 电子发烧友App
电子发烧友App


本文首先通过字节跳动人工智能实验室的一些研究成果介绍最前沿的人工智能技术,总结这一两年来人工智能领域的研究发展动态。之后本文分享了对人工智能领域长期发展的看法。
前言
冯 · 诺伊曼的《计算机和人脑》是人类历史上第一部将计算机和人脑相提并论的著作。这位科学巨人希望比较计算机和人脑的计算机制,为未来建立统一的计算理论打下基础。事实上,建立计算机和人脑的统一计算理论是冯 · 诺伊曼晚年研究的主要课题。他所关注的统一计算理论应该也是人工智能领域的核心问题。站在人工智能的角度,人脑是智能系统的代表,应该从人脑的计算机制得到启发,开发出未来的智能计算理论和方法。
本文首先通过字节跳动人工智能实验室的一些研究成果介绍最前沿的人工智能技术,总结这一两年来人工智能领域的研究发展动态。之后分享我们对人工智能领域长期发展的看法。主张人工智能的未来需要新的计算范式和新的计算理论。具体地,脑启发计算(brain-inspired computing)应是重要的探索方向;从信息、数据、模型角度的学习理论研究至关重要。
人工智能的最新动态
这一两年来人工智能特别是深度学习的研究又有了令人瞩目的进展。主要体现在几个方面。Transformer 模型及其变种被广泛应用到各个领域,包括语言、语音、图像。人工智能各个子领域的差异更多地体现在数据和应用问题上,使用的模型和算法趋于相同。基于大数据的模型预训练或自监督学习被广泛使用,成为各个领域学习和推理的基础。深度学习实现的是类推推理,如何实现逻辑推理也成为研究的重要课题。人工智能技术被广泛应用到各个领域,在实际应用中的可信赖 AI 问题也成为关注的焦点,包括深度学习的可解释性,公平性等。深度学习技术也被推广应用到其他领域,典型的是科学智能(AI for Science),即用深度学习技术解决物理、化学、生物、医药学问题的新方向。总结趋势如下。
·Transformer 模型一统天下
·视觉、听觉、语言处理的区别更多在于数据
·预训练、自监督学习越加重要
·从类推推理到逻辑推理
·可信赖的 AI 广受关注
·扩展到科学智能等新领域
字节跳动人工智能实验室在进行自然语言处理、语音处理、计算机视觉、科学智能、机器人,机器学习公平性等各个领域的技术研究和开发。这里介绍几个今年发表的工作,以展示人工智能最近的发展动向。具体概述非自回归模型 DA-Transformer,端到端语音到文本翻译模型 ConST,多颗粒度的视觉语言模型 X-VLM,图片和文本统一生成模型 DaVinci,语言理解模型 Neural Symbolic Processor。
更快的 Transformer 模型
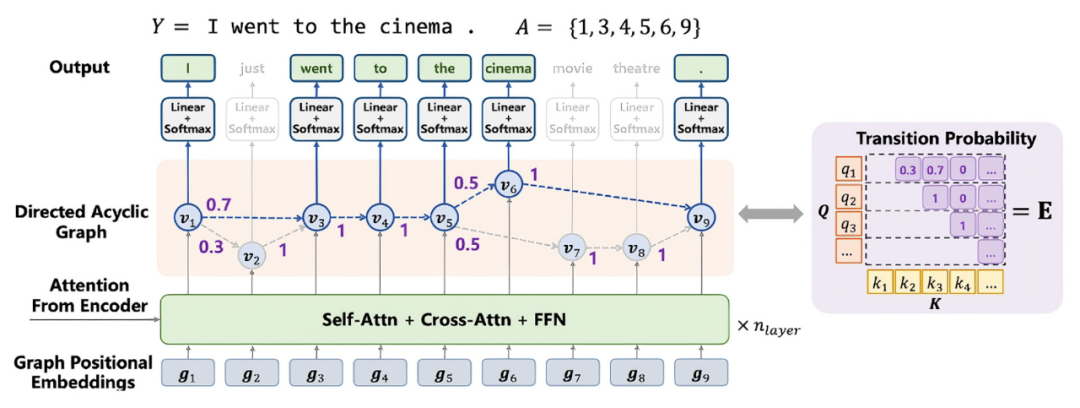
图 1 DA-Transformer 的架构
Transformer 最初作为机器翻译模型被提出,后来被广泛应用于人工智能各个领域。Transformer 的一个大问题是解码基于自回归,计算需要一环扣一环地进行,速度比较慢。为解决这个问题,非自回归模型成为最近研究的一个热点。目前为止提出的非自回归模型在机器翻译的精度上没有能够与原始的 Transformer 匹敌。我们提出的 DA-Transformer 在机器翻译上首次达到了 Transformer 同样的精度,而处理的速度提高了 7~14 倍[1]。DA-Transformer 不仅可以用于机器翻译,而且可以用于任意的序列到序列任务。
DA-Transformer (Directed Acyclic Graph Transformer)的核心想法是在解码层的最后一层构建有向无环图,如图 1 所示。有向无环图的结点表示生成翻译(目标语言句子)的状态,边表示状态之间的转移。边上有状态转移概率,结点上有表示向量,生成目标语言单词。解码器的输入是目标语言单词的位置的索引。有向无环图的结点对应着解码器的输入,有向边只能是从前面的位置指向后面的位置。有向无环图的从起始位置到终止位置的一条路径,对应着一个翻译状态的序列,在一条路径上可以产生目标语言句子(单词的序列)。其他部分的结构与 Transformer 相同。
DA-Transformer 的解码是基于并行处理的。在解码器输入的各个位置上进行并行计算,得到解码器最后一层的有向无环图的结点上的表示向量。在此基础上计算各个边上的转移概率,从每个位置出发到达其之后位置的转移概率是归一的。这个过程的计算速度非常快。DA-Transformer 的训练也是基于翻译数据进行极大似然估计。这时一个翻译(目标语言句子)可以由有向无环图的多条路径产生,翻译的生成概率要对所有的路径求和。使用动态规划可以高效地完成一个翻译概率(似然函数)的计算。DA-Transformer 的推理可以使用多个算法。最简单的贪心算法从起始位置开始从左到右动态递归地计算到每个位置概率最大的翻译,直到生成句子终止符为止。
语言和语音的融合
ConST
传统的语音到文本的翻译是通过语音识别和文本机器翻译的串联实现。这个方法的缺点是推理过程中的错误会累加。ConST 可以直接将英语的语音翻译成中文的文本,而且在语音到文本的翻译中,达到了 SOTA(state of the art)的效果[2]。
ConST 的架构由 Transformer 的编码器和解码器组成(见图 2)。编码器既可以接受语音输入又可以接受文本输入。输入是语音时有特殊的前处理模块,使用 wave2vec2 和 CNN。输入是文本时处理跟一般的 Transformer 相同。用同一个系统实现语音到文本的语音识别,文本到文本的机器翻译,语音到文本的语音翻译。训练时进行语音识别、文本翻译、语音翻译的多任务学习。ConST 的最大特点是,使用对比学习将语义相同的语音输入的表示和文本输入的表示拉近。可以理解为对表示学习进行了正则化。图 2 的下图左边直观说明没有使用对比学习的表示,右边直观说明使用了对比学习之后的表示。
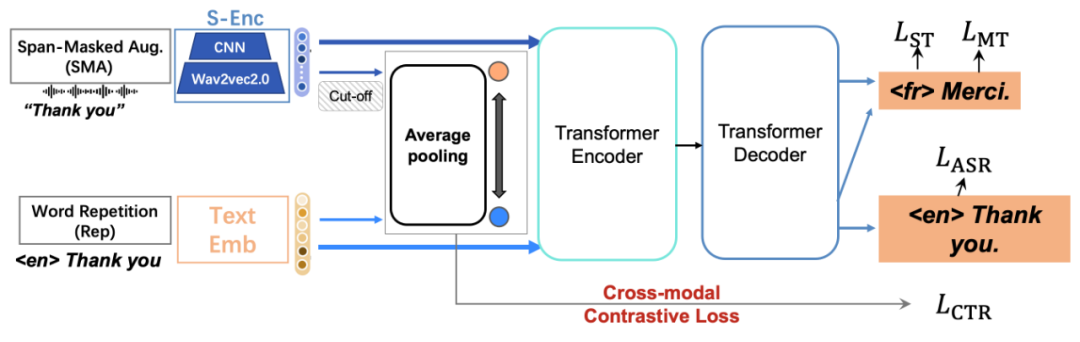
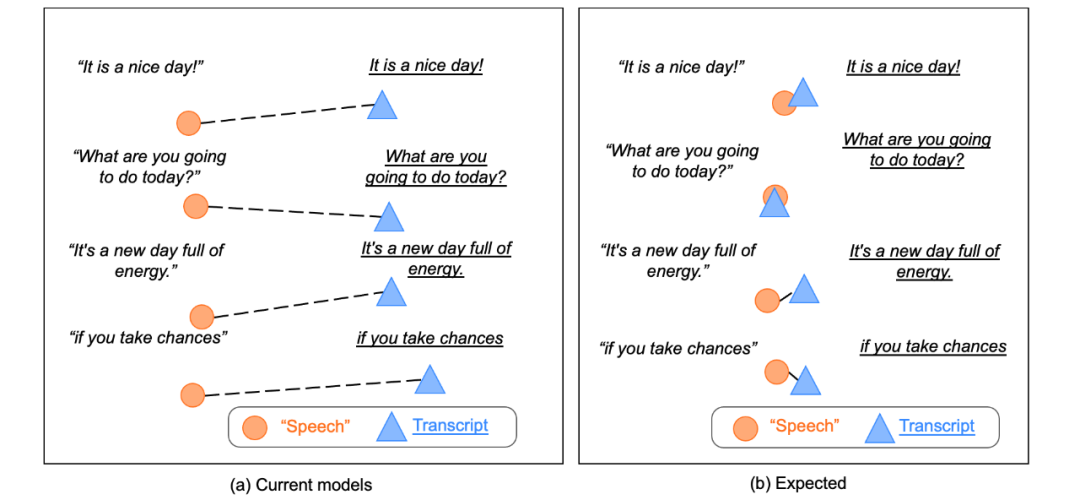
图 2 ConST 的架构与语义空间
视觉语言预训练模型
X-VLM
X-VLM 是以 Transformer 为基础,以文本 - 图片对数据作为输入进行预训练得到的视觉语言模型,可以用多种跨模态的下游任务(见图 3)[3]。具有多模态处理能力的视觉语言模型是最近研究的热点。我们这里假设文本和图片对的内容是强关联的,文本描述图片内容,但描述是多颗粒度的。文本可能描述图片整体、区域或物体,如图 3 所示。这种基础模型对 visual question answering 和 visual grounding 等任务等更加适用,也可以用于其他任务。X-VLM 是目前视觉语言各种任务的 SOTA。
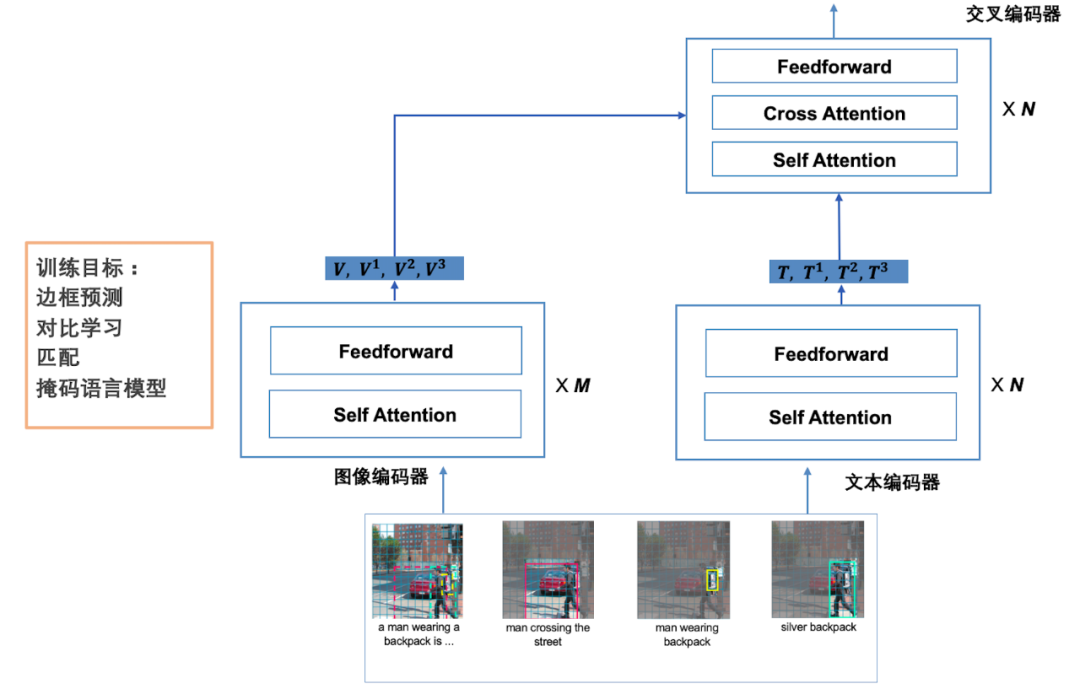
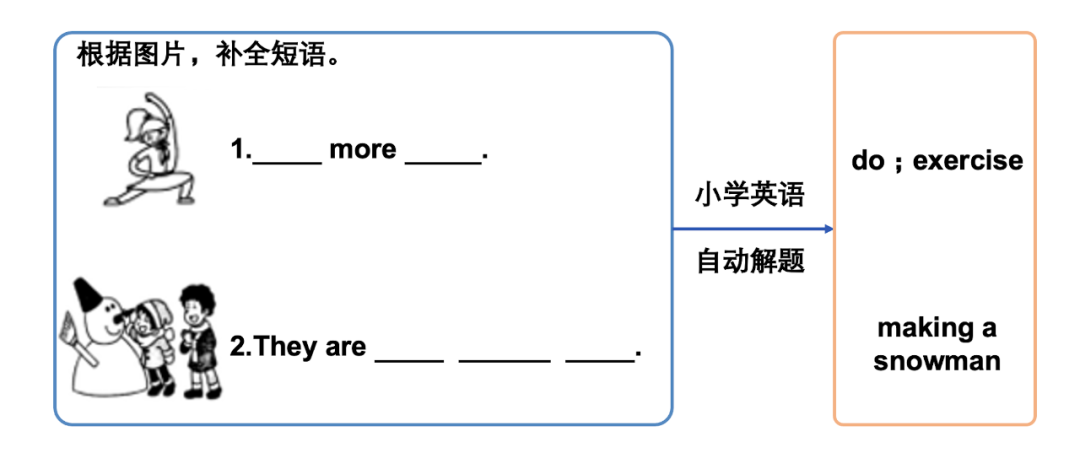
图 3 X-VLM 的架构和英语解题例
之前的方法都是在训练之前或训练之中使用物体检测,而 X-VLM 完全不使用。从已有数据中导出不同颗粒度的文本 - 图片对数据,包括物体的名称和图像中框出的物体的对应数据。模型由文本编码器、图像编码器、交叉编码器组成。文本编码器和图像编码器是 Transformer 的编码器,交叉编码器有从文本到图像的注意力计算,文本表示作为 query。训练有四个目标,包括边框预测、掩码语言模型、匹配、对比学习。边框预测是掩盖物体的边框,从文本 - 图片对数据中还原边框,掩码语言模型掩盖一些 token 再从文本 - 图片对数据中还原,匹配判断文本 - 图片数据的匹配程度,对比学习进一步在 batch 数据中拉进语义相近的文本和图片的表示。X-VLM 已经用于多个实际应用,比如图 3 下的小学英语解题。输入带图的英语填空题,系统可以自动完成填空,这个任务之前是非常困难的。
最近的 X^2-VLM 将 X-VLM 扩展,也可以处理视频和多语言。实验结果显示在 base 和 large 的规模上 X^2-VLM 是语言视觉任务的最新 SOTA[4]。
DaVinci
Davinci 是更偏文本和图片生成的多样化视觉语言处理模型[5]。文本 - 图片对数据作为输入,假设文本 - 图片是强关联的,文本描述图片内容。DaVinci 一个模型,完成从文本到图片生成,从图片到文本生成,甚至其他的理解和生成等许多任务,在这些任务上达到或接近 SOTA 结果。
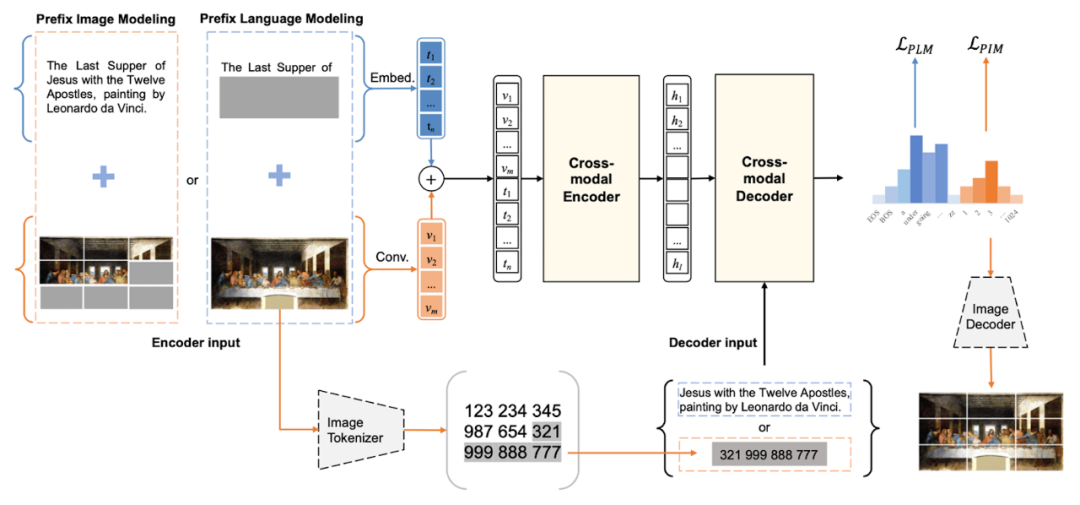

图 4 DaVinci 的架构和图片生成例
DaVinci 的模型是 Transformer,如图 4 上图所示,预训练采用 prefix language modeling 的方法。预训练时,输入是文本 - 图片对,将其中的部分文本或部分图片掩盖,然后让数据通过 Transformer 的编码器和解码器,将被掩盖的内容还原。事先对图片进行 image tokenizing 处理,每个图片的 token 由一个离散的编码表示,进行了图像的离散化。还原实际是生成被掩盖部分的图片 token,这时没有被掩盖的上下文(可能是文本或图片)帮助生成。没有被掩盖的部分就是 prefix。DaVinci 的模型虽然简单,但可以做高质量的文本和图片生成。比如,图 4 中的下图是给定文本 DaVinci 自动生成的图片的例子。DaVinci 论证了使用同一个模型是能够同时学习“写”(基于图片的文本生成)和“画”(基于文本的图像生成),并且这两种能力能够互相促进。
深度学习加逻辑推理
Neural Symbolic Processor
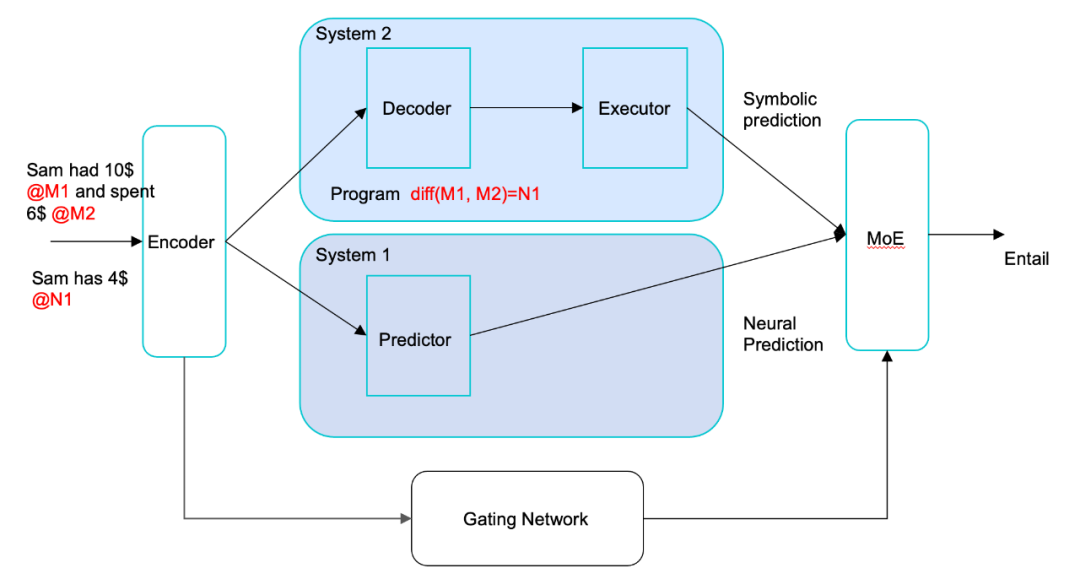
图 5. NSP 的架构,由系统 1 和系统 2 组成
这里考虑自然语言理解的问题,具体的文本蕴含任务。比如 "Sam 有 10 美元,他花了 6 美元" 这句话和 "Sam 有 4 美元" 这句话存在蕴含关系。传统的深度学习方法用预训练语言模型 BERT 判断,可以达到一定的准确率,但是有很多蕴含关系的判断需要逻辑推理,包括数字推理。纯深度学习的方法并不能保证做得很好。推测人分别使用系统 1 和系统 2 进行类推推理和逻辑推理,然后进行综合判断。
NSP(neural symbolic processing)是模仿人的自然语言理解系统,也包含系统 1 和系统 2(见图 5)[6]。核心想法是将输入的文本,通过两路处理分别进行类推推理和逻辑推理。先将输入通过编码器转换成基于向量的内部表示。之后,在系统 1 里基于内部表示进行预测,与基于 BERT 的传统深度学习方法相似。在系统 2 里将内部表示进行解码,产生基于符号的内部表示,称之为程序,接着执行程序;可以认为对输入文本进行了翻译,转换成程序。最后,将两路的处理结果进行集成,产生最终的结果,集成使用 MoE 模型。编码器和解码器都基于预训练语言模型 BART。比如,针对上面的例子,系统 2 产生并执行程序,也就是将第 1 个数字减去第 2 个数字等于第 3 个数字(M1-M2=N1)。这样的机制可以保证无论数字具体是多少,都可以进行同样的推理。系统 1 同时进行基于深度模型(编码器)的预测。两者的判断又通过 MoE 得到最终集成结果。NSP 在需要逻辑推理的语言理解任务上比传统的方法在准确率上有大幅度的提升。
人工智能需要怎样的计算范式
深度学习虽然取得了很大的进展,但相比人脑的学习和推理能力还相差甚远,主要体现以下几个方面。深度学习善于类推推理,但需要逻辑推理时往往无能为力。深度学习依然需要依赖于大模型、大数据和大算力,数据效率和能源效率要比人低很多。更重要的是,学习和推理往往只能针对具体的任务进行,而不像人脑那样拥有通用的学习和推理能力。
展望未来,在很长一段时间里机器学习,特别是深度学习仍将是人工智能的主体技术。另一方面,人工智能需要更大的突破,有必要研究和开发下一代的智能计算技术。我们认为,脑启发计算应该是未来发展的主要方向。最近 Bengio、LeCun 等也提出了类似的主张[7]。这里说的脑启发计算并不是简单地模仿人脑,而是根据计算机的实际特点参考人脑的机制,构建机器的学习和推理智能系统,主体可能还是深度学习,但与深度学习又有本质的不同,属于新的范式。脑科学家马尔将计算分为三个层面,分别是功能、算法和实现。脑启发计算更多的应该是从功能层面借鉴人脑的机制。希望能解决样本效率、能源效率、逻辑推理等方面的问题,为领域带来更大的突破。下面通过几个例子说明我们所说的脑启发计算。
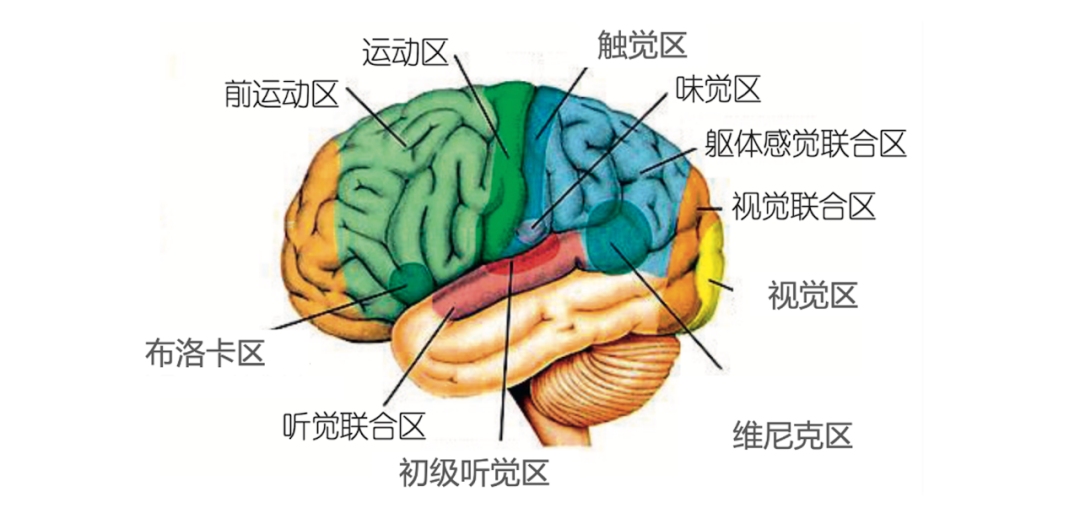
图 6. 大脑皮层中的主要脑区
人脑的信息处理分多个脑区。各个脑区相对独立,又相互关联(见图 6)。比如,对自己祖母的记忆,包括视觉、听觉、语言等方面的信息,分别存储在不同的脑区。脑启发计算可以参考人脑的分区处理机制。深度学习中的 MoE(mixture of experts)技术有一定的相关性。
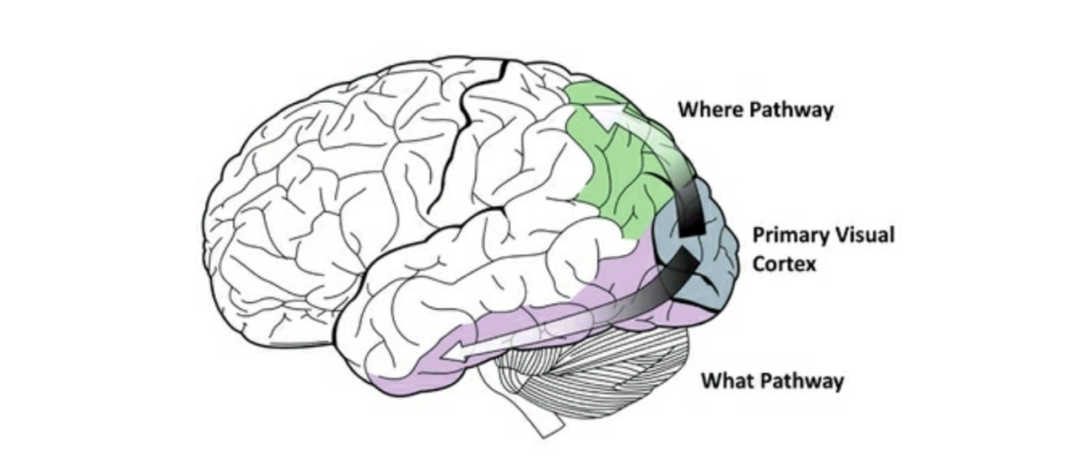
图 7. 视觉处理的 What 通道和 Where 通道
人脑的视觉处理是分两个通道进行的,分别是 What 通道和 Where 通道(见图 7)。What 通道负责识别物体的大小,形状,颜色,而 Where 通道负责识别物体的空间位置。基于深度学习的图像识别不将两者的信息加以区分。这就可能导致了学习效率的降低。比如,在卷积神经网络网络的学习中需要通过数据增强的方法,增加样本训练模型,以应对图像中物体的尺度不变性、旋转不变性。
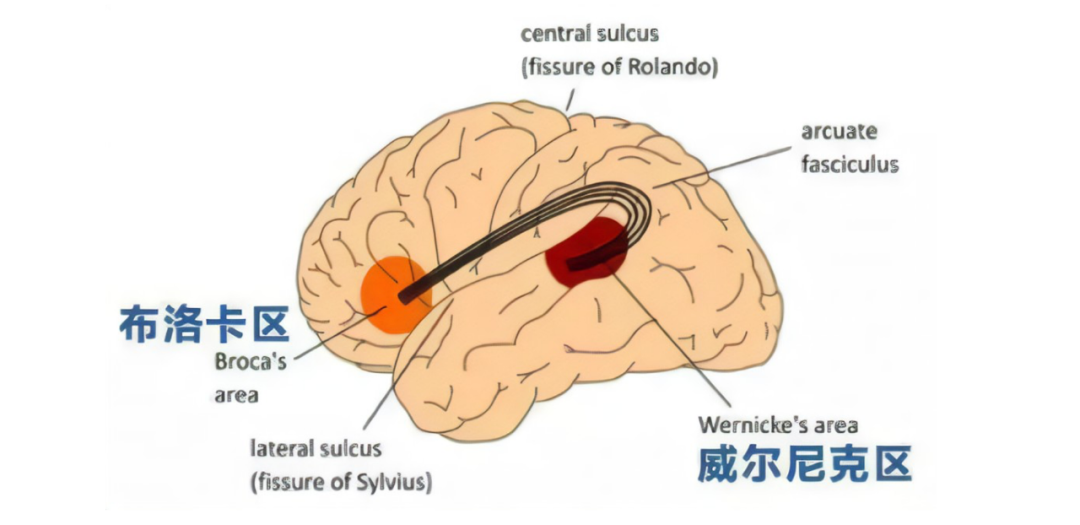
图 8 语言处理的布洛卡区和韦尼克区
人脑的语言处理在布洛卡区和韦尼克区同时进行,分别负责语法和词汇(见图 8)。人的语言理解和生成是在两个脑区并行进行的。而现在基于 Transformer 的语言处理模型都没有将两者分开,可能导致训练需要更多的样本。
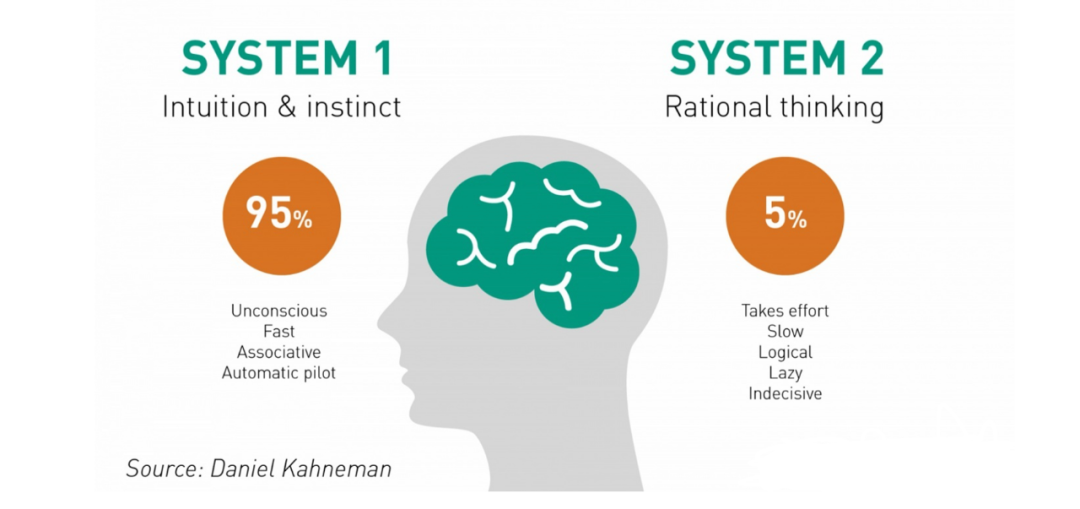
图 9 人脑信息处理的系统 1 和系统 2
如上所述,人脑的信息处理由系统 1 和系统 2 组成(见图 9)。如何实现包含系统 1 和系统 2 的智能系统,是人工智能的一大课题。Neural Symbolic Processor 等采用的神经符号处理是一条路径,面向这个方向迈出了一小步。
图 10 人生来就具基本的感知和认知能力
人的许多感知和认知能力是生来具有的,包括对物理法则、数量、概率等概念的认识,以及语言的习得和使用。当前的预训练、自监督学习从大量的无监督数据中自动学习基础模型,也可以认为学习到的对应着人生来具有的能力。没有必要假设人工智能系统需要将所有的能力都通过数据驱动,机器学习的方法获取。比如,知识图谱是一种高质量的结构化数据,可以直接提供给智能系统作为一种 “生来具有的” 资源使用。
人工智能需要怎样的计算理论
人工智能的未来发展同时也需要更强大的机器学习理论指导。用传统的泛化上界解释深度学习现象已经明显遇到了困难。深度学习及脑启发计算的现象通常是非常复杂的。我们认为,应该从信息、数据、模型等几个角度出发建立新的深度学习及脑启发计算理论。
具体地应该考虑以下问题。学习和推理过程中信息是如何流动的?数据中存在怎样的内在结构?模型有怎样的函数表示能力?最近的一些研究在这些方向取得了一定成果,值得大家关注。这里进行一个简单总结,也期待出现更完整全面的理论。也建议阅读马毅等最近的文章[8]。
信息瓶颈理论
机器学习和数据压缩是一枚硬币的两面。无监督学习的目标是给定数据 X 发现其内在结构 X'。数据压缩是将数据 X 进行压缩得到表示 X',并且能从表示 X'还原原始数据 X。两者是相互对应的,可以认为数据压缩得到的表示 X'就是无监督学习要得到的内在结构 X'。监督学习的目标是学习从输入数据 X 到输出 Y 的映射。Tishby 等提出的信息瓶颈理论从数据压缩的角度解释监督学习。将数据 X 进行充分的压缩得到表示 X',使得表示 X'对输出 Y 有充分准确的预测,将两者分别用互信息表示,进行以下优化,最小化 X 和 X'之间的互信息,同时最大化 Y 和 X'之间的互信息,就对应着监督学习。这时表示 X'是对预测有用的特征,称作信息瓶颈。
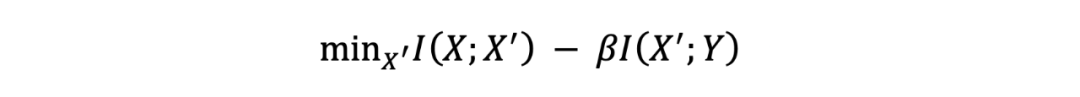
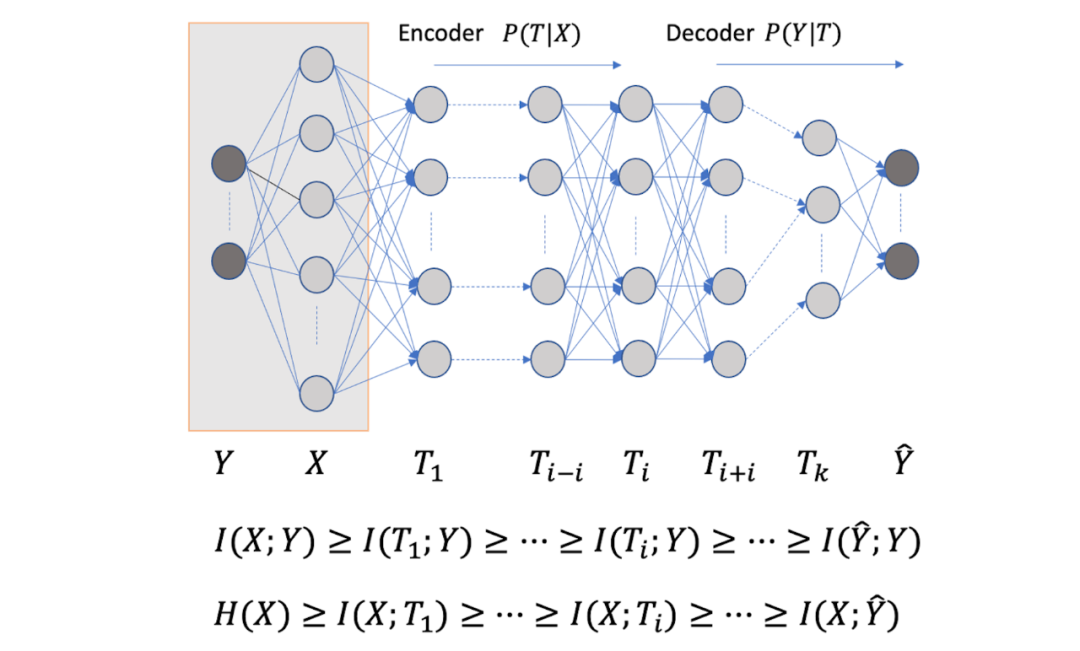
图 11 信息瓶颈理论解释神经网络学习
Tishby 等使用信息瓶颈理论对神经网络学习的过程进行了分析,得到了一些有意思的分析结果[9]。考虑前馈神经网络的学习和推理中的信息流动。假设输入 X 和理想的输出 Y 的联合概率分布已知(理论上假设是已知的,对学习算法来说是未知的)。前馈神经网络的输入是 X,输出是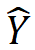 。前馈神经网络每层由一个随机变量
。前馈神经网络每层由一个随机变量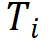 表示。如图 11 所示,从输入层 X 到隐层,再从隐层到输出层
表示。如图 11 所示,从输入层 X 到隐层,再从隐层到输出层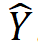 ,构成一个马尔可夫链,可以由有向图表示。输入 X 和理想输出 Y 之间的关系由无向图表示。前馈神经网络预测时要保留输入 X 的信息,互信息
,构成一个马尔可夫链,可以由有向图表示。输入 X 和理想输出 Y 之间的关系由无向图表示。前馈神经网络预测时要保留输入 X 的信息,互信息 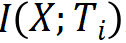 减少或不变。满足数据处理不等式,当且仅当处理后是充分统计量时互信息不变。同时要对理想输出 Y 有预测能力,使得互信息
减少或不变。满足数据处理不等式,当且仅当处理后是充分统计量时互信息不变。同时要对理想输出 Y 有预测能力,使得互信息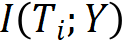 尽量保持不变。信息瓶颈理论,认为学习的过程就是对输入 X 互信息减少,对理想输出 Y 互信息保持不变的神经网路参数调节过程。每一层兼顾对输入的压缩和对输出的预测作用,认为每一层存在着对输入的 encoder 和对输出的 decoder。
尽量保持不变。信息瓶颈理论,认为学习的过程就是对输入 X 互信息减少,对理想输出 Y 互信息保持不变的神经网路参数调节过程。每一层兼顾对输入的压缩和对输出的预测作用,认为每一层存在着对输入的 encoder 和对输出的 decoder。
在模拟实验中(假设输入 X 和输出 Y 已知),用交叉熵和 SGD 训练一个 5 层的前馈神经网络,得到学习过程中神经网络每一层的两个互信息的值,将其画在图 12 中,得到信息平面。横轴和纵轴分别表示互信息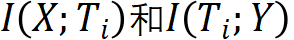 。图中将学习过程中得到的各个神经网络的每一层的互信息连成一条线。理想情况学习结束时得到的神经网络,各层的纵轴表示的互信息不变,各层横轴表示的互信息随着层级的增加而减少。就是图中最上面的一条线。模拟实验发现,神经网络的学习分两阶段,前 300 左右的 epoch 在学如何预测(初步的预测),学习比较快,之后到 10000epoch 的学习在学习如何压缩,学习比较慢,大部分时间学压缩。
。图中将学习过程中得到的各个神经网络的每一层的互信息连成一条线。理想情况学习结束时得到的神经网络,各层的纵轴表示的互信息不变,各层横轴表示的互信息随着层级的增加而减少。就是图中最上面的一条线。模拟实验发现,神经网络的学习分两阶段,前 300 左右的 epoch 在学如何预测(初步的预测),学习比较快,之后到 10000epoch 的学习在学习如何压缩,学习比较慢,大部分时间学压缩。
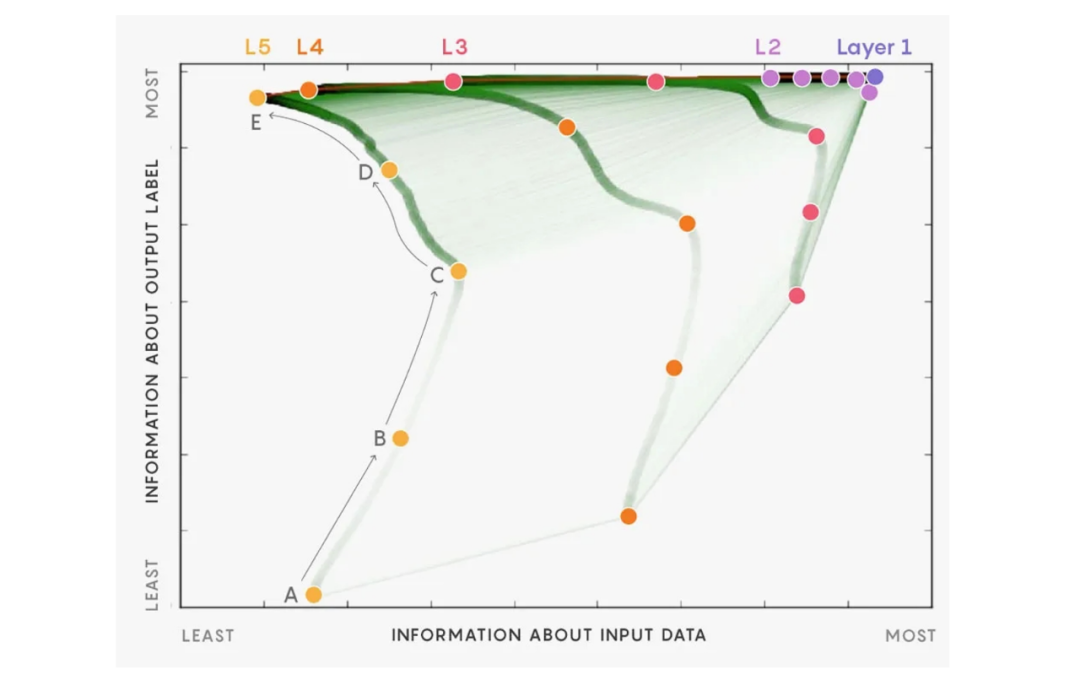
图 12 信息平面分析神经网络学习过程
数据流形假说
学习中的数据的内在结构也是需要考虑的。马毅等的工作中,假设高维数据存在于低维空间的流形上,更具体地,多个流形的混合体[10]。认为聚类和分类学习是对数据通过深度神经网络的非线性变换进行压缩。将流形混合体上的数据从高维空间映射到低维线性空间,在低维线性空间进行聚类或分类。低维线性空间中,类内样本相近,类外样本相远(见图 13)。
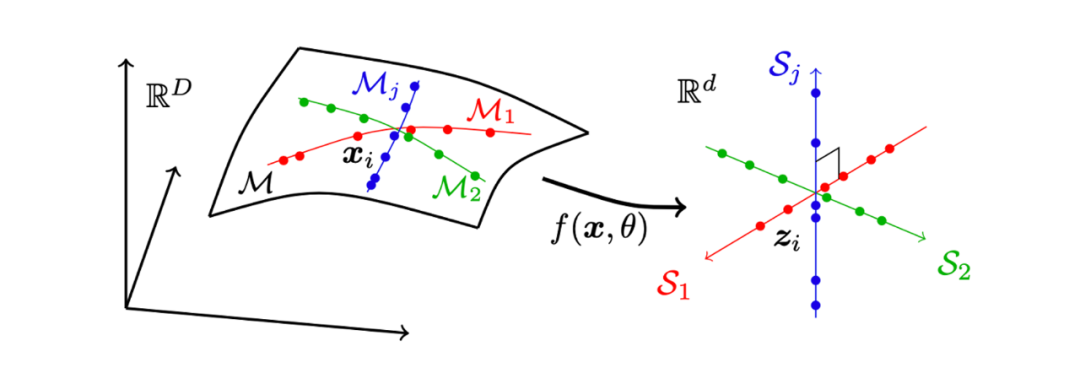
图 13 数据处在高维空间的流形上,学习是对数据的压缩
马毅等提出了机器学习的压缩比最大原理 MCR2(maximal coding rate reduction)[10]。
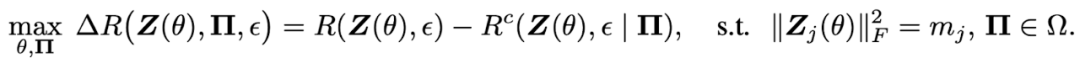
考虑分类问题,假设输入数据 X 中的同类样本在同一个流形上。输入数据 X 通过神经网络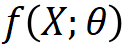 被影射为表示 Z。R 是样本表示 Z 的(平均)编码长度,
被影射为表示 Z。R 是样本表示 Z 的(平均)编码长度, 是样本表示 Z 在一个划分
是样本表示 Z 在一个划分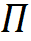 下分类后的(平均)编码长度,
下分类后的(平均)编码长度,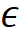 是编码精度。压缩比最大原理,认为压缩比越大,即编码长度减少越大,分类的结果就越好。学习就是要找到压缩比最大的神经网络。理论证明,在一定条件下,压缩比最大的分类是将同类样本放到同一个子空间里的分类,而且同类样本在子空间均质(isotropic)分布,各个类的子空间正交。MCR2 是学习的指导原理,也可以用于解释学习的现象。学习理论不仅需要考虑数据压缩,而且需要考虑数据内在结构,MCR2 是一个很好的例子。
是编码精度。压缩比最大原理,认为压缩比越大,即编码长度减少越大,分类的结果就越好。学习就是要找到压缩比最大的神经网络。理论证明,在一定条件下,压缩比最大的分类是将同类样本放到同一个子空间里的分类,而且同类样本在子空间均质(isotropic)分布,各个类的子空间正交。MCR2 是学习的指导原理,也可以用于解释学习的现象。学习理论不仅需要考虑数据压缩,而且需要考虑数据内在结构,MCR2 是一个很好的例子。
Transformer 的模型
最近对 Transformer 模型的表示能力分析有一些重要的结论。Transformer 模型有几个重要构成要素,首先通过注意力包括自注意力机制实现输入表示的组合。文本、图像、语音数据都是具有组合性的,也就是说,整体的表示由局部的表示组合而成。注意力的计算实际是一种查询,是 key-value store 符号查询在向量查询上的扩展。向量是 one-hot vector 时注意力就等价于 key-value store 查询。这样做的一个优点是,用固定的参数量处理可变的输入。人的类推推理也可以认为是一种相似度计算,注意力机制是类推推理的一个合理且有效的实现。注意力本质是线性变换(不考虑其中的 softmax 计算),在其基础上的 FFN 又实现了非线性变换。
最近 Dong 等的理论研究发现,Transformer 中的残差连接实际起着非常重要的作用[11]。残差连接实现了深度不同的各种注意力网络加上非线性变换的集成(见图 14)。理论证明,如果只有注意力,而没有残差连接或者前馈神经网络,Transformer 学到的表示就会变成是秩为 1 的矩阵,也就是每个输入 token 的表示趋于相同。以往的实验也证明 position embedding 如果没有残差连接也不能传到 Transformer 的高层。
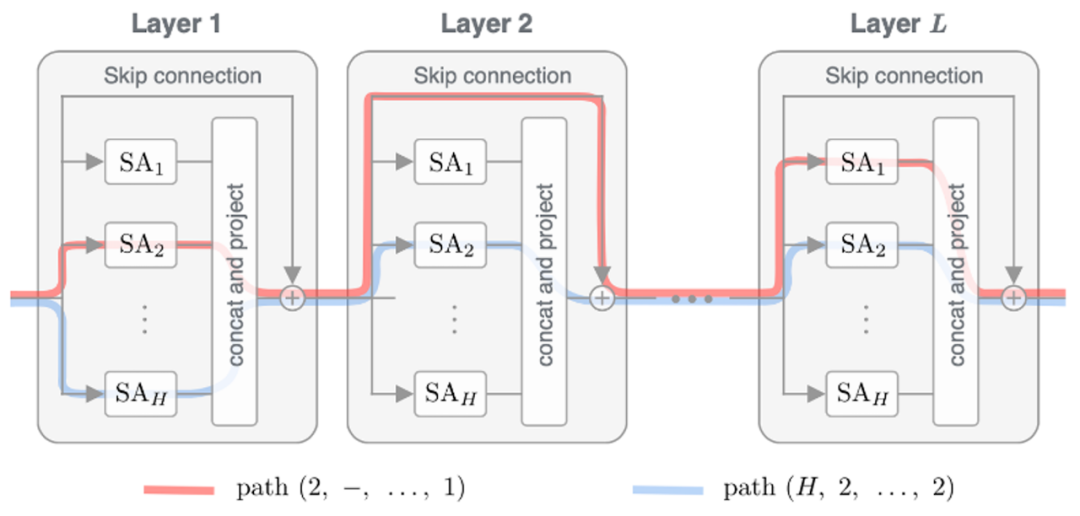
图 14 Transformer 实际是自注意力网络的集成,自注意力网络中通过残差连接形成了许多路径
总结
本文的主要观点如下。
深度学习的大模型、大数据和大算力模式继续取得成果,沿着这个方向还有很大的发展空间。
字节跳动人工智能实验室在进行创新工作,推动领域的发展,在深度学习和应用方面做出了业界领先的成果。
另一方面深度学习的局限也已凸显,样本效率和能源效率低下,逻辑推理能力缺乏。整体缺少理论指导。
下一代的人工智能更应该是从人脑计算得到启发的,脑启发计算是未来的发展方向。
脑启发计算是指以现在的深度学习等机器学习为主体,在其基础上(主要在功能层面)借鉴人脑的计算机制,构成的全新的智能计算范式。
脑启发计算、深度学习需要强大的理论支撑,从信息流动、数据内在结构、模型表示能力等多方面的研究非常重要。冯 · 诺伊曼对人脑和计算机研究的一个假设是智能可以还原为计算。人脑的计算机制是极其复杂的。所以,人工智能需要借鉴人脑,才能构建像人一样智能的计算机系统。本文所说的脑启发计算应该是迈向人工智能理想的一个新的范式。在这个过程中,也需要有对应的智能计算理论作为基础。
作者 李航,字节跳动研究部门负责人,ACL 会士、IEEE 会士,《机器学习方法》等书作者。 致谢 马毅、宋睿华、徐君、张新松等对本文的初稿提出了宝贵意见,在此对他们表示感谢。 参考文献 [1] Fei Huang, Hao Zhou, Yang Liu, Hang Li, Minlie Huang. Directed Acyclic Transformer for Non-Autoregressive Machine Translation, ICML 2022. [2] Rong Ye, Mingxuan Wang, Lei Li, Cross-modal Contrastive Learning for Speech Translation, NAACL 2022. [3] Yan Zeng, Xinsong Zhang, Hang Li, Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts, ICML 2022. [4] Yan Zeng, Xinsong Zhang, Hang Li, Jiawei Wang, Jipeng Zhang, Wangchunshu ZhouX2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks, arxiv 2022. [5] Shizhe Diao, Wangchunshu Zhou, Xinsong Zhang, Jiawei Wang. Prefix Language Models are Unified Modal Learners, arxiv 2022. [6] Zhixuan Liu, Zihao Wang, Yuan Lin, Hang Li, A Neural Symbolic Approach to Natural Language Understanding, EMNLP 2022 findings. [7] Zador, A., Richards, B., Ölveczky, B., Escola, S., Bengio, Y., Boahen, K., Botvinick, M., Chklovskii, D., Churchland, A., Clopath, C. and DiCarlo, J., Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution. arXiv preprint, 2022. [8] Ma, Y., Tsao, D. and Shum, H.Y., On the principles of parsimony and self-consistency for the emergence of intelligence. Frontiers of Information Technology & Electronic Engineering, 2022. [9] Tishby, N. and Zaslavsky, N., Deep learning and the information bottleneck principle. In 2015 IEEE information theory workshop. [10] Yu, Y., Chan, K.H.R., You, C., Song, C. and Ma, Y., Learning diverse and discriminative representations via the principle of maximal coding rate reduction, NeurIPS 2022. [11] Dong, Y., Cordonnier, J.B. and Loukas, A., Attention is not all you need: Pure attention loses rank doubly exponentially with depth, ICML 2021.
编辑:黄飞







 工商网监
工商网监
评论