 电子发烧友App
电子发烧友App


有效的数据结构对于机器学习算法分析和操作海量数据集至关重要。程序员和数据科学家可以通过了解这些数据结构来提高性能并优化他们的程序。
了解机器学习中最常用的数据结构。
机器学习中的数据结构和算法是什么
数据结构是指数据在计算机内存中的组织和存储。机器学习过程使用通用数据结构在每个阶段有效地存储和修改数据。
机器学习上下文中的算法是指用于训练模型、进行预测和分析数据的数值或计算技术。程序员逐渐使用算法来解决特定问题或完成特定任务。
1. 数组
数组是机器学习中用于有效存储和检索数据的基本数据结构。由于其矢量化操作和恒定时间元素访问,它们非常适合管理大量数据集。
使用数组是将数据存储在连续内存块中的一种简单有效的方法。它们可以存储相同数据类型的片段,使其适合在机器学习任务中表示特征向量、输入数据和标签。
以下代码演示如何使用数组存储数据集。
# Create an array to store a dataset
dataset = [2.5, 3.2, 1.8, 4.9, 2.1]
# Access elements in the array
print("First element:", dataset[0])
print("Third element:", dataset[2])
# Perform vectorized operations on the array
squared_values = [x ** 2 for x in dataset]
print("Squared values:", squared_values)
在此示例中,您将创建一个名为数据集的数组,该数组存储多个数值。您可以使用索引表示法访问数组的各个元素,例如 dataset[0],以获取第一个元素。
无论数组大小如何,数组都提供对其元素的常量时间访问。
数组还包括矢量化操作,这些操作同时对数组的所有成员执行单个操作。上面的示例使用列表推导式计算数据集数组中每个成员的平方值。因此,可以在没有显式循环的情况下准确执行计算。
数组与库和架构的兼容性是机器学习的主要优势之一。
数组简化了流行库中机器学习算法的加载,例如 NumPy、TensorFlow 和 sci-kit-learn。这加快了数据处理和模型训练。
数组是机器学习中用于有效存储和操作数据的基本数据结构。它们非常适合处理大型数据集和进行计算,因为它们具有矢量化操作和对项目的恒定时间访问。
使用数组的开发人员可以提高其程序在机器学习活动中的效率。
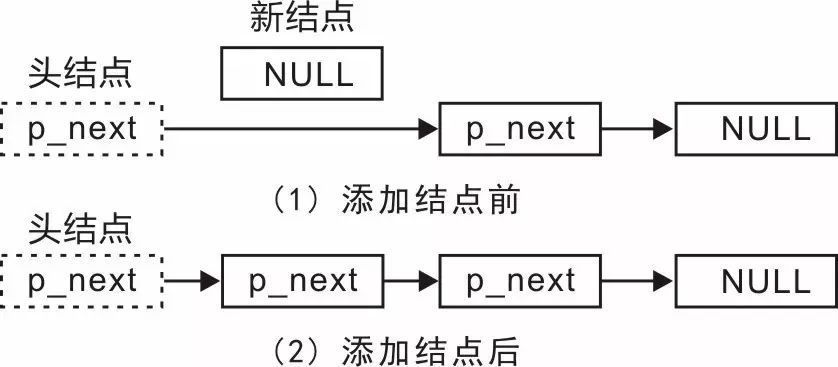
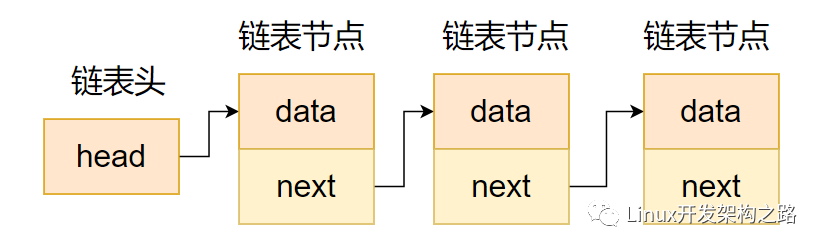
2. 链表
链表是机器学习中使用的常见数据结构,特别是用于处理顺序数据或构建数据管道。与数组相反,链表提供动态内存分配,使其适合处理不同长度的数据。
查看一个示例以了解 Python 中的链表实现。
# Node class for a linked list
class Node:
def __init__(self, data):
self.data = data
self.next = None
# Creating a linked list
head = Node(1)
second = Node(2)
third = Node(3)
head.next = second
second.next = third
在链表中插入和删除元素很简单,因为它需要调整节点之间的指针。由于这种质量,它们在处理流数据或需要实时更新时至关重要。
3. 矩阵
表格数据的有效表示和操作需要使用矩阵,矩阵是机器学习中的基本数据结构。它们是二维数组,以逻辑和结构化的方式传达数据。
矩阵运算、矩阵分解和神经网络取决于矩阵在机器学习中的使用。
矩阵数据结构存储和操作多维数据的多功能性使它们对机器学习至关重要。行和列构成结构,每个元素表示一个数据点或感兴趣的功能。
矩阵运算(如矩阵乘法、加法和减法)可实现快速高效的数学计算。
下面是在机器学习中使用矩阵的示例代码。
import numpy as np
# Create a matrix
matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Access elements in the matrix
print("Element at row 1, column 2:", matrix[1, 2])
# Perform matrix operations
transpose = matrix.T
sum_rows = np.sum(matrix, axis=1)
# Print the transpose and sum of rows
print("Transpose of the matrix:\n", transpose)
print("Sum of rows:", sum_rows)
该代码示例使用 NumPy 库生成矩阵并与之交互。为了创建矩阵,请使用 np.array 函数。行索引和列索引允许访问某些矩阵成员。
此外,该代码还演示了如何使用 np.sum 函数转置矩阵以及如何计算行的总和,这两者都是矩阵运算。
矩阵计算在机器学习应用程序中很常见。当将输入特征和目标变量表示为矩阵时,快速计算模型参数是可行的,例如在线性回归中一样。
该矩阵在神经网络中存储向前和向后传播期间的权重和激活,从而实现有效的训练和预测。
4. 决策树
称为决策树的灵活机器学习算法使用分层结构根据输入特征生成判断。内部节点表示特征,而叶节点表示类标签或结果。决策树在可解释性方面表现出色,可以处理分类和回归问题。
决策树分析和简化机器学习决策。这些关系的层次性质使得理解特征和目标变量之间的复杂关系变得更加简单。
考虑一个如何使用 sci-kit-learn 库构建决策树分类器的示例。
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a Decision Tree classifier
clf = DecisionTreeClassifier()
# Train the Decision Tree classifier
clf.fit(X_train, y_train)
# Predict the classes for the test set
y_pred = clf.predict(X_test)
# Calculate the accuracy of the classifier
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
上面示例中的第一个数据集是众所周知的 Iris 数据集,它将数据集用于分类任务。使用 train_test_split 函数将数据集拆分为训练集和测试集。然后使用 DecisionTreeClassifier 类来制作决策树分类器。
fit 方法在训练集上训练分类器。然后使用测试集和accuracy_score函数的预测来计算分类器的精度。
决策树提供了适应性强、可解释性以及随时可以处理数字和分类特征的几个好处。他们能够识别具有非线性关系的特征和目标变量。
此外,您还可以使用决策树作为基本算法构建更复杂的集成技术,例如随机森林。
决策树是灵活且易于理解的机器学习算法,可以管理分类和回归任务。它们的层次结构和快速决策使它们在各个领域都很有用。
在机器学习应用程序中使用决策树来了解基础数据模式并得出明智的结论。
5. 神经网络
人脑中的神经连接是一类称为神经网络的机器学习模型的灵感来源。它们由模仿感知器网络的互连人工神经元组成。
图像识别、自然语言处理和推荐系统都采用神经网络,因为它们具有理解复杂模式的卓越能力。
以下示例演示如何使用 TensorFlow 库创建神经网络。
import tensorflow as tf
# Creating a neural network model
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
由于它们包括隐藏层和复杂的设计,神经网络具有令人难以置信的适应性。您可以更改模型的参数,并使用梯度下降等优化方法对其进行训练。
机器学习中的数据结构和算法
使用数据结构和算法,您的代码可以提高机器学习系统的速度、可伸缩性和可解释性。选择的最佳设计将取决于主要问题的精确要求。每种设计都有一定的优势和用途。
数据科学家可以通过定期试验各种技术和数据类型来提高他们的性能并微调他们的模型。
您可以最大限度地发挥机器学习的潜力,并通过利用这些数据结构的优势推动图像识别、自然语言处理和推荐系统方面的突破。
审核编辑:郭婷
import tensorflow as tf
# Creating a neural network model
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))














 工商网监
工商网监
评论