)加速卡数量更多:一般配置四块及以上加速卡;3) 设计更独特:针对系统结构、散热、拓扑等专门设计;4)技术更专用:如服务器平台需要 更大内存带宽,NVlink 提供更大的显存位宽带宽,TensorCore 提供更强的 AI计算力等。这些区别,尤其是 NVlink 这些特殊接口都使得 AI 服务器对 PCB 层数,通信速度都提出了 更高要求,从而带动 AI 服务器的 PCB 价值量大幅提升。根据产业调研, AI 服务器用 PCB 一般是 20-28 层,传统服务器最多 16 层,每提升一层, PCB 价值量提升 1000 元左右,因此单台 AI 服务器的 PCB 价值量相较传统服务器的 PCB 价值量将有明显提升。
AI 服务器占全球服务器出货量比例将逐年提升,长期仍有量增空间
量:AI 服务器占全球服务器出货量比例将逐年提升,长期仍有量增空间。目前 AI 服务器占 整体服务器出货量的比例并不高,但在智算算力需求的潜在预期下占比有望逐年提升,长 期看对 PCB/CCL 有增量空间。据 TrendForce 数据,截至 2022 年为止,预估搭载 GPGPU 的 AI 服务器年出货量占整体服务器比重近 1%,预计在 ChatBot 相关应用加持下,2023 年 出货量年增长可达 8%,另外预测其 2022-2026 年 CAGR 将达 10.8%,是全球整体服务器 的复合增速的 2 倍多。因此,AI 服务器对 PCB 的影响,短期以价值量提升为主,长期仍有 增量空间。
从竞争格局上看,大陆 PCB 厂商在全球服务器的竞争中已占据一席之地,但在 AI 服务器 领域参与度不高。AI 大模型要求多张 GPU 通过 NVLINK 等特殊接口紧密链接形成一张超 级 GPU,对高密度 PCB 板的层数、通信速度等提出更高要求。产业链公司包括生产通信 用高密度 PCB 的深南电路、沪电,兴森科技等,以及生产高速 PCB 板用材料(M6)的生 益科技。
高算力需求带动先进封装需求,ABF 载板有望充分受益
高算力需求带动先进封装需求,ABF 载板有望充分受益。以 AI 大模型为基础的 AIGC 新应 用快速兴起,对算力的要求提高,服务器单机将搭载更多的 CPU/GPU 等芯片,解决多芯 片间高速互连的先进封装成为关键。而 IC 载板作为先进封装的关键材料,有望进一步打开 价值空间。尤其 ABF 载板,相较于 BT 载板具备层数多、面积大、线路密度高、线宽线距 小等特点,更能承载 AI 高性能运算,在 CPU、GPU、FPGA、ASIC 等高运算性能 IC 放量 预期下将更充分受益。据 Prismark 预测,ABF 载板为 IC 载板行业规模最大、增速最快的 细分领域,预计全球 ABF 载板市场规模 2026 年将达到 121 亿美元,2021-2026 年 CAGR 为 11.5%。
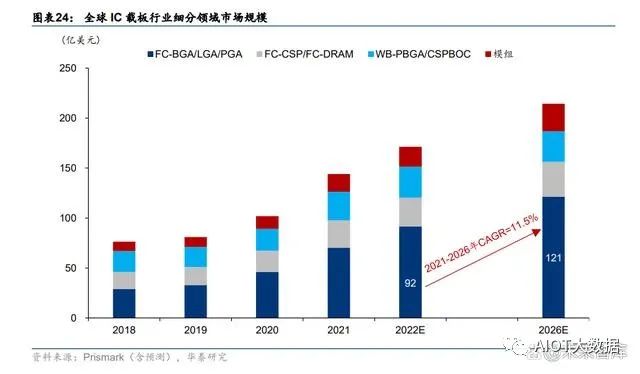
从竞争格局看,载板技术壁垒较高,长期以日韩台厂商为主,国内起步较晚。我们认为, 随着半导体产业链的国产化替代加速,国内厂商仍有较大上升空间。
半导体厂商如何把握 AI 大模型机会
电源芯片:AI 服务器多相电源用量提升,国产替代空间广阔
随着大数据、云计算、人工智能概念的兴起, CPU、GPU 对供电电压调节器(VRM/Vcore) 和负载点电源 (PoL)的效率和功率提出了严峻挑战。多相Buck电源包含控制器及DrMOS, 是一种多路交错并联的同步 Buck 拓扑,被公认为是此类应用场景的最佳解决方案。通过多 相控制器和 DrMOS 的组合使用,将多个降压电路的输出并联使用,从而输出数百安培到数 千安培的电流,适用于超大功率供电的需求。DrMOS 能给 CPU /GPU 电源设计带来三点 优势:1)更稳定的电源;2)power 零部件减少;3)power 零件小型化与线路简洁化,满 足下游产品轻薄短小但高效的需求。
根据 MPS 数据,服务器主板电源解决方案涉及 CPU/GPU 供电、存储 DDR 供电、POL 以及 EFuse 等产品,CPU 服务器及 GPU 服务器电源合计市场规模约 20 亿美金。具体来 看 CPU、GPU 供电主要采用多相控制器+ DrMOS 模式。根据 MPS 官网,最初 CPU 采用 4 相,6 相,GPU 已经演进至采用 16 相供电,总市场规模约 6 亿美金。POL(负载点电源) 则是分布与各个功能单元电路前端的 DC/DC 稳压器,一台服务器上有十多颗 POL,对应市 场规模约 6000 万美金。由于 DDR5 标准将直流供电功能从主板转移至内存条,因此每一 个内存条将额外包含一组 DC-DC 直流变压电路。这种方式无疑会增加成本,总市场规模 约 2.8 亿美金。电子保险丝 EFuse 用于为子电路或 PC 板提供局部快速响应保护, 对应全 球市场规模约 6000 万美金。

AI 服务器采用异构式架构,NVIDIA DGX A100 服务器 8 个 GPU+2 个 CPU 的配置远高于 普通服务器 1~2 个 CPU 的配置。单颗 NVIDIA A100 至少需要 16 相电源解决方案,单台 AI 服务器所需多相电源数量呈几何式增长。IDC 预计,全球 AI 服务器市场规模稳健增长, 2021-2026E CAGR 预计达 21%。我们认为,AI 大模型将带动算力需求增长,催生对 AI 服务器的需求,带动多相电源市场需求增加。
国外厂商主导 DrMOS及多相控制器市场,国内空白亟待弥补。由于DrMOS技术难点较多:1)大功率大电流的工艺——BCD 工艺;2)设计;3)封装,DrMOS 在国内尚属空白,国 产替代亟待推进。DrMOS 主要厂商为 MPS、ADI、TI 和安森美等,目前下游厂商几乎只采 用海外 DrMOS 产品,如微星 B650 迫击炮采用 MPS 产品, 2206/MP87670 单相提供额定 80A 电流。大陆厂商仅杰华特具有 DrMOS 量产能力,单芯片已经做到 70 安培,性能可与 国际一流厂商相比,有望弥补国内空白,目前公司 DrMOS 产品在服务器、笔电领域均实 现批量出货。公司多相控制器产品目前处于送样阶段,未来会与 DrMOS 配套出货。
计算芯片/存储控制芯片:增加 AI 加速器芯片,提升计算效率
芯片端:增加 GPU 等 AI 加速芯片提升计算效率
AI 服务器与普通服务器相比,AI 服务器的芯片通常被优化和设计用于执行机器学习和深度 学习算法,常采用异构计算的方式。具体来看 1)CPU:AI 服务器和普通服务器都使用 CPU。但 AI 服务器通常会使用性能更高的 CPU, 以便更快地处理复杂的计算任务。2)GPU:GPU 是 AI 服务器的核心组成部分,在矩阵运算和深度学习模型训练方面具有更 高的效率。相比之下,普通服务器通常只使用 CPU 而不使用 GPU。以浪潮信息为例,我 们看到 AI/HPC 服务器分别配备 8 颗 A800 GPU 以及 4 颗 V100/ P100 等英伟达 GPU。3)FPGA/ASIC:是专门为特定任务设计的芯片,与通用 CPU 或 GPU 相比,这两类芯片 可以更快地执行特定的计算任务。我们看到 HPC 服务器相比通用/AI 服务器多配备 2 颗赛 灵思 FPGA,整体服务器的单机台芯片用量预计随着 AI 服务器的用量而显著提升。

寒武纪训练卡:思元 370 推训一体实现硬件升级,同英伟达数据中心产品 T4/A10 直面竞 争,思元 590 加入浮点计算实测性能优异。目前寒武纪核心发力云端,其核心产品包括:1) 思元 370 于 2021 年推出,是寒武纪第三代云端产品采用 7nm 制程工艺,是寒武纪首款采 用 Chiplet(芯粒)技术的人工智能芯片。思元 370 智能芯片最大算力高达 256TOPS(INT8), 是寒武纪第二代云端推理产品思元270算力的2倍,产品形态包括3款加速卡:MLU370-S4、 MLU370-X4、MLU370-X8,已与国内主流互联网厂商开展深入的应用适配。2)思元 590 在上一代思元 290 的基础上增加浮点计算能力,采用 MLUarch05 全新架构,实测训练性能 较在售旗舰产品有了大幅提升,它提供了更大的内存容量和更高的内存带宽,其 IO 和片间 互联接口也较上代实现大幅升级。
海光 DCU:公司 DCU 产品主要面向智能计算以及人工智能市场,采用高性能计算市场目 前主流的 GPGPU 架构。当前 DCU 产品综合性能约为英伟达 A100 产品的 70%-80%,与 国内同行相比,公司的优势在于:①全精度计算:公司产品覆盖 64 位、32 位、16 位以 及整型 8 位训练/推理;②兼容主流生态:兼容“类 CUDA”环境,能够较好地适配、适应 国际主流商业计算软件和人工智能软件,并通过更好的性价比实现国产替代。海光 DCU 集 成片上高带宽内存芯片,可以在大规模数据计算过程中提供优异的数据处理能力,使海光 DCU 可以广泛应用于不同的场景。目前该产品可广泛应用于大数据处理、人工智能、商业 计算等计算密集类应用领域,我们预计将在超算中心首先得到应用,长期来看将凭借当前 与互联网公司、AI 厂商、先进计算中心以及智算中心的深度合作关系,实现从政府项目到 行业的破圈。
通信设备厂商如何把握 AI 大模型机会
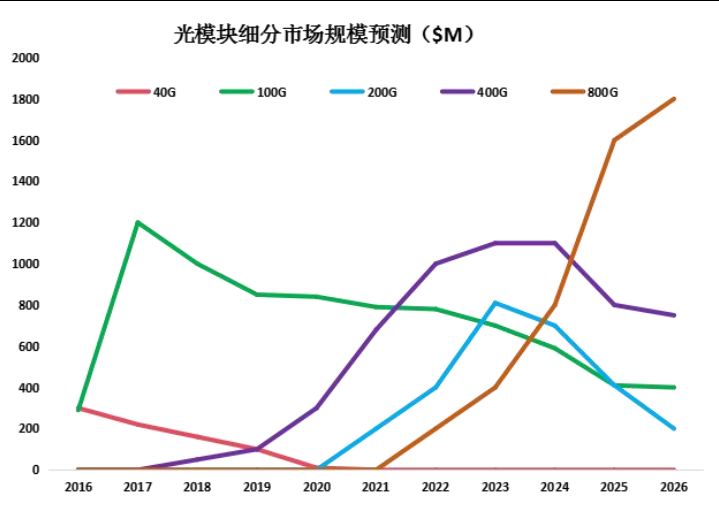
光模块:数据中心市场空间广阔,2023 年有望迎 800G 放量元年
全球光模块市场稳健增长,数据中心光模块市场空间广阔。根据 LightCounting 的统计及 预测,2019~2021 年,全球光模块市场规模从 89 亿美元增长到 114 亿美元,预测 2025 年 全球光模块市场将达到 171 亿美元,对应 2022~2025 年 CAGR 为 10.65%。全球光模块市 场结构方面,CWDM/DWDM 光模块和用于数据中心的以太网光模块占比较高,二者出货 金额合计占比从 2019 年的 74%提升至 2021 年的 79%,其中光模块市场规模为 47亿美元, 占比为 41%,为光模块中最大细分品类市场。
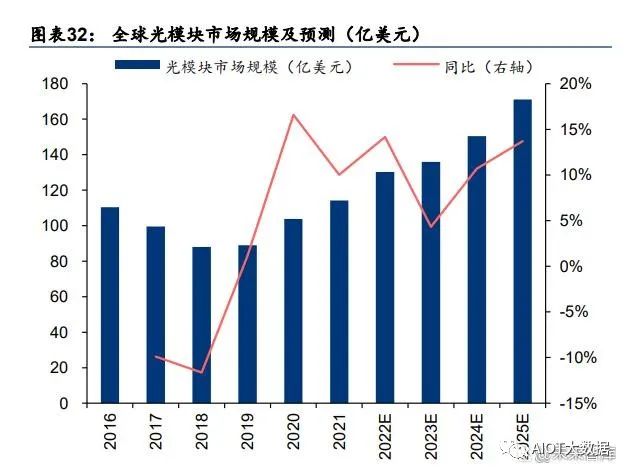
800G 有望迎接放量元年。随着云计算、AI、元宇宙等技术产业的快速发展和传统产业数字 化的转型,全球范围内数据快速的增长对网络带宽提出新的要求,有望催生光模块速率升 级需求。LightCounting 指出,AI 应用等带来的数据流量的增长,超预期的数据中心带宽需 求以及光模块厂商技术的迭代都是推动 800G 应用的动力。根据 LightCounting 于 2022 年 4 月发布的预测,2022~2024 年全球 800G 以太网光模块出货量有望达 11、39、119 万只。我们认为随着 800G 光模块有望迎来放量元年,国内头部光模块以及上游光器件、光芯片 厂商有望迎发展机遇。
国内光模块厂商彰显全球竞争力。根据 Lightcounting 于 2022 年 5 月发布的统计数据,2021 年全球前十大光模块厂商,中国厂商占据六席,分别为旭创(与 II-VI 并列第一)、华为海思 (第三)、海信宽带(第五)、光迅科技(第六)、华工正源(第八)及新易盛(第九);相 比于 2010 年全球前十大厂商主要为海外厂商,国内仅 WTD(武汉电信器件有限公司,2012 年与光迅科技合并)一家公司入围,体现出十年以来国产光模块厂商竞争实力及市场地位 的快速提升。
以太网交换机芯片:交换机核心部件,国产替代空间广阔
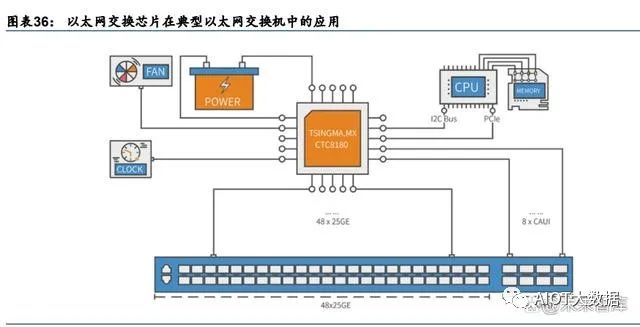
以太网交换芯片是交换机核心部件。以太网交换机为用于网络信息交换的网络设备,是实 现各种类型网络终端互联互通的关键设备。交换设备由以太网交换芯片、CPU、PHY、PCB、 接口/端口子系统等组成,其中以太网交换芯片为最核心部件。交换芯片是用于交换处理大量数据及报文转发的专用芯片,是针对网络应用优化的专用集成电路(ASIC)。
全球以太网交换芯片市场增长稳健,国内增速领先。根据盛科通信招股书和灼识咨询预测, 2020 年全球以太网交换芯片市场规模为 368 亿元,同比下降 4.3%,预计 2020-2025E 年 均复合增速为 3.4%,2025 年全球市场规模为 434 亿元。2020 年我国交换芯片市场规模为 90 亿元,同比增长 25.2%,灼识咨询预测 2025 年我国市场规模可达 171.4 亿元,对应 2021E-2025E 复合增速为 13.8%,显著领先全球增速。根据信通院,国内市场由于数据中 心等新基建领域政策环境向好(如东数西算、算力网络建设等政策),而交换机作为搭建数 据中心架构的骨骼,用以保证数据传输稳定可靠,将随之大量提振需求。
“高速化”:100G 及以上端口速率将成主流,应对下一代数据中心带宽需求。端口速率是 以太网芯片的每个端口每秒钟传输的最大 bit 数量,是衡量芯片性能的重要指标。近年数字 经济的快速发展,推动了云计算、人工智能、大数据等技术产业的快速发展和传统产业数 字化的转型,全球范围内数据快速的增长对网络带宽提出新的要求。根据信通院《数据中 心产业图谱研究报告》预测,100G、400G 及以上的市场需求将逐渐增多,预计 400G 产 品最终会占据优势地位,中长期来看,预计 400G 数据中心交换机 2022 年末有望成为营收 主力,2023 年开始 800G 交换机有望得到快速发展。根据灼识咨询预测,100G 以上占比 将从 2020 年的 24.1%提升至 2025 年的 44.2%。
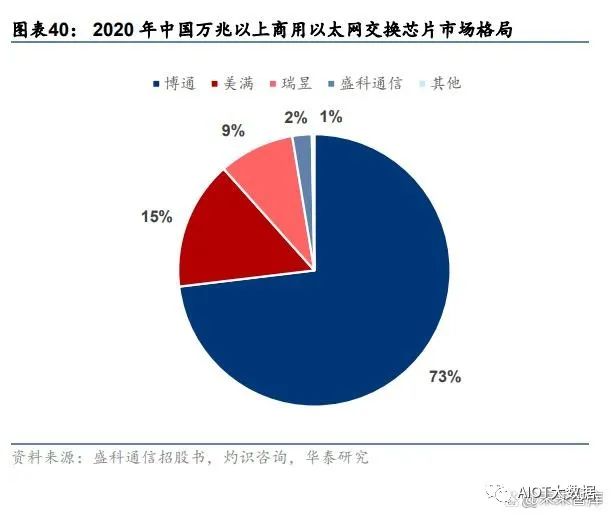
国内商用交换芯片行业集中度高,海外巨头垄断,盛科通信为头部国产商。以太网交换芯 片领域由少数参与者掌握大部分份额,2020 年中国商用以太网交换芯片市场中,博通、美 满和瑞昱分别以 61.7%、20.0%和 16.1%分列前三,CR3 达到 97.8%,博通的产品在超大 规模的云数据中心、HPC 集群与企业网络市场上占据较高份额,为以太网交换芯片的全球 龙头,是盛科发展方向借鉴的对象。由于交换芯片具备较高技术、客户、应用和资金壁垒, 行业整体国产化程度较低,国内参与厂商较少。盛科通信在中国商用以太网交换芯片市场 中,以销售额计占据 1.6%的份额,排名第四,在国产厂商中排名第一。此外,2020 年中 国万兆以上商用以太网交换芯片市场中,盛科通信市占率达 2.3%。
AI产业化再加速,GPU智能大时代已开启
(报告出品方/作者:华金证券,孙远峰、王臣复、王海维)
1.由专用走向通用,GPU赛道壁垒高筑
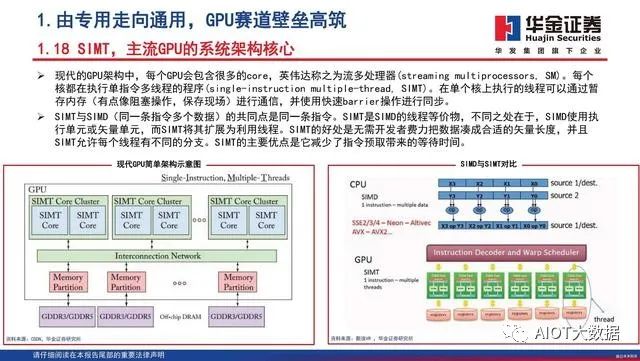
什么是GPU
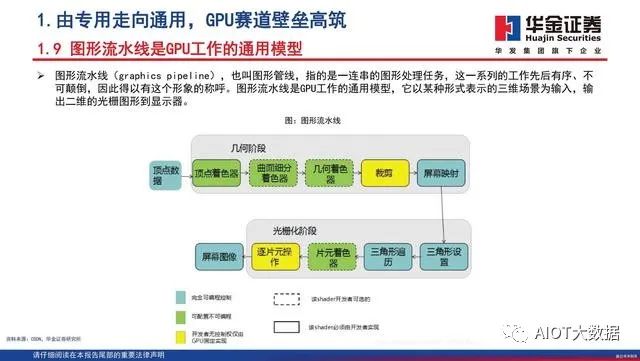
图形处理器(graphics processing unit,缩写:GPU), 又称显示核心、视觉处理器、显示芯片,是一种专门在个 人电脑、工作站、游戏机和一些移动设备(如平板电脑、 智能手机等)上做图像和图形相关运算工作的微处理器。NVIDIA公司在1999年发布GeForce 256图形处理芯片时首 先提出GPU的概念。从此NVIDIA显卡的芯片就用这个新名 字GPU来称呼。GPU使显卡削减了对CPU的依赖,并执行部 分原本CPU的工作,尤其是在3D图形处理时。
始于图形处理设备
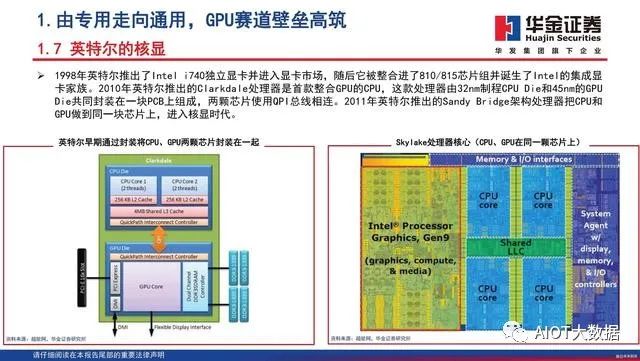
最早计算机是黑白显示的时代,机器对于显示的要求极低,随着计算机的普及和软件的多样化,使用者对于显示的要求越来越高。VGA(Video Graphics Array,视频图形阵列)是一种标准的显示接口,是IBM于1987年提出的一个使用模拟信号的电脑显示标准。VGA标准由于可以呈现的彩色显示能力大大加强,因此迅速成为了显示设备的标准,也推动了VGA Card也即是显卡的诞生。早期的VGA Card的唯一功能是输出图像,图形运算全部依赖CPU,当微软Windows操作系统出现后,大量的图形运算占据了CPU的大量资源,如果没有专门的芯片来处理图形运算,Windows界面运作会大受影响而变得卡顿,因此出现专门处理图形运算的芯片成为必然趋势。1993年1月,英伟达创立,1999年,英伟达发布了划时代的产品GeForce 256,首次推出了所谓图形处理器(GPU,Graphic Processing Unit)的概念,它带来了3D图形性能的一次革命。
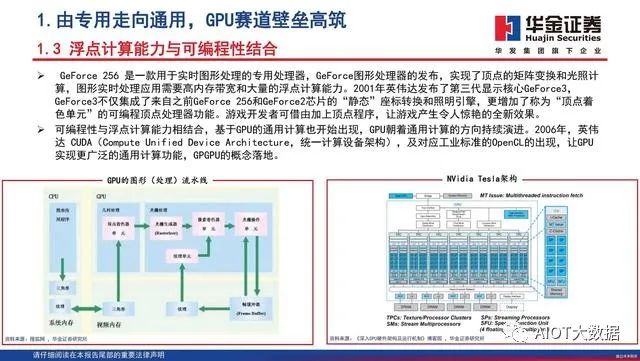
浮点计算能力与可编程性结合
GeForce 256 是一款用于实时图形处理的专用处理器,GeForce图形处理器的发布,实现了顶点的矩阵变换和光照计算,图形实时处理应用需要高内存带宽和大量的浮点计算能力。2001年英伟达发布了第三代显示核心GeForce3,GeForce3不仅集成了来自之前GeForce 256和GeForce2芯片的“静态”座标转换和照明引擎,更增加了称为“顶点着色单元”的可编程顶点处理器功能。游戏开发者可借由加上顶点程序,让游戏产生令人惊艳的全新效果。可编程性与浮点计算能力相结合,基于GPU的通用计算也开始出现,GPU朝着通用计算的方向持续演进。2006年,英伟达 CUDA(Compute Unified Device Architecture,统一计算设备架构),及对应工业标准的OpenCL的出现,让GPU实现更广泛的通用计算功能,GPGPU的概念落地。
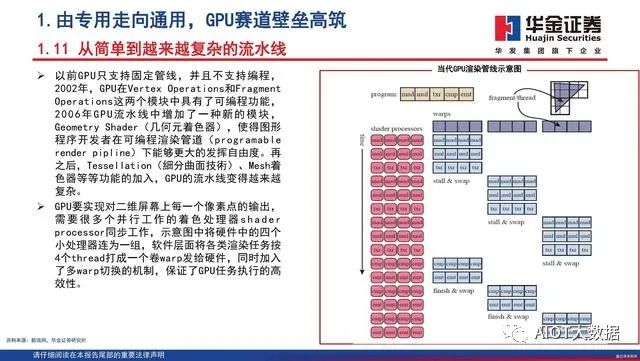
GPU发展三大方向
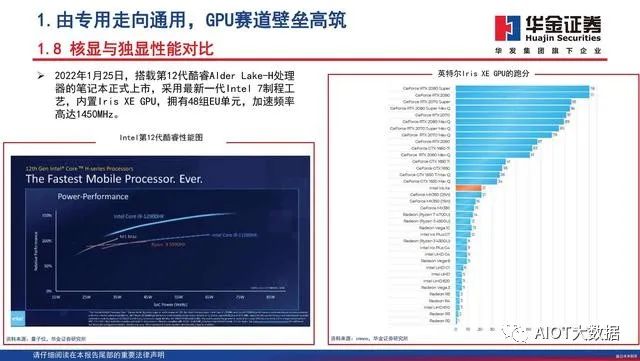
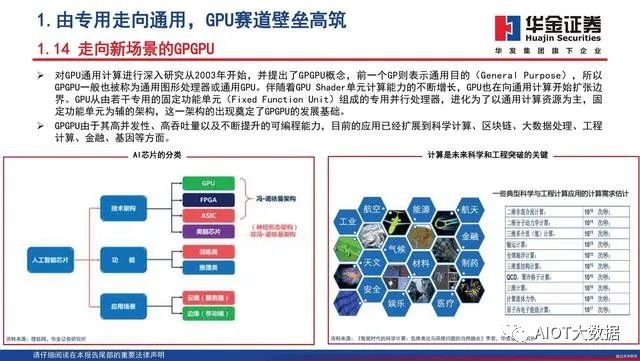
GPU最初用在PC和移动端上运行绘图运算工作的微处理器,与CPU集成以集成显卡(核显)的形态发挥功能。NVIDIA于2007年率先推出独立GPU(独显),使其作为“协处理器”在PC和服务器端负责加速计算,承接CPU计算密集部分的工作负载,同时由CPU继续运行其余程序代码。2019年NVIDIA的中国GTC大会设置了两大主题:AI和图形。从大会的关注重点可以看出,GPU未来趋势主要是3个:大规模扩展计算能力的高性能计算(GPGPU)、人工智能计算(AIGPU)、更加逼真的图形展现(光线追踪RayTracingGPU)。
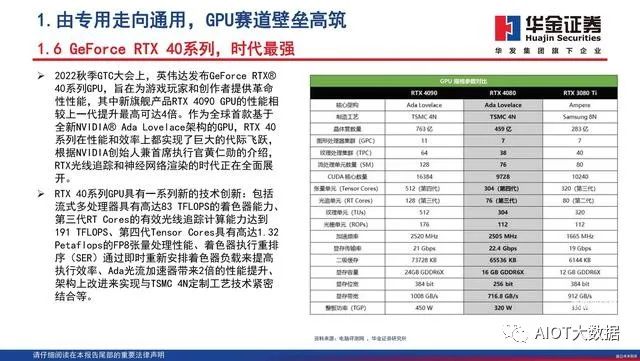
GeForce RTX 40系列,时代最强
2022秋季GTC大会上,英伟达发布GeForce RTX 40系列GPU,旨在为游戏玩家和创作者提供革命 性性能,其中新旗舰产品RTX 4090 GPU的性能相 较上一代提升最高可达4倍。作为全球首款基于 全新NVIDIA Ada Lovelace架构的GPU,RTX 40 系列在性能和效率上都实现了巨大的代际飞跃, 根据NVIDIA创始人兼首席执行官黄仁勋的介绍, RTX光线追踪和神经网络渲染的时代正在全面展 开。RTX 40系列GPU具有一系列新的技术创新:包括 流式多处理器具有高达83 TFLOPS的着色器能力、 第三代RT Cores的有效光线追踪计算能力达到 191 TFLOPS、第四代Tensor Cores具有高达1.32 Petaflops的FP8张量处理性能、着色器执行重排 序(SER)通过即时重新安排着色器负载来提高 执行效率、Ada光流加速器带来2倍的性能提升、 架构上改进来实现与TSMC 4N定制工艺技术紧密 结合等。
2. 产业化路径显现,全球AI竞赛再加速
AI技术赋能实体经济面临的瓶颈
过去,绝大部分人工智能企业和研究机构遵循算法、算力和数据三位一体的研究范式,即以一定的算力和数据为基础,使用开源算法框架训练智能模型。而这也导致了当前大部分人工智能处于“手工作坊式”阶段,面对各类行业的下游应用,AI逐渐展现出碎片化、多样化的特点,也出现了模型通用性不高的缺陷。这不仅是AI技术面临的挑战,也限制了AI的产业化进程。随着人工智能赋能实体经济进入深水区,企业通常面临数据资源有限、算力投资难度大、模型泛化能力差、高水平人才稀缺的发展瓶颈。
ChatGPT的破圈
聊天生成型预训练变换模型(Chat Generative Pre-trained Transformer)简称ChatGPT,是OpenAI开发的人工智慧聊天机器人程序,于2022年11月推出,上线两个月后已有上亿用户。ChatGPT目前仍以文字方式互动,而除了可以用人类自然对话方式来互动,还可以用于甚为复杂的语言工作,包括自动生成文本、自动问答、自动摘要等多种任务。
ChatGPT的成功离不开预训练大模型
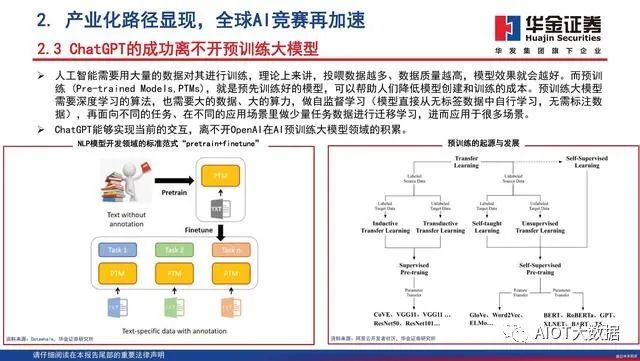
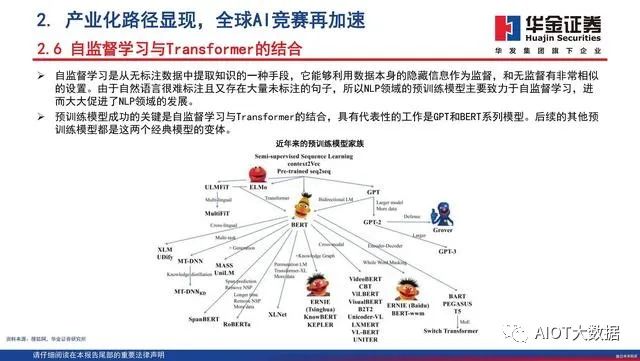
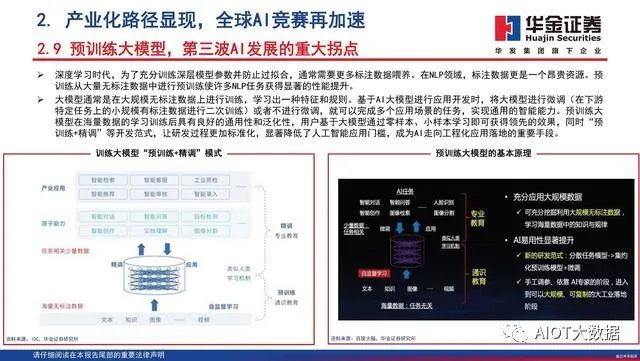
人工智能需要用大量的数据对其进行训练,理论上来讲,投喂数据越多、数据质量越高,模型效果就会越好。而预训练 (Pre-trained Models,PTMs),就是预先训练好的模型,可以帮助人们降低模型创建和训练的成本。预训练大模型需要深度学习的算法,也需要大的数据、大的算力,做自监督学习(模型直接从无标签数据中自行学习,无需标注数据),再面向不同的任务、在不同的应用场景里做少量任务数据进行迁移学习,进而应用于很多场景。ChatGPT能够实现当前的交互,离不开OpenAI在AI预训练大模型领域的积累。
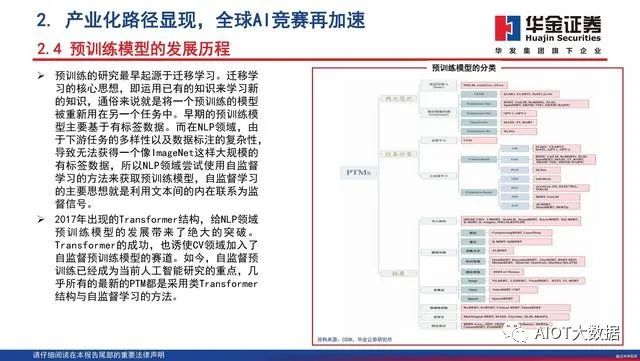
预训练模型的发展历程
预训练的研究最早起源于迁移学习。迁移学 习的核心思想,即运用已有的知识来学习新 的知识,通俗来说就是将一个预训练的模型 被重新用在另一个任务中。早期的预训练模 型主要基于有标签数据。而在NLP领域,由 于下游任务的多样性以及数据标注的复杂性, 导致无法获得一个像ImageNet这样大规模的 有标签数据,所以NLP领域尝试使用自监督 学习的方法来获取预训练模型,自监督学习 的主要思想就是利用文本间的内在联系为监 督信号。2017年出现的Transformer结构,给NLP领域 预训练模型的发展带来了绝大的突破。Transformer的成功,也诱使CV领域加入了 自监督预训练模型的赛道。如今,自监督预 训练已经成为当前人工智能研究的重点,几 乎所有的最新的PTM都是采用类Transformer 结构与自监督学习的方法。
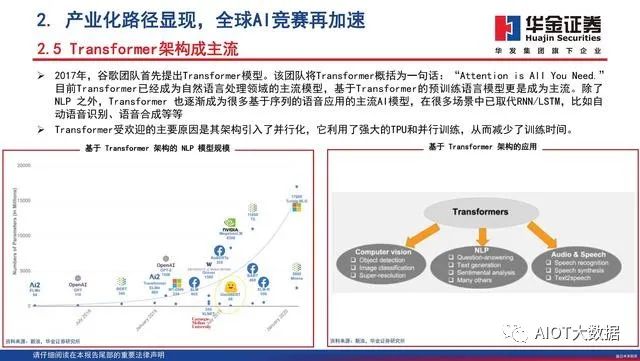
Transformer架构成主流
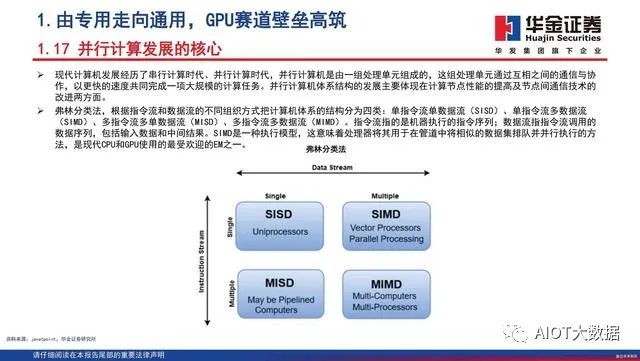
2017年,谷歌团队首先提出Transformer模型。该团队将Transformer概括为一句话:“Attention is AllYouNeed.”目前Transformer已经成为自然语言处理领域的主流模型,基于Transformer的预训练语言模型更是成为主流。除了NLP 之外,Transformer 也逐渐成为很多基于序列的语音应用的主流AI模型,在很多场景中已取代RNN/LSTM,比如自动语音识别、语音合成等等 。Transformer受欢迎的主要原因是其架构引入了并行化,它利用了强大的TPU和并行训练,从而减少了训练时间。
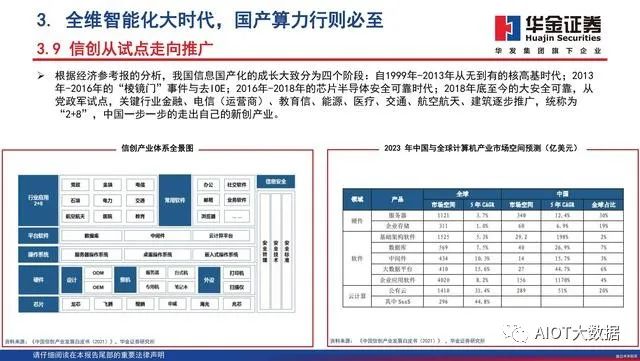
3. 全维智能化大时代,国产算力行则必至
全球数据中心负载任务量快速增长
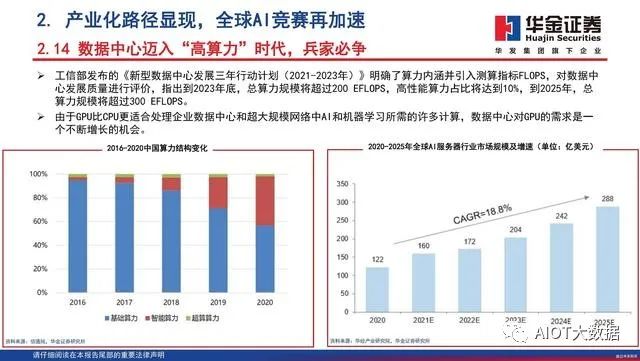
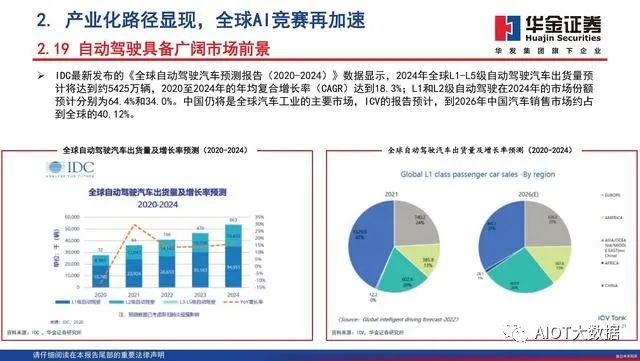
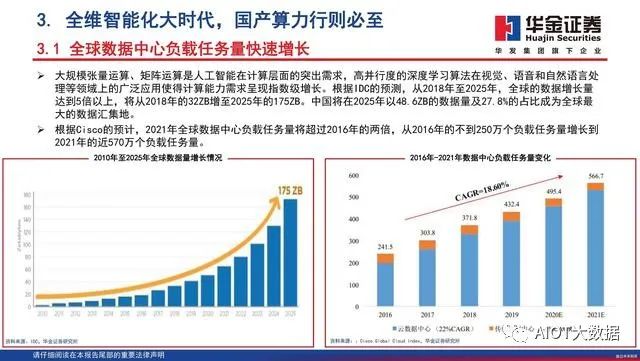
大规模张量运算、矩阵运算是人工智能在计算层面的突出需求,高并行度的深度学习算法在视觉、语音和自然语言处理等领域上的广泛应用使得计算能力需求呈现指数级增长。根据IDC的预测,从2018年至2025年,全球的数据增长量达到5倍以上,将从2018年的32ZB增至2025年的175ZB。中国将在2025年以48.6ZB的数据量及27.8%的占比成为全球最大的数据汇集地。根据Cisco的预计,2021年全球数据中心负载任务量将超过2016年的两倍,从2016年的不到250万个负载任务量增长到2021年的近570万个负载任务量。
全球计算产业投资空间巨大
根据《鲲鹏计算产业发展白皮书》内容显示,数字化浪潮正重塑世界经济格局,数字经济正在成为全球可持续增长的引擎。IDC预测,到2023年数字经济产值将占到全球GDP的62%,全球进入数字经济时代。新的计算产业链将推动全球计算产业快速发展,带动全球数字经济走向繁荣。IDC预测,到2023年,全球计算产业投资空间1.14万亿美元。中国计算产业投资空间1043亿美元,接近全球的10%,是全球计算产业发展的主要推动力和增长引擎。
预训练大模型对于GPU的需求
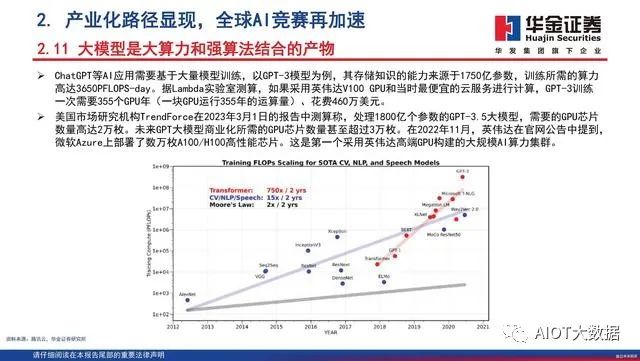
根据TrendForce的估计,2020年,GPT模型处理训练数据所需的GPU数量达到了20000左右。展望未来,GPT模型(或ChatGPT)商业化所需的GPU数量预计将达到30000个以上。这些均使用英伟达的A100 GPU作为计算基础。根据中关村在线的新闻显示,目前英伟达A100显卡的售价在1.00~1.50万美元之间。英伟达还将A100作为DGXA100系统的一部分进行销售,该系统具有八块A100,两块AMD Rome 7742 CPU,售价高达199,000美元。
国内市场需求将保持高增长
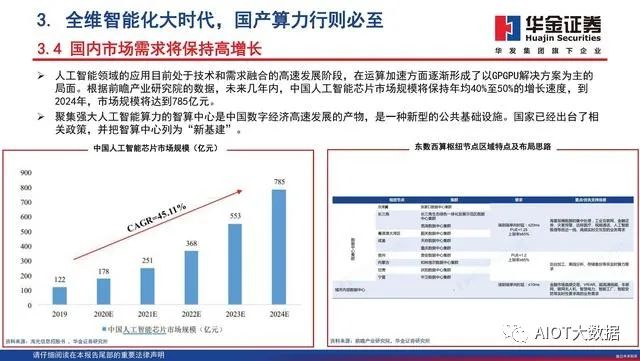
人工智能领域的应用目前处于技术和需求融合的高速发展阶段,在运算加速方面逐渐形成了以GPGPU解决方案为主的局面。根据前瞻产业研究院的数据,未来几年内,中国人工智能芯片市场规模将保持年均40%至50%的增长速度,到2024年,市场规模将达到785亿元。聚集强大人工智能算力的智算中心是中国数字经济高速发展的产物,是一种新型的公共基础设施。国家已经出台了相关政策,并把智算中心列为“新基建”。
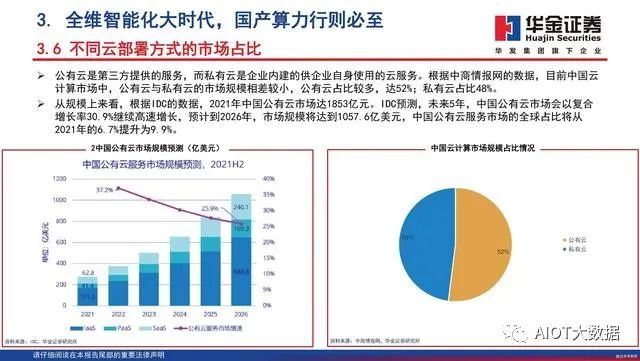
云计算及云部署方式
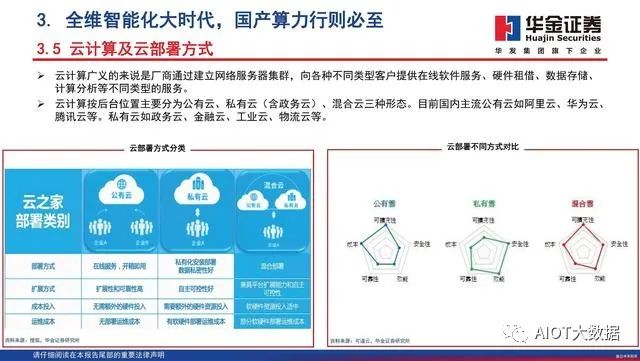
云计算广义的来说是厂商通过建立网络服务器集群,向各种不同类型客户提供在线软件服务、硬件租借、数据存储、计算分析等不同类型的服务。云计算按后台位置主要分为公有云、私有云(含政务云)、混合云三种形态。目前国内主流公有云如阿里云、华为云、腾讯云等。私有云如政务云、金融云、工业云、物流云等。
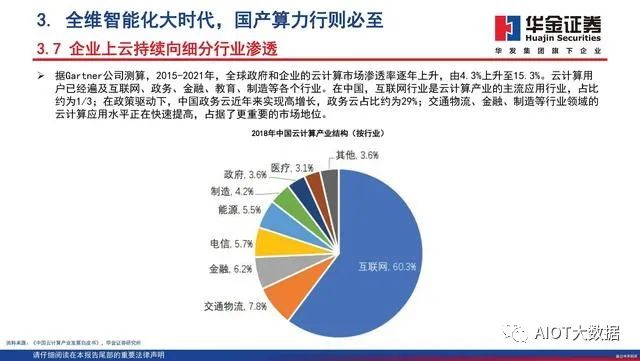
企业上云持续向细分行业渗透
据Gartner公司测算,2015-2021年,全球政府和企业的云计算市场渗透率逐年上升,由4.3%上升至15.3%。云计算用户已经遍及互联网、政务、金融、教育、制造等各个行业。在中国,互联网行业是云计算产业的主流应用行业,占比约为1/3;在政策驱动下,中国政务云近年来实现高增长,政务云占比约为29%;交通物流、金融、制造等行业领域的云计算应用水平正在快速提高,占据了更重要的市场地位。
4.重点公司分析
瑞芯微主要致力于大规模集成电路及应用方案的设计、开发和销售,在大规模SoC芯片设计、数模混合芯片设计、影像处理、高清视频编解码、人工智能及系统软件开发上具有丰富的经验和技术储备,形成了多层次、多平台、多场景的专业解决方案,赋能智能硬件、机器视觉、行业应用、消费电子、汽车电子等多元领域。公司产品涵盖智能应用处理器芯片、数模混合芯片、接口转换芯片、无线连接芯片及与自研芯片相关的模组产品等,并为客户提供技术服务。
晶晨股份
晶晨半导体是全球布局、国内领先的无晶圆半导体系统设计厂商,为智能机顶盒、智能电视、音视频系统终端、无线连接及车载信息娱乐系统等多个产品领域提供多媒体SoC芯片和系统级解决方案,业务覆盖全球主要经济区域,积累了全球知名的客户群。产品技术先进性和市场覆盖率位居行业前列,为智能机顶盒芯片的领导者、智能电视芯片的引领者和音视频系统终端芯片的开拓者。晶晨半导体拥有丰富的SoC全流程设计经验,坚持超高清多媒体编解码和显示处理、内容安全保护、系统IP等核心软硬件技术开发,整合业界领先的CPU/GPU技术和先进制程工艺,实现前所未有的成本、性能和功耗优化,提供基于多种开放平台的完整系统解决方案,帮助全球顶级运营商、OEM、ODM等客户快速部署市场。
星宸科技
公司为全球领先的视频监控芯片企业,主营业务为视频监控芯片的研发及销售,产品主要应用于智能安防、视频对讲、智能车载等领域。公司在芯片设计全流程具有丰富经验,可支撑大型先进工艺下的SoC设计。公司自研全套AI技术,包含AI处理器指令集、AI处理器IP及其编译器、仿真器等全套AI处理器工具链。公司拥有大量核心IP资源,包含图像IP、视频IP、高速模拟IP和音频IP等。公司在视频监控领域持续研发创新,在图像信号处理、音视频编解码、显示处理等领域具有领先优势,并积极投入AI等新领域的芯片研发。公司拥有ISP技术、AI处理器技术、多模视频编码技术、高速高精度模拟电路技术、先进制程SoC芯片设计技术等多项核心技术,公司拥有已授权专利92项,其中境内发明专利11项,境外专利81项;在申请中专利154项,其中境内发明专利63项,境外专利91项。
公司是领先的智能应用处理器SoC、高性能模拟器件和无线互联芯片设计厂商。公司目前的主营业务为系智能应用处理器SoC、高性能模拟器件和无线互联芯片的研发与设计。主要产品为智能应用处理器SoC、高性能模拟器件和无线互联芯片,产品广泛适用于智能硬件、平板电脑、智能家电、车联网、机器人、虚拟现实、网络机顶盒以及电源模拟器件、无线通信模组、智能物联网等多个产品领域。公司以客户为中心,凝聚卓越团队和坚持核心技术长期投入,在超高清视频编解码、高性能CPU/GPU/AI多核整合、先进工艺的高集成度、超低功耗、全栈集成平台等方面提供具有市场突出竞争力的系统解决方案和贴心服务。
报告节选:

























编辑:黄飞
















 工商网监
工商网监
评论