 电子发烧友App
电子发烧友App


AI 时代的曙光就在这里,了解 AI 驱动软件的成本结构与传统软件有很大差异至关重要。芯片微架构和系统架构在这些创新软件的开发和可扩展性方面发挥着至关重要的作用。运行软件的硬件基础设施对资本支出和运营支出以及随后的毛利率有明显更大的影响,这与前几代软件相比,前几代软件的开发人员成本相对较高。因此,更加重要的是要投入大量精力来优化您的 AI 基础设施,以便能够部署 AI 软件。在基础设施方面具有优势的公司在使用 AI 部署和扩展应用程序的能力方面也将具有优势。
谷歌早在 2006 年就提出了构建 AI 专用基础设施的想法,但这个问题在 2013 年达到了定点。他们意识到,如果他们想以任何规模部署 AI,就需要将现有数据中心的数量增加一倍。因此,他们开始为 2016 年投入生产的 TPU 芯片奠定基础。将此与亚马逊进行比较很有趣,亚马逊在同一年意识到他们也需要构建定制芯片。
自 2016 年以来,谷歌现已构建了 6 种不同的 AI 芯片,TPU、TPUv2、TPUv3、TPUv4i、TPUv4 和 TPUv5。谷歌主要设计了这些芯片,并与博通进行了不同程度的中后端合作。这些芯片全部由台积电代工。自 TPUv2 以来,这些芯片还使用了三星和 SK 海力士的 HBM 内存。虽然谷歌的芯片架构很有趣,我们将在本报告的后面深入探讨,但还有一个更重要的话题在起作用。
谷歌拥有近乎无与伦比的能力,能够以低成本和高性能可靠地大规模部署人工智能。话虽如此,让我们为这个论点带来一些合理性,因为谷歌也做出了与芯片级性能相关的虚伪声明,需要纠正。我们认为,由于谷歌从微架构到系统架构的整体方法,与微软和亚马逊相比,谷歌在 AI 工作负载方面具有性能/总拥有成本 (perf/TCO) 优势,而将生成人工智能商业化给企业和消费者的能力是一个不同的讨论。
技术领域是一场永无休止的军备竞赛,人工智能是移动最快的战场。随着时间的推移,经过训练和部署的模型架构发生了显着变化。案例和重点是谷歌的内部数据。CNN 模型在 2016 年到 2019 年迅速上升,但随后又下降了。与 DLRM、Transformers 和 RNN 相比,CNN 在计算、内存访问、网络等方面具有非常不同的配置文件。同样的情况也发生在完全被 Transformer 取代的 RNN 上。
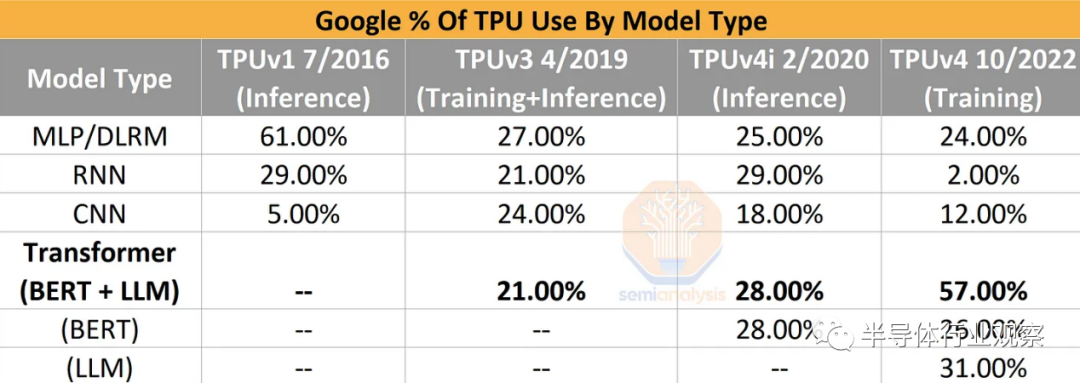
因此,硬件必须灵活地适应行业的发展并支持它们。底层硬件不能过度专注于任何特定的模型架构,否则它可能会随着模型架构的变化而变得过时。芯片开发到大规模部署一般需要 4 年时间,因此,硬件可以被软件想在其上做的事情抛在脑后。这已经可以从使用特定模型类型作为优化点的初创公司的某些 AI 加速器架构中看出。这是大多数 AI 硬件初创公司已经/将要失败的众多原因之一。
这一点在谷歌自己的 TPUv4i 芯片上尤为明显,该芯片专为推理而设计,但无法在谷歌最好的模型(如 PaLM)上运行推理。上一代 Google TPUv4 和 Nvidia A100 不可能在设计时考虑到大型语言模型。同样,最近部署的谷歌 TPUv5 和 Nvidia H100 不可能在设计时考虑到”AI墙”,也没有为解决它而开发的新模型架构策略。这些策略是 GPT-4 模型架构的核心部分。
硬件架构师必须对机器学习在他们设计的芯片中的发展方向做出最好的猜测。这包括内存访问模式、张量大小、数据重用结构、算术密度与网络开销等。
此外,芯片微架构只是人工智能基础设施真实成本的一小部分。系统级架构和部署灵活性是更为重要的因素。今天,我们想深入探讨 Google 的 TPU 微架构、系统架构、部署切片、可扩展性,以及他们在基础设施方面与其他技术巨头相比的巨大优势。这包括我们在 TCO 模型中的想法,该模型将 Google 的 AI 基础设施成本与 Microsoft、Amazon 和 Meta 的成本进行比较。
我们还将从从业者的角度对大型模型研究、训练和部署进行研究。我们还想深入研究 DLRM 模型,尽管目前是最大的大规模 AI 模型架构,但这些模型经常被低估。此外,我们将讨论 DLRM 和 LLM 模型类型之间的基础设施差异。最后,我们将讨论谷歌利用 TPU 为外部云客户取得成功的能力。同样在最后,我们认为谷歌的 TPU 有一个异常的复活节彩蛋是一个错误。
谷歌的系统基础设施优势
谷歌在基础设施方面的部分优势在于,他们始终从系统级的角度设计 TPU。这意味着单个芯片很重要,但如何在现实世界的系统中一起使用它更为重要。因此,在我们的分析中,我们将逐层从系统架构到部署使用再到芯片级别。
虽然从系统的角度思考,但他们的系统规模比谷歌更小、更窄。此外,直到最近,Nvidia 还没有云部署方面的经验。谷歌在其 AI 基础设施方面最大的创新之一是在 TPU、ICI 之间使用自定义网络堆栈。相对于昂贵的以太网和 InfiniBand 部署,此链接具有低延迟和高性能。它更类似于 Nvidia 的 NVLink。
谷歌的 TPUv2 可以扩展到 256 个 TPU 芯片,与 Nvidia 当前一代 H100 GPU 的数量相同。他们使用 TPUv3 将这个数字增加到 1024,使用 TPUv4 增加到 4096。根据趋势线,我们假设当前一代 TPUv5 可以扩展到 16,384 个芯片,而无需通过低效的以太网。虽然从大规模模型训练的性能角度来看这很重要,但更重要的是他们将其划分以供实际使用的能力。

谷歌的 TPUv4 系统每台服务器有 8 个 TPUv4 芯片和 2 个 CPU。此配置与 Nvidia 的 GPU 相同,后者配备 8 个 A100 或 H100 服务器,每台服务器 2 个 CPU。单个服务器通常是 GPU 部署的计算单元,但对于 TPU,部署单元是更大的“slice”,由 64 个 TPU 芯片和 16 个 CPU 组成。这 64 个芯片通过直接连接的铜缆在 4^3 立方体中与 ICI 网络内部连接。

在这个 64 芯片单元之外,通信转而转移到光学领域。这些光收发器的成本是无源铜缆的 10 倍以上。
将此与 2023 Nvidia SuperPod 部署进行比较,后者使用 NVLink 最多配备 256 个 GPU,仅为 4096 的芯片的 2020 TPUv4 pod 的十六分之一。此外,基于 Nvidia 的第一方渲染和 DGX Superpod 系统,Nvidia 显然不太关注密度和网络成本。Nvidia 的部署通常是每个机架 4 个服务器。
除了 4 台服务器总共 32 个 GPU 之外,通常,通信必须采用光学方式。因此,Nvidia 需要更多的光收发器来进行大规模部署。
谷歌OCS
谷歌部署了其定制光开关,它使用基于 mems 的微镜阵列阵列在 64 个 TPU slice之间切换。简短的总结是,谷歌声称他们的自定义网络将吞吐量提高了 30%,使用的电力减少了 40%,资本支出减少了 30%,流程完成减少了 10%,并且在他们的网络中减少了 50 倍的停机时间,
谷歌使用这些 OCS 来构建其数据中心主干。他们还使用它们将 TPU pod 互连和内部连接在一起。此 OCS 的一大优势是信号仅保留在光域中,从任何 64 TPU slice到 4096 TPU Pod 内的任何其他 TPU slice。
将此与具有多个 Nvidia SuperPods 的 4,096 个 GPU 的 Nvidia GPU 部署进行比较。该系统需要在这些 GPU 之间进行多层切换,总共需要约 568 个 InfiniBand 交换机。谷歌只需要 48 个光开关来部署 4096 个 TPU。
应该注意的是,与第三方从 Nvidia 购买 Nvidia 的 InfiniBand 交换机相比,直接从 Google 的合同制造商处购买时, Google 的 OCS每个交换机的价格也高出 3.2 到 3.5 倍。不过,这不是一个公平的比较,因为它包括 Nvidia 约 75% 的数据中心毛利率。
如果我们只比较合同制造成本,谷歌的 IE 成本与 Nvidia 的成本;然后成本差异上升到 Nvidia InfiniBand 交换机的 12.8 到 14 倍。部署4096芯片所需的交换机数量为48 vs 568,IE为11.8x。Nvidia 的解决方案在交换机基础上的制造成本更低。当包括额外的光收发器的成本时,这个等式趋于平衡或向有利于谷歌的方向移动。
每层交换之间的每个连接都是另一个需要更多布线的点。虽然其中一些可以通过直接连接的铜缆完成,但仍有多个点的信号也需要通过光纤传输。这些层中的每一层都会在每一层切换之间从电转换为光再转换为电。这将使大型电气开关系统的功耗远高于谷歌的OCS。
谷歌声称所有这些功率和成本的节省都非常大,以至于它们的网络成本不到 TPU v4 超级计算机总资本成本的 5% 和总功率的不到 3%。这不仅仅是通过从电气开关转向内部光开关来实现的。
通过拓扑最小化网络成本
虽然谷歌大力推动这一观点,但重要的是要认识到 Nvidia 和 Nvidia 网络的拓扑结构完全不同。Nvidia 系统部署了“non-blocking”的“Clos 网络”。这意味着它们可以同时在所有输入和输出对之间建立全带宽连接,而不会发生任何冲突或阻塞。此设计提供了一种可扩展的方法,用于连接数据中心中的许多设备、最大限度地减少延迟并增加冗余。
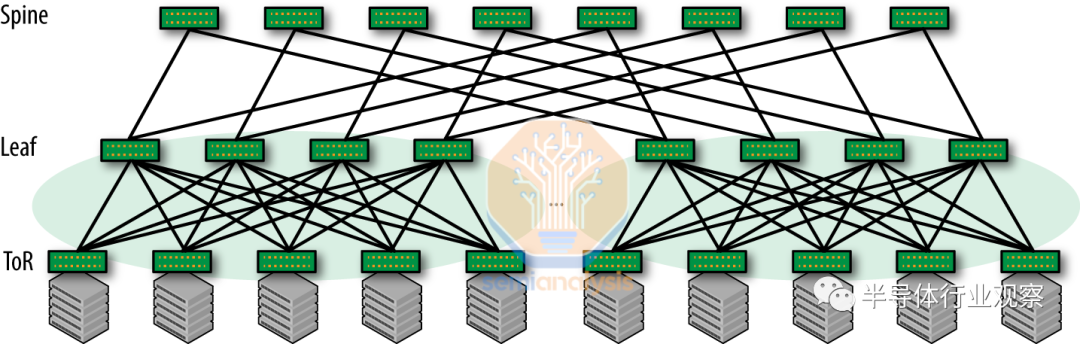
谷歌的 TPU 网络放弃了这一点。他们使用 3D 环面拓扑连接三维网格状结构中的节点。每个节点都连接到网格中的六个相邻节点(上、下、左、右、前和后),在三个维度(X、Y 和 Z)中的每一个维度上形成一个闭环。这创建了一个高度互连的结构,其中节点在所有三个维度上形成一个连续的循环。

第一张图比较合乎逻辑,但如果你想一想有点饿了,这个网络拓扑简直就是一个甜甜圈!

与 Nvidia 使用的 Clos 拓扑相比,torus 拓扑有几个优点:
更低的延迟:3D 环面拓扑可以提供更低的延迟,因为它在相邻节点之间有短而直接的链接。这在运行需要节点之间频繁通信的紧密耦合的并行应用程序时特别有用,例如某些类型的 AI 模型。
更好的局部性:在 3D 环面网络中,物理上彼此靠近的节点在逻辑上也很接近,这可以带来更好的数据局部性并减少通信开销。虽然延迟是一个方面,但功耗也是一个巨大的好处。
较低的网络直径:对于相同数量的节点,3D 环面拓扑的网络直径低于 Clos 网络。由于相对于 Clos 网络需要更少的交换机,因此可以节省大量成本。
另一方面,3D 环面网络有很多缺点。
可预测的性能:Clos 网络,尤其是在数据中心环境中,由于其非阻塞特性,可以提供可预测和一致的性能。它们确保所有输入输出对都可以在全带宽下同时连接,而不会发生冲突或阻塞,而这在 3D 环面网络中是无法保证的。
更易于扩展:在脊叶(spine-leaf )架构中,向网络添加新的叶交换机(例如,以容纳更多服务器)相对简单,不需要对现有基础设施进行重大更改。相比之下,缩放 3D 环面网络可能涉及重新配置整个拓扑,这可能更加复杂和耗时。
负载平衡:Clos 网络在任意两个节点之间提供更多路径,从而实现更好的负载平衡和冗余。虽然 3D 环面网络也提供多条路径,但 Clos 网络中的备选路径数量可能更多,具体取决于网络的配置。
总的来说,虽然 Clos 有优势,但谷歌的 OCS 减轻了其中的许多优势。OCS 支持在多个切片和多个 pod 之间进行简单缩放。
3D 环面拓扑面临的最大问题是错误可能是一个更大的问题。错误可能会突然出现并发生。即使主机可用性为 99%,2,048 个 TPU 的幻灯片也将具有接近 0 的正常工作能力。即使在 99.9% 的情况下,使用 2,000 个 TPU 运行的训练在没有 Google 的 OCS 的情况下也有 50% 的有效输出。
OCS 的美妙之处在于它支持动态重新配置路由。
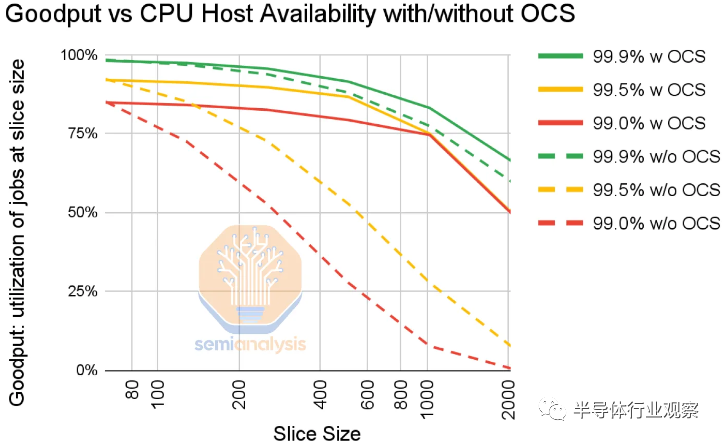
尽管有一些节点出现故障,但仍需要备件以允许调度作业。操作员无法在不冒失败风险的情况下从 4k 节点 pod 实际调度两个 2k 节点切片。基于 Nvidia 的训练运行通常需要过多的开销,专门用于检查点、拉出故障节点并重新启动它们。谷歌通过绕过故障节点路由在某种程度上简化了这一点。
OCS 的另一个好处是切片可以在部署后立即使用,而不是等待整个网络。
部署基础设施——用户的视角
从成本和功耗的角度来看,基础设施效率很高,允许谷歌每美元部署更多的 TPU,而不是其他公司可以部署的 GPU,但这意味着没有任何用处。谷歌内部用户体验到的最大优势之一是他们可以根据自己的模型定制基础设施需求。
没有任何芯片或系统能够匹配所有用户想要的内存、网络和计算配置文件类型。芯片必须通用化,但与此同时,用户需要这种灵活性,他们不想要一种放之四海而皆准的解决方案。Nvidia 通过提供许多不同的 SKU 变体来解决这个问题。此外,它们还提供一些不同的内存容量层级以及更紧密的集成选项,例如 Grace + Hopper 和为SuperPods准备的 NVLink Network。
谷歌负担不起这种奢侈。每个额外的 SKU 意味着每个单独 SKU 的总部署量较低。这反过来又降低了他们整个基础设施的利用率。更多的 SKU 也意味着用户更难在需要时获得他们想要的计算类型,因为某些选项将不可避免地被超额订阅。然后,这些用户将被迫使用次优配置。
因此,谷歌面临着一个棘手的问题,即向研究人员提供他们想要的确切产品,同时还要最大限度地减少 SKU 差异。与 Nvidia 必须支持其更大、更多样化的客户群的数百种不同规模的部署和 SKU 相比,谷歌恰好有 1 个 TPUv4 部署配置,即 4,096 个 TPU。尽管如此,谷歌仍然能够以一种独特的方式对其进行slice和切块,使内部用户能够拥有他们想要的基础设施的灵活性。
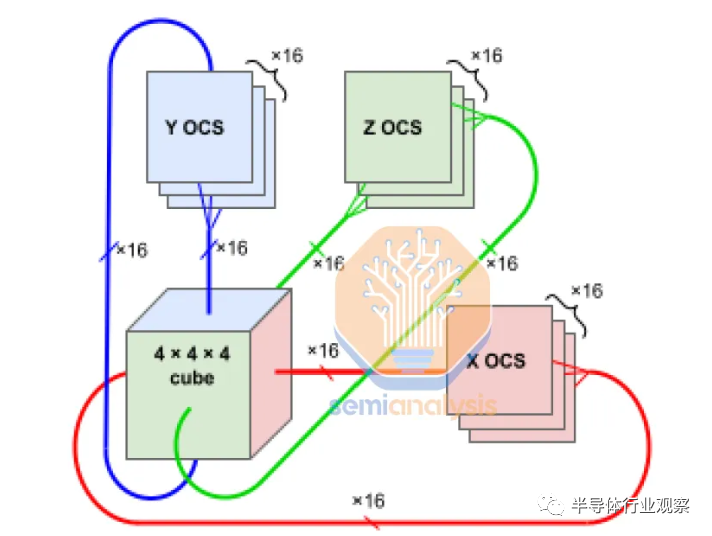
Google 的 OCS 还支持创建自定义网络拓扑,例如扭曲环面网络。这些是 3d 环面网络,其中某些维度是扭曲的,这意味着网络边缘的节点以非平凡、非线性的方式连接,从而在节点之间创建额外的捷径。这进一步提高了网络直径、负载平衡和性能。
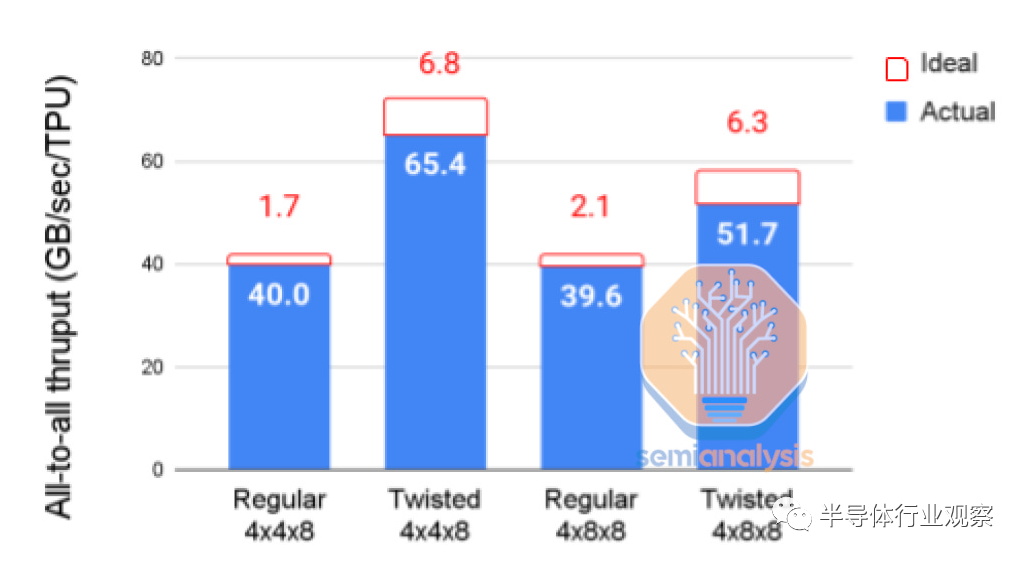
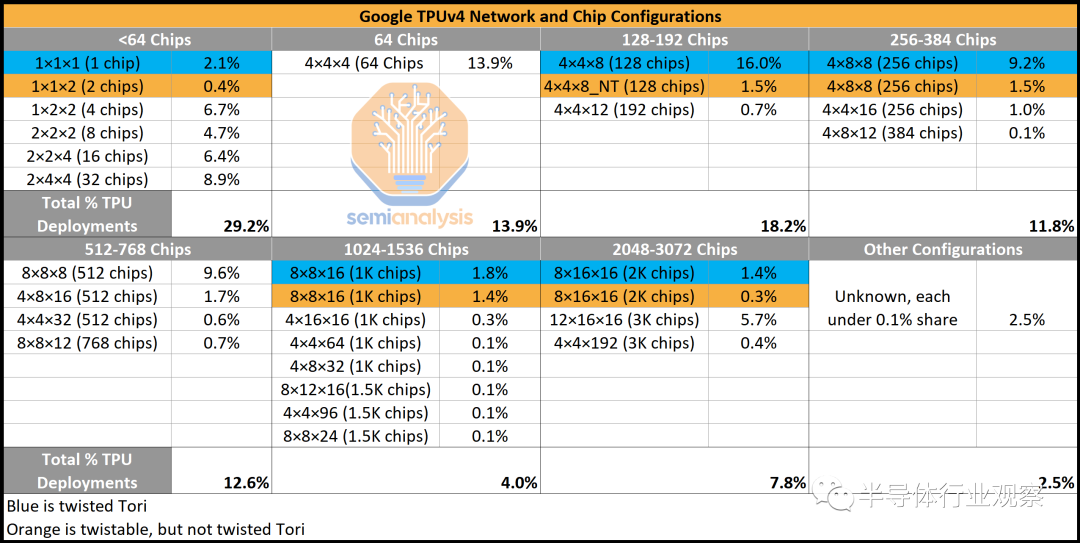
谷歌的团队充分利用这一点来协助某些模型架构。以下是 2022 年 11 月仅 1 天的各种 TPU 配置的流行情况快照(按芯片数量和网络拓扑)。有 30 多种不同的配置,尽管许多配置在系统中具有相同数量的芯片,以适应正在开发的各种模型架构。这是谷歌对他们使用 TPU 和灵活性的巨大深刻见解。此外,它们还有许多甚至未被描绘的较少使用的拓扑。
为充分利用可用带宽,用户沿 3D 环面的一个维度映射数据并行性,并在其他维度上映射两个模型并行参数。谷歌声称最佳拓扑选择可以使性能提高 1.2 到 2.3 倍。
规模最大的 AI 模型架构:DLRM
如果不讨论深度学习推荐模型 (DLRM),任何关于 AI 基础设施的讨论都是不完整的。这些 DLRM 是百度、Meta、字节跳动、Netflix 和谷歌等公司的支柱。它是广告、搜索排名、社交媒体订阅等领域年收入超过 1 万亿美元的引擎。这些模型包含数十亿个权重,对超过一万亿个示例进行训练,
以每秒超过 300,000 个查询的速度处理推理。这些模型的大小 (10TB+) 甚至远远超过了最大的transformer模型,例如 GPT4,大约为 1TB+(模型架构差异)。
上述所有公司的共同点是,它们依靠不断更新的 DLRM 来推动其在电子商务、搜索、社交媒体和流媒体服务等各个行业中的个性化内容、产品或服务业务。这些模型的成本是巨大的,必须针对它共同优化硬件。DLRM 并不是一成不变的,而是随着时间的推移不断改进,但在继续之前让我们先解释一下通用模型架构。我们将尽量保持简单。
DLRM 旨在通过对分类和数值特征进行建模来学习用户-项目交互的有意义的表示。该架构由两个主要组件组成:嵌入组件(处理分类特征)和多层感知器 (MLP) 组件(处理数字特征)。
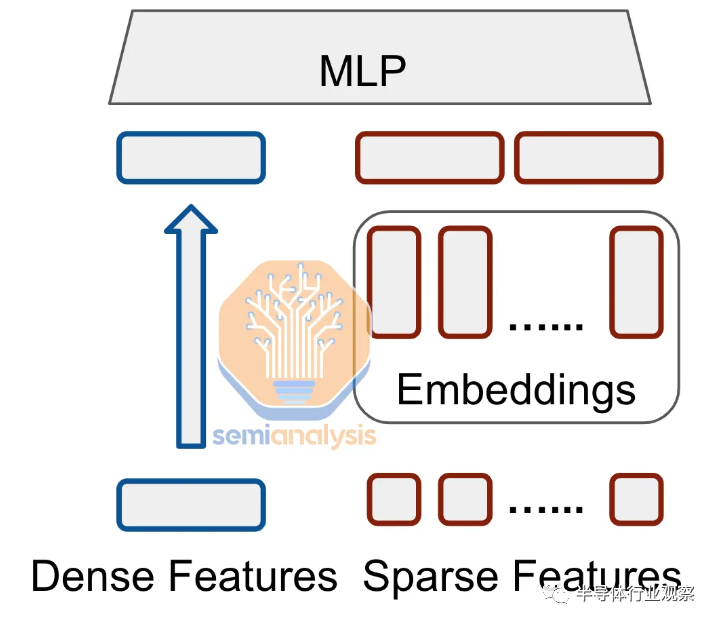
用最简单的术语来说, the 多层感知器组件是密集的。这些特征被馈送到一系列完全连接的层中。这类似于旧的 GPT 4 之前的transformer架构,它们也是密集的,密集层可以很好地映射到硬件上的大规模矩阵多单元。
嵌入组件对于 DLRM 来说是非常独特的,也是使其计算配置文件如此独特的组件。DLRM 输入是表示为离散、稀疏向量的分类特征。一个简单的谷歌搜索只包含整个语言中的几个词。这些稀疏输入不能很好地映射到硬件中的大量矩阵乘法单元,因为它们从根本上更类似于哈希表,而不是张量。由于神经网络通常在密集向量上表现更好,因此使用嵌入将分类特征转换为密集向量。
稀疏输入:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
密集向量:[0.3261477, 0.4263801, 0.5121493]
嵌入函数将分类空间(英语单词、社交媒体帖子的参与度、对某种帖子的行为)映射到更小的密集空间(100 个向量代表每个单词)。这些功能是使用查找表实现的,查找表是 DLRM 的重要组成部分,通常构成 DLRM 模型的第一层。嵌入表的大小可以有很大的不同,从几十兆字节到几百千兆字节甚至 TB 不等。
Meta 推出 2 年的 DLRM 参数超过 12 万亿个,需要 128 个 GPU 来运行推理。如今,最大的生产 DLRM 模型至少大了好几倍,并且仅仅为了保存模型嵌入就消耗了超过 30TB 的内存。预计明年嵌入量会增加到 70TB 以上!因此,这些表需要在许多芯片的内存中进行分区。共有三种主要的分区方法:列分片(column sharding)、行分片(row sharding)和表分片(table sharding)。
DLRM 的性能在很大程度上取决于内存带宽、内存容量、矢量处理性能以及芯片之间的网络/互连。嵌入查找操作主要由小的收集或分散内存访问组成,这些访问具有低算术强度(FLOPS 根本无关紧要)。对嵌入表的访问基本上是非结构化的稀疏性。每个查询都必须从 30TB 以上的嵌入中提取数据,这些嵌入分布在数百或数千个芯片上。这会导致用于 DLRM 推理的超级计算机的计算、内存和通信负载不平衡。
这对于 MLP 和类似 GPT-3 的转换器中的密集操作有很大不同。 芯片 FLOPS/秒仍然是主要性能驱动因素之一当然,除了 FLOPs 之外beyond FLOPs还有多种因素阻碍性能,但 仍然可以在 Chinchilla 风格的 LLM 中实现超过 71% 的硬件触发器利用率。
谷歌的 TPU 架构
谷歌的 TPU 在架构中引入了一些关键创新,使其有别于其他处理器。与传统处理器不同,TPU v4 没有专用的指令缓存。相反,它采用类似于 Cell 处理器的直接内存访问 (DMA) 机制。TPU v4 中的矢量缓存不是标准缓存层次结构的一部分,而是用作暂存器。便签本与标准缓存的不同之处在于它们需要手动写入,而标准缓存会自动处理数据。由于不需要服务于大型通用计算市场,谷歌可以利用这种更高效的基础设施。这确实会在一定程度上影响编程模型,尽管 Google 工程师认为 XLA 编译器堆栈可以很好地处理这个问题。对于外部用户则不能这样说。
TPU v4 拥有用于暂存器的 160MB SRAM 以及 2 个 TensorCore,每个 TensorCore 都有 1 个向量单元和 4 个矩阵乘法单元 (MXU) 和 16MB 向量内存 (VMEM)。两个 TensorCore 共享 128MB 内存。它们支持 BF16 的 275 TFLOPS,还支持 INT8 数据类型。TPU v4 的内存带宽为 1200GB/s。芯片间互连 (ICI) 通过六个 50GB/s 链路提供 300GB/s 的数据传输速率。
TPU v4 中包含一个 322b 超长指令字 (VLIW) 标量计算单元。在 VLIW 架构中,指令被组合成一个单一的长指令字,然后被分派到处理器执行。这些分组指令,也称为束,在程序编译期间由编译器显式定义。VLIW 包包含多达 2 条标量指令、2 条矢量 ALU 指令、1 条矢量加载和 1 条矢量存储指令,以及 2 个用于将数据传入和传出 MXU 的插槽。
Vector Processing Unit (VPU) 配备了 32 个 2D 寄存器,包含 128x 8 个 32b 元素,使其成为一个 2D 矢量 ALU。矩阵乘法单元 (MXU) 在 v2、v3 和 v4 上为 128x128,v1 版本采用 256x256 配置。发生这种变化的原因是谷歌模拟了四个 128x128 MXU 的利用率比一个 256x256 MXU 高 60%,但四个 128x128 MXU 占用的面积与 256x256 MXU 相同。MXU 输入使用 16b 浮点 (FP) 输入并使用 32b 浮点 (FP) 进行累加。
这些更大的单元允许更有效的数据重用以突破内存墙。
谷歌 DLRM 优化
谷歌是最早开始在其搜索产品中大规模使用 DLRM 的公司之一。这种独特的需求导致了一个非常独特的解决方案。上述架构的主要缺陷在于它无法有效处理 DLRM 的嵌入。Google 的主要 TensorCore 非常大,与这些嵌入的计算配置文件不匹配。谷歌必须在他们的 TPU 中开发一种全新类型的“SparseCore”,它不同于上面描述的用于密集层的“TensorCore”
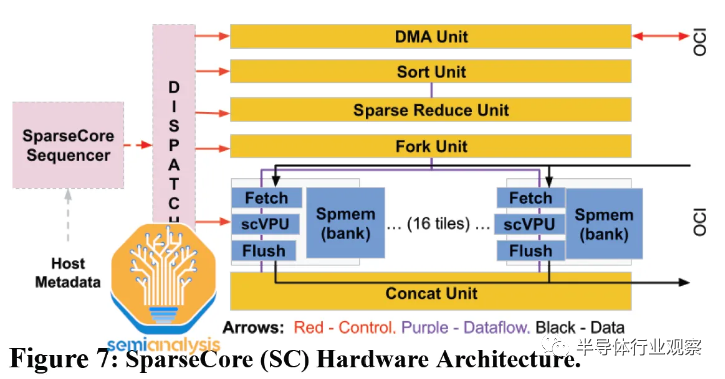
SparseCore (SC) 为 Google 的 TPU 中的嵌入提供硬件支持。早在 TPU v2 中,这些特定领域的处理器就有直接绑定到每个 HBM 通道/子通道的块。它们加速了训练深度学习推荐模型 (DLRM) 中内存带宽最密集的部分,同时仅占用大约 5% 的芯片面积和功率。通过在每个 TPU v4 芯片而非 CPU 上使用快速的 HBM2 进行嵌入,与将嵌入留在主机 CPU 的主内存上相比,谷歌展示了其内部生产 DLRM 的 7 倍加速(TPU v4 SparseCore vs TPU v4 Embeddings on Skylake-SP )。
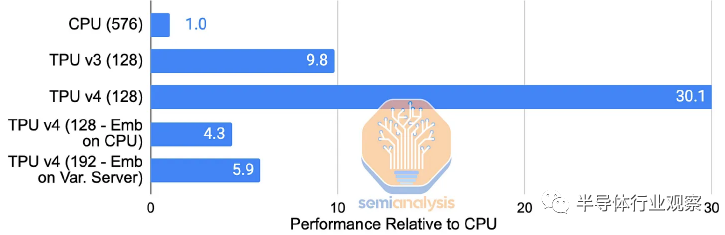
SparseCore 支持从 HBM 进行快速内存访问,使用专用的获取、处理和刷新单元将数据移动到稀疏向量内存 (Spmem) 的组,并由可编程的 8 宽 SIMD 向量处理单元 (scVPU) 更新。这些单元的 16 个计算块进入一个 SparseCore。
额外的跨通道单元执行特定的嵌入操作(DMA、排序、稀疏减少、分叉、连接)。每个 TPU v4 芯片有 4 个 SparseCore,每个有 2.5MB 的 Smem。展望未来,我们推测由于 HBM3 上子通道数量的增加,TPUv5 的 SparseCores 数量将继续增加到 6,tiles数量将增加到 32。
虽然迁移到 HBM 带来的性能提升是巨大的,但性能扩展仍然受到互连对分带宽的影响。TPU v4 中 ICI 的新 3D 环面有助于进一步扩展嵌入查找性能。然而,当扩展到 1024 个芯片时,由于 SparseCore 开销成为瓶颈,改进会下降。
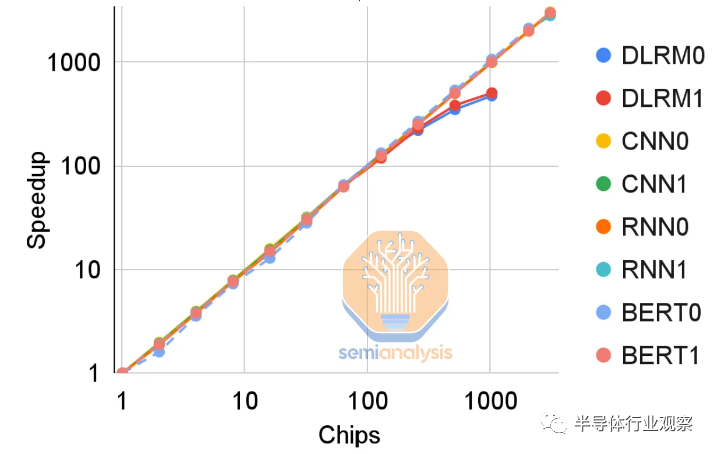
如果谷歌认为他们的 DLRM 需要增加超过约 512 个芯片的大小和容量,这个瓶颈可能会导致每个图块的 Smem 也随着 TPUv5 增加。
编辑:黄飞














 工商网监
工商网监
评论